RabbitMQ 3.8.6: Topic exchange stopped routing message despite existing bindings
526 views
Skip to first unread message

joha...@contentful.com
Aug 18, 2020, 4:46:42 PM8/18/20
to rabbitmq-users
Hey,
Queue:
we are running multiple rabbitmq clusters and have recently run into fairly serious issue. A topic exchange is not routing published message to the respective queues despite matching bindings and seems to simply discard those messages.
Queue:
# rabbitmqctl list_bindings | grep 'content_management.entity.Asset.process'
events exchange uploadProcessing queue content_management.entity.Asset.process.* []
Output from trace:
When the issue occurred we were running `rabbitmq:3.8.5-management-alpine` (from docker hub), but an affected cluster is also not fixed by upgrading to `rabbitmq:3.8.6-management-alpine`.
The issue occurred when we applied some changes to our k8s cluster-dns and tried serving stale records https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/coredns/broken_configmap.yml#L18, but it so I haven't been able to replicate the same behaviour locally. https://github.com/johanneswuerbach/rabbitmq-bug shows our rough setup though.
I'm happy to provide any additional information required, but so far nothing I checked indicates that the cluster is broken. The only uncommon log line I noticed was that affected cluster all seem to have logged "Global hang workaround: global state on rab...@rabbitmq-1.rabbitmq.mgmt-shard-XYZ.svc.cluster.local seems broken" at some point, which is mentioned here https://github.com/rabbitmq/rabbitmq-server/issues/2360#issuecomment-637515876, but we are running that version already.
Does someone have any pointers what might be the problem and how to actually detect it from the outside?
Thank you,
Johannes
Node: rab...@rabbitmq-1.rabbitmq.mgmt-shard-7.svc.cluster.local
Connection: 100.96.24.198:33352 -> 100.96.24.196:5672
Virtual host: /
Channel: 1
Exchange: events
Routing keys: [<<"content_management.entity.Asset.process.en-US">>]
Routed queues: []
When the issue occurred we were running `rabbitmq:3.8.5-management-alpine` (from docker hub), but an affected cluster is also not fixed by upgrading to `rabbitmq:3.8.6-management-alpine`.
The issue occurred when we applied some changes to our k8s cluster-dns and tried serving stale records https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/coredns/broken_configmap.yml#L18, but it so I haven't been able to replicate the same behaviour locally. https://github.com/johanneswuerbach/rabbitmq-bug shows our rough setup though.
I'm happy to provide any additional information required, but so far nothing I checked indicates that the cluster is broken. The only uncommon log line I noticed was that affected cluster all seem to have logged "Global hang workaround: global state on rab...@rabbitmq-1.rabbitmq.mgmt-shard-XYZ.svc.cluster.local seems broken" at some point, which is mentioned here https://github.com/rabbitmq/rabbitmq-server/issues/2360#issuecomment-637515876, but we are running that version already.
Does someone have any pointers what might be the problem and how to actually detect it from the outside?
Thank you,
Johannes
Luke Bakken
Aug 18, 2020, 5:20:25 PM8/18/20
to rabbitmq-users
Hello,
Are you absolutely certain those messages are routable? In other words, did something change with how they are published? Your publishers should be using both publisher confirmations and the mandatory flag. Using both ensures publish and routing reliability.
RabbitMQ has a dropped message statistic - you should check that.
Thanks,
Luke
Johannes Würbach
Aug 18, 2020, 5:28:55 PM8/18/20
to rabbitm...@googlegroups.com
Hey Luke,
yes those messages were routable and work reliably on unaffected clusters. When recreating the cluster by deleting all state, the issue also stops happening, but a simple rolling doesn't resolve the issue (so it seems something on disk might be corrupted).
Due to historic reasons we can't use the mandatory flag, but we use confirm and rabbitmq confirms the publish operation (the messages also show up in https://github.com/rabbitmq/rabbitmq-tracing).
