Gerrit clone time takes ages, because of PackWriter.searchForReuse()
131 views
Skip to first unread message

Luca Milanesio
Oct 1, 2020, 5:51:33 PM10/1/20
to JGit Developers list, Repo and Gerrit Discussion, Luca Milanesio
Hi all,
I am writing to both JGit and Gerrit mailing list, because the problem is found when using Gerrit *BUT* can be relevant to JGit developers and users as well.
I have a situation where *certain* Git fetches are taking 10x to 100x of the expected execution time.
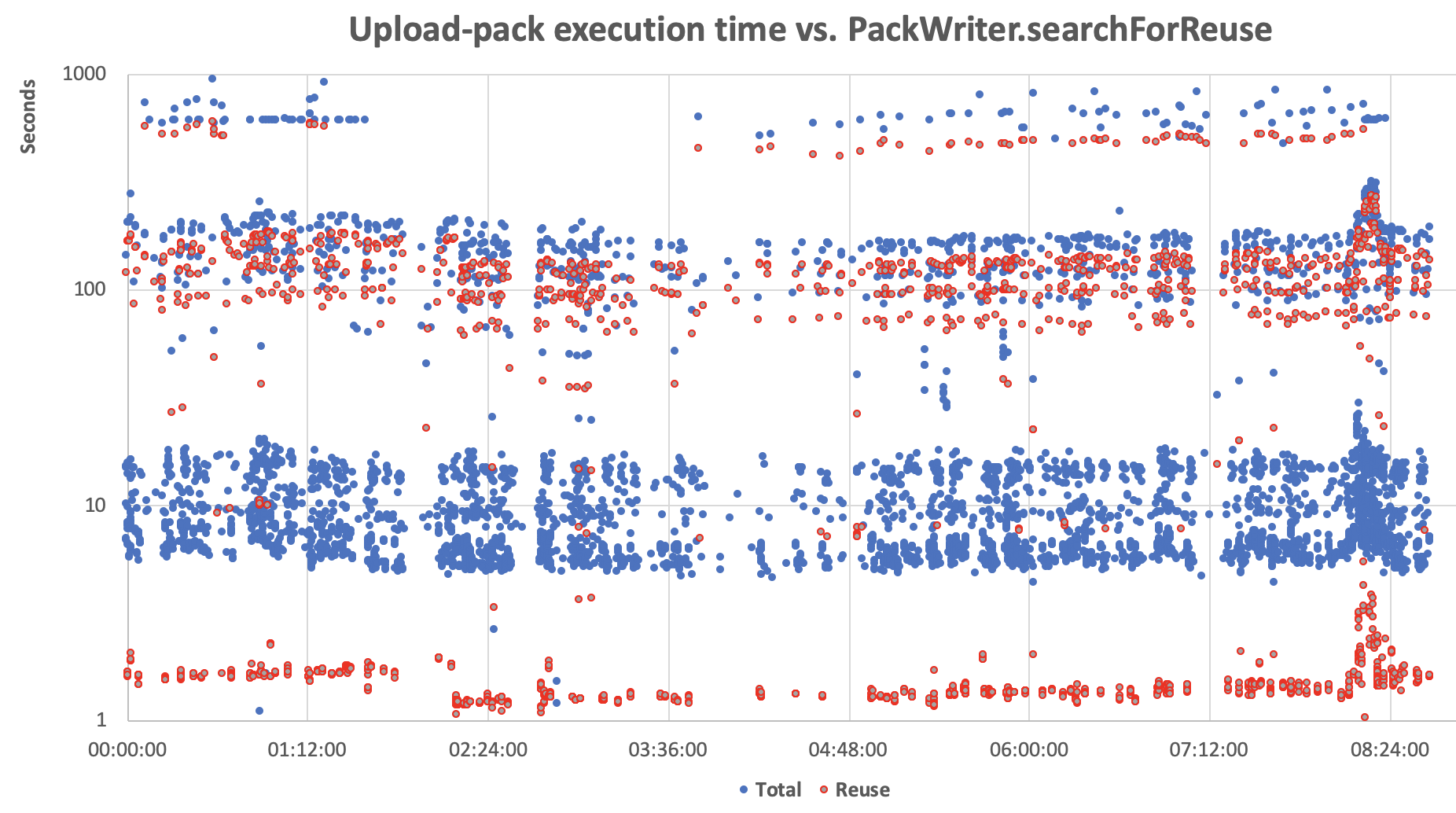
The blue dots represent the total execution time of the upload-pack, whilst the red dots represent the time for searching for objects reuse in existing packfiles.
