Compactions make cluster unresponsive
28 views
Skip to first unread message

hor...@gmail.com
<horschi@gmail.com>Oct 17, 2022, 11:18:07 AM10/17/22
to ScyllaDB users
Hi,

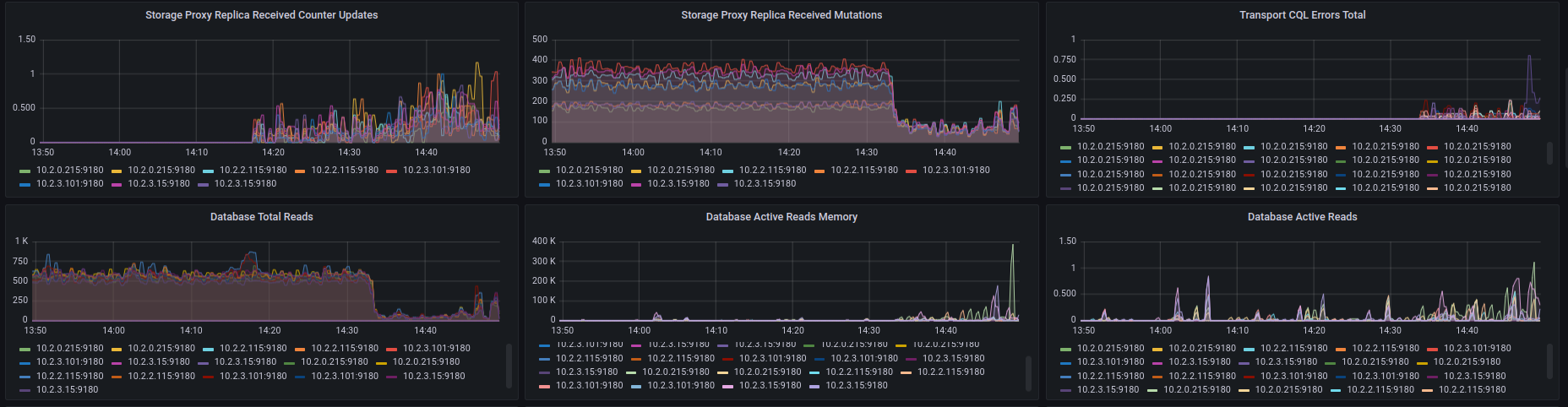
today I have seen a extreme compaction behaviour that brought down the entire scylla cluster for 20 minutes. (~16:35 - 16:55).
It seems that a lot of compactions were triggered at the same time, on two of the 4 servers I was seeing ~10 concurrent compactions. These are small VMs with SMP 2, which means these nodes were completely swamped by compactions:
You can see that reads/writes are going down dramatically and lots of queries fail:
After 20 minutes, the compactions were finished and the system became responsive again.
Is there any way to limit the amount of concurrent compactions in scylla? I would prefer if the compactions would be spread over a longer time and not all at the same time.
regards,
Christian

Raphael S. Carvalho
<raphaelsc@scylladb.com>Oct 17, 2022, 2:11:12 PM10/17/22
to scylladb-users@googlegroups.com
Hi,
which version are you running?
latest OSS version should make compaction more friendly to the overall performance
which compaction strategy(ies) are you using in your tables?
In this doc, you'll find good suggestions on how to reduce compaction impact:
regards,Christian--
You received this message because you are subscribed to the Google Groups "ScyllaDB users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scylladb-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/77483c49-7b0d-4b4d-8f45-1ad912699006n%40googlegroups.com.