>. RabbitMQ has a dropped message statistic - you should check that.
You mean the overall number of unroutable messages? Yes that one is increased, so messages become somehow unroutable without any change to the bindings / queue setup.
Due to historic reasons we can't use the mandatory flag, but we use confirm and rabbitmq confirms the publish operation (the messages also show up in https://github.com/rabbitmq/rabbitmq-tracing).
>. RabbitMQ has a dropped message statistic - you should check that.
You mean the overall number of unroutable messages? Yes that one is increased, so messages become somehow unroutable without any change to the bindings / queue setup.
Thanks for your input,
Johannes
Johannes
--
You received this message because you are subscribed to a topic in the Google Groups "rabbitmq-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rabbitmq-users/YidEQVCY2NQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/6afe9a8e-1aeb-4d95-aa0f-457017dafb49n%40googlegroups.com.
Johannes Würbach
Engineering
Contentful GmbH
Registration Court: Berlin-Charlottenburg HRB 155607 B
Managing Directors: Steve Sloan, Paolo Negri, Dr. Markus Harder
Luke Bakken
Aug 18, 2020, 5:41:59 PM8/18/20
to rabbitmq-users
The issue occurred when we applied some changes to our k8s cluster-dns and tried serving stale records https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/coredns/broken_configmap.yml#L18, but it so I haven't been able to replicate the same behaviour locally. https://github.com/johanneswuerbach/rabbitmq-bug shows our rough setup though
Tell me more about what "serving stale records" means in your environment. Since you're using full DNS names for nodes any incorrect DNS information might cause issues? I'm not really sure.
Can you reproduce this without using k8s and / or DNS "errors"?
Thanks
joha...@contentful.com
Aug 18, 2020, 6:15:49 PM8/18/20
to rabbitmq-users
I totally understand that messing with DNS can cause clustering issues, but I wouldn't expect to end up in a persistent half-broken state. Some queues are actually still routable, but some aren't.
"serving stale records" records essentially means k8s cluster-dns (aka CoreDNS) returns an outdated record when I isn't able to talk to the upstream server and we hoped to increase fault tolerance of our cluster dns by that. More on that https://coredns.io/plugins/cache/ `serve_stale` One hypothesis I tried to replicate was that k8s is somehow re-using pod IPs for DNS records and that is confusing rabbitmq, but I couldn't cause that.
Just as a recap: Some DNS misconfiguration seems to have cause a persistent failure on disk, which makes the cluster look fine (all queues and bindings are present), but somehow causes that some topic bindings are actually ignored and messages are just discarded. We also use `{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}` with 3 replicas with classic queues if that makes somehow a difference.
Thank you,
Johannes
Luke Bakken
Aug 18, 2020, 9:48:08 PM8/18/20
to rabbitmq-users
Thanks for the additional information. "Global hang workaround" is not much to work with. I've brought this to the rest of the team's attention.
Thanks,
Luke
Gerhard Lazu
Aug 19, 2020, 6:55:42 AM8/19/20
to rabbitmq-users
When a RabbitMQ node gets updated, what happens to the queue master that runs on that node?
If you are not using replicated queues (preferably Quorum Queues), and the queue master stops running, where would you expect messages to be routed? I would expect them to be routed to running queues only.
Johannes Würbach
Aug 19, 2020, 12:00:01 PM8/19/20
to rabbitm...@googlegroups.com
Hey Gerhard,
While I have some knowledge on rabbitmq as a user / administrator, I don't know much about the internals. We are using `{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}` with classic queues (quorum queues look preferable for our usage, but we didn't had the time yet).
We run rabbitmq in a k8s statefulset (with the default podManagementPolicy OrderedReady) with "rabbitmq-upgrade post_upgrade" as a postStart and "rabbitmq-upgrade await_online_quorum_plus_one -t 600; rabbitmq-upgrade await_online_synchronized_mirror -t 600;" as preStop hooks, which as far as I understand ensures to within reason that we have a synchronised mirror ready and masters are balanced across the cluster.
