Logstash + RabbitMQ = Runaway RabbitMQ Memory Usage
810 views
Skip to first unread message

Bryn Hughes
Apr 22, 2019, 5:52:35 PM4/22/19
to rabbitmq-users
The scenario:
- Logstash (using its rabbitmq-output plugin) feeds a 3 node RabbitMQ cluster behind an F5 load balancer
- RabbitMQ has a single fanout exchange bound to a single lazy queue, which is configured as HA across all nodes
- A shovel runs shipping data from the queue to another RabbitMQ cluster
- Logstash 5.6.4
- RabbitMQ 3.7.13
- Erlang 21.2.6
Sending high data rates from Logstash to RabbitMQ seems to cause RabbitMQ's memory usage to run away. A node will eventually hit the high memory watermark and then stop everything. Even though no more messages are being published, memory use on the affected nodes will continue to grow far past the high memory watermark. Eventually the node will crash and restart, though it doesn't appear to log anything when this happens beyond the message stating that the high memory watermark has been hit. Memory growth only appears to happen when we are hitting the upper limits of performance for RabbitMQ.
The second cluster, which is receiving all of the same messages via the shovel, does not experience any problems. Memory use stays flat there. The second cluster has a more complicated configuration with a topic exchange, multiple fanout exchanges and multiple queues. Memory use stays below 1GB and does not increase during periods of high message load. To me that would seem to indicate the content of the messages is not related to whatever the problem we're having here is. The second cluster is seeing higher total throughput rates as well since many messages are sent to more than one queue via fanout exchanges, but again it does not seem to have any problems. However, if I connect Logstash directly to this cluster rather than going through the intermediate one above the same memory consumption issues will occur; the memory consumption follows the Logstash publisher.
Let's look at a node's memory use through this scenario... After the first burst of messages, this is what we see:
Even when traffic levels return to 'normal', no memory is released. However we are still healthy at this point... Once the traffic subsides, we see this:

A few minutes later, we've crossed our high watermark (3.1GB) and publishers have been blocked:

There's basically nothing happening in the cluster; the queues are empty, there's not much GC going on, everything has stopped:


However, memory usage is still growing in the node:


At this point we're done; restarting the node is the only thing I can do to restore service.
So what I've learned:
- This issue follows the Logstash producers; if I move them to another cluster, the problem occurs there
- We have tried enabling background_gc with no change
- This issue does NOT occur unless traffic levels are high
- I can trigger this problem easily by ingesting a few hundred MB of logs from a single machine
- I have a reproducible test now; I have a sample data set that I can re-ingest whenever I want which will consistently break the cluster
- We have made a few changes to try and troubleshoot; we're currently running with these options:
RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS='+MHas ageffcbf +MBas ageffcbf +MHlmbcs 512 +MBlmbcs 512 +MMscs 4096'Would very much like to sort this out! I can easily reproduce this in my QA environment so I have a good place to test...
Thanks,
Bryn

Michael Klishin
Apr 23, 2019, 9:18:32 AM4/23/19
to rabbitmq-users
Hi,
We've recommended a number of things in separate threads before. None of them seem to have helped. Most of memory according to the breakdown
are used by the binary heap and allocators, which RabbitMQ has no control over (the Erlang runtime does).
We have long running environments that publish way more than a few 100 MBs, usually 24/7. They do not exhibit this issue
(although they also may be restarted sometimes every few hours as new alpha builds are deployed).
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
MK
Staff Software Engineer, Pivotal/RabbitMQ
Bryn Hughes
Apr 23, 2019, 12:19:05 PM4/23/19
to rabbitmq-users
Unfortunately we're kind of old school; RHEL VMWare images which I can't really share... I'm happy to share the Logstash configuration and versions but that requires a lot more work for someone...
Other testing I've done today included removing the load balancer from the equation so producers are connecting directly (no change), and updating RabbitMQ to 3.7.14 and Erlang to 21.3.6 (also no change).
Other testing I've done today included removing the load balancer from the equation so producers are connecting directly (no change), and updating RabbitMQ to 3.7.14 and Erlang to 21.3.6 (also no change).
