Scribe configuration for NYC Marriage Index

Ben Brumfield
(Scribe is not the only possible solution for indexing these records, but efforts relying on other platforms should start their own threads.)
Ben W. Brumfield
http://manuscripttranscription.blogspot.com/
Ben Brumfield
Target Data:
According to Brooke, researchers will use this index to order copies of records from the NYC Municipal Archives as follows:
It also seems possible to me that researchers might find the name of a bride, then use the vol/page/doc numbers to find the name of a groom, or vice-versa. I do not know enough about the sources to say whether this cross-correlation would work, however.
Sources:
I spot-checked 13 rolls, choosing the ones that appeared on the left column of the Internet Archive collection listing.
Brooklyn 1919:
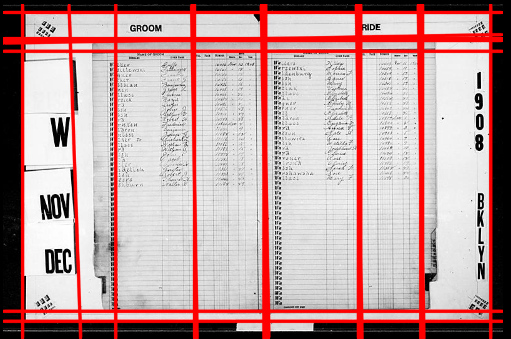
- The photographs was made of an entire opening, rather than a single page. As a result, any given horizontal band may have two records rather than one.
- Verso pages contain listings for the groom, recto for the bride.
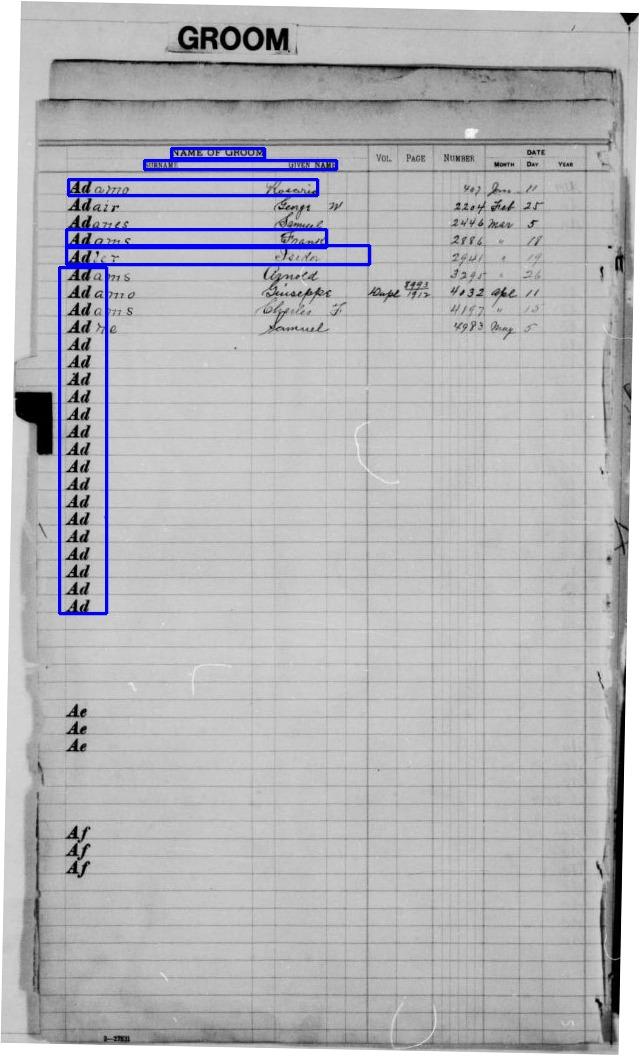
- Bride and groom entries on the same line of same opening are not correlated -- the surname is the bride's maiden name, so the two names appearing on the same horizontal band of the opening do not represent the couple in the wedding. (See "leaf" 10 for an example of bride entries with no groom entries on the same line.)
Codicology:
The books appear to be organized as follows:
- A series records documents within a year. The microfilm reels on the Internet archive contain one series per reel.
- Records from that year are divided by surname range (from "A" to "XYZ") into volumes (e.g. 1919 B)
- Each volume contains several quires, each quire recording between one and four months of entries. (eg. 1919 B Jan-Mar precedes B Apr-Jun, B Jul-Sep, B Oct-Dec, and then B Dec.)
