Questions About Model Validation
56 views
Skip to first unread message

Gregory Lahman
Feb 19, 2023, 4:32:54 PM2/19/23
to scalismo
Hello everyone,
I have a few questions regarding my model. I am working on doing statistical shape modelling of human kidneys. I have built a ssm of the kidneys, and have sampled from the model space and played with the model parameters, so I know there is a decent amount of variation between them, but for some reason when I use the code:
val coeffs = DenseVector.zeros[Double](model.rank)
coeffs(0) = 3
val three_mesh = model.instance(coeffs)
ui.show(modelGroup, three_mesh, "+3")
coeffs(0) = 1
val one_mesh = model.instance(coeffs)
ui.show(modelGroup, one_mesh, "+1")
coeffs(0) = 2
val two_mesh = model.instance(coeffs)
ui.show(modelGroup, two_mesh, "+2")
MeshIO.writeMesh(two_mesh, new File("./data/kidney_pos_twomesh.stl"))
coeffs(0) = -3
val minus_three_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_three_mesh, "-3")
coeffs(0) = -2
val minus_two_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_two_mesh, "-2")
coeffs(0) = -1
val minus_one_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_one_mesh, "-1")
coeffs(0) = 3
val three_mesh = model.instance(coeffs)
ui.show(modelGroup, three_mesh, "+3")
coeffs(0) = 1
val one_mesh = model.instance(coeffs)
ui.show(modelGroup, one_mesh, "+1")
coeffs(0) = 2
val two_mesh = model.instance(coeffs)
ui.show(modelGroup, two_mesh, "+2")
MeshIO.writeMesh(two_mesh, new File("./data/kidney_pos_twomesh.stl"))
coeffs(0) = -3
val minus_three_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_three_mesh, "-3")
coeffs(0) = -2
val minus_two_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_two_mesh, "-2")
coeffs(0) = -1
val minus_one_mesh = model.instance(coeffs)