I believe I've isolated the problem now; it appears to be related to TLS. I'm currently running the exact same configuration / testing that I've been doing with TLS turned off on the producers and I'm not seeing any memory spikes beyond what I would expect for managing the queues and unack'd messages. Memory is balanced across all the nodes even at "maxed out" throughput. I'll re-run the test again with TLS switched back on to verify but it very much seems like the culprit at this point. Logstash is using TLS v1.2 by default; we haven't configured anything else.
I'm going to re-check my work but it seems like we are losing data when we get in to these memory errors; I have gaps in my log data on the other end of things that correspond with the RabbitMQ problems. It almost seems like Rabbit is continuing to accept data when in its 'bad' state; perhaps that's what the binary memory use is all about.
Exact same workload, running for more than long enough to trigger the problem normally, TLS off on the producer:

Bryn
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitm...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Luke Bakken
Apr 23, 2019, 12:33:49 PM4/23/19
to rabbitmq-users
Hi Bryn,
The rabbitmq_mqtt section is there to demonstrate the setting if you're using the MQTT plugin, and I've left the background GC setting in place since you can probably use that.
The above settings will work in a rabbitmq.config or advanced.config file, if you're using rabbitmq.conf. Please note that if you're using rabbitmq.conf all of the rabbit-section settings must be migrated to advanced.config. Let me know if you have questions about that.
Thanks for the information about TLS being the source of this issue. There is a setting you should try to specifically address TLS memory use (http://erlang.org/doc/man/ssl.html#type-hibernate_after):
[
{rabbit, [
{background_gc_enabled, true},
{background_gc_target_interval, 10000},
{ssl_options, [
{hibernate_after, 500}
]},
]},
{rabbitmq_mqtt, [
{ssl_options, [
{hibernate_after, 500}
]},
]}
].
The rabbitmq_mqtt section is there to demonstrate the setting if you're using the MQTT plugin, and I've left the background GC setting in place since you can probably use that.
The above settings will work in a rabbitmq.config or advanced.config file, if you're using rabbitmq.conf. Please note that if you're using rabbitmq.conf all of the rabbit-section settings must be migrated to advanced.config. Let me know if you have questions about that.
If you apply the above changes, restart RabbitMQ and re-enable TLS. If the issue is resolved, you can experiment with larger timeout values for both hibernate_after and background GC.
Thanks,
Luke
Michael Klishin
Apr 23, 2019, 12:50:14 PM4/23/19
to rabbitmq-users
I'm going to comment on the data loss part.
and eventually time out. If a publisher is not ready to handle such scenarios, data can and likely will be lost.
I am not familiar with modern Logstash enough to tell whether that's the case but March Hare, the client it uses, will not do any internal
buffering for such timing out writes, even though it is notified when ti is blocked. The reason for that is two-fold:
* With large messages and/or rates the process would run out of heap quickly
* Writing such data to disk to replay is a better option but non-trivial to get right and can be a no-go in increasingly common environments
where applications are not meant to rely on a local filesystem for anything (because Teh Cloud™, 12 Factor and other One Size Fits All ideas)
While I'd be happy to address this in March Hare and/or RabbitMQ Java client one day, there is no consensus as to how this feature should behave.
Also, Logstash arguably could do this first.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
Apr 23, 2019, 2:05:02 PM4/23/19
to rabbitmq-users
Hi Luke,
No change with the 'hibernate_after' option; I get in to a stuck state in less than 10 minutes just like before. Tested both with and without the load balancer between logstash and rabbit.
Reading through the docs, I'm not sure that this setting would apply in our case anyhow as we aren't creating or destroying connections really; active connections aren't really getting in to a state where they would be hibernating, and the total number of connections is only a dozen or so.
{rabbit, [
{tcp_listeners, []},
{ssl_listeners, [{"----------------", 5671}]},
{ssl_options, [{cacertfile,"/etc/rabbitmq/cacert.pem"},
{certfile,"/etc/rabbitmq/-------------.pem"},
{keyfile,"/etc/rabbitmq/private/--------------.key"},
{verify,verify_peer},
{depth, 3},
{fail_if_no_peer_cert,false},
{hibernate_after, 500}]},
{auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]},
{vm_memory_high_watermark, 0.40},
{disk_free_limit, {mem_relative, 1.00}},
{background_gc_enabled, true},
{background_gc_target_interval, 10000}
]},
I also tried setting server_reuse_sessions to false after digging through some other erlang docs, no dice there either.
