Research update: AISIC, Outstanding Poster, and convention-forming games

Ram Rachum
Hi everyone!
Here's my research update for this month.
Retrospective on goals for last month
In the last month's update I outlined a list of goals. Here's my update on these goals:
Speak at AISIC and Reversim Summit: ✅ Done
I spent a couple of weeks designing my poster for AISIC 2022. I did a few rounds of reviews with my researcher friends. I was anxious about presenting it. A few people sent me this great video that explains the experience of presenting a poster. I was concerned about keeping the balance between being available to questions and being a pushy salesperson.
On October 19th I took the train from Tel Aviv to Haifa and spent the next two days at AISIC. This is the second AI Safety event that I've been to, and I'm getting a better understanding of the alignment problem.
I met a few interesting researchers there that I'd like to follow up with. More details about them in the goals section at the bottom.
When the poster session started I was a little nervous, but after people started flowing in I felt better. A few dozen people came to my poster, some asking lots of questions and some just reading. They included Stuart Russell, who was the celebrity guest at AISIC. (He wrote Human Compatible.)
After the poster session ended, the organizers announced that Adi Simhi won the Best Poster award, and that I won the Outstanding Poster award 😊
I'm very proud of myself. I'm short on academic achievements, and it's nice to have some validation from established researchers that I'm doing something valuable.
StayAway experiments: Introduce blue agents that want to get close: ✅ Done
I've been having lots of fun running experiments. I'm getting comfortable with RLlib. I'm far from being an expert on it, but I know enough to iterate on experiments.