We run rabbitmq in a k8s statefulset (with the default podManagementPolicy OrderedReady) with "rabbitmq-upgrade post_upgrade" as a postStart and "rabbitmq-upgrade await_online_quorum_plus_one -t 600; rabbitmq-upgrade await_online_synchronized_mirror -t 600;" as preStop hooks, which as far as I understand ensures to within reason that we have a synchronised mirror ready and masters are balanced across the cluster.
If I understand your question correctly a queue master is some sort of (erlang) process, that would only receive messages if it is currently running. How can I see if its currently running and can it be that it isn't started long (like hours) after the node is ready? Our health/readiness checks are here https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/rabbitmq/statefulset.yaml#L49-L66 and both pass on all nodes, but the cluster is still not routing messages.
Do I understand correctly that rabbitmq might drop messages as unroutable in case the queue master fails and there is no layer of buffering/retry/persistence here?
Thank you for your help already,
Johannes
--
You received this message because you are subscribed to a topic in the Google Groups "rabbitmq-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rabbitmq-users/YidEQVCY2NQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/c5f1203b-aa60-4b07-9d38-761ca915056dn%40googlegroups.com.
Luke Bakken
Aug 19, 2020, 6:09:29 PM8/19/20
to rabbitmq-users
I'd like to add that you must use the mandatory flag for your applications to be notified of unroutable messages.
Luke Bakken
Aug 19, 2020, 7:39:56 PM8/19/20
to rabbitmq-users
The issue occurred when we applied some changes to our k8s cluster-dns and tried serving stale records https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/coredns/broken_configmap.yml#L18, but it so I haven't been able to replicate the same behaviour locally. https://github.com/johanneswuerbach/rabbitmq-bug shows our rough setup though
Thanks for taking the time to put that example together. Unfortunately, even after many runs of the 06_roll.sh script, the publisher keeps on publishing just fine and the four consumers I was running get messages.
Anything you think I could do to make it fail? I'm running an up-to-date Arch Linux system with kind 0.9.0-alpha
Thanks,
Luke
Johannes Würbach
Aug 19, 2020, 9:37:30 PM8/19/20
to rabbitm...@googlegroups.com
As said I wasn’t able to replicate the bug in this local setup so the instructions don’t work despite they kind of reflecting what we did in our AWS kops k8s cluster :-(
If you have any pointers what else I could try to break / poke at the cluster please let me know. Would it somehow trip up rabbitmq clustering if the IP behind a DNS name change during clustering? Like the cluster saw one valid IP, but the queue master got something different?
Just to be sure I understand correctly, setting the mandatory flag will ensure that all queues with the respective binding got the message or just that at least one of them got it? Is a partial routing possible?
Is there any way I can look at the internal state of the routing table (e.g. via the erlang console) to see what bindings are configured and used for routing?
Thanks again,
Johannes
--
You received this message because you are subscribed to a topic in the Google Groups "rabbitmq-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rabbitmq-users/YidEQVCY2NQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/18da767e-5224-4d8a-800c-a847d455d1ebn%40googlegroups.com.
Johannes Würbach
Aug 19, 2020, 9:45:04 PM8/19/20
to rabbitm...@googlegroups.com
I would also be happy to set up a call / screen share to look at the affected cluster and run commands as one of the affected clusters is a staging cluster and doesn't receive production traffic.
Obviously I can understand if you don't have time for that, but I guess we could also work out something with my company around some paid consulting hours if that helps and would be an option. We have been running rabbitmq for several years so have some serious interest on how it performs.
Cheers,
Johannes
Luke Bakken
Aug 19, 2020, 9:49:34 PM8/19/20
to rabbitmq-users
Hi Johannes,
It wasn't clear what "local setup" meant.
