[RFC] Replication proposal for LFS objects
571 views
Skip to first unread message

Remy Bohmer
Jan 2, 2017, 2:12:58 PM1/2/17
to Jacek Centkowski, Repo and Gerrit Discussion
Hi,
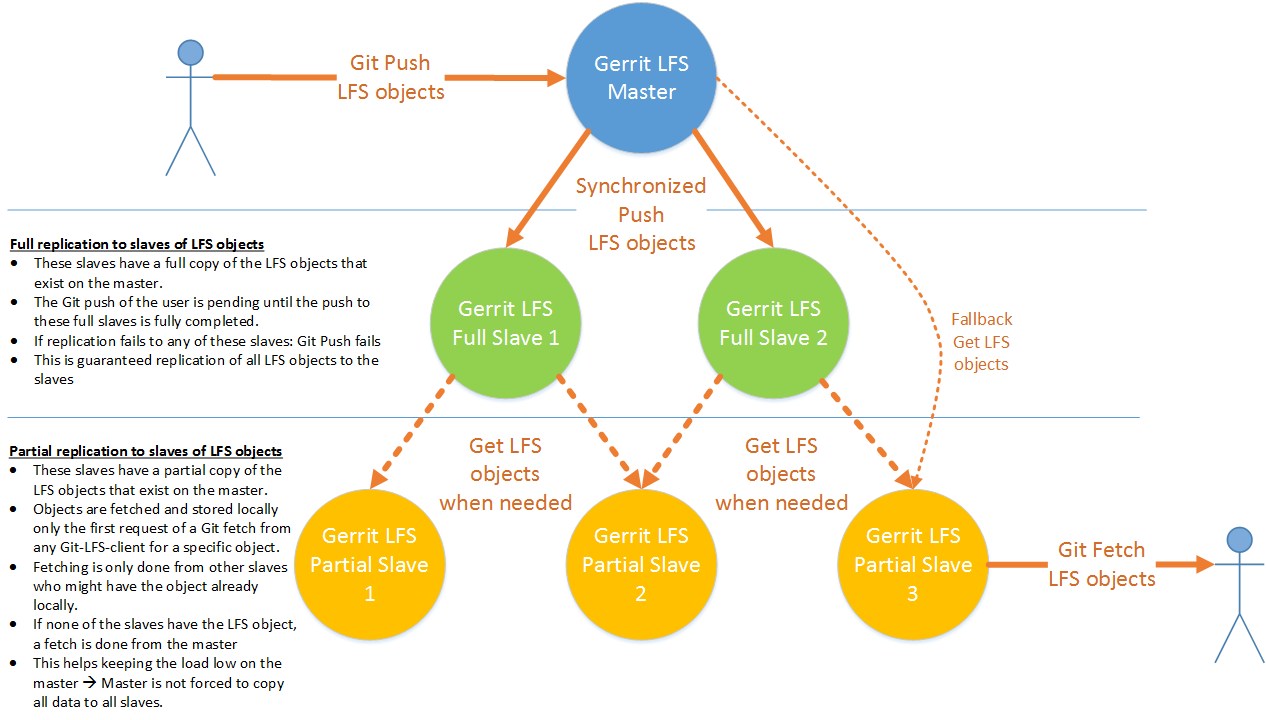
We are looking for a replication solution for LFS objects for an environment where there is no distributed file system, where we only have local disk solutions for mirroring the data.
So, we need to go for a FileSystem based solution. So far we have not found a replication mechanism for LFS, as such we plan to implement one, as part of the LFS plugin :-)
Before spending time on implementing it: what do you all think of the following approach? Comment are welcome. For details see diagram below. If you know of better solutions: please share that as well :-)
We plan to go for a 2-type-of-slaves approach:
- Full Slaves: Contains a full set of LFS objects. Everything the master has, must be on the slave as well. These type of slaves should typically be able to take over the role of the master in case of disasters.