I ran the experiment with red agents and blue agents that I described in last month's update. I actually ran a few variations of this experiment. Here's one of them. Scroll down to near the bottom (for example line 12568) to see the agents after training:
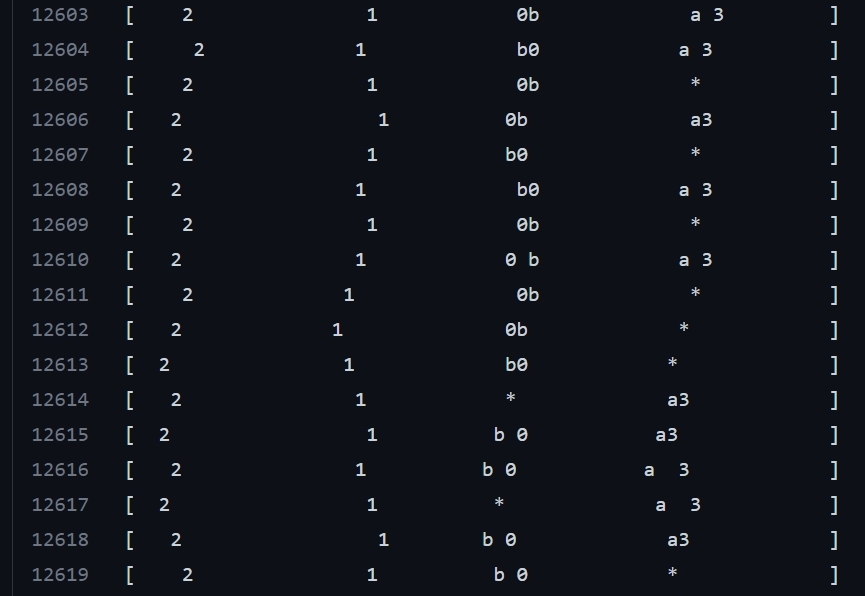
The letter agents (a.k.a. blue agents or predator agents) are represented by
aandb, and they get reward for being as close as possible to the number agents (a.k.a. red agents or prey agents.) The number agents want to be as far away from both the letter agents and the other number agents.The letter agents
aandbare doing a good job of sticking close to a couple of unlucky number agents. These number agents aren't doing a great job of running away. I'm guessing that's because they tried it and saw that the letter agents catch them anyway, or push them to be too close to other number agents.I also ran a different variation of this experiment. What if number agents only cared about being far away from letter agents, but didn't mind being close to each other? Here's the output from that experiment:
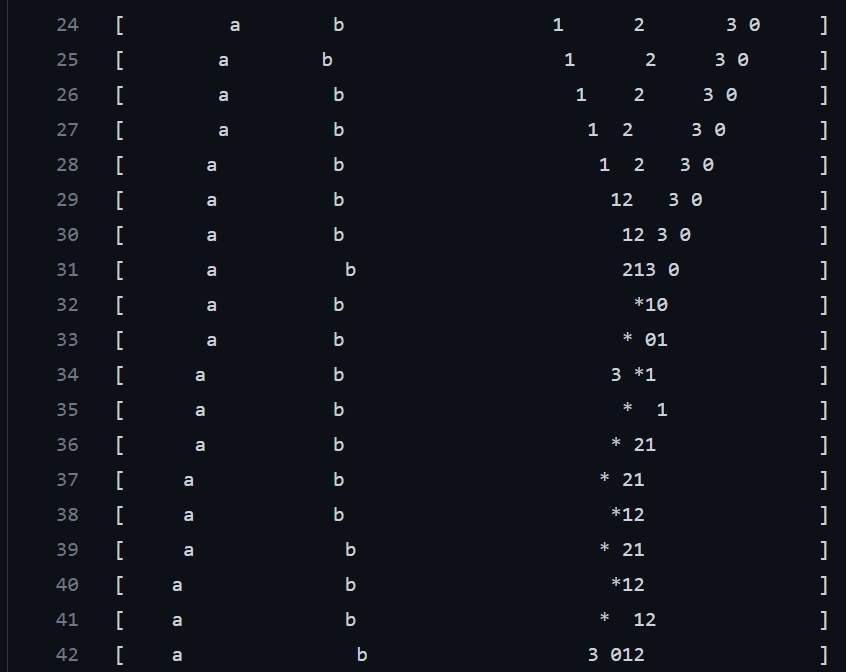
An aside: It's so much fun to be able to run these experiments so easily. You just change a few lines of code and it's as if you created a whole new world with creatures that have evolved different strategies to survive in it.
Looking at that output above, it's interesting to see how all the number agents huddle together between