The mandatory flag ensures that a message is routed to at least one queue - https://www.rabbitmq.com/publishers.html
I can't think of how an IP change would result in lost or invalid bindings, or perhaps non-running queues (no evidence of that here, though). Entities within RabbitMQ like queues have no real knowledge of DNS, IP addresses or cluster details. That's all handled by the Erlang VM.
The rabbitmqctl command can list queues, bindings, exchanges, etc.
The rabbitmqctl command can list queues, bindings, exchanges, etc.
There have been issues around lost bindings (https://github.com/rabbitmq/rabbitmq-server/issues/1873) and we've tried to address them but perhaps you've found a new case.
Unfortunately there is little we can do without a reproducer.
Thanks,
Luke
Gerhard Lazu
Aug 20, 2020, 8:34:09 AM8/20/20
to rabbitmq-users
👋🏻
While I have some knowledge on rabbitmq as a user / administrator, I don't know much about the internals. We are using `{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}` with classic queues (quorum queues look preferable for our usage, but we didn't had the time yet).
Since you are using Classic Mirrored Queues with a replication factor of 2 (1 queue master + 1 queue mirror), the only thing which may be a problem is queue synchronisation.
Since you are using automatic message synchronisation, when the queue master goes offline and the existing queue mirror becomes the new queue master, a new queue mirror needs to be created and all messages need to be synchronised before the queue will accept new messages. During this period it is possible for new messages to not be delivered to this queue. Since messages can potentially be delivered to multiple queues (multiple queues can match the topic) I am not 100% certain what the exact behaviour is for publisher confirms when messages are delivered to some but not all queues. I am not sure if the mandatory flag will help, since messages are delivered, but only to non-blocked running queues. Do you know @luke @michael?
We run rabbitmq in a k8s statefulset (with the default podManagementPolicy OrderedReady) with "rabbitmq-upgrade post_upgrade" as a postStart and "rabbitmq-upgrade await_online_quorum_plus_one -t 600; rabbitmq-upgrade await_online_synchronized_mirror -t 600;" as preStop hooks, which as far as I understand ensures to within reason that we have a synchronised mirror ready and masters are balanced across the cluster.
Your understanding is correct and your implementation is robust, I cannot recommend anything more that you could do in this area.
The only thing that I would add here is that stale DNS may look like a problem, but it's not the cause for the misbehaviour that we are trying to understand & address here. DNS plays a discovery role and does not affect established connections. Our issue is many layers above DNS, in the Erlang processes world.
As an analogy, if you think of RabbitMQ as a hamburger (can you tell that it's close to lunch-time for me?), we are debugging an issue with how the ketchup interacts with the cheese in the hamburger. DNS is the menu that we used to order the hamburger. To complete the analogy, K8S is the restaurant.
If I understand your question correctly a queue master is some sort of (erlang) process, that would only receive messages if it is currently running. How can I see if its currently running and can it be that it isn't started long (like hours) after the node is ready? Our health/readiness checks are here https://github.com/johanneswuerbach/rabbitmq-bug/blob/master/kubeconfigs/rabbitmq/statefulset.yaml#L49-L66 and both pass on all nodes, but the cluster is still not routing messages.
Yes, also correct. I would recommend enabling rabbitmq_prometheus with per object metrics across all nodes with this Grafana dashboard: https://grafana.com/grafana/dashboards/10991
If it's a staging cluster, I would enable debug logging on all RabbitMQ nodes and aggregating to a single log destination. We may need to use these to debug further.
Do I understand correctly that rabbitmq might drop messages as unroutable in case the queue master fails and there is no layer of buffering/retry/persistence here?
You are on a roll! 3 for 3 correct assumptions : )
If the queue Erlang process cannot receive the message, that message goes nowhere (null routed or /dev/null). Without publisher confirms or the mandatory flag, you have the fire & forget behaviour of UDP connections.
Hope this helps, Gerhard.
