splitting audio files based on amplitude
72 views
Skip to first unread message

विश्वासो वासुकिजः (Vishvas Vasuki)
Jul 17, 2022, 8:48:59 AM7/17/22
to sanskrit-programmers
namo vaH
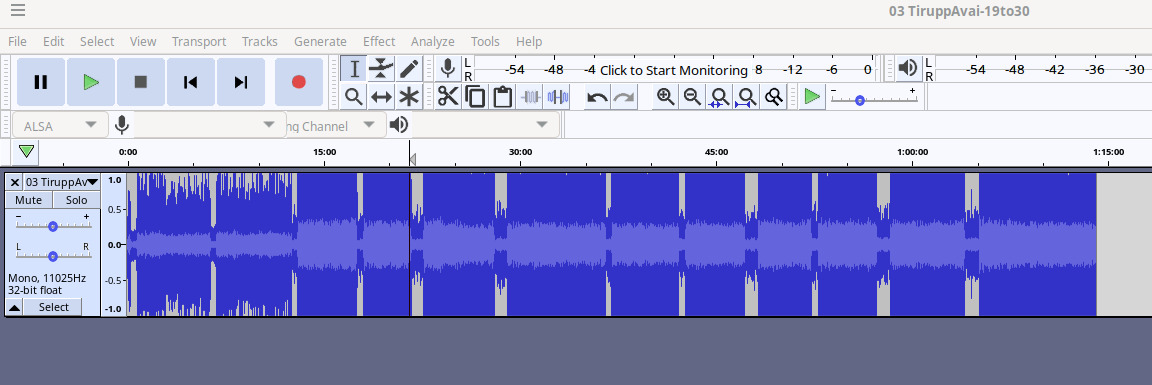
Consider the waveform shown above in audacity. Clear sections can be separated based on amplitude.
This can be separated manually as shown - https://youtu.be/8rYSEaXzepg .
This can (and ideally should) be done programmatically (there are 4000 pairs of files to be made.) But is there an easy way to accomplish it so that writing (or finding or copying) the program itself doesn't take 68 hours (~ time to do it manually)?
This is a general problem - so if someone makes the effort, there is high potential for future use.
This is a general problem - so if someone makes the effort, there is high potential for future use.
--
--
Vishvas /विश्वासः
Vishvas /विश्वासः

Avinash L Varna
Jul 17, 2022, 2:02:06 PM7/17/22
to sanskrit-programmers
I had played around with this a little bit when looking at the audio forced alignment. Doing a gross split is relatively easy. Most of the work will be in fine-tuning what happens in between those sections with large amplitude. Some manual adjustments, or fine-tuning of parameters for a program will invariably be necessary.
In your use case, is it mostly silence? If so, the simplest way to get started is to use the Silence finder in Audacity, since it allows fine-tuning as well. See e.g. https://www.youtube.com/watch?v=jO7Y9OvFRGM
Also, if the text corresponding to the audio is available, then the audio alignment tool can be used to align the text and audio followed by splitting based on some Section in the text.
Thanks
Avinash
--
You received this message because you are subscribed to the Google Groups "sanskrit-programmers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sanskrit-program...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAFY6qgHFKSHiBo50GoNRKkU_OU2sTePVL_zOxQUzbagu2vxvsA%40mail.gmail.com.
विश्वासो वासुकिजः (Vishvas Vasuki)
Jul 17, 2022, 10:18:05 PM7/17/22
to sanskrit-programmers
My use case:
Basically my uncle reading out ( https://drive.google.com/drive/folders/1FMDOZSs3ntq1_cg-BBK6VSz7bpC7YIFG ) a detailed kannaDa commentary https://archive.org/details/divya-prabandha-pratipadArtha/03.%20%20Periyazhwar%20Tirumozhi-second%20century/page/n1/mode/2up mixed with the original sung by TTD paNDitas. There are 4k such verses!
I don't have a typed transcript, which would be required for "forced alignment".
Splitting based on silence detection would not work- silence between small and large amplitude sections have been almost eliminated so as to be undistinguishable from intra-section silences (pic below). Mash up has been too smart!

shrIrAma has suggested
- As for just splitting audio files by amplitude, it should be easy to write some C code to do that if they are in a known format like wav.
- As for just splitting audio files by amplitude, it should be easy to write some C code to do that if they are in a known format like wav.
- Another option is to write macros on protools. The total process for protools would be something like set up markers based on amplitude levels and cut based on markers
- Oh also, sox is very convenient for these kinds of operations
Yet to check out protools and sox.
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAALtx9Z2jhjCjiGLAm6FFGhXMePyZNwqVFNcTPBN0ySUTja_Yg%40mail.gmail.com.

Shreevatsa R
Jul 17, 2022, 11:23:31 PM7/17/22
to sanskrit-programmers
I don't know anything about what tools are out there, but I imagine it should be possible to do something like this:
1. Export some sort of report about the audio file, how much the "amplitude" is at each timestamp.
2. Write some script to analyze this timestamp -> amplitude map, and decide at what points to split.
3. Write another script to split the audio at those timestamps.
(3) is easy (lots of tools: ffmpeg etc), and (2) has some uncertainty but is probably still doable. It is (1) that I don't know how to do.
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAFY6qgHdeGQHdKRAbCSe3hsHHozE1KB%3DJqqJOKNwhEZWwmtycg%40mail.gmail.com.
Avinash L Varna
Jul 18, 2022, 10:45:24 PM7/18/22
to sanskrit-programmers
IMHO (2) is more difficult, since there are always some heuristics involved and may require some tuning per audio file.
Here is a sample script that essentially does what you asked for - https://gist.github.com/avinashvarna/d05668d7f720f249c843480826d6a30c
In my experiment (note the singular :)), it seemed to work reasonably well, given the 1s window resolution I picked. You may have to play with the parameters for each audio file and YMMV. An improvement would be to export the indices that are generated into a tsv, import them into Audacity as labels, manually fine-tune the boundaries, and then split using Audacity. This will still require some manual effort, but might serve as a good bootstrapping to reduce the overall time required.
Another possibility for your use case, since the different segments are by different speakers is to use Speaker Diarization. It will likely be slower, but could be more precise if the separation is good. pyAudioAnalysis has an implementation + docs. You could give that a try as well.
Hope this helps!
Thanks
Avinash
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAKEM%3DPPtKYvD%2B5xRuZ8%2BAL-FTcSFu74HZ3Sed_1Ar0ZA5j_ZWw%40mail.gmail.com.
Shreevatsa R
Jul 19, 2022, 12:18:16 AM7/19/22
to sanskrit-programmers
Thanks for sharing that script! Very informative.
Yes the heuristics are the most ambiguous part and the easiest to underestimate; guess I've done just that. :-)
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAALtx9awi24VQiHoSHPp3Bz8fyTdw6zpKnWg89dDVYp1KzZjBw%40mail.gmail.com.
विश्वासो वासुकिजः (Vishvas Vasuki)
Jul 20, 2022, 2:31:05 AM7/20/22
to sanskrit-programmers
धन्योऽस्मि!
To view this discussion on the web visit https://groups.google.com/d/msgid/sanskrit-programmers/CAALtx9awi24VQiHoSHPp3Bz8fyTdw6zpKnWg89dDVYp1KzZjBw%40mail.gmail.com.
Reply all
Reply to author
Forward
0 new messages