aandb. Because the game world is a circle, there are actually two "betweens" betweenaandb. There's the "big between" and the "small between". Yes, my scientific nomenclature game is on point. The number agents want to stay in the big between, because then they're farther away from the letter agents and get more points. The letter agents realize this and they try to move closer to each other, squeezing the number agents in between and getting more points.There are some chicken-like dynamics here. When the letter agents squeeze too hard, like around line 400, the number agents escape in either of the two directions, to get to the previously small between which is now the big between:
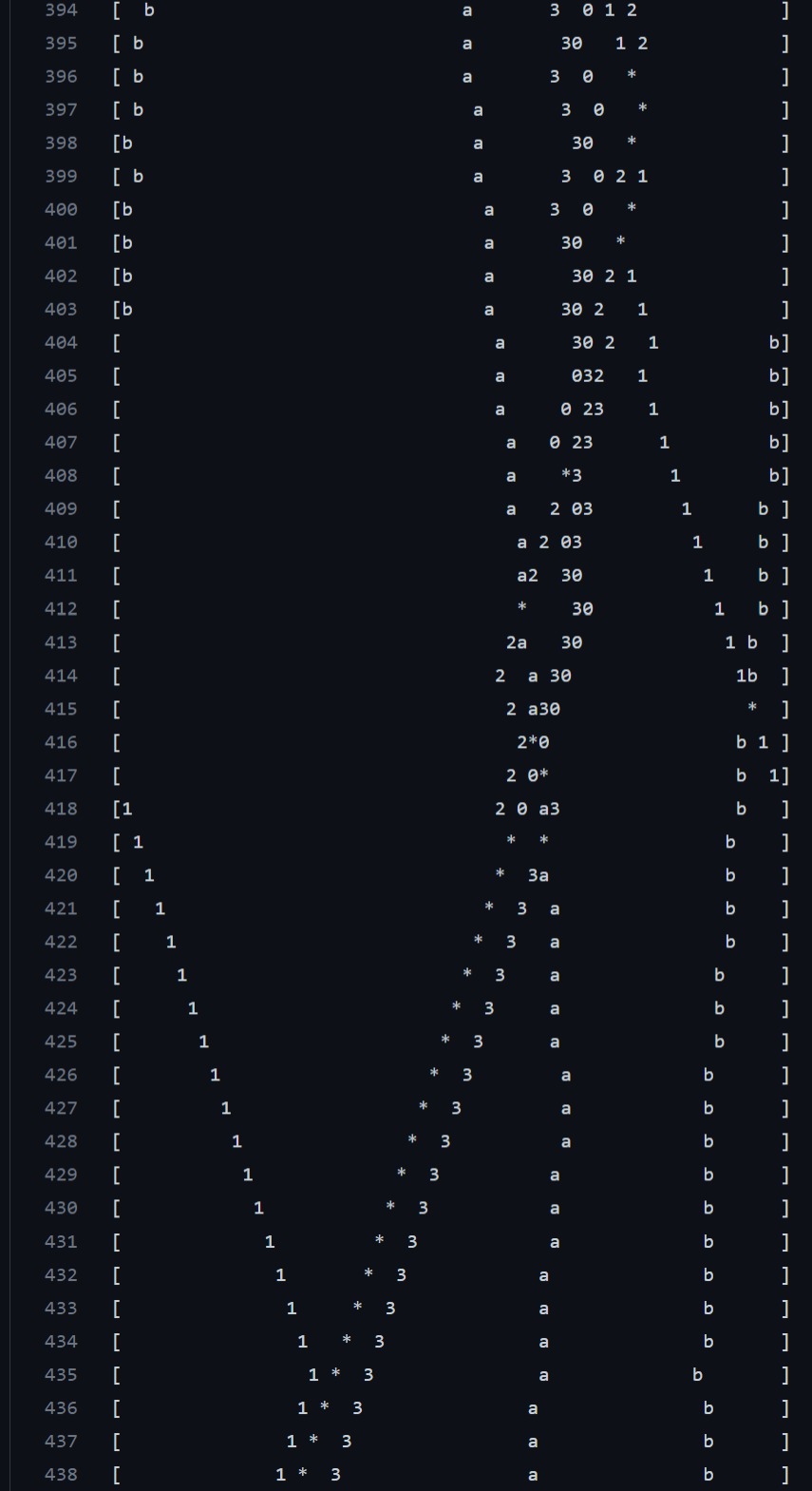
The number agents are taking a lot of damage by doing this maneuver, and they're also taking the risk that by the time they complete it, the letter agents will release the squeeze and the new big between will become the small between again.
This is fascinating, but I'm filing that aside for the future, while I'm investigating something else. Let's look again at the previous experiment, where the number agents are incentivized to stay away from each other. Scroll down to line 14319, and observe the behavior of
bbetween that line and down to line 14364: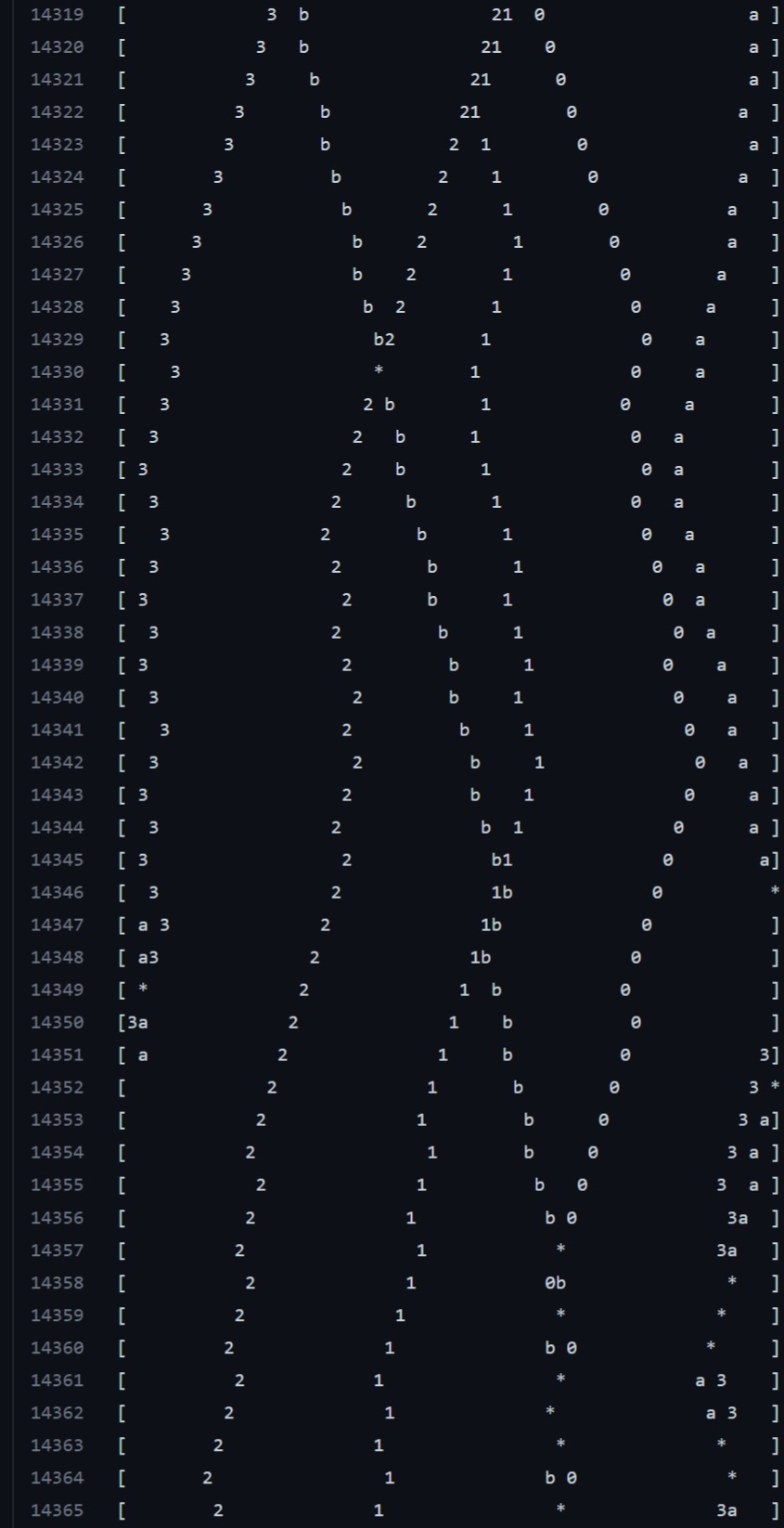
The
bagent is incentivized for being close to a number agent, any number agent. It looked likebwas gunning for2but then it ran right past it. It was making a beeline straight for0, casually skipping over agents2and1. This is despite the fact thatbwould be getting the exact same number of points from hunting either0,1,2or3!What's happening here? This is a known phenomenon in reinforcement learning, and it doesn't even have anything to do with multi-agent RL.
Agent