Luke Bakken
Aug 20, 2020, 8:39:41 AM8/20/20
to rabbitmq-users
Thanks Gerhard -
Since you are using automatic message synchronisation, when the queue master goes offline and the existing queue mirror becomes the new queue master, a new queue mirror needs to be created and all messages need to be synchronised before the queue will accept new messages. During this period it is possible for new messages to not be delivered to this queue. Since messages can potentially be delivered to multiple queues (multiple queues can match the topic) I am not 100% certain what the exact behaviour is for publisher confirms when messages are delivered to some but not all queues. I am not sure if the mandatory flag will help, since messages are delivered, but only to non-blocked running queues. Do you know @luke @michael?
My understanding is that the message will not be confirmed unless all queues to which it is routed accept it.
Thanks,
Luke
Gerhard Lazu
Aug 20, 2020, 8:45:59 AM8/20/20
to rabbitmq-users
If a message is routed to a multiple queues
And one queue is blocked and does not accept the message
And the message is not confirmed
What happens to the message copy that was accepted and confirmed by all other queues?
The follow-up question is what happens if the publisher re-sends the message? Will some queues have the message multiple times and other queues, which continue to be blocked, no message?
Johannes Würbach
Aug 20, 2020, 5:30:23 PM8/20/20
to rabbitm...@googlegroups.com
Thank you for your time and input Luke & Gerhard.
As an analogy, if you think of RabbitMQ as a hamburger (can you tell that it's close to lunch-time for me?), we are debugging an issue with how the ketchup interacts with the cheese in the hamburger. DNS is the menu that we used to order the hamburger. To complete the analogy, K8S is the restaurant.
Thank you for this great analogy, it made me laugh so hard :-D
While the issue might be at a different level, it seems somewhat related. We were running 3.8.5 for 27 days on 81 clusters before rolling out the DNS change and within 48h had three clusters failing with this behaviour. On all of them the issue started after the rabbitmq cluster was rolled by some automation. Once we reverted the DNS change we never saw this issue again (31 days now). We upgraded to 3.8 (3.8.3 to be precise) 177 days and also never saw something like that. I know that correlation doesn't imply causation, but this looks odd.
After enabling rabbitmq_prometheus I can also see messages being confirmed, but dropped as unroutable.
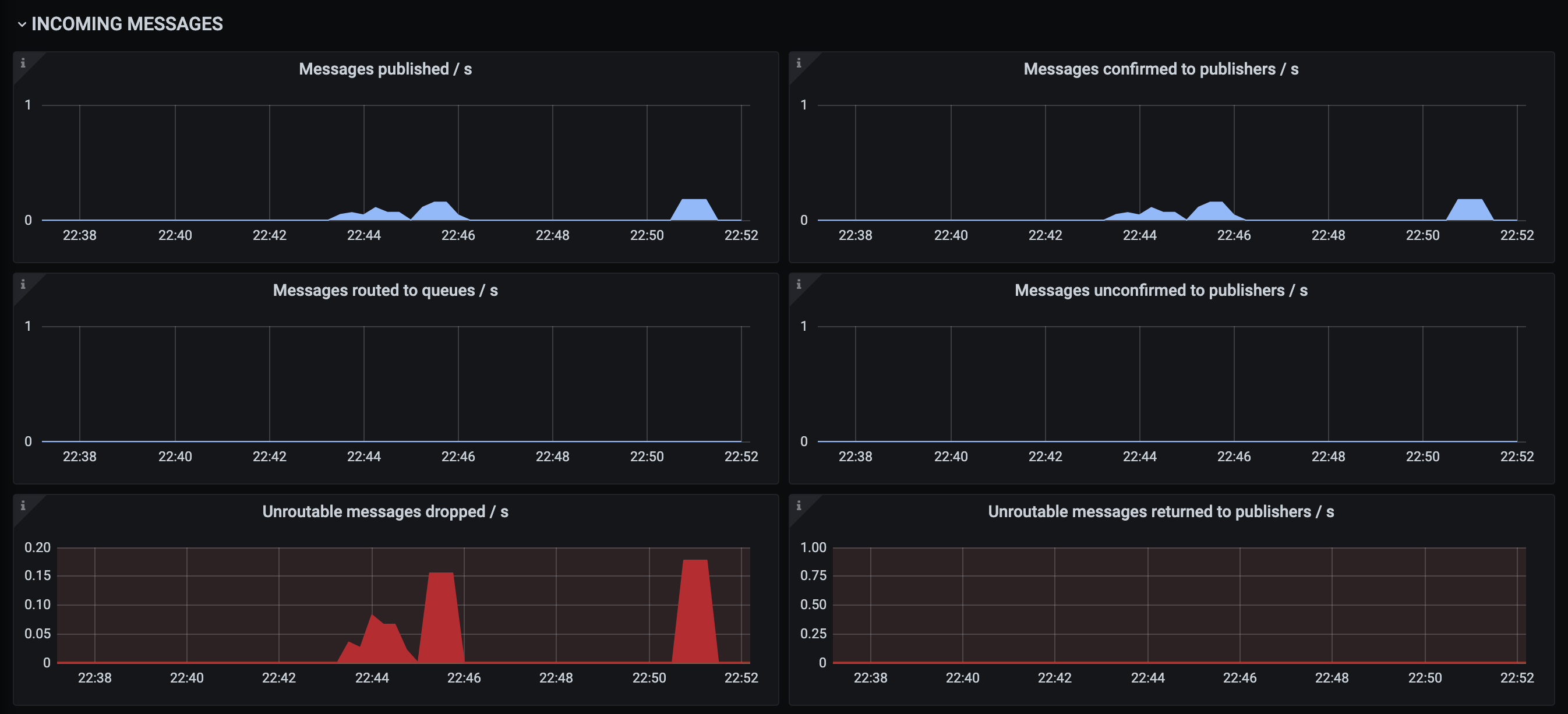