The normal expected execution time is the blue band around 10s. The slower execution times are the one over 100s and the *super slow* execution times are the ones coming up to 1000s.
The repository is *exactly the same* for all those upload-pack executions.
Looking at the code called by the searchForReuse, I ended up in:
@Override
public void selectObjectRepresentation(PackWriter packer,
ProgressMonitor monitor, Iterable<ObjectToPack> objects)
throws IOException, MissingObjectException {
for (ObjectToPack otp : objects) {
db.selectObjectRepresentation(packer, otp, this);
monitor.update(1);
}
}
The above is a cycle for *all* objects that goes into the another scan for *all* packfiles inside the selectObjectRepresentation().
The slow clones were going through 2M of objects on a repository with 4k packfiles … the math would say that it went through a nested cycle of 2M x 4k => 8BN of operations.
I am not surprised it is slow after all :-)
So, it looks like it works the way it is designed: very very slowly.
My questions on the above are:
1. Is there anyone else in the world, using Gerrit or JGit, with the same problem?
2. How to disable the search for reuse? (Even if I disable the reuseDelta or reuseObjects in the [pack] section of the gerrit.config, the searchForReuse() phase is trigged anyway)
3. Would it make sense to estimate the combination explosion of the phase beforehand (it is simple: just multiply the number of objects x number of packfiles) and automatically disable that phase?
Comments and experiences are more than welcome :-)
I am writing to both JGit and Gerrit mailing list, because the problem is found when using Gerrit *BUT* can be relevant to JGit developers and users as well.
I have a situation where *certain* Git fetches are taking 10x to 100x of the expected execution time.
The blue dots represent the total execution time of the upload-pack, whilst the red dots represent the time for searching for objects reuse in existing packfiles.
The normal expected execution time is the blue band around 10s. The slower execution times are the one over 100s and the *super slow* execution times are the ones coming up to 1000s.
The repository is *exactly the same* for all those upload-pack executions.
Looking at the code called by the searchForReuse, I ended up in:
@Override
public void selectObjectRepresentation(PackWriter packer,
ProgressMonitor monitor, Iterable<ObjectToPack> objects)
throws IOException, MissingObjectException {
for (ObjectToPack otp : objects) {
db.selectObjectRepresentation(packer, otp, this);
monitor.update(1);
}
}
The above is a cycle for *all* objects that goes into the another scan for *all* packfiles inside the selectObjectRepresentation().
The slow clones were going through 2M of objects on a repository with 4k packfiles … the math would say that it went through a nested cycle of 2M x 4k => 8BN of operations.
I am not surprised it is slow after all :-)
So, it looks like it works the way it is designed: very very slowly.
My questions on the above are:
1. Is there anyone else in the world, using Gerrit or JGit, with the same problem?
2. How to disable the search for reuse? (Even if I disable the reuseDelta or reuseObjects in the [pack] section of the gerrit.config, the searchForReuse() phase is trigged anyway)
3. Would it make sense to estimate the combination explosion of the phase beforehand (it is simple: just multiply the number of objects x number of packfiles) and automatically disable that phase?
Comments and experiences are more than welcome :-)
P.S. I am planning to prepare a patch for implementing 3. If we believe it’s a good idea to auto-disable the phase.
Luca.

Martin Fick
Oct 1, 2020, 6:44:32 PM10/1/20
to repo-d...@googlegroups.com, Luca Milanesio, JGit Developers list
On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> Looking at the code called by the searchForReuse, I ended up in:
>
> @Override
> public void selectObjectRepresentation(PackWriter packer,
> ProgressMonitor monitor, Iterable<ObjectToPack> objects)
> throws IOException, MissingObjectException {
> for (ObjectToPack otp : objects) {
> db.selectObjectRepresentation(packer, otp, this);
> monitor.update(1);
> }
> }
>
>
> The above is a cycle for *all* objects that goes into the another scan for
> *all* packfiles inside the selectObjectRepresentation().