Again, thanks for your help,
Bryn
Michael Klishin
Apr 23, 2019, 4:00:37 PM4/23/19
to rabbitmq-users
Have you compared to a setup where HAproxy performs TLS terminations and all connections to RabbitMQ nodes are plain TCP?
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
Apr 23, 2019, 4:39:42 PM4/23/19
to rabbitmq-users
Re: Data Loss:
Bryn
Bryn Hughes
Apr 23, 2019, 4:42:52 PM4/23/19
to rabbitmq-users
I haven't no; based on what I've seen so far I'd expect that to work fine, but I suppose I could run a test. I think I have a spare machine I can use... Might be interesting just in case there's something funky in the logstash TLS code pathway.
We got flagged previously on one of our security audits for having unencrypted AMQP so any solution I use needs to end up with TLS on the wire, but I can test and report back.
Bryn
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitm...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Michael Klishin
Apr 24, 2019, 3:04:57 AM4/24/19
to rabbitmq-users
Well, if there's evidence that Erlang's TLS implementation causes runaway binary heap growth then using TLS termination may be
the only option for now.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
Apr 26, 2019, 12:10:02 PM4/26/19
to rabbitmq-users
Elastic has opened an issue around Logstash not correctly handling back pressure when RabbitMQ is blocking publishers:
Curious as to what RabbitMQ does when a client publishes data despite the channel being blocked? Just wondering if this could be tied to the near-linear memory growth we see here. If we're say, starting to block connections when the node is busy but the producer keeps sending anyways, could that lead to the runaway memory growth?
Bryn
Michael Klishin
Apr 28, 2019, 7:13:09 PM4/28/19
to rabbitmq-users
RabbitMQ does not do anything as it does not read from the socket of a blocked client.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
May 1, 2019, 1:56:47 PM5/1/19
to rabbitmq-users
I'll toss out the theory then that Erlang is receiving the data, buffering it but RabbitMQ is not reading it which in turn leads to binary memory growth. I'm not a programmer; just trying to understand the issue.
Bryn
Michael Klishin
May 2, 2019, 6:32:50 AM5/2/19
to rabbitmq-users
If RabbitMQ does not read from the socket, eventually TCP socket buffers on the sender end will fill up and the OS will block or reject writes. So there's only so much
data that a TLS socket process can read that way. It would also not explain why this only happens with TLS enabled.
Have you tried using HAproxy or similar for TLS termination?
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
May 2, 2019, 12:07:08 PM5/2/19
to rabbitmq-users
When TLS is enabled, RabbitMQ becomes the bottleneck. With TLS off, it is fast enough that it never needs to block the channel. I could probably try throwing more load at it with TLS off to confirm that theory...
I haven't retested with haproxy yet.
Bryn
Michael Klishin
May 2, 2019, 2:29:59 PM5/2/19
to rabbitmq-users
TLS introduced about 30-35% overhead for publishers, at least it was the case a few years ago when Mirantis did the benchmarking.
Publishers have to do so little work compared to RabbitMQ than with a fast client such as Java one (used by Logstash via March Hare), it always will outpace
a single channel which can only use a single core for most of what it does.
The question is whether the binary heap is growing in with TLS termination.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Michael Klishin
May 8, 2019, 12:54:00 PM5/8/19
to rabbitmq-users
A pretty interesting finding from the Erlang/OTP team: [1].
An attempted fix so far had a regression (in 21.3.8) that would be problematic for RabbitMQ users. They are looking
into an alternative fix.

Jozsef Basa
May 10, 2019, 3:41:56 AM5/10/19
to rabbitmq-users
Hi
We have the same problem dispite the fact that our logstash publishers don't use TLS because they run on the same node as one of the node of the RMQ cluster. I checked the log of logstash instances on both the shipper and the indexer (ES) side but no error.
So you are right it looks that the malfunctioning cluster accepting messages but exchages don't route them to the bound queues.
RMQ 3.7.10
Erlang 21.2.4
Two 3-nodes cluster with exchange and queue federation between them
Jozsef
Michael Klishin
May 10, 2019, 12:48:46 PM5/10/19
to rabbitmq-users
Let's keep this thread on point. It had nothing to do with routing originally and was narrowed down to a specific setup
and an Erlang TLS implementation issue reported independently.
3.7.10 is 4 patch releases behind, including a few issues highly relevant to Logstash users [1].