I tried running "rabbitmq-diagnostics list_unresponsive_queues", but no queue is returned, also "rabbitmq-diagnostics cluster_status" doesn't list anything. I also enabled debugging logging, but don't see anything special. Is there something I should look out for?
While the issue might be at a different level, it seems somewhat related. We were running 3.8.5 for 27 days on 81 clusters before rolling out the DNS change and within 48h had three clusters failing with this behaviour. On all of them the issue started after the rabbitmq cluster was rolled by some automation. Once we reverted the DNS change we never saw this issue again (31 days now). We upgraded to 3.8 (3.8.3 to be precise) 177 days and also never saw something like that. I know that correlation doesn't imply causation, but this looks odd.
After enabling rabbitmq_prometheus I can also see messages being confirmed, but dropped as unroutable.
I tried running "rabbitmq-diagnostics list_unresponsive_queues", but no queue is returned, also "rabbitmq-diagnostics cluster_status" doesn't list anything. I also enabled debugging logging, but don't see anything special. Is there something I should look out for?
According to rabbitmq the queue is also seems healthy
$ kubectl exec -it rabbitmq-1 -- rabbitmqctl list_queues --local --online name pid slave_pids synchronised_slave_pids state | grep uploadProcessing
uploadProcessing <rab...@rabbitmq-1.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953399.1257.0> [<rab...@rabbitmq-0.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953574.1380.0>] [<rab...@rabbitmq-0.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953574.1380.0>] running
uploadProcessing <rab...@rabbitmq-1.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953399.1257.0> [<rab...@rabbitmq-0.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953574.1380.0>] [<rab...@rabbitmq-0.rabbitmq.mgmt-shard-7.svc.cluster.local.1597953574.1380.0>] running
the bindings are up and running
$ kubectl exec -it rabbitmq-1 -- rabbitmqctl list_bindings | grep uploadProcessing
events exchange uploadProcessing queue content_management.entity.Asset.process.* []
but a manual publish isn't routing the message
rabbitmqadmin -H rabbitmq-management -u XYZ -p XYZ publish routing_key='"'"'content_management.entity.Asset.process.test'"'"' payload="test $(date
)" exchange=events
Message published but NOT routed
)" exchange=events
Message published but NOT routed
Is there any way to see based on which internal state the routing decision is made and to see whether the queue master process is tried to be contacted?