>
> The slow clones were going through 2M of objects on a repository with 4k
> packfiles … the math would say that it went through a nested cycle of 2M x
> 4k => 8BN of operations. I am not surprised it is slow after all :-)
Yes, it is terrible to have 4K pack files (or even 300) in a repo. It clearly
> Looking at the code called by the searchForReuse, I ended up in:
>
> @Override
> public void selectObjectRepresentation(PackWriter packer,
> ProgressMonitor monitor, Iterable<ObjectToPack> objects)
> throws IOException, MissingObjectException {
> for (ObjectToPack otp : objects) {
> db.selectObjectRepresentation(packer, otp, this);
> monitor.update(1);
> }
> }
>
>
> The above is a cycle for *all* objects that goes into the another scan for
> *all* packfiles inside the selectObjectRepresentation().
>
> The slow clones were going through 2M of objects on a repository with 4k
> packfiles … the math would say that it went through a nested cycle of 2M x
> 4k => 8BN of operations. I am not surprised it is slow after all :-)
needs to be repacked (but you knew that)!
> So, it looks like it works the way it is designed: very very slowly.
>
> My questions on the above are:
> 1. Is there anyone else in the world, using Gerrit or JGit, with the same
> problem?
repo with 4K to perform atrociously! We have certainly experienced it and we
avoid it!
> 2. How to disable the search for reuse? (Even if I disable the
> reuseDelta or reuseObjects in the [pack] section of the gerrit.config, the
> searchForReuse() phase is trigged anyway) 3. Would it make sense to
> estimate the combination explosion of the phase beforehand (it is simple:
> just multiply the number of objects x number of packfiles) and
> automatically disable that phase?
problem is not short circuiting the search when one it found? If I remember
correctly, the loop searches for all the possibilities to attempt to find the
best one. So I do believe that some mechanism to short circuit this is needed,
not just for the degenerate case of a repo that has not been repacked.
We have repos that we call siblings, they share objects via the alternatives
mechanisms. They are different copies of the kernel/msm repo. Each copy
points to the other copy via alternatives. When they get repacked, each one
ensures that it has a copy of all the objects it references, and since there
is a lot of shared history in these repos, the main objects are in many of
these repos. In the past, I measured clones to take along the lines of 20%
longer for each alternative than if there were no alternatives. I tracked it
down to this same problem. I welcome a solution in this area.
My thoughts for solving this it to introduce ways to short circuit. Of course,
short circuiting could lead to subpar performance in some cases too, so it is
tricky. I would guess that once a delta is found, it would usually make sense
to just send it. If however a non deltafied copy is found, it might still be
worth looking a bit further for a deltafied one, maybe a configurable amount,
one or two?
To make short circuiting work well, I believe it would make sense to order the
packfiles in a way that fewer searches are likely to be needed before finding
an object. I have thought about ordering based on dates, older packfiles are
more likely to have deltas of more(most) objects. Similarly, the largest
packfiles are also more likely to have deltafied objects in them since the
largest packfiles are likely the ones that have been repacked, whereas small
ones are likely to be new pushes which are more likely to have been thickened
(which removes some deltas) on receipt of the pack. Additionally it might make
sense to dynamically sort the packs based on the results of the searches
themselves. As certain packfiles start to shine as the best candidates, they
would get searched first. This might help transition well from packfile to
packfile dynamically, especially with large object counts (clones), or if they
have "islands" in them.
Lastly, what does git do in this situation? What tradeoffs, if any, does it
make when deciding which copy of an object to send?
> P.S. I am planning to prepare a patch for implementing 3. If we believe it’s
> a good idea to auto-disable the phase.
-Martin
--
The Qualcomm Innovation Center, Inc. is a member of Code
Aurora Forum, hosted by The Linux Foundation
Luca Milanesio
Oct 1, 2020, 6:51:10 PM10/1/20
to Martin Fick, Luca Milanesio, repo-d...@googlegroups.com, JGit Developers list
Thanks, Martin, for the prompt reply.
> On 1 Oct 2020, at 23:44, Martin Fick <mf...@codeaurora.org> wrote:
>
> On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
>> Looking at the code called by the searchForReuse, I ended up in:
>>
>> @Override
>> public void selectObjectRepresentation(PackWriter packer,
>> ProgressMonitor monitor, Iterable<ObjectToPack> objects)
>> throws IOException, MissingObjectException {
>> for (ObjectToPack otp : objects) {
>> db.selectObjectRepresentation(packer, otp, this);
>> monitor.update(1);
>> }
>> }
>>
>>
>> The above is a cycle for *all* objects that goes into the another scan for
>> *all* packfiles inside the selectObjectRepresentation().