Routing can be set up incorrectly (it's applications that control it), so that's no evidence of a malfunctioning cluster.
This is, in fact, common enough that in 3.8 there will be a new metric to make troubleshooting easier [2].
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/d3f0840b-15ea-47ff-a782-aa2f981b3507%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Jozsef Basa
May 10, 2019, 2:34:30 PM5/10/19
to rabbitm...@googlegroups.com
Hi Michael,
I expressed myself badly I meant "it looks as if". But actually from the perspective of logstash it is the case. No errors in the logstash log, no errors in the rabbitmq log even on debug level.
Jozsef
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/CAGcLz6XMdwr0_PnLd9Ou4kX8m5KcDB26Mb4UAjyZ3dk%3DZjJrow%40mail.gmail.com.
Michael Klishin
May 10, 2019, 3:15:13 PM5/10/19
to rabbitmq-users
Jozsef,
We use one thread per topic on this list. Please stop posting to an existing (and fairly long running, including at least
one background thread) thread: this one. We have almost certainly gotten to the bottom of this one and currently waiting for [1]
to be merged in order for the OP to give a release that will include it a try.
Unroutable messages are NOT an error as far as RabbitMQ or client libraries are concerned. If an app (such as Logstash) publishes
messages as mandatory and they cannot be routed anywhere, they will be returned. The app has to register a return handler. My guess
is that Logstash does neither (which is not necessarily wrong but makes it much harder to spot routing issues). Non-mandatory unroutable
messages are dropped, with a new metric for drop rate coming in 3.8 to make them easier to spot. Firehose [3] or traffic capture [4] will help
detect those.
So far there was no evidence (cold hard data, e.g. exchange, binding and queue information) or a way to reproduce posted.
We do not guess or speculate on this list, it is too expensive for everyone involved. Please take a look at the exchange
and queue metrics you can find in the management UI [2], specifically:
* Exchange ingress (incoming) rate
* Target queue(s) ingress rate
* Bindings on the exchange and queues
If that doesn't reveal anything (read: the topology seems correct), see [3][4]. Well over 80% of routing issues are really basic and have to do
with mismatching routing key, misconfigured exchange type or incorrect user expectations. We are highly confident that it is not a routing bug
as nothing around routing by built-in exchanges has changed for years.
Please DO NOT respond to this thread. I would really like to have a channel for the OP here to post an update
on whether [1] made any difference. Thanks.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/CACm8b41On07YAVfB3mqtz7rdCcH22OzRxPe25tc3ZZ%3DMCtaYDA%40mail.gmail.com.
For more options, visit https://groups.google.com/d/optout.
Bryn Hughes
May 30, 2019, 1:15:59 PM5/30/19
to rabbitmq-users
Interesting reading... Certainly sounds very similar to my issue!! One caveat I'll throw out there is I have reproduced the problem while running with TLS off on the logstash servers sending data to RabbitMQ. The TLS module is still enabled and in the config of my RabbitMQ servers, I'm just not sending data to the port. Not sure if the bug described would come in to play in that scenario or not.
I have updated my QA cluster to 3.7.15 / erlang 22.0.1 today; are you saying you believe the fix from ERL-934 is likely to cause a regression?
Thanks!
Bryn
Michael Klishin
May 30, 2019, 3:00:30 PM5/30/19
to rabbitmq-users
ERL-934 [1] is marked as resolved in 22.0.1. [2] contains evidence that an alternative
solution that does not suffer from ERL-938 is also available in 21.3.8.2 [2] (at least that group of commits is included
in the 21.3.8.2 tag).
I suggest that you give Erlang 22.0.1 a shot in a separate environment first. Our digging wasn't very deep but it suggested
that RabbitMQ or its networking dependencies were not responsible for ERL-938.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To post to this group, send email to rabbitm...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/82f13aa6-966e-4446-8e84-cb2f0794600b%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Michael Klishin
May 30, 2019, 3:01:51 PM5/30/19
to rabbitmq-users
Speaking of trying things and reporting back, ERL-934 includes a comment from 5 days ago that says:
«I wanted to provide an update from our side: we have been running a new server version built using OTP 21.3.8.2
for about 5 days now. So far it seems to be running well and memory usage is back to the usual levels.