Thank you,
Johannes
--
You received this message because you are subscribed to a topic in the Google Groups "rabbitmq-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rabbitmq-users/YidEQVCY2NQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/1e5f3ddf-9b0c-41d2-89c3-0567d413300en%40googlegroups.com.
Gerhard Lazu
Aug 21, 2020, 1:39:37 PM8/21/20
to rabbitmq-users
Hi,
Thank you for this great analogy, it made me laugh so hard :-D
I'm glad that it connected ; )
While the issue might be at a different level, it seems somewhat related. We were running 3.8.5 for 27 days on 81 clusters before rolling out the DNS change and within 48h had three clusters failing with this behaviour. On all of them the issue started after the rabbitmq cluster was rolled by some automation. Once we reverted the DNS change we never saw this issue again (31 days now). We upgraded to 3.8 (3.8.3 to be precise) 177 days and also never saw something like that. I know that correlation doesn't imply causation, but this looks odd.
I reviewed the entire thread from the top and was able to construct a new mental model that is able to explain the issue that you are seeing. Spoiler alert: it is (always?) a DNS issue.
This is what I'm thinking:
1. RabbitMQ node 1 (R1) gets shutdown gracefully, queues migrate correctly (good job with this)
2. When a new RabbitMQ pod spins up to replace the pod that was just terminated, the DNS remains the same, but the IP address changes
3. If your DNS is configured to serve stale records, RabbitMQ nodes 2 (R2) & 3 (R3) cannot reach R1, which is running in the new pod, with a new IP address that is not resolving correctly for R2 & R3. R1 is however able to communicate with R2 & R3 (their IPs have not changed). This inconsistent state triggers the "global" hang workaround which you can see in your logs.
4. Any channel or queue that runs on R1 will be affected, since communication to any Erlang process that runs on R2 or R3 is affected by 3. The queues are less of a concern, because the node just booted, so I don't expect queue masters from mirrored queues to migrate onto this node so soon. Having said that, this line might be problematic, specifically forcing queues to rebalance onto R1 which is affected by 3. I cannot imagine how this would work, it's worth digging into.
I tried running "rabbitmq-diagnostics list_unresponsive_queues", but no queue is returned, also "rabbitmq-diagnostics cluster_status" doesn't list anything. I also enabled debugging logging, but don't see anything special. Is there something I should look out for?
As a next step, it would be interesting to look at the Erlang Distribution Grafana dashboard, especially the state of distribution links when R1 is gets updated and DNS gets refreshed correctly. A snapshot is great, but this is better, as @michal explains.
It would be interesting to find out more about the state of the queue master process in question. Can you share the output for this command?
rabbitmqctl eval < queue_process_info.erl
cat queue_process_info.erl
VhostName = "/",
QueueName = "foo",
{ok, Queue} = rabbit_amqqueue:lookup({
resource, list_to_binary(VhostName),
queue, list_to_binary(QueueName)
}),
QueueStat = rabbit_amqqueue:stat(Queue),
io:format("=== QUEUE~n~p~n~n=== QUEUE STAT~n~p~n~n=== QUEUE PROCESS~n", [Queue, QueueStat]),
QueuePid = amqqueue:get_pid(Queue),
recon:info(QueuePid).
Replace VhostName & QueueName with your values.
Is there any way to see based on which internal state the routing decision is made and to see whether the queue master process is tried to be contacted?
This is stored in rabbit_route mnesia table, which will be the same on all nodes. rabbitmqctl list_bindings is already reading from this table, so the command that you ran confirms that the routing is set correctly.
If the routing config is correct, and the queue process is running, the only thing that could affect messages getting delivered is the queue process not receiving those messages. The command above should show us what information is stored about the queue, and the state of the queue process itself.