>>
>> The slow clones were going through 2M of objects on a repository with 4k
>> packfiles … the math would say that it went through a nested cycle of 2M x
>> 4k => 8BN of operations. I am not surprised it is slow after all :-)
>
> Yes, it is terrible to have 4K pack files (or even 300) in a repo. It clearly
> needs to be repacked (but you knew that)!
Yeah, and the GC of the repo solves the problem … but that takes time (this is a *veeeery big* repo) and during the day pack files are piling up again.
So the problem is really *in between* GC cycles.
>
>> So, it looks like it works the way it is designed: very very slowly.
>>
>> My questions on the above are:
>> 1. Is there anyone else in the world, using Gerrit or JGit, with the same
>> problem?
>
> Well, I do think most people (especially you know) that you should expect a
> repo with 4K to perform atrociously! We have certainly experienced it and we
> avoid it!
I have to say that *IF* we sort out this problem, then it won’t be *SO bad* after all.
Good point, let me repeat the tests with the latest and greatest c-based Git implementation.
>
>> P.S. I am planning to prepare a patch for implementing 3. If we believe it’s
>> a good idea to auto-disable the phase.
>
> I look forward to testing out what you come up with,
+1
Luca.
> On 1 Oct 2020, at 23:44, Martin Fick <mf...@codeaurora.org> wrote:
>
> On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
>> Looking at the code called by the searchForReuse, I ended up in:
>>
>> @Override
>> public void selectObjectRepresentation(PackWriter packer,
>> ProgressMonitor monitor, Iterable<ObjectToPack> objects)
>> throws IOException, MissingObjectException {
>> for (ObjectToPack otp : objects) {
>> db.selectObjectRepresentation(packer, otp, this);
>> monitor.update(1);
>> }
>> }
>>
>>
>> The above is a cycle for *all* objects that goes into the another scan for
>> *all* packfiles inside the selectObjectRepresentation().
>>
>> The slow clones were going through 2M of objects on a repository with 4k
>> packfiles … the math would say that it went through a nested cycle of 2M x
>> 4k => 8BN of operations. I am not surprised it is slow after all :-)
>
> Yes, it is terrible to have 4K pack files (or even 300) in a repo. It clearly
> needs to be repacked (but you knew that)!
So the problem is really *in between* GC cycles.
>
>> So, it looks like it works the way it is designed: very very slowly.
>>
>> My questions on the above are:
>> 1. Is there anyone else in the world, using Gerrit or JGit, with the same
>> problem?
>
> Well, I do think most people (especially you know) that you should expect a
> repo with 4K to perform atrociously! We have certainly experienced it and we
> avoid it!
>
>> P.S. I am planning to prepare a patch for implementing 3. If we believe it’s
>> a good idea to auto-disable the phase.
>
> I look forward to testing out what you come up with,
Luca.
Martin Fick
Oct 1, 2020, 6:51:58 PM10/1/20
to jgit...@eclipse.org, repo-d...@googlegroups.com
On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> > The above is a cycle for *all* objects that goes into the another scan
> > for *all* packfiles inside the selectObjectRepresentation().
Also, check the jgit DFS implementation, I seem to recall that it might have
> On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> > The above is a cycle for *all* objects that goes into the another scan
> > for *all* packfiles inside the selectObjectRepresentation().
done something a bit better here?
Martin Fick
Oct 1, 2020, 7:04:57 PM10/1/20
to repo-d...@googlegroups.com, jgit...@eclipse.org
On Thursday, October 1, 2020 4:51:46 PM MDT Martin Fick wrote:
> On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> > On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> > > The above is a cycle for *all* objects that goes into the another scan
> > > for *all* packfiles inside the selectObjectRepresentation().
>
> Also, check the jgit DFS implementation, I seem to recall that it might have
> done something a bit better here?
If I remember correctly, it stores something about the size of the objects
> On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> > On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> > > The above is a cycle for *all* objects that goes into the another scan
> > > for *all* packfiles inside the selectObjectRepresentation().