It seems like the issue is resolved and we will roll it out to more servers over the coming weeks.»
for about 5 days now. So far it seems to be running well and memory usage is back to the usual levels.
It seems like the issue is resolved and we will roll it out to more servers over the coming weeks.»
which sounds promising to me.
Bryn Hughes
May 31, 2019, 1:39:05 PM5/31/19
to rabbitmq-users
Running with erlang-22.0.1 was no help - can't definitively say it was "worse" but it certainly wasn't any better.
I've reverted one of my clusters to 21.3.8.2 now, and I'll continue to monitor.
Thanks for the ongoing support!
Bryn
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/82f13aa6-966e-4446-8e84-cb2f0794600b%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--MKStaff Software Engineer, Pivotal/RabbitMQ
Bryn Hughes
Jun 13, 2019, 12:38:12 PM6/13/19
to rabbitmq-users
Erlang 21.3.8.2 appears to be significantly better behaved. After nearly 2 weeks I haven't had any issues on 21.3.8.2 even with TLS turned on. Memory use is much more stable.
For comparison, yesterday I ran in to a traffic storm in one of my environments that was on erlang-21.2.6. I could run for about 5 minutes tops before a node would go in to an alarm state. After repeatedly restarting nodes I decided to bump the erlang version to 21.3.8.2. Same traffic, memory use hit a peak of about 1.6GB and stayed there.
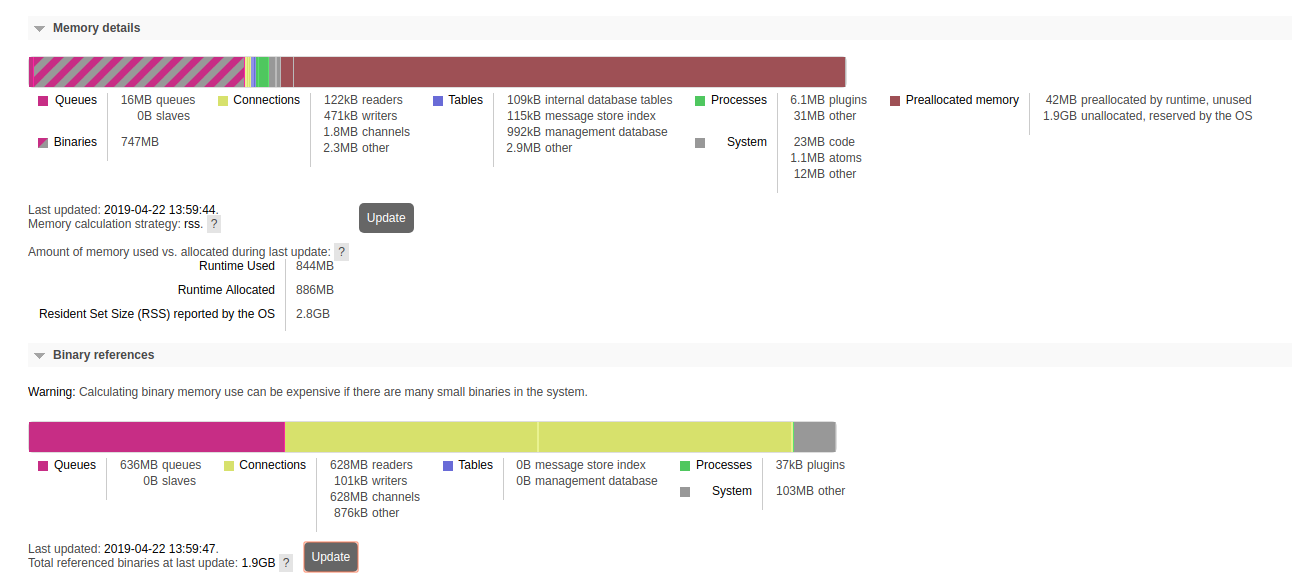
We do still have memory preallocated from our previous config changes, so at the moment that memory is being held as 'preallocated'. Actual binary memory use is less than 20MB at the moment (we're back to 'normal' traffic levels), and the binary memory we are using is all where it should be (there's only 360kB going to 'System' now).
Appears to be a significant improvement!
Bryn
Luke Bakken
Jun 13, 2019, 1:31:39 PM6/13/19
to rabbitmq-users
Hi Bryn,
Thank you very much for reporting back to the list.
Reply all
Reply to author
Forward
0 new messages