- Each quire is divided into pre-printed surname sub-ranges -- "Aa", "Ab", etc. The number of entries in each subrange varies according to the printer's understanding of the distribution of spelling of English surnames: twoscore entries for "Cz" follows three entries for "Cy", ten entries for "Cv", forty for "Cu" and fifty for "Cr". (Note also the clerk manually filling in a "Cw" entry here.) The chronological length of the quires appears to be irregular -- my suspicion is that when the longest sub-range ran out of room in a quire, the clerk would grab a new blank notebook and start a new range.
- Each entry contains the following fields:
- Name of (Bride|Groom)
- Surname
- Given Name
- Vol
- Page
- Number
- Date
- Month
- Day
- Year
The microfilming recorded the beginning of each volume with some kind of marker frame (sorry that I don't know the terminology here), as in this "Start B File" slide. It appears that no attempt was made to photograph covers, spines, front-matter or end-matter. That's unfortunate, since it loses context, but it will simplify the data model.
Brooklyn 1929: identical
Manhattan 1917: identical (however note this page of G entries inserted in the middle of XYZ Jun-Sep)
Manhattan 1909:
The microfilm begins with this warning:
Each month(s) time section
May be taken from 2 books-
(2) - Even number license
time section may be in
2 parts.
There is an occasional
exception wherein a month(s)
time perion[sic] was only one
book
Unlike the other registers, this microfilm photographed a page at a time, rather than a two-page opening.
As predicted by the warning, two quires record A Jan-Mar, in a series, the quire with odd-numbered documents preceding the one indexing even-numbered documents.
This roll ends with a MISC volume containing random pages.
Manhattan 1924: Identical to Brooklyn 1919
Manhattan 1919: Identical to Brooklyn 1919
Brooklyn 1924: Identical to Brooklyn 1919
Manhattan 1911:
Begins with this document:
Each volume is made
up of two books,
odd and even numbers.
Therefore each alphabet
is in two parts.
Manhattan 1914:
Identical to Brooklyn 1919, however several entries have "NO RETURN" stamped on them after the surname. See XYZ Nov-Dec Z p2 for an example.
Does anyone know what this means? Brooke?
It certainly seems like a datum worth transcribing.
Bronx 1921: Identical to Brooklyn 1919
Bronx 1922: Identical to Brooklyn 1919
Bronx 1927: Identical to Brooklyn 1919
Queens 1910: Identical to Brooklyn 1919
Ben

Tom Morris
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Ben Brumfield
My responses inline:
On Sunday, April 10, 2016 at 9:20:53 AM UTC-5, Tom Morris wrote:
- correlating couples by marriage license volume, (page), and number should work, as I understand the system. Date can be used as a cross-check. Of course this isn't really very solid evidence in the absence of an image of the original document with both names present, but it's a good hint.
- The microfilm start of book thing is called a "target" as far as I know.
- Good point about retaining context, but rather than segmenting a page using OpenCV, I think it'd be better to mark the zones/fields and then do the transcription in situ. Regardless, there's a decision to be made as to whether do verbatim transcription or not. I'd lean towards verbatim with interpretation done as a separate step.
Looking over the Scribe documentation, it seems like we could populate the database with each image as "Primary Subjects", then use OpenCV to fake out "Secondary Subjects". If we were doing this manually, the Primary subjects would request a drawing task which would ask volunteers to highlight each line, which would then create such secondary subjects. It looks like the next step there is for someone with a Scribe instance running to do some drawing, then post what a "secondary subject" looks like in the database.
- As for NO RETURN, remembering that this is an index of marriage license APPLICATIONS, I suspect that the "no returns" are those who never actually returned a completed license (ie didn't get married).
- I note that there's no page numbering in the volumes I checked. That'll make it more difficult to catch page misses (although the pre-printed letters help).
(see https://iiif.archivelab.org/iiif/NYC_Marriage_Index_Manhattan_1914/manifest.json for an example)
- There's volume metadata, page scan metadata, raw images in both JPEG2000 & TIFF format, etc available by clicking on the "details" link e.g. https://archive.org/download/NYC_Marriage_Index_Brooklyn_1919
That means that we can deep-link directly to regions of the image:
https://iiif.archivelab.org/iiif/NYC_Marriage_Index_Manhattan_1914$1103/900,2030,2100,130/full/0/default.jpg
should retrieve page 1103, at a region 900x2030 pixels from the upper left, grabbing a section 2100 pixels wide by 130 high.