ui.show(modelGroup, minus_one_mesh, "-1")
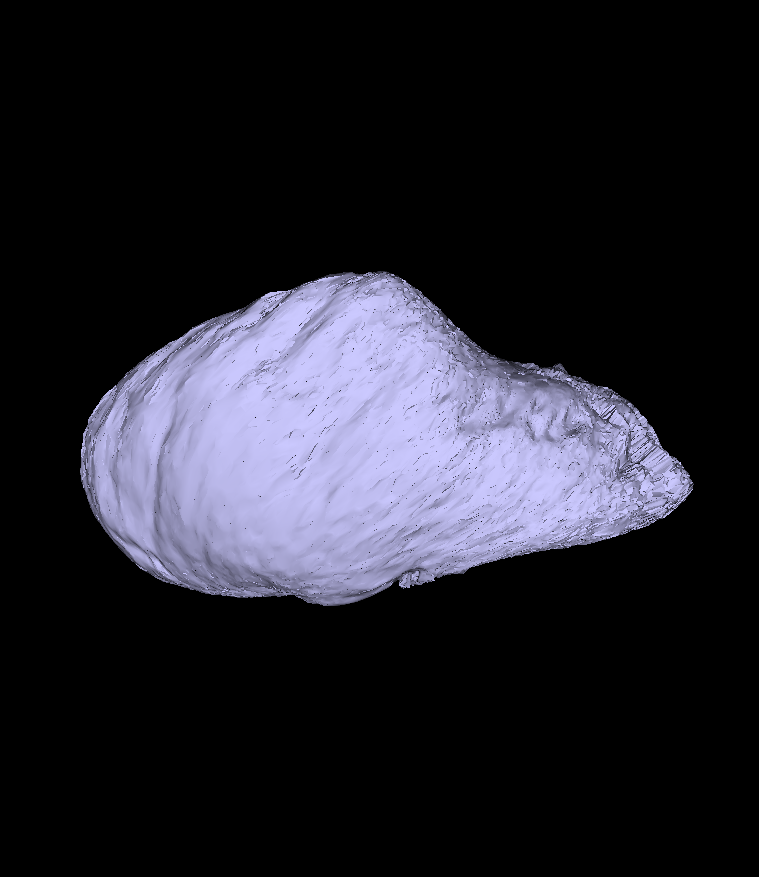
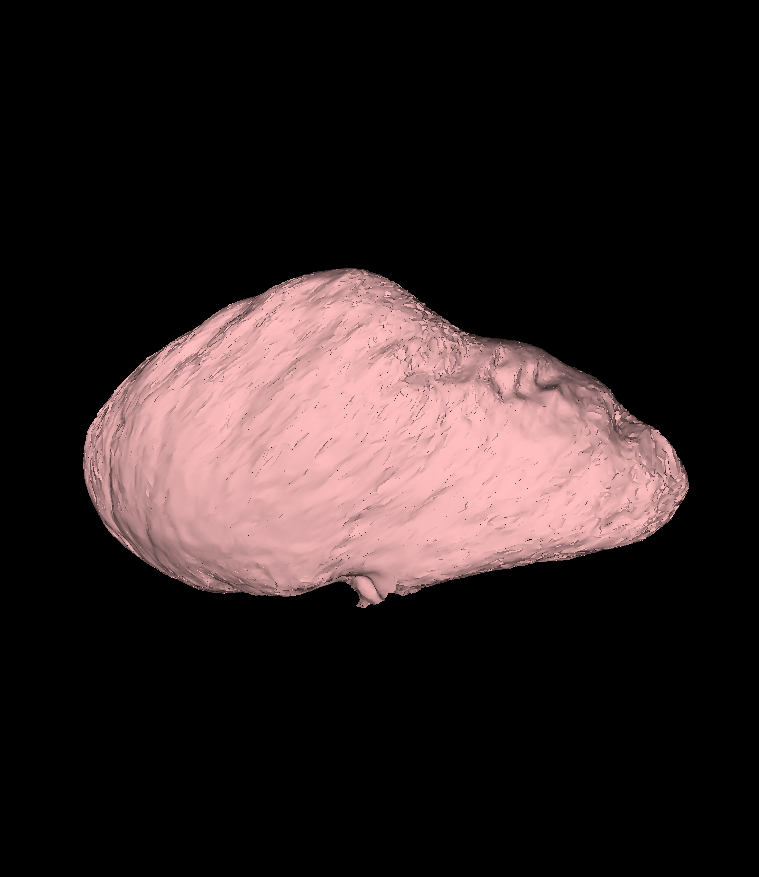
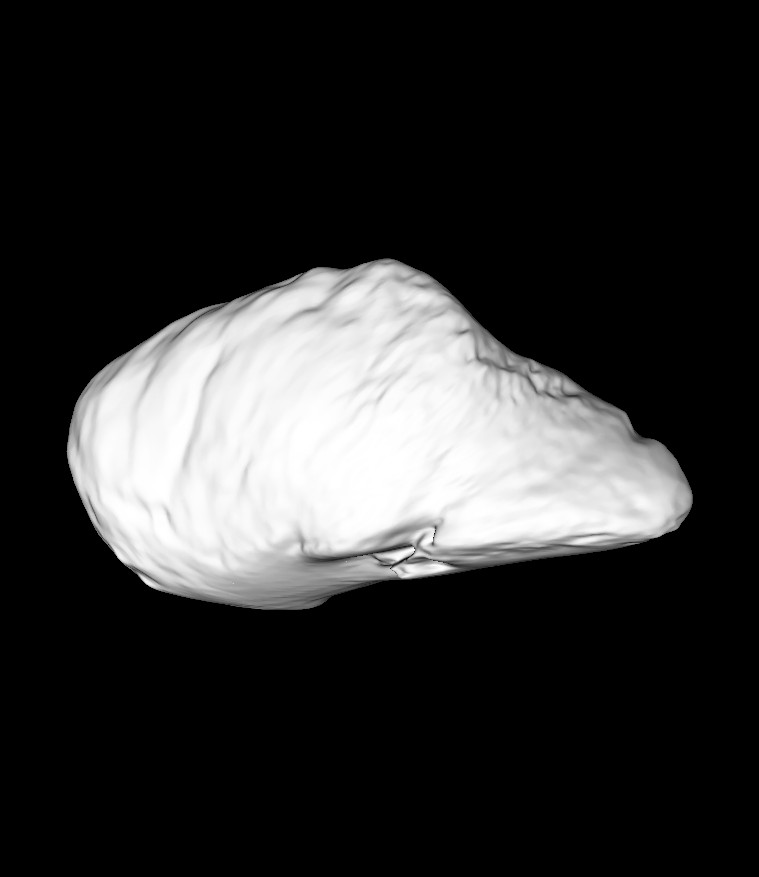
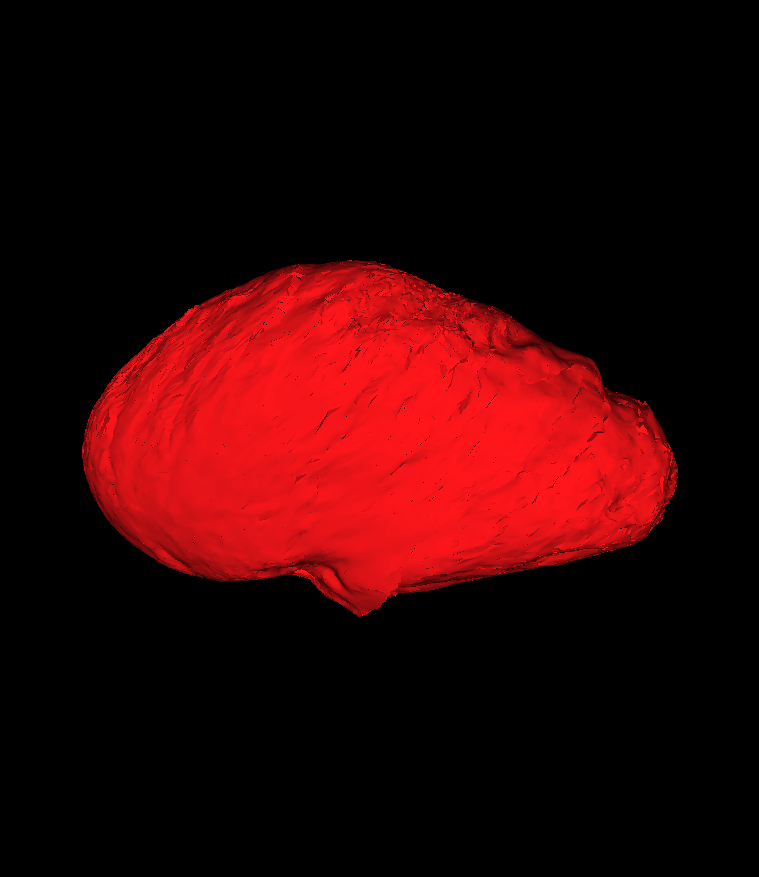
my models generated that are a certain distance from the mean model (i.e. +1, +2, +3 STDs) are almost identical to each other. I have attached some of these figures to show what I mean. In addition, I have found code in the past scalismo conversations about how to calculate model compactness and specificity, but the code that I found prints out the specificity from the last model rank to the first, when I am trying to generate an array from the first to the last:
def computeTotalVarianceFromKLBasis(ssm : StatisticalMeshModel) : Double = {
ssm.gp.klBasis.map(basis => basis.eigenvalue).sum
}
val total_variance = computeTotalVarianceFromKLBasis(ssm)
val specArray = Array[Double]()
val compArray = Array[Double]()
(ssm.rank+0 to ssm.gp.klBasis.length-1 by +1).foreach{rank =>
val reduced_ssm = ssm.truncate(rank)
val sample = reduced_ssm.sample
val compactness = ssm.gp.klBasis.take(rank).map(_.eigenvalue).sum
val dists = meshes.map{mesh=>
val dist = avgDistance(mesh, sample)
dist
}
specArray(rank-1) = min(dists)
compArray(rank-1) = compactness/total_variance
println(rank+" components, result in "+min(dists)+" specificity")
println(rank+" components, result in "+(compactness/total_variance)+" compactness")
}
ssm.gp.klBasis.map(basis => basis.eigenvalue).sum
}
val total_variance = computeTotalVarianceFromKLBasis(ssm)
val specArray = Array[Double]()
val compArray = Array[Double]()
(ssm.rank+0 to ssm.gp.klBasis.length-1 by +1).foreach{rank =>
val reduced_ssm = ssm.truncate(rank)
val sample = reduced_ssm.sample
val compactness = ssm.gp.klBasis.take(rank).map(_.eigenvalue).sum