bis trapped in a local maximum. It learned a behavior that works fairly well, and now any variation on that behavior involves a risk that's too big for the reward. Could agentbdevelop logic for being more flexible with its choice of prey, preferring the closest number agent rather than a specific one? Sure it can. But it's already doing a good job chasing0. If it tries to develop a flexible behavior, it'll have to ease up on its strong instincts to chase0. While this might lead to slightly bigger rewards in the long term, it might also lead to a lower reward in the short term.At this point, many a researcher would be thinking about how to solve this problem. Maybe increase agent
b's exploration factor so it'll try more varied strategies? I'm not going to go there. I don't even consider this behavior to be a problem. I consider it to be the very phenomenon that I'm studying.People don't make perfect decisions; at best they make "good enough" decisions and at worst they follow their misguided instincts in a downward spiral of madness. I'm interested in the miracle where millions of flawed, erratic agents inevitably come together to form a coherent, functioning society. Agent
bis my spirit animal on that journey.My next line of experimenting will explore this direction. Follow this thread in the section "Convention-forming games" below.
Continue fundraising: 😒 I can't even
Fundraising isn't fun. I'm talking to the manager of one foundation that might be interested in funding me. But for him to agree to fund me, he wants me to secure some kind of academic affiliation. We're not talking about starting an official program to get a degree, but something like a "visiting researcher" or a "pre-doctoral researcher". It doesn't have to be paid, he just wants me to be able to list my authorship in a paper as part of some university or lab rather than as an "independent researcher", which he thinks could cause people to take my research less seriously.