- Partial Slaves: Only LFS objects downloaded by some Git-client from that slave are on that box. If an object is never downloaded from that slave: then that object is not there (yet).
Kind regards,
Remy
Shawn Pearce
Jan 2, 2017, 3:18:42 PM1/2/17
to Remy Bohmer, Jacek Centkowski, Repo and Gerrit Discussion
Its unfortunate that there isn't a distributed version control system that can version binary objects and distribute them using a wire protocol that manages copying objects between nodes. If only someone could figure out the math required to make such a thing possible! If they did, they should name it a silly name.
;-)
In all seriousness, I'd like to just fix git-core to support bigger files better, and then much of the problems that Git LFS brings disappear. Authentication/authorization is still handled by the same thing that handles the repository. `git clone -mirror` can still produce a full mirror clone of that repository, binary assets and all. Distribution between nodes is just git fetch/push, because the binaries are transporting with the sources.
Its going to take a while to get that done, but its something I'd like to work on in 2017.
Git LFS support in Gerrit is IMHO an interim solution, and for those whose histories are already damaged by Git LFS pointers (vs. just storing the contents in Git).
--
--
To unsubscribe, email repo-discuss+unsubscribe@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-discuss+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Jacek Centkowski
Jan 2, 2017, 3:53:22 PM1/2/17
to Repo and Gerrit Discussion, li...@bohmer.net, geminica...@gmail.com
Hi,
Handling binary objects better in git is the ultimate solution (and there is replication already in Gerrit that will take it further) but for now I would rather vote for 'Partial replication slave' as the preferred option to solve the replication problem: there is no front load (loading all history of LFS objects may and probably will not be needed for slaves in most cases) and in the worst case the same amount of master resource will be used to get to synched state but there is a bigger chance that it will be delayed in time... and you can still build cascade of slaves out of it if needed ;)
Regards
Jacek
On Monday, 2 January 2017 21:18:42 UTC+1, Shawn Pearce wrote:
Its unfortunate that there isn't a distributed version control system that can version binary objects and distribute them using a wire protocol that manages copying objects between nodes. If only someone could figure out the math required to make such a thing possible! If they did, they should name it a silly name.;-)In all seriousness, I'd like to just fix git-core to support bigger files better, and then much of the problems that Git LFS brings disappear. Authentication/authorization is still handled by the same thing that handles the repository. `git clone -mirror` can still produce a full mirror clone of that repository, binary assets and all. Distribution between nodes is just git fetch/push, because the binaries are transporting with the sources.Its going to take a while to get that done, but its something I'd like to work on in 2017.Git LFS support in Gerrit is IMHO an interim solution, and for those whose histories are already damaged by Git LFS pointers (vs. just storing the contents in Git).
On Mon, Jan 2, 2017 at 11:12 AM, Remy Bohmer <li...@bohmer.net> wrote:
Hi,We are looking for a replication solution for LFS objects for an environment where there is no distributed file system, where we only have local disk solutions for mirroring the data.So, we need to go for a FileSystem based solution. So far we have not found a replication mechanism for LFS, as such we plan to implement one, as part of the LFS plugin :-)Before spending time on implementing it: what do you all think of the following approach? Comment are welcome. For details see diagram below. If you know of better solutions: please share that as well :-)We plan to go for a 2-type-of-slaves approach:It is crucial for CI purposes that the binary content is on the slave before the CI system gets a trigger to start a build, so we do not plan to go for a full asynchronous solution like the replication plugin does.
- Full Slaves: Contains a full set of LFS objects. Everything the master has, must be on the slave as well. These type of slaves should typically be able to take over the role of the master in case of disasters.
- Partial Slaves: Only LFS objects downloaded by some Git-client from that slave are on that box. If an object is never downloaded from that slave: then that object is not there (yet).
Kind regards,Remy

--
--
To unsubscribe, email repo-discuss...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-discuss...@googlegroups.com.

Luca Milanesio
Jan 2, 2017, 5:58:39 PM1/2/17
to Jacek Centkowski, Remy Bohmer, Repo and Gerrit Discussion
Hi Jacek, Remy,
I apologies in advance if my reply is misplaced or my understand of the problem is not accurate as yours.
I do not see the point of using Gerrit for replicating large files over multiple HTTP Servers: it is a mere NGINX and file-service replication problem.
Why don't you use some off-the-shelf solutions or just do a simple RSYNC over crontab?
I wouldn't put any code for doing HTTP Server replication logic into Gerrit, NGINX does his job perfectly in serving static files.
And what about S3? Just buy some space in an S3 bucket and you've solved all your problems :-)
You've got replication and CDN out of the box.
My impression is that you're trying to solve a non-problem :-O
Luca.
Remy Bohmer
Jan 3, 2017, 6:49:03 AM1/3/17
to Luca Milanesio, Jacek Centkowski, Repo and Gerrit Discussion
Hi All,
Thanks for the feedback.
I agree that if Git core would have a built-in solution for handling large files properly it would have the preference. Unfortunately there is no solution for it yet, neither within the foreseeable future. Great to read that there are plans to work on it this year, but we cannot wait for it.
The only solution that is currently available to us is Git-LFS. From our view: in case there comes another/better solution available in the future, we can still migrate our LFS based content to that solution later. We are talking about an company internal hosted Gerrit environment with no exposure to external company users. As such we can deal with changing directions over time as we know all users of the content.
Please note that we are looking for a solution to the case where one of our company internal Gerrit Master servers is located in Europe, while parts of the CI infra runs for example in the US and in China. We have many slaves across the globe located in all kinds of regions. Many regions have more than one slave for disaster recovery and continuity.
Regarding the context of this topic: Off course there is load balancing in front of the Gerrit slaves.
But we need to balance the load to a machine that has the content readily available when requested for it. As such this topic was about: how to get the content to these machines where we balance the load to. Basically it is only about the replication problem.
A few options exist:
* rsync: Off course we thought about that as well, but this is asynchronous only, and it does not scale as it puts more load on the master server that grows with the amount of content and number of slaves. It is good for syncing on a regular base the master with all the slaves, including cleaning up, but not for handling the CI case. (see below)
* distributed filesystems: Would have been our preference but is not possible due to several (internal) reasons.
* S3: We cannot use a public S3 system as this is company internal content.
The CI case:
* A user uploads a patch to the Gerrit Master, and event handling triggers CI to start running a build. As such, a machine in a different Geo gets an event to start building the patch. It frequently happens that the event arrives to the CI machines before the actual content is there. This is especially the case with large files. Building in delays is cumbersome because how long do the delays need to be? And users will complain as they want to see the CI results asap, minutes count here.
* With plain Git, you can check if the replication is completed before checking out the workarea with git ls-remote, but with LFS objects this gets trickier.
* I already dislike the asynchronous behavior of the Gerrit replication-plugin, as you never know when the data is actually replicated. Waiting for 'replication-done' event is cumbersome as there are slaves out there which are behind a slow and less reliable WAN link and waiting until that replication completes make the system too slow and too unreliable. We even see that sometimes the replication-done event is not fired in some cases (not found the root cause yet). Redesigning the replication plugin is already a long time on our wish list :-)
As such we need a solution where we only generate the 'patch created' event when:
* The data is guaranteed to be there, OR
* The first fetch from that local slave in that Geo is guaranteed to be able to deliver the content on first request. It may take longer for the first fetch but that is not an issue, as long as it succeeds.
The reason why Gerrit is in the picture above is because all events are known inside the Gerrit ecosystem, and from there we are able to stay in control of the flow.
I hope this clears up the context from where we were reasoning when coming up with this proposal. Still we may be overlooking some obvious options for a better solution, and we are open to that :-)
We still may not understand the actual solution that Luca has in mind, especially with how to deal with NGINX and serving static files and deal with replication.
Kind regards,
Remy
To unsubscribe, email repo-discuss+unsubscribe@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-discuss+unsubscribe@googlegroups.com.
Luca Milanesio
Jan 3, 2017, 7:02:29 AM1/3/17
to Remy Bohmer, Jacek Centkowski, Repo and Gerrit Discussion
On 3 Jan 2017, at 11:48, Remy Bohmer <li...@bohmer.net> wrote:Hi All,Thanks for the feedback.I agree that if Git core would have a built-in solution for handling large files properly it would have the preference. Unfortunately there is no solution for it yet, neither within the foreseeable future. Great to read that there are plans to work on it this year, but we cannot wait for it.The only solution that is currently available to us is Git-LFS. From our view: in case there comes another/better solution available in the future, we can still migrate our LFS based content to that solution later. We are talking about an company internal hosted Gerrit environment with no exposure to external company users. As such we can deal with changing directions over time as we know all users of the content.Please note that we are looking for a solution to the case where one of our company internal Gerrit Master servers is located in Europe, while parts of the CI infra runs for example in the US and in China. We have many slaves across the globe located in all kinds of regions. Many regions have more than one slave for disaster recovery and continuity.Regarding the context of this topic: Off course there is load balancing in front of the Gerrit slaves.But we need to balance the load to a machine that has the content readily available when requested for it. As such this topic was about: how to get the content to these machines where we balance the load to. Basically it is only about the replication problem.A few options exist:* rsync: Off course we thought about that as well, but this is asynchronous only, and it does not scale as it puts more load on the master server that grows with the amount of content and number of slaves. It is good for syncing on a regular base the master with all the slaves, including cleaning up, but not for handling the CI case. (see below)
Of course you need to manage fallbacks in case the sync did not complete yet.
The NGINX layer should be in charge of that, falling back the 404s.
Keep in mind that with Git LFS you *never* update files, you just create new ones.
* distributed filesystems: Would have been our preference but is not possible due to several (internal) reasons.
Possibly the geo-distribution is one of them :-)
* S3: We cannot use a public S3 system as this is company internal content.
When I said "S3" I mean the concept. S3 is just a AWS servicing of HDFS. You can still deploy an HDFS cluster internally and use it for this purpose.
The CI case:* A user uploads a patch to the Gerrit Master, and event handling triggers CI to start running a build. As such, a machine in a different Geo gets an event to start building the patch. It frequently happens that the event arrives to the CI machines before the actual content is there. This is especially the case with large files. Building in delays is cumbersome because how long do the delays need to be? And users will complain as they want to see the CI results asap, minutes count here.
See my fallback comment above: you have to take into account that sometimes the "replica hasn't finished" and manage the fallback to service that file from master.
* With plain Git, you can check if the replication is completed before checking out the workarea with git ls-remote, but with LFS objects this gets trickier.* I already dislike the asynchronous behavior of the Gerrit replication-plugin, as you never know when the data is actually replicated. Waiting for 'replication-done' event is cumbersome as there are slaves out there which are behind a slow and less reliable WAN link and waiting until that replication completes make the system too slow and too unreliable. We even see that sometimes the replication-done event is not fired in some cases (not found the root cause yet). Redesigning the replication plugin is already a long time on our wish list :-)
The problem here isn't the replication plugin but rather your WAN infrastructure.
There isn't any software solution if the hardware and network isn't there.
The problem is your infrastructure, not Gerrit replication here.
As such we need a solution where we only generate the 'patch created' event when:* The data is guaranteed to be there, OR* The first fetch from that local slave in that Geo is guaranteed to be able to deliver the content on first request. It may take longer for the first fetch but that is not an issue, as long as it succeeds.The reason why Gerrit is in the picture above is because all events are known inside the Gerrit ecosystem, and from there we are able to stay in control of the flow.I hope this clears up the context from where we were reasoning when coming up with this proposal. Still we may be overlooking some obvious options for a better solution, and we are open to that :-)We still may not understand the actual solution that Luca has in mind, especially with how to deal with NGINX and serving static files and deal with replication.
We can take it off-line and show you in a POC.
Jacek Centkowski
Jan 3, 2017, 8:07:34 AM1/3/17
to Repo and Gerrit Discussion, li...@bohmer.net, geminica...@gmail.com
Hi,
I am not saying that we can solve the following issue programmatically only but:
What if the large object should be no longer served but it is still available and served by replica (there is separate thread how to handle that situation in LFS on master but for discussion sake lets assume that it is solved ;)) - I can imagine that one can solve it by object's expiration time but that would mean that objects will be invalidated and downloaded again... I am not familiar with nginx but can static proxy handle such situation properly?
Regards
Jacek
Luca Milanesio
Jan 3, 2017, 8:45:15 AM1/3/17
to Jacek Centkowski, Repo and Gerrit Discussion, li...@bohmer.net
On 3 Jan 2017, at 13:07, Jacek Centkowski <geminica...@gmail.com> wrote:
Hi,
I am not saying that we can solve the following issue programmatically only but:What if the large object should be no longer served but it is still available and served by replica
If you remove the files from the master, rsync will remove them from the slaves as well.
Additionally, if they aren't referenced anymore by your Git LFS links, they'll not be discoverable anymore.
Removing them from the slaves is just housekeeping, which can be done asynchronously.
(there is separate thread how to handle that situation in LFS on master but for discussion sake lets assume that it is solved ;)) - I can imagine that one can solve it by object's expiration time but that would mean that objects will be invalidated and downloaded again...
Object expiration? Are you talking about the files or the commits?
For the Git commits, the GC will get rid of them.
With regards to the files referenced by it, possibly the Gerrit GC mechanism should notify the LFS plugins that files need to be removed: that part isn't implemented yet I believe.
I am not familiar with nginx but can static proxy handle such situation properly?
Again, it is going to be complicated to describe how to setup a file-server replicated cluster with NGINX on this forum, please contact me off-line and we can work on it :-)
Luca.

Andreas Lederer
Nov 7, 2019, 2:50:40 AM11/7/19
to Repo and Gerrit Discussion
Hi,
we also cannot use amazon S3 due to company content.
You wrote that you mean with S3 only the concept of a HDFS cluster, does this mean it would be possible to use the "S3" storage type of the gerrit lfs plugin configuration or is it necessary to use the "file system backend" storage type in this case ?
You wrote that you mean with S3 only the concept of a HDFS cluster, does this mean it would be possible to use the "S3" storage type of the gerrit lfs plugin configuration or is it necessary to use the "file system backend" storage type in this case ?
I just want to ask, if someone has already used a replicated Glusterfs
volume as distributed storage for the lfs files in a simple master-slave (distributed between Austria and Italy)
configuration. I assume a replicated volume is also working over this WAN connection.
I think the Glusterfs setup has less overhead compared to HDFS, is this correct?
I think the Glusterfs setup has less overhead compared to HDFS, is this correct?
The Glusterfs bricks would be located directly on the gerrit servers (master and slave), mounting locally the glusterfs as storage for the lfs (fs type) storage of gerrit.
All changes on lfs files are anyway done on the master, the slave is only used for initial clones and further fetches at the second location.
All changes on lfs files are anyway done on the master, the slave is only used for initial clones and further fetches at the second location.
Regards,
Andreas
Andreas
Kind regards,Remy
To unsubscribe, email repo-d...@googlegroups.com
More info at http://groups.google.com/group/repo-discuss?hl=en
---
You received this message because you are subscribed to the Google Groups "Repo and Gerrit Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to repo-d...@googlegroups.com.
Trevor Getty
Nov 7, 2019, 6:23:43 PM11/7/19
to Repo and Gerrit Discussion
Hi Andreas,
If you wish to update to a fully working Replicated LFS solution based around FS storage, we have one available on github that you could use as a starting point.
We have many Multi-master Gerrit environments all using the WANdisco Gerrit Multisite product, which all act as full time read-write Masters.
We therefore needed to implement LFS replication to match our standard git repository replication.
We wished to have an FS based storage solution to allow replication to be done on systems which couldn't and didnt' want to use S3 for the file storage.
In our own case the process of replication for the LFS data is done by a server running locally on the same box, which means we communicate with it via a REST api, and let it do the replication for us.
You will not have access to this but you can still use all the same endpoints and instead split in your own code.
I was going to implement a basic version of this local server as a gerrit plugin for LFS replication which used RSYNC to other servers, or transferred content using the LFS protocol to the remote nodes, either way it would allow someone to use this as a POC / demo outside of using a full WANdisco replication solution using one other plugin.
Our solution allows for any repository to be replicated or not. For a replicated repository it can itself be selectively replicated, to 1 server or all servers depending on how the system is setup. So that it entirely up to you to decide what suits your environment best.
The good thing is that the standard LFS plugin isn't changed very much at all to support replication, there is simply some hooks to the read and create points to allow for replicated checks or updates.
All the replication itself happens outside of this plugin, which allows this plugin to move forward easily and hopefully we can then contribute this back instead of using a fork and users simply plug in whatever replication (Plugin or resource) they wish to do that actual replication for them.
If you are interested in talking about this more, or wish to review the code it is available for you to view on github: https://github.com/WANdisco/gerrit-lfs-plugin
If you wish to try to work on this here is some quick pointers:
The content itself is replicated to another location by a single class: LfsReplicateContent->replicateLfsData
This is a REST Api request to our local server for replication, but you could update this to be a local plugin in gerrit to keep the logic seperate or just make the call inside this plugin if you so wish using something like RSYNC, I wanted to keep the method
of replication as seperate from the LFS data layer as possible, as we use this replication to do more than just LFS content.
The next thing is the intercept of the LFS calls are already updated in LfsFsContentServlet class.
This will be looking for our replication information being present on the LargeFileRepository object in order to see if the repository is replicated and what its replication identity is.
You will want to update this jgit object with whatever will represent your replication information grouping.
For us a repository can have a replication grouping, and this is something you would need so that you can a request if the item is already replicated to the other servers
a) do nothing its already replicated to all, so return with size.
b) its locally available then use this local copy - replicate to all in the group and continue.
c) its not locally available take the LFS content from the request, place it locally on your FS destination, replicate to all other servers in the group.
The last thing for a successful replication integration is the doGet which I have integrated with.
I changed the repository.getSize() method, which by default checks only the local file system for the presence of the item, and returns its size if its there else -1 if not.
Instead this request on replicated repositories, will check if the item is present on all the replicated servers.
What you return here is related to the push operation list above:
1) The code here does the check to make sure the content is on all replication group nodes, and if so and locally available it will return the items size anything else returns -1 to force the client to do a push, meaning it will all be fixed up in the push operation just as if it was a new file for the first time.
Although you could do any of the following:
1) If it isn't available locally then you must return -1, to let it do a push.
2) If the item isn't locally but is remotely in the rest of the group then you could repair this location from another replicated server which has the content then return the size
3) If the item is local but not in all remote locations you could heal the remote locations then return size.
The code included does option 1 currently as the push operation has a better progress reporter whereas the get operation expects to receive only the size of the file in a quicker period of time.
I hope all of this helps, and potentially together we could have a simple replicated LFS storage solution for everyone to use.
Trevor.
Andreas Lederer
Nov 26, 2019, 10:38:49 AM11/26/19
to Repo and Gerrit Discussion
Hi Trevor,
thanks for this info, but we have currently no resources to check and implement the required handling here.
We have in the meantime configured the glusterfs based replication and it seems at least the replication of the files is working as expected.
We have now performance issues when fetching the lfs files from the server, I will create a different post for it.
We have now performance issues when fetching the lfs files from the server, I will create a different post for it.
Regards,
Andreas
Andreas
Reply all
Reply to author
Forward
0 new messages