val dists = meshes.map{mesh=>
val dist = avgDistance(mesh, sample)
dist
}
specArray(rank-1) = min(dists)
compArray(rank-1) = compactness/total_variance
println(rank+" components, result in "+min(dists)+" specificity")
println(rank+" components, result in "+(compactness/total_variance)+" compactness")
}
It's probably something stupid, but what am I doing wrong? Is there an easy method to do a training, and testing split from input data during the model building process in scalismo? Is the purpose of computing leaveoneoutcrossvalidation to create a model to compare your original built ssm to, or is it just another way to model data? Finally, how do you compute sufficiency in scalismo?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Marcel Luethi
Feb 23, 2023, 3:19:49 AM2/23/23
to Gregory Lahman, scalismo
Dear Gregory
Sorry for the late reply. I don't see anything that is wrong with your code and why it does not show the correct variance. Have you tried what happens when you visualize the model directly in Scalismo-UI and put the sliders to the corresponding values (e.g. putting the first slider to -3). Do you see more shape variation? What happens when you just draw random samples? If you see not much variation in the first component, but a lot of variation if you draw random samples?
Regarding your section question: I am not sure that I understand what you mean when you say, it prints out the specificity from the last to the first. What the code does it iteratores over ranks and computes a corresponding low-rank model, for which it computes specificity and compactness. You should see that the values for compactness becomes larger in each iteration, which implies that it captures more variance. Is this what you observe?