Is his assessment correct? Will it be possible for me to get such a title? Will it be easy enough? I'll investigate.
If you can shed light on any of these questions, or better yet, you can help me get such an affiliation from your university or lab, please let me know.
Stuff I've done beyond the monthly goals
Convention-forming games
I wrote above about agent b's sub-optimal strategy, and how I'd like to continue making experiments that explore this direction. Agent b decided to hunt only one of the number agents (agent 3), even though it could hunt all of them, just because it had already gotten used to hunting 3.
I made a plot to see the preference of a letter agent to hunting specific number agents:
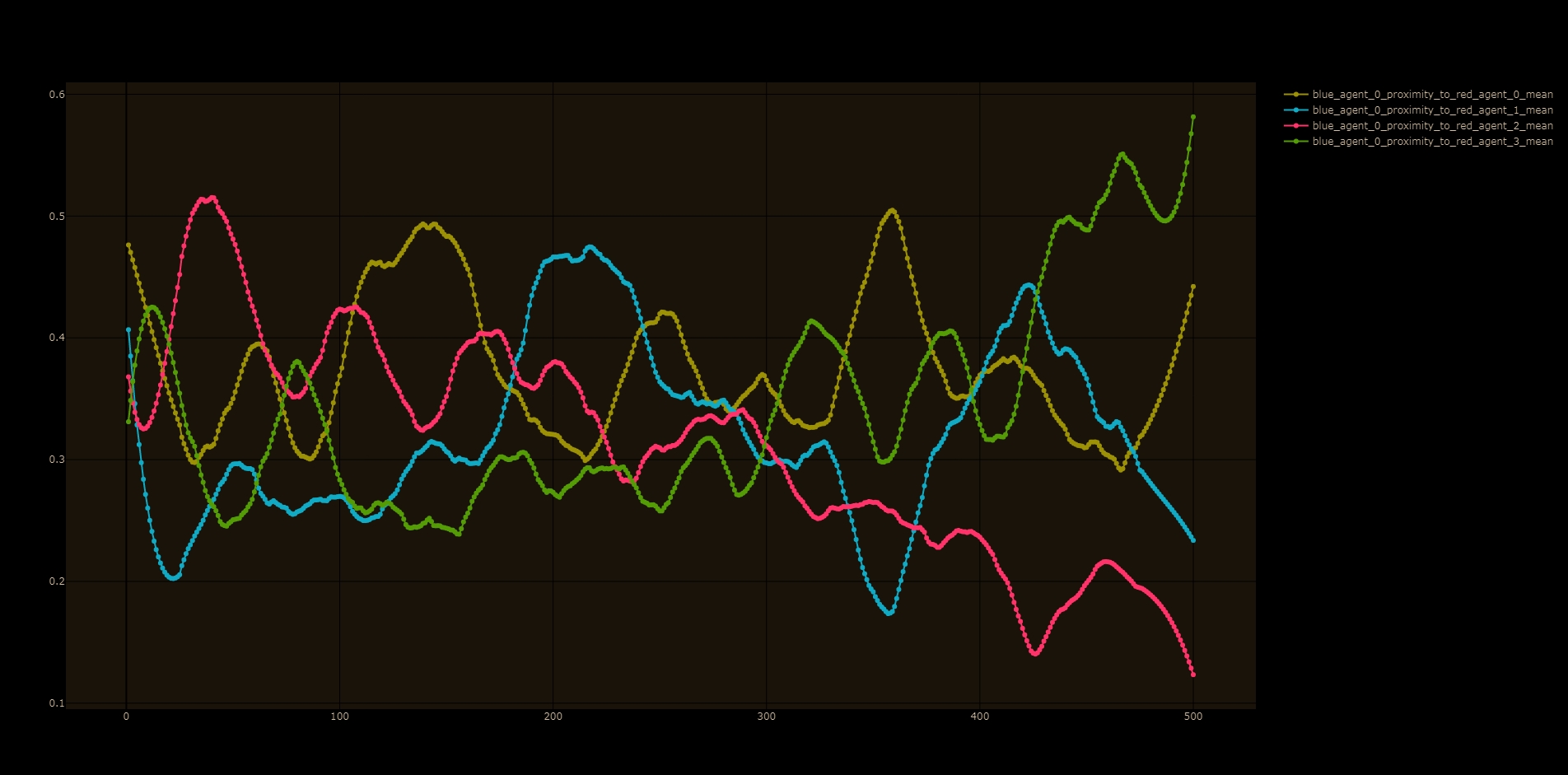
Each line in the plot corresponds to a number agent. The lines are fluctuating without a clear pattern. This makes sense, because the preferences of each letter agent could affect the learning process of all the other agents, creating complex second-order and third-order effects that would be difficult to follow.