Which it does!
![]()
- There's no OCR data (*_abby.gz) available because the language was set to "english-handwritten", but the volumes could be run through Tesseract to pick up any of the pre-printed info, if that was deemed useful.
- All items are part of the NY Marriage Index collection (somewhat misleading since it's an index to marriage license *applications*, not marriages)- Years 1911-1913 show as only have films for Brooklyn in the year facet, but there are other films (e.g. Queens 1911, Manhattan 1911-1913) available, but missing from the facet- Queens only has films for 1908-1911- Bronx runs 1914 - 1929- Manhattan & Brooklyn run 1908-1929I could write a quick Python script to download and summarize the metadata to generate page counts, etc if that would be useful for planning purposes.
Ben
Tom
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+unsubscribe@googlegroups.com.

Justin York
Tom
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
Ben Brumfield
Ben Brumfield
1) Create a git repository under rootsdev for sample data and configurations only? ScribeConfigNYCMarriages, containing project directories and test data directories?
2) Fork the entire ScribeAPI repository from zooniverse to rootsdev, then create a new branch for this work, with project directories in the working location and test_data directories somewhere that seems to make sense?
3) Something else?
Ben
Justin York
--
Tom Morris
Ben Brumfield
Ben Brumfield
Tom Morris
Reading a bit more, it looks like the subject configuration files under /projects would live pretty comfortably in our fork, though we probably want them in a separate branch, and to do any generally-useful stuff in a different branch without config information so that we can actually issue pull requests.
Tom Morris
--
Ben Brumfield
Tom Morris
Ben Brumfield
order,file_path,thumbnail,capture_uuid,page_uri,book_uri,source_rotated,width,height,source_x,source_y,source_w,source_h
-
order- Integer - the sequence of the subjects -
file_path- String - the URL to the full media file -
thumbnail- String - the URL to the thumbnail image of the media file -
width- Integer - width in pixels of media file -
height- Integer - height in pixels of media file
Did I miss something in the docs, or will we need to do code archaeology to figure this out? Regardless, I'm just using some stub values for the things I don't understand so I can try to get something checked in tonight.
Ben
Tom Morris
Ben Brumfield
Justin York
Tom Morris
For those of us that don't know anything about Ruby or Scribe, is there any way to help with the technical side?
Ben Brumfield
I'd love to see a way of detecting actual lines of text from an index, which seems like a common enough task that someone in the Computer Vision world has figured it out already.

Brooke Ganz
Ben Brumfield
# ingest NYC_Marriage_Index_Brooklyn_1919 from the Internet Archive. This will
# 1) create project/marriages/subjects/group_nyc_marriage_index_brooklyn_1919.csv and
# 2) print a line to be appended to project/marriages/subjects/groups.csv
rake project:subject_from_archive[marriages,NYC_Marriage_Index_Brooklyn_1919]
Having done that, running rake project:reload[marriages] loads the subjects into the system.
The one thing I don't understand is why the images aren't displaying once I run
rails sTom, would you have time to take a look at the csv file and compare it to the one you hand-coded? I went ahead and checked in the modified groups.csv file and the new subject file for Brooklyn 1919.
Ben
Ben
Ben Brumfield
Ben
Tom Morris
I agree with Tom, and in particular with his recommendation of #2. The Scribe folks recommend OpenCV, which I've never used -- I gather it's a python library?
I'd love to see a way of detecting actual lines of text from an index, which seems like a common enough task that someone in the Computer Vision world has figured it out already.
Tom Morris
Now that the weekend is over and I need to get back to work, I've pushed my rake task to generate Scribe subjects from the Internet Archive.
# 1) create project/marriages/subjects/group_nyc_marriage_index_brooklyn_1919.csv and
# 2) print a line to be appended to project/marriages/subjects/groups.csv
rake project:subject_from_archive[marriages,NYC_Marriage_Index_Brooklyn_1919]
Having done that, running rake project:reload[marriages] loads the subjects into the system.
The one thing I don't understand is why the images aren't displaying once I run
Tom, would you have time to take a look at the csv file and compare it to the one you hand-coded? I went ahead and checked in the modified groups.csv file and the new subject file for Brooklyn 1919.
Justin York
--
Tom Morris
Justin York
It might be a good idea to switch the default branch of our fork to be the `marriages` fork (I don't have privileges to do that). We could also consider enabling the Github issue tracker for the repo when we get a little further along and use it for tracking issues specific to the marriages fork/project.
Justin York
Ben Brumfield
Justin York
--
Tom Morris
Is the project ready for people to try out, so we can come up with needs beyond the ones we've already mentioned?

todd.d....@gmail.com
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Tom Morris
Looking good everyone! Should I hold off on QA for things like UI bugs?
Justin York
I know it's a little difficult to design/comment in the abstract without knowing what's easy and what's hard to do in Scribe, but you can take a look at the Emigrants Bank, Old Weather, etc projects to get an idea. Perhaps we could also put together a small smorgasbord of example workflows that people could play with to get an idea of what's possible (e.g. using the table row marker, rather than the cell marker).
Also, making even a rough start depends on getting our image processing pipeline in place which no one has signed up to tackle yet. I've got some ideas on rough building blocks, but haven't had a chance to experiment with them yet. We need square, vertical, & true images to work well with the Scribe marking tools, which also implies that we need to separate the left and right pages since they often need different amounts of rotation.
todd.d....@gmail.com
Could you create issues in Github to start the conversation on those tasks?

Matthew LaFlash
--
---
You received this message because you are subscribed to a topic in the Google Groups "rootsdev" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rootsdev/Sd1_h_f8o6Y/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rootsdev+u...@googlegroups.com.
Ben Brumfield
Tom's recommended an approach based on Hough line detection, which I did not attempt but which sounds very promising.
After talking the problem over with Chad Bailey, we talked about using OCR to identify the entry header letters and use them to anchor the entry. So I pulled down an image, cropped out the Groom page, deskewed, and tried running tesseract on the results.
The results were discouraging. Tesseract did a fine job of identifying the location of the header texts, which might be useful for extrapolating the page layout. It did a mediocre job on the entry heading letters. Actually recognizing the text was a total failure.
All of this was done with a totally untrained tesseract. Were I to continue this approach, I'd want to find training sets that match the fonts in the pages, or to create them using a methodology similar to the eMOP project.
So I'd say that OCR isn't a dead end, but it's not a quick solution either.
I'll attach the hocr file tessersact produced as well as a couple of images showing bounding boxes for lines and words.
Ben
Ben Brumfield

{kind=link}
{kind=link}
Justin York
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
Ben Brumfield
Tom Morris
Justin York
Tom I am particularly interested to hear why you think splitting the pages will boost performance. It appears that your the only one recommending that we split pages. I have no opinion on it test so I would like more detail on the benefits.
Ben Brumfield
Is that right? If so, it should be testable.
Tom Morris
Tom I am particularly interested to hear why you think splitting the pages will boost performance. It appears that your the only one recommending that we split pages. I have no opinion on it test so I would like more detail on the benefits.
I think that Tom's main concern is load on the Internet Archive servers to handle scaling, rotating, and cropping.
Tom Morris
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
Tom Morris
Brooke Ganz
So researchers will be searching on names, dates and borough to find volume number, page number, document number, and document date.
It also seems possible to me that researchers might find the name of a bride, then use the vol/page/doc numbers to find the name of a groom, or vice-versa. I do not know enough about the sources to say whether this cross-correlation would work, however.
Identical to Brooklyn 1919, however several entries have "NO RETURN" stamped on them after the surname. See XYZ Nov-Dec Z p2 for an example.
Does anyone know what this means? Brooke?
It certainly seems like a datum worth transcribing.