>
> Also, check the jgit DFS implementation, I seem to recall that it might have
> done something a bit better here?
during the initial walking phase so that it does not need to refind that data
during selectObjectRepresentation() (I think I was hacking a solution to do
that and noticed that the DFS version has already done the same thing),
Luca Milanesio
Oct 2, 2020, 5:46:50 PM10/2/20
to Terry Parker, Luca Milanesio, Martin Fick, repo-d...@googlegroups.com, jgit-dev
On 2 Oct 2020, at 22:24, Terry Parker <tpa...@google.com> wrote:
On Thu, Oct 1, 2020 at 4:05 PM Martin Fick <mf...@codeaurora.org> wrote:On Thursday, October 1, 2020 4:51:46 PM MDT Martin Fick wrote:
> On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> > On Thursday, October 1, 2020 10:51:19 PM MDT Luca Milanesio wrote:
> > > The above is a cycle for *all* objects that goes into the another scan
> > > for *all* packfiles inside the selectObjectRepresentation().
>
> Also, check the jgit DFS implementation, I seem to recall that it might have
> done something a bit better here?
If I remember correctly, it stores something about the size of the objects
during the initial walking phase so that it does not need to refind that data
during selectObjectRepresentation() (I think I was hacking a solution to do
that and noticed that the DFS version has already done the same thing),
In DfsPackCompactor searchForReuse shows up as the scalability bottleneckwhen the pack count grows, but we are aggressive about compacting afternearly every push. That workaround has kept it from being too urgent. It showsup in GC too but generally takes less time than building reachability bitmaps.It only shows up in UploadPack when our compaction or GC backgroundjobs get wedged, and even then we push back with TOO_MANY_PACKSservice errors at 2.5k packs, so we get paged and fix things before readlatencies get too bad.One thing that may help is ignoring duplicated content that a client sendsto the server (as a follow on to the "goodput" measurement). The idea is thatwhen a server receives a pack from a client and realizes it contains objectsthe server already has, we can drop those objects from the received pack'sindex (making them invisible) and the next GC or compaction will drop themand reclaim the storage.I'm not sure if that solves all of the searchForReuse inefficiencies, but itshould help.The Gerrit workflow of creating new refs/changes branches from a clientthat may not have been synced for a few days, plus the lack of negotiationin push, makes for this conversation:client: hello server!server: here are sha-1s for my current refs (including active branchesupdated in the last N minutes)client: I synced two days ago. I don't recognize most of those sha-1s. Youdidn't mention the parent commit for my new change, which was the tip ofthe 'main' branch when I started working on it. I see a sha-1 for the build wetagged last week. Let me send you all of history from that sha-1 to myshiny new change.
Oh yes, that makes things clearer and yes, it is worrying :-(
In my local tests last night, I managed to create a 10GB repository very quickly, that after a gc ended up to be just over 200MBytes.
That’s a symptom of the huge duplication happening.
The situation is bad. Those goodput metrics show that for active Gerritrepos, over 90% of the data sent in pushes is data the server already has.Negotiation in push is the best way to solve it, but until that is widelyavailable in clients (and even beyond to deal with cases wherenegotiation breaks down), I think ignoring duplicate objects at thepoint where the server receives them will make life a lot better.
Yeah, agreed.
Thanks for the detailed explanation.
Luca.
-Martin
--
The Qualcomm Innovation Center, Inc. is a member of Code
Aurora Forum, hosted by The Linux Foundation
______________________________________________________________________________________________
jgit-dev mailing list
jgit...@eclipse.org
To unsubscribe from this list, visit https://www.eclipse.org/mailman/listinfo/jgit-dev
jgit-dev mailing list
jgit...@eclipse.org
To unsubscribe from this list, visit https://www.eclipse.org/mailman/listinfo/jgit-dev
Martin Fick
Oct 2, 2020, 7:44:11 PM10/2/20
to Terry Parker, repo-d...@googlegroups.com, jgit-dev
On Friday, October 2, 2020 2:24:17 PM MDT Terry Parker wrote:
transferred bytes? I wonder if the amount of data sent by the client (Mbs
transferred) is nearly as big as how much data hits the disk in those
packfiles? If the transfer is much smaller than the pack file, then it would
mean that the duplicate data on disk is mostly the result of packfile
thickening, not duplicate data being sent.
Packfile thickening is very wasteful, potentially much more then sending
duplicate deltas since deltas tend to be space efficient, and thickening
undoes all that efficiency by copying a full non deltafied object from an
existing pack into the new pack making it balloon. So even though an out of
date client may need to send a bunch of extra diffs the server doesn't need
because it thinks the server is out of date, it does that usually in a pretty
space efficient manner, but that space efficiency is lost upon receipt! It
save transfer data, but not storage data. I would not be surprised if this is
where the extra data comes from mostly.