Avi Kivity
<avi@scylladb.com>Oct 17, 2022, 2:42:15 PM10/17/22
to scylladb-users@googlegroups.com, xemul@scylladb.com
These are spinning disks, yes? A move to 5.0.latest + setting --io-latency-goal-ms=500 should greatly improve things.
That setting tells the scheduler that it can push as many compaction requests as it likes, as long as single-request latency (from the disk perspective, not database requests) doesn't exceed 500ms. You can play with the number, but setting it too low for a spinning disk will make it impossible for the scheduler to satisfy the requirements and it won't work well.
Please update the monitoring to the latest version, and when you post, switch to shard view. The aggregation can hide important information.
With that done, ScyllaDB should be able to spread out the compactions itself.
Pavel, should we change the I/O scheduler decay interval to me max(whatever it is now, io-latency-goal * some factor)? With a slow disk, it may forget history too quickly.
horschi
<horschi@gmail.com>Oct 17, 2022, 3:17:27 PM10/17/22
to scylladb-users@googlegroups.com
Hi Rafael,
which version are you running?
5.0.5
latest OSS version should make compaction more friendly to the overall performancewhich compaction strategy(ies) are you using in your tables?
Mostly Size-tiered, and some small Leveled tables.
In this doc, you'll find good suggestions on how to reduce compaction impact:
Will the compaction shares also reduce the concurrent compactions? Generally, the use CPU cycles are not the issue I think. I think the problem is that the storage is backed by spinning disks, which do not like the many concurrent reads.
Thanks,
Christian
Avi Kivity
<avi@scylladb.com>Oct 17, 2022, 3:47:33 PM10/17/22
to scylladb-users@googlegroups.com
The compaction concurrency will not be lower, but with a higher --io-latency-goal the scheduler will be able to restrict the bandwidth used by compaction (or so we hope, we haven't tested with spinning disks). Note that due to RAID you do need some concurrency.
horschi
<horschi@gmail.com>Oct 17, 2022, 3:50:20 PM10/17/22
to scylladb-users@googlegroups.com
These are spinning disks, yes? A move to 5.0.latest + setting --io-latency-goal-ms=500 should greatly improve things.
Its already on 5.0.5.
I assume the storage is HDD based. Its the standard storage of a VM.
That setting tells the scheduler that it can push as many compaction requests as it likes, as long as single-request latency (from the disk perspective, not database requests) doesn't exceed 500ms. You can play with the number, but setting it too low for a spinning disk will make it impossible for the scheduler to satisfy the requirements and it won't work well.Please update the monitoring to the latest version, and when you post, switch to shard view. The aggregation can hide important information.
It should be pretty recent, but its integrated in our Grafana. The number of compactions and compaction shares are evenly distributed across shards. But not across hosts. There are two (out of 4) hosts compacting like crazy (8 compactions per host, roughly 5 per shard).

<- this is aggregated, but its evenly shared across shards.
With that done, ScyllaDB should be able to spread out the compactions itself.
I will give it a try. But I am not sure if I am able to get feedback as I had to scale the servers up so that people are not interrupted by these issues.
The number of compactions goes up very quickly. Will there be enough time for the scheduler to notice a increased latency in time? Won't there too many compactions already started, at the time when the latency goes up?
Avi Kivity
<avi@scylladb.com>Oct 17, 2022, 3:56:40 PM10/17/22
to scylladb-users@googlegroups.com
The scheduler doesn't care about the number of compactions. Compactions issue read and write requests and they are placed in a queue maintained by a scheduler. Similary queries issue read requests to another queue. The scheduler selects which queue to pick jobs from. If your io_properties.yaml is reasonable, then the scheduler will pick just enough requests from the compaction queue so that the latency doesn't shoot up too high (and you tell it how high it can go with --io-latency-goal). If there are lots of concurrent compactions, then they are served round-robin.
We don't want to serialize compactions to avoid this problem: a very large compaction starts, and while it's compacting, many memtables are flushed. Since they can't be compacted while the large compaction is ongoing, many small sstables accumulate and read amplification climbs.
With concurrent compactions, the small sstables can be compacted together while the larger one makes progress.
horschi
<horschi@gmail.com>Oct 17, 2022, 4:05:51 PM10/17/22
to scylladb-users@googlegroups.com
The scheduler doesn't care about the number of compactions. Compactions issue read and write requests and they are placed in a queue maintained by a scheduler. Similary queries issue read requests to another queue. The scheduler selects which queue to pick jobs from. If your io_properties.yaml is reasonable, then the scheduler will pick just enough requests from the compaction queue so that the latency doesn't shoot up too high (and you tell it how high it can go with --io-latency-goal). If there are lots of concurrent compactions, then they are served round-robin.
IO is configured to --max-io-requests=4, which is the lowest config allowed I think.
I will try io-goal setting.
We don't want to serialize compactions to avoid this problem: a very large compaction starts, and while it's compacting, many memtables are flushed. Since they can't be compacted while the large compaction is ongoing, many small sstables accumulate and read amplification climbs.With concurrent compactions, the small sstables can be compacted together while the larger one makes progress.
That problem is clear. How did cassandra do that btw? I guess it would need an algorithm that ensures that at least one compaction slot is left for smaller compactions.
Avi Kivity
<avi@scylladb.com>Oct 17, 2022, 4:16:29 PM10/17/22
to scylladb-users@googlegroups.com
On Mon, 2022-10-17 at 22:05 +0200, horschi wrote:
The scheduler doesn't care about the number of compactions. Compactions issue read and write requests and they are placed in a queue maintained by a scheduler. Similary queries issue read requests to another queue. The scheduler selects which queue to pick jobs from. If your io_properties.yaml is reasonable, then the scheduler will pick just enough requests from the compaction queue so that the latency doesn't shoot up too high (and you tell it how high it can go with --io-latency-goal). If there are lots of concurrent compactions, then they are served round-robin.IO is configured to --max-io-requests=4, which is the lowest config allowed I think.
IIRC it's ignored by the new scheduler.
I will try io-goal setting.
Please also post your io_properties.yaml for a sanity check.
We don't want to serialize compactions to avoid this problem: a very large compaction starts, and while it's compacting, many memtables are flushed. Since they can't be compacted while the large compaction is ongoing, many small sstables accumulate and read amplification climbs.With concurrent compactions, the small sstables can be compacted together while the larger one makes progress.That problem is clear. How did cassandra do that btw? I guess it would need an algorithm that ensures that at least one compaction slot is left for smaller compactions.
Not sure what Cassandra does. Note that Scylla has independent per-shard compaction, so we can have (number of shards) * (number of tiers). Note that same-sized compactions from different tables (but on the same shard) are serialized.
horschi
<horschi@gmail.com>Oct 17, 2022, 4:24:26 PM10/17/22
to scylladb-users@googlegroups.com
IIRC it's ignored by the new scheduler.
Then I will have to read up on the new scheduler.
Please also post your io_properties.yaml for a sanity check.
Its empty, as I thought max-io-requests is already set to the lowest possible value.
Avi Kivity
<avi@scylladb.com>Oct 17, 2022, 4:42:15 PM10/17/22
to scylladb-users@googlegroups.com
It has to be populated for the I/O scheduler to work. You have to run iotune to measure the disk, though that may fail (since we don't test spinning disks).
See https://github.com/scylladb/seastar/blob/master/doc/io-properties-file.md for documentation. The values should be something like
read_iops: nr_disks * 100
write_iops: nr_disks * 100
read_bandwidth: nr_disks * 150000000
write_bandwidth: nr_disks * 150000000
Does the log complain that the file is missing? If not we'll have to figure out that it's actually read.

Pavel Emelyanov
<xemul@scylladb.com>Oct 18, 2022, 11:23:07 AM10/18/22
to Avi Kivity, scylladb-users@googlegroups.com
On 17.10.2022 21:42, Avi Kivity wrote:
> These are spinning disks, yes? A move to 5.0.latest + setting --io-latency-goal-ms=500 should greatly improve things.
>
> That setting tells the scheduler that it can push as many compaction requests as it likes, as long as single-request latency (from the disk perspective, not database requests) doesn't exceed 500ms. You can play with the number, but setting it too low for a spinning disk will make it impossible for the scheduler to satisfy the requirements and it won't work well.
>
> Please update the monitoring to the latest version, and when you post, switch to shard view. The aggregation can hide important information.
>
>
> With that done, ScyllaDB should be able to spread out the compactions itself.
>
> Pavel, should we change the I/O scheduler decay interval to me max(whatever it is now, io-latency-goal * some factor)? With a slow disk, it may forget history too quickly.
There's even a request to make it configurable
https://github.com/scylladb/seastar/issues/1214
> On Mon, 2022-10-17 at 08:18 -0700, hor...@gmail.com wrote:
>> Hi,
>>
>> today I have seen a extreme compaction behaviour that brought down the entire scylla cluster for 20 minutes. (~16:35 - 16:55).
>>
>> It seems that a lot of compactions were triggered at the same time, on two of the 4 servers I was seeing ~10 concurrent compactions. These are small VMs with SMP 2, which means these nodes were completely swamped by compactions:
>>
>>
>> compactions.png
>>
>> You can see that reads/writes are going down dramatically and lots of queries fail:
>> rw.png
>>
>> You can see that reads/writes are going down dramatically and lots of queries fail:
>>
>> cqlread.png
>>
>> After 20 minutes, the compactions were finished and the system became responsive again.
>>
>> Is there any way to limit the amount of concurrent compactions in scylla? I would prefer if the compactions would be spread over a longer time and not all at the same time.
>>
>>
>> regards,
>> Christian
>>
>>
>> --
>> You received this message because you are subscribed to the Google Groups "ScyllaDB users" group.
>> To unsubscribe from this group and stop receiving emails from it, send an email to scylladb-user...@googlegroups.com <mailto:scylladb-user...@googlegroups.com>.
>> cqlread.png
>>
>> After 20 minutes, the compactions were finished and the system became responsive again.
>>
>> Is there any way to limit the amount of concurrent compactions in scylla? I would prefer if the compactions would be spread over a longer time and not all at the same time.
>>
>>
>> regards,
>> Christian
>>
>>
>> --
>> You received this message because you are subscribed to the Google Groups "ScyllaDB users" group.
>> To view this discussion on the web visit https://groups.google.com/d/msgid/scylladb-users/77483c49-7b0d-4b4d-8f45-1ad912699006n%40googlegroups.com <https://groups.google.com/d/msgid/scylladb-users/77483c49-7b0d-4b4d-8f45-1ad912699006n%40googlegroups.com?utm_medium=email&utm_source=footer>.
>
Reply all
Reply to author
Forward
0 new messages