Justin York
Tom Morris
Tom Morris
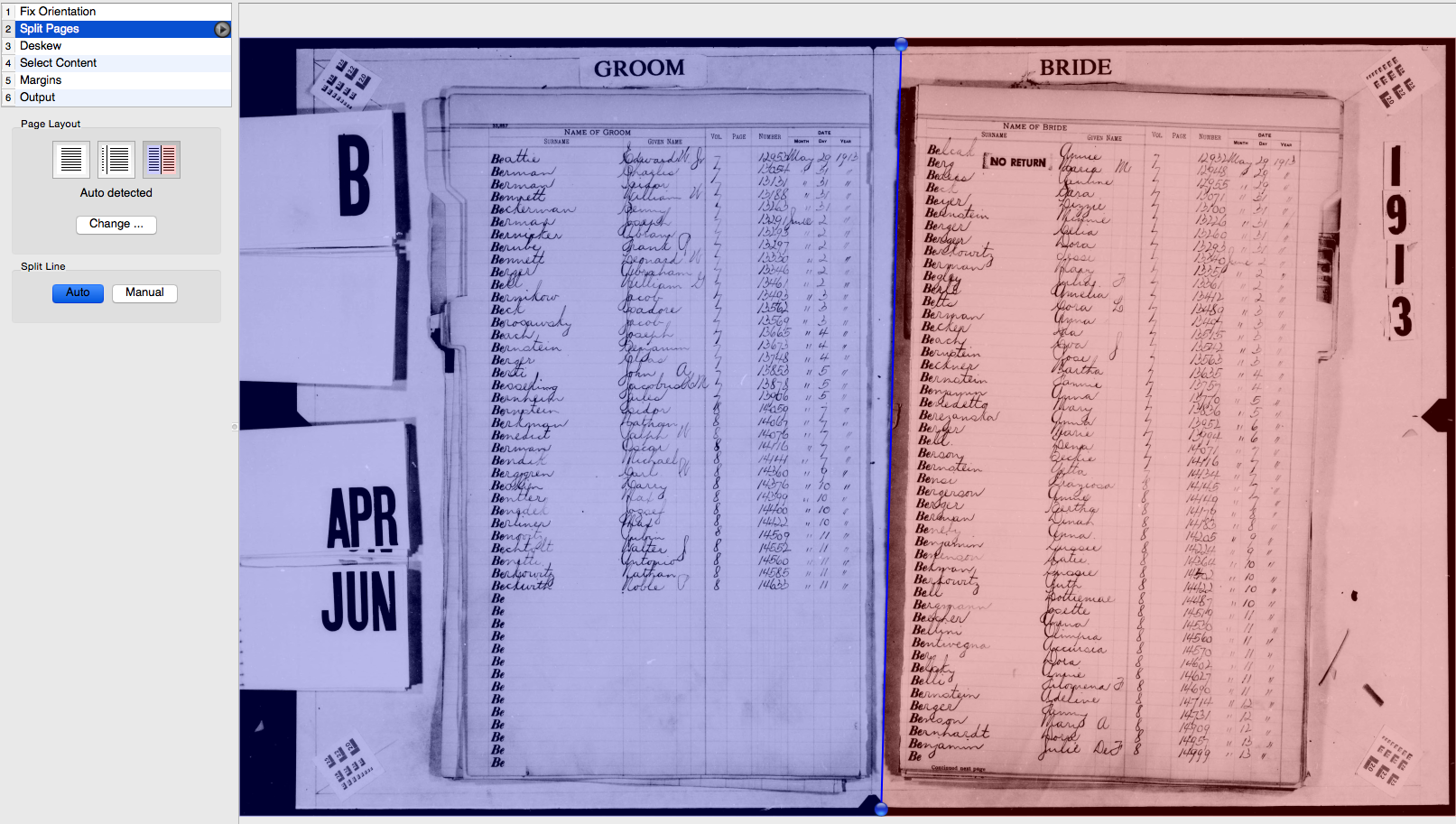
Tom Morris


Tom Morris
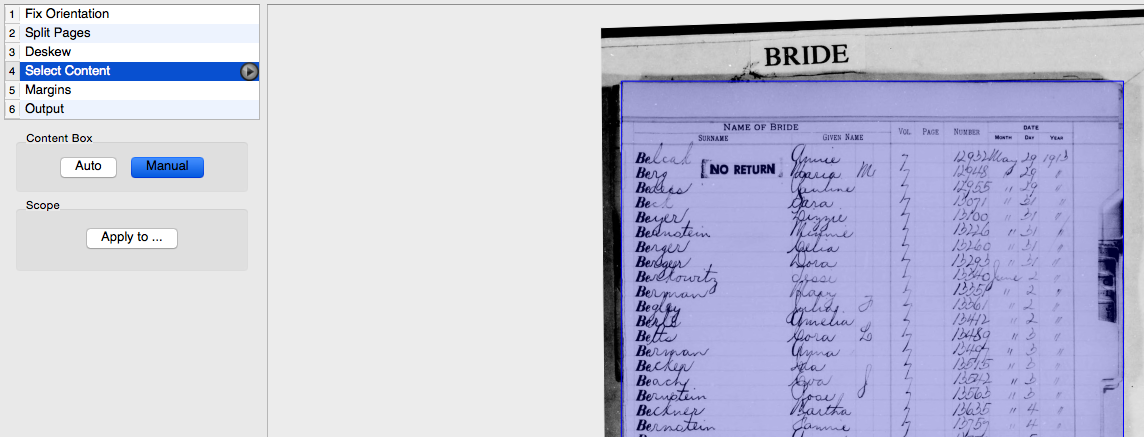

Tom Morris
Justin York
Ben Brumfield
1) Calculating ROIs based on page layout. We all know that the drawing task will be a deal-breaker, so we have to calculate ROIs in a pre-processing phase.