It would be also most helpful to understand the state of the Erlang Distribution via the dashboard that I linked above.
Let us know how it goes, Gerhard.
joha...@contentful.com
Aug 26, 2020, 5:50:33 PM8/26/20
to rabbitmq-users
Hello Gerhard,
sorry for the late reply.
Here is the output from the script run on the rabbitmq-1 pod (the current queue master):
=== QUEUE
{amqqueue,{resource,<<"/">>,queue,<<"uploadProcessing">>},
true,false,none,
[{<<"x-dead-letter-exchange">>,longstr,<<"failures">>},
{<<"x-dead-letter-routing-key">>,longstr,
<<"failures-uploadProcessing">>}],
<11719.3461.0>,
[<11720.1278.0>],
[<11720.1278.0>],
['rab...@rabbitmq-0.rabbitmq.mgmt-shard-7.svc.cluster.local'],
[{vhost,<<"/">>},
{name,<<"ha-two">>},
{pattern,<<".">>},
{'apply-to',<<"all">>},
{definition,[{<<"ha-mode">>,<<"exactly">>},
{<<"ha-params">>,2},
{<<"ha-sync-mode">>,<<"automatic">>}]},
{priority,0}],
undefined,
[{<11720.1279.0>,<11720.1278.0>},{<11719.3473.0>,<11719.3461.0>}],
[],live,0,[],<<"/">>,
#{user => <<"XYZ">>},
rabbit_classic_queue,undefined}
=== QUEUE STAT
{ok,0,1}
=== QUEUE PROCESS
Error:
{:badarg, [{:erlang, :process_info, [#PID<11719.3461.0>, [:registered_name, :dictionary, :group_leader, :status]], []}, {:recon, :proc_info, 2, [file: 'src/recon.erl', line: 235]}, {:recon, :info_type, 3, [file: 'src/recon.erl', line: 223]}, {:recon, :"-info/1-lc$^0/1-0-", 2, [file: 'src/recon.erl', line: 181]}, {:erl_eval, :do_apply, 6, [file: 'erl_eval.erl', line: 680]}, {:erl_eval, :exprs, 2, []}]}
and here is a 30 min dashboard snapshot https://snapshot.raintank.io/dashboard/snapshot/5a74i4tTquC4AdknBc703aWjkKKPfDrm. In the last 15 mins of the timeframe the entire cluster was rolled once.
Thank you for your time,
Johannes
Michael Klishin
Aug 27, 2020, 11:43:24 AM8/27/20
to rabbitmq-users
See server logs for queue process exceptions. If erlang:process_info returns a badarg, the process may have failed
and therefore cannot accept any routed messages.
joha...@contentful.com
Aug 28, 2020, 10:36:17 AM8/28/20
to rabbitmq-users
Hey Michael,
is there anything specific to look out for, because I don't see any error or exception being logged when the cluster is rolled and all nodes are restarted? Is there a specific prefix to search for?
Thank you,
Johannes
Michael Klishin
Sep 3, 2020, 4:50:11 PM9/3/20
to rabbitmq-users
You are looking for any exceptions present, so there cannot be a prefix known ahead of time.
Johannes Würbach
Sep 11, 2020, 10:37:05 AM9/11/20
to rabbitm...@googlegroups.com
Hey Michael,
I checked again and can't see any exception. With prefix I meant more something to grep for, but even after manually searching the cluster logs I can't see something which looks like an error or exception.
Maybe the queue master is not started at all for whatever reason? Is there a way to manually attempt a restart or list the supposed to be started queue masters?
Thank you,
Johannes
--
You received this message because you are subscribed to a topic in the Google Groups "rabbitmq-users" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/rabbitmq-users/YidEQVCY2NQ/unsubscribe.
To unsubscribe from this group and all its topics, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/2b45c2a7-b28e-4e4d-887b-91e99ec15810o%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages