PyOpenCL Buffer Usage/Transfer in reikna FFT
111 views
Skip to first unread message

Mike
Jan 16, 2020, 6:25:31 PM1/16/20
to reikna
Hello,
I have posted the code this relates to in a stackoverflow question here: https://stackoverflow.com/questions/59777482/optimization-of-pyopencl-program-fft
Code is available directly here: https://github.com/mswallac/PyMotionOCT
In my code I do some math with PyOpenCL (pocl) kernels and then process the output of these kernels in the reikna FFT module. So I have a pocl buffer with the data I'd like to use and I need to have it as a reikna gpu array to use with the reikna FFT module (right?). Is the process of transferring between these types costly enough to cause concern? I'm having some trouble benchmarking it so I'm unsure. If this is an issue is there maybe a way to point a reikna array to a pocl buffer's memory?
I'd also really appreciate suggestions on the more general issue I mention in the linked stackoverflow post.
Thanks,
Mike

Bogdan Opanchuk
Jan 16, 2020, 7:35:11 PM1/16/20
to reikna
Hi Mike,
Admittedly, the reikna-pyopencl interop is not very well documented at the moment. What you need to do is:
1. Create a reikna Thread object from whatever pyopencl queue you want it to use (probably the one associated with the arrays you want to pass to FFT)
2. Create an FFT computation based on this Thread
3. Pass your pyopencl arrays to it without any conversion.
(you can create a reikna array based on the buffer from a pyopencl array, by passing it as `base_data` keyword, but if using FFT is all you need, that is not necessary).
Reikna threads are wrappers on top of pyopencl context + queue, and reikna arrays are subclasses of pyopencl arrays, so the interop should be pretty simple. Please tell me if you have any issues. I'll look at your SO question too, but that may be harder to answer.
Incidentally, I'm aware of all this baggage and weird design decisions I made :) I'm now in the process of separating cluda from high-level stuff (computations/transformations/etc), and adding a more consistent PyOpenCL/PyCUDA interop, automatic multi-GPU support and other features. I'm expecting to have a publish-ready version next month (high-level reikna needs a big redesign too, but that's the next step).

Mike
Jan 16, 2020, 9:23:49 PM1/16/20
to reikna
Thanks for the quick responses and help!
However, I realized that I may have spoken a bit too soon on stackoverflow, now that I'm checking the results it seems that the output is all 'nan' now, although this was not an issue previously. I think this is because the type of the previous computations are float32 while the fft is initialized with a type of complex64. How can I efficiently typecast in this context? I feel like I remember reading something about this in the docs but I don't remember where!
It should also be noted that the array is in 2048*n format coming from pocl kernels, while the reikna fft plan expects 2048,n. I'm not sure if that may also be an issue.
Anyway, I will keep investigating. I appreciate the help!
P.S. I look forward to the upcoming update, good luck!
Bogdan Opanchuk
Jan 16, 2020, 9:42:03 PM1/16/20
to reikna
Ah yes, it was my bad, I basically just outlined the way to do it without checking that the results are actually good.
> How can I efficiently typecast in this context?
The best way to convert would be to use transformations - see https://github.com/fjarri/reikna/blob/develop/examples/demo_real_to_complex_fft.py which solves your exact problem. There is no specialized real-to-complex FFT in reikna at the moment.
> It should also be noted that the array is in 2048*n format coming from pocl kernels, while the reikna fft plan expects 2048,n. I'm not sure if that may also be an issue.
Not an issue as long as your data is contiguous and starts from the offset 0. FFT will treat the given buffer as an array of shape and dtype that was specified at creation.
Bogdan Opanchuk
Jan 16, 2020, 9:46:05 PM1/16/20
to reikna
Also, I just noticed another thing - you are creating an FFT of a 2D array over the outermost axis. An FFT over the innermost axis will be significantly faster, so if you can keep your array transposed, it'll improve performance.
Mike
Jan 16, 2020, 10:07:30 PM1/16/20
to reikna
Thanks! I fixed the typing issue using the example you linked.
However, I'm not quite sure what to you mean by 'keep' the array transposed? If I'm doing the FFT over the wrong axis now then shouldn't I transpose it instead?
Sorry, maybe I'm missing something. I'll experiment a bit myself.
Bogdan Opanchuk
Jan 16, 2020, 10:12:50 PM1/16/20
to reikna
Well, now you're keeping your data with the FFT axis (the one with size 2048) being the axis 0. You're doing the FFT over the correct axis, but it is not efficient. If you keep your data so that it has the shape (n, 2048) and do FFT over the axis 1, your code will run faster (providing the FFT is the bottleneck, of course). You can, of course, transpose your data before each FFT, if you prefer - that will work too - but if the rest of your code does not care about the data layout, it is better to keep it in (n, 2048) at all times.
blacks...@gmail.com
Jan 16, 2020, 10:26:59 PM1/16/20
to reikna
It would definitely be easiest to just do the transpose for the FFT as the code is written now, if that doesn't get me the desired speed then I may consider doing a fresh rewrite so that everything can be (n,2048). Thanks, I will try to implement the transpose now.
blacks...@gmail.com
Jan 16, 2020, 10:45:58 PM1/16/20
to reikna
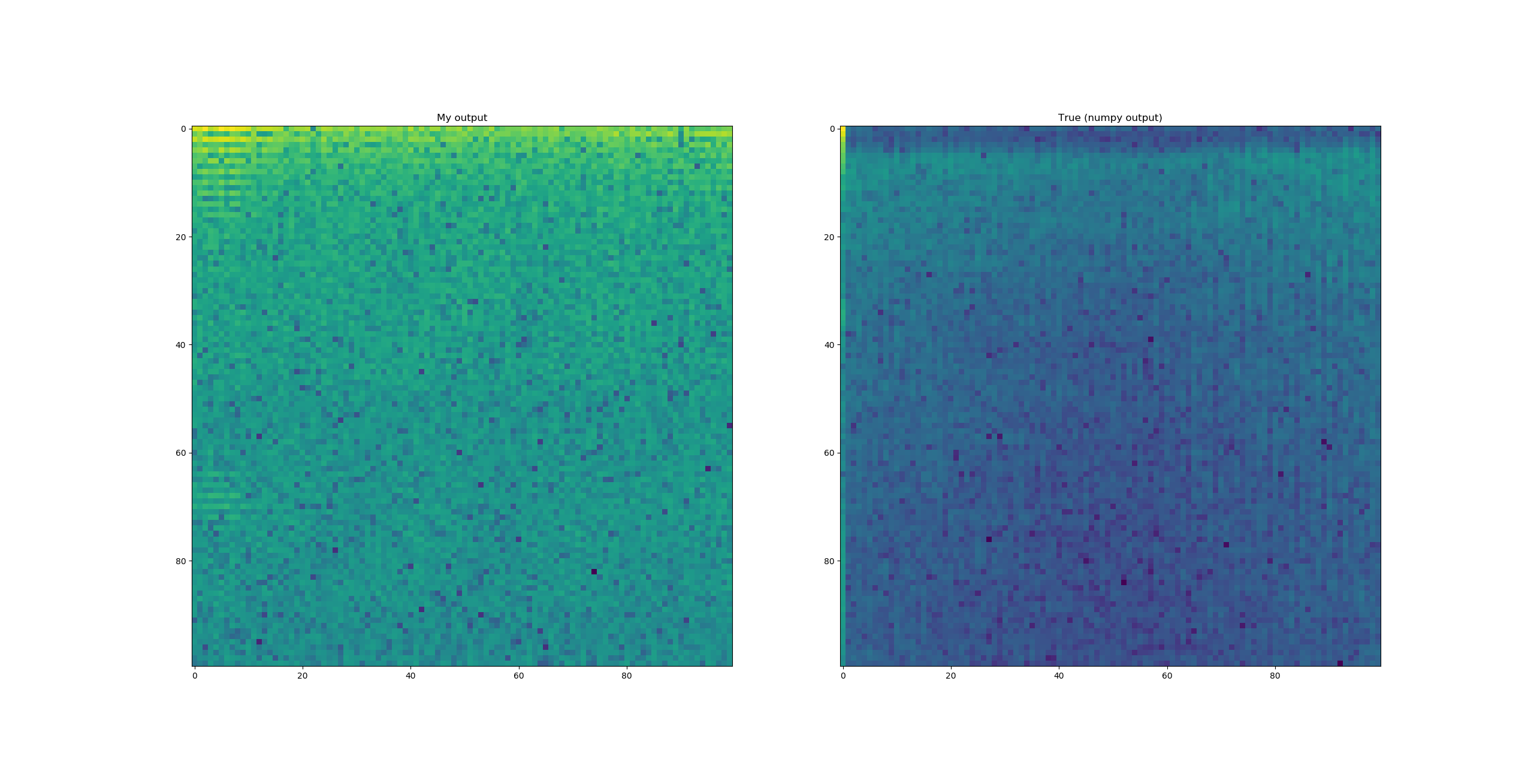
Hmm it seems I may have spoken too soon (again--apologies) my output is no longer nan, but now doesn't match up with the numpy output which I am taking to be my 'ground truth' here. This is before implementing the transpose. I updated the code on github so that it makes a plot to show the difference with the new implementation. I'll attach an image of that plot here.

Mike
Jan 16, 2020, 10:52:41 PM1/16/20
to reikna
Better illustration (sorry if each reply spams you with an email--hopefully not)
Bogdan Opanchuk
Jan 17, 2020, 1:33:06 AM1/17/20
to reikna
Ok, there are several things.
1. Both in your numpy.fft.fft call and reikna FFT call you're calculating the FFT of a single array with length 2048*n, instead of calculating n 2048-element FFTs:
- in `res_np = np.fft.fft(self.npres_interp,axis=0)`, `self.npres_interp` is a flat array
- in `self.trf = self.get_complex_trf(self.data_prefft)`, `self.data_prefft` is also a flat array, and then you use `FFT(self.trf.output)` which makes the FFT work on flat arrays too. (BTW, you can check the required array shapes/dtypes by printing `trf.signature` or `cfft.signature`)
2. The reikna FFT is performed on complex64 numbers, but numpy.fft.fft casts your array to complex128 internally, so the results may be a little different (not too much in this case though).
3. There is something strange going on with buffers - there is some wrong usage there (either they are reused incorrectly, or the shapes/dtypes are mismatched somewhere). I created its own buffer for reikna FFT, and the results seems to be identical to numpy now. See the updated https://gist.github.com/fjarri/f781d3695b7c6678856110cced95be40
Regarding point 3., I recommend using arrays instead of buffers (either PyOpenCL arrays or reikna arrays) - you will need less code, and it will be easier to catch type errors.
Mike
Jan 17, 2020, 2:58:04 PM1/17/20
to reikna
Thanks for all your help, I really appreciate it!
With your changes I think I have a working version which runs much faster than before now! I still haven't made it so that the FFT operates on the innermost axis, so I may pursue that in the event I need more speed.
Best,
Mike
Reply all
Reply to author
Forward
0 new messages