It would be nice if new packfiles could be appended to existing packfiles so
that they would not need to be thickened,
> On Thu, Oct 1, 2020 at 4:05 PM Martin Fick <mf...@codeaurora.org> wrote:
> > On Thursday, October 1, 2020 4:51:46 PM MDT Martin Fick wrote:
> > > On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> > On Thursday, October 1, 2020 4:51:46 PM MDT Martin Fick wrote:
> > > On Thursday, October 1, 2020 4:44:22 PM MDT Martin Fick wrote:
> One thing that may help is ignoring duplicated content that a client sends
> to the server (as a follow on to the "goodput" measurement
> <https://git.eclipse.org/r/c/jgit/jgit/+/160004>). The idea is that
> to the server (as a follow on to the "goodput" measurement
> when a server receives a pack from a client and realizes it contains objects
> the server already has, we can drop those objects from the received pack's
> index (making them invisible) and the next GC or compaction will drop them
> and reclaim the storage.
>
> I'm not sure if that solves all of the searchForReuse inefficiencies, but it
> should help.
>
> The Gerrit workflow of creating new refs/changes branches from a client
> that may not have been synced for a few days, plus the lack of negotiation
> in push, makes for this conversation:
> client: hello server!
> server: here are sha-1s for my current refs (including active branches
> updated in the last N minutes)
> client: I synced two days ago. I don't recognize most of those sha-1s. You
> didn't mention the parent commit for my new change, which was the tip of
> the 'main' branch when I started working on it. I see a sha-1 for the build
> we
> tagged last week. Let me send you all of history from that sha-1 to my
> shiny new change.
>
> the server already has, we can drop those objects from the received pack's
> index (making them invisible) and the next GC or compaction will drop them
> and reclaim the storage.
>
> I'm not sure if that solves all of the searchForReuse inefficiencies, but it
> should help.
>
> The Gerrit workflow of creating new refs/changes branches from a client
> that may not have been synced for a few days, plus the lack of negotiation
> in push, makes for this conversation:
> client: hello server!
> server: here are sha-1s for my current refs (including active branches
> updated in the last N minutes)
> client: I synced two days ago. I don't recognize most of those sha-1s. You
> didn't mention the parent commit for my new change, which was the tip of
> the 'main' branch when I started working on it. I see a sha-1 for the build
> we
> tagged last week. Let me send you all of history from that sha-1 to my
> shiny new change.
>
> The situation is bad. Those goodput metrics show that for active Gerrit
> repos, over 90% of the data sent in pushes is data the server already has.
> Negotiation in push is the best way to solve it, but until that is widely
> available in clients (and even beyond to deal with cases where
> negotiation breaks down), I think ignoring duplicate objects at the
> point where the server receives them will make life a lot better.
I haven't looked at those measurements, do they take into account the actual
> repos, over 90% of the data sent in pushes is data the server already has.
> Negotiation in push is the best way to solve it, but until that is widely
> available in clients (and even beyond to deal with cases where
> negotiation breaks down), I think ignoring duplicate objects at the
> point where the server receives them will make life a lot better.
transferred bytes? I wonder if the amount of data sent by the client (Mbs
transferred) is nearly as big as how much data hits the disk in those
packfiles? If the transfer is much smaller than the pack file, then it would
mean that the duplicate data on disk is mostly the result of packfile
thickening, not duplicate data being sent.
Packfile thickening is very wasteful, potentially much more then sending
duplicate deltas since deltas tend to be space efficient, and thickening
undoes all that efficiency by copying a full non deltafied object from an
existing pack into the new pack making it balloon. So even though an out of
date client may need to send a bunch of extra diffs the server doesn't need
because it thinks the server is out of date, it does that usually in a pretty
space efficient manner, but that space efficiency is lost upon receipt! It
save transfer data, but not storage data. I would not be surprised if this is
where the extra data comes from mostly.
It would be nice if new packfiles could be appended to existing packfiles so
that they would not need to be thickened,

Jonathan Nieder
Oct 2, 2020, 8:34:19 PM10/2/20
to Martin Fick, Terry Parker, Repo and Gerrit Discussion, jgit-dev
Martin Fick wrote:
I haven't looked at those measurements, do they take into account the actual
transferred bytes?
Yes, they measure bytes transferred over the wire.
See https://lore.kernel.org/git/20200603015...@google.com/ for more discussion of this behavior.
Thanks,
Jonathan
Reply all
Reply to author
Forward
0 new messages