I'm interested in the way that one agent "gets used to" behaving in a certain way, and the way it affects how the other agents behave. But I need to study examples that are more tractable than this.
I came up with a very simple game: I call it musical chairs. It's somewhat similar to the children's game with the same name, but without the music and the mild violence :)
In the musical chairs game, the goal of every agent is to sit in a chair that no other agent has chosen to sit in. There are five agents and five chairs, so there are enough chairs for each agent to have a chair. On each round, each agent chooses the chair it would like to sit in (i.e. a number between 0 and 4.) If an agent succeeds in choosing a vacant chair, it gets 1 point. If two agents choose the same chair, they each get 0.5 points. If 3 agents choose the same chair, they each get 0.333 points, etc.
In this game, all the agents can get the ideal reward, but it requires some kind of coordination between the agents. Alas, the agents don't get any kind of communication protocol with the other agents. In fact, I've made them completely blind. The only information they get after playing is how many points they've gotten. They can't even see where the other agents are sitting.
Here is a visualization of the musical chairs game. Here are some observations from it:
In the first games (like the one on line 2) the agents are very bad. Wherever there's an asterisk, it means that multiple agents sat on the same chair and got less points. The average score is 336.
After some training, for example on line 752, the agents are already doing a better job. Agent 2 is almost always picking the first chair. Agent 1 is almost always choosing the second chair. The other agents are still in flux. The average score is 380.
Scroll down to line 2452 to see the agents doing an almost perfect job. Everyone has assigned seating and the average score is 490:
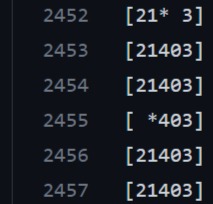
Scroll down to the bottom of the file and you'll see that the average score is a perfect 500.
The interesting thing about this game is that each agent wants the other agents to be decisive already. Each agent is basically looking for the seat that the other agents like the least. But because all of the agents are still in the learning process and are changing their minds on which chair to choose, the title of "least occupied chair" will move around between a few chairs before it stabilizes.