Since these documents are so consistent, we should be able to calculate fields geometrically if we're given the corners of a single page. While I have no insights on identifying corners (though it looks like Tom does), I was able to create a script to identify rectangles and draw them on a local image: https://github.com/rootsdev/scribeAPI/blob/marriages/lib/tasks/image_preprocess.rake
An example result is here:

The next step on this is to remove the image-drawing code (really only useful for debugging purposes) and instead use the rectangles to create secondary subjects withing the Scribe database. (That still leaves the questions of actually getting the page layout correct, dealing with skew at presentation time, and not presenting blank images to users, all of which are major challenges that Tom may be better able to address.)
2) Exposing transcripts via IIIF/OpenAnnotation. While I'm interested in publishing the indexed records via stand-alone, web-based search engines like MyopicVicar or through researcher-friendly bulk downloads as CSVs, the IIIF connection gives us the ability to anchor genealogy records within the Linked Open Data world. I've added a new controller that exposes transcribed volumes as IIIF manifests, exposes pages as SharedCanvas canvases, and exposes transcribed ROIs as OpenAnnotation annotationLists on the canvases.
Example AnnotationList:
{
"@context": "http://iiif.io/api/presentation/2/context.json",
"@id": "http://localhost:3000/iiif/list/5756379da020dd53e83fe0e3",
"@type": "sc:AnnotationList",
"resources": [
{
"@id": "http://localhost:3000/iiif/list/5756379da020dd53e83fe0e3/annotation/5756ad2ba020dd5a893a80fe/em_number",
"@type": "oa:Annotation",
"motivation": "sc:painting",
"on": "https://iiif.archivelab.org/iiif/NYC_Marriage_Index_Manhattan_1908$2077/#xywh=1307,361,100,42",
"resource": {
"@id": "em_number_5756ad2ba020dd5a893a80fe",
"@type": "cnt:ContentAsText",
"format": "text/plain",
"chars": "7259"
}
},
{
"@id": "http://localhost:3000/iiif/list/5756379da020dd53e83fe0e3/annotation/5756ad38a020dd5a893a8100/em_number",
"@type": "oa:Annotation",
"motivation": "sc:painting",
"on": "https://iiif.archivelab.org/iiif/NYC_Marriage_Index_Manhattan_1908$2077/#xywh=1307,399,103,39",
"resource": {
"@id": "em_number_5756ad38a020dd5a893a8100",
"@type": "cnt:ContentAsText",
"format": "text/plain",
"chars": "7523"
}
},At this point, if you re-generate a group of subjects from a volume, load it into a clean Scribe database, and do some transcribing you can use an IIIF client like Mirador to view the results:
![]()
To try this out, go to http://projectmirador.org/demo and close one of the viewer panes, then select "New object" from the menu and add a URL corresponding to http://localhost:3000/iiif/manifest/nyc_marriage_index_manhattan_1908 to the input field. Clicking on the item that loads will re-open the viewer pane on the marriage application index volume. Clicking the two word balloons will display ROIs and text from the transcripts.
I'll be demoing this to the IIIF group today on their community call at 11am central (notes doc), and am hoping for some advice and maybe some help from that group. I'm definitely a newbie to linked open data, but if other people have ideas for ways genealogy tools can use records presented as LOD, I'm all ears.
Ben
text
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+unsubscribe@googlegroups.com.
todd.d....@gmail.com
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
--
---
You received this message because you are subscribed to the Google Groups "rootsdev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rootsdev+u...@googlegroups.com.
Tom Morris
Thanks Tom for looking at scantailor. It looks like a nice solution.We might need the ROI metadata no matter how the images are hosted. I think there's value in being able to correlate the data we publish with the original images hosted in Internet Archive. If the data we publish can only be understood in the context of the images we modify and host for indexing then we either host the images forever or our data loses value sometime in the future. I don't like either of those options.