As somebody mentioned before, there is a crossvalidation object in Scalismo, which might be useful, if you don't want to manually split your examples into training and test sets. You can find an example how to use it in the corresponding tests:
Best regards,
Marcel
--
You received this message because you are subscribed to the Google Groups "scalismo" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scalismo+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/scalismo/8f3a4ea5-caf0-4dd0-ab04-652493dfe1d6n%40googlegroups.com.
Gregory Lahman
Feb 27, 2023, 9:57:45 AM2/27/23
to Marcel Luethi, scalismo
It seems I was wrong and the images were just to small for me to see the varying morphology.
I don't think leave one out cross validation would be appropriate with my sample size which is now close to 500. That's why I was asking if there is an easy method to do a train test split in scala. I know scikit-learn in python has a built in function.
Did you say how to calculate the model sensitivity?
Marcel Luethi
Feb 28, 2023, 3:28:14 AM2/28/23
to Gregory Lahman, scalismo
Hi Gregory
With such a big dataset, you can just split the data in two, train the model on one and then project all the test data into the model manually, using the project method of the PointDistributionModel. Regarding sensitivity: I am not sure if there is an official way to compute the sensitivity of a model. The way I understand it is that you would like to know how much the model changes when you change the data from which you build the model slightly. You can for example check how the measures such as generalization or compactness change when you use randomly leave out one of your training exanokes,
Best regards,
Marcel
Reply all
Reply to author
Forward
0 new messages