Here is a plot of one agent's preferences for chairs:
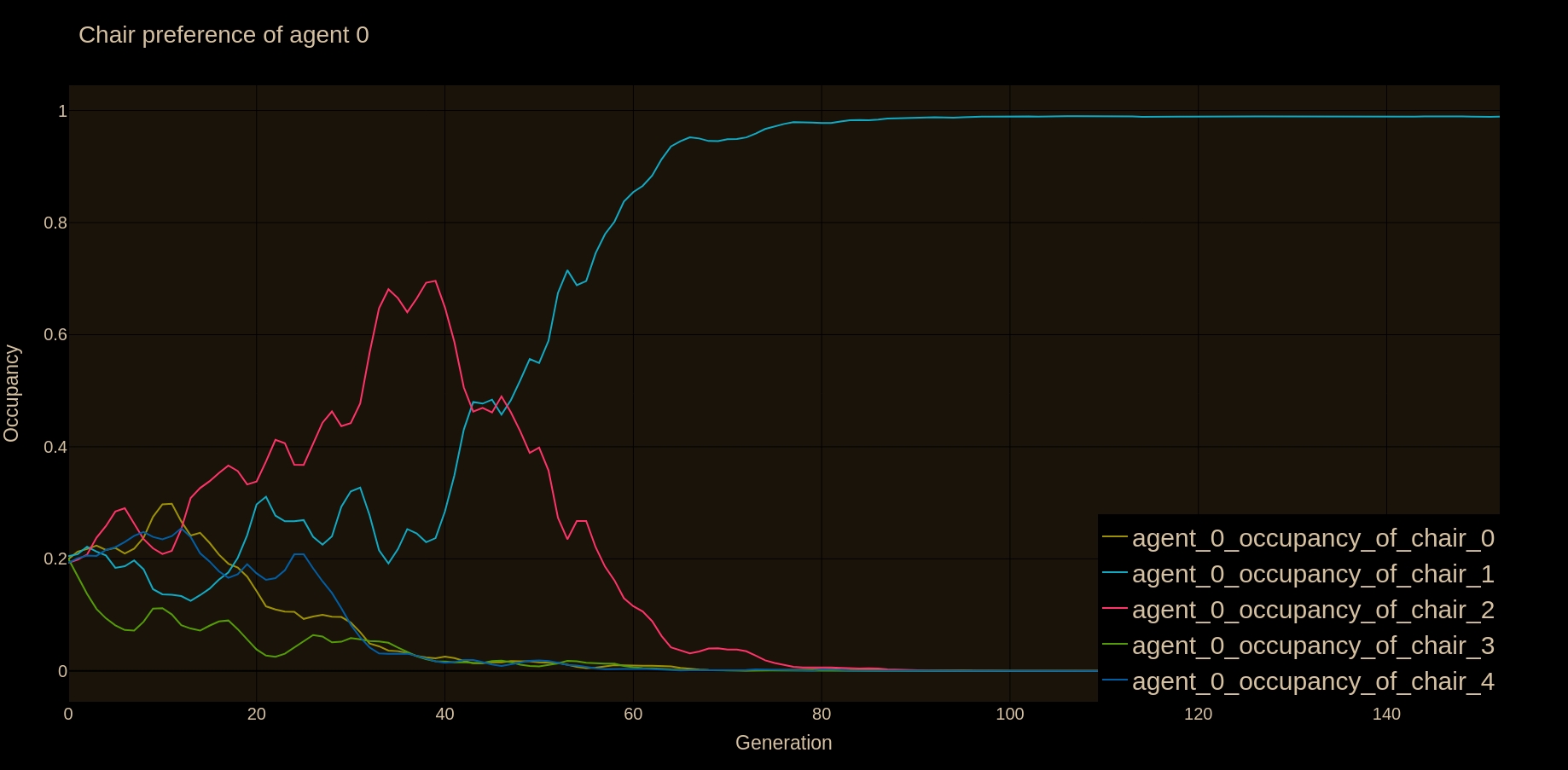
Each line in the plot corresponds to one chair. Here are a few observations:
The 5 lines fluctuate as the agent is trying to decide which chair is best. At around generation 80 it stabilizes on chair 1. Once it stabilizes, it sticks there like a magnet. This makes sense, because once an agent has a strong opinion on a specific chair, all the other agents are strongly incentivized to not sit on that chair.
There's a false start between generations 20 and 40. Our agent is really warming up to chair 2, but I guess some other agent (or multiple agents) are even more assertive about sitting in that chair. Our agent changes its mind and chooses chair 1.
I also used an experimental method to measure the learning progress for the agent. It produced this plot. I won't go into much detail on that now, because I'm not really sure that this method is good. So I'll put that aside for now.
I'm happy with this simple experiment. I'll write about how I intend to continue this thread in the first goal below.
My goals for this month
Run experiments with more interesting convention-forming games.
Running the musical chairs experiment was fun, but that was basic. I like the fact that each agent was settling into its own "niche", and there was a clear interaction between the niches of the different agents. This has a lot of parallels in biological life: Different species choose different specializations, for example to feed on different food sources, and this affects all the other species in the ecosystem.
Now I want the niches to be more interesting. I want the personality of each agent to be more than choosing a specific chair number. I'm not sure what it would look like, but I want their behavior to be more distinctive and creative. I don't want the number of niches to be defined in the premise of the game; I hope for them to be as emergent as possible.
I've got a couple of ideas for games that I'm going to experiment with. (Teaser with no context.) Stay tuned.
Have 1-on-1 meetings with some of the people I met at AISIC 2022.
When I was at AISIC, I met Sarah Keren, who is a professor at the Technion doing MARL research and touching on sequential social dilemmas. We found each other and I hope she'll be interested in helping me with my research. I also met Fazl Barez and Zohar Jackson, and I hope to follow up with them as well.
That's it for now. See you next month!
Ram.