RabbitMQ Operator pod crashes with invalid memory address error
517 views
Skip to first unread message

Anjitha M
Apr 12, 2021, 8:11:30 AM4/12/21
to rabbitmq-users
Hi all,
.png?part=0.1&view=1)
I am trying to upgrade to the latest version of rabbitmq cluster operator (1.6.0). I am referring files from here: https://github.com/rabbitmq/cluster-operator/releases/tag/v1.6.0
I haven't made any changes to crd, rbac or any other files.
I had a few queries related to this version of the operator.
1. Since the version I was using before was way older, I am not familiar with the services "rabbitmqcluster" and "rabbitmqcluster-nodes " that came up. Could I get an explanation of what the services would be used for?
2. What I noticed is that when I try to deploy a rabbitmq cluster, the operator pod is in running state for a second but then goes into error state and furtehr goes into crashloopbackoff after multiple restarts.
I am not sure how/ why this error is occuring. Could someone help out/give advice?
Adding the logs from operator pod here for reference.
---------------------------------------------------------------------------------------
I0412 11:51:19.679747 1 request.go:655] Throttling request took 1.038793705s, request: GET:https://240.224.0.1:443/apis/policy/v1beta1?timeout=32s
{"level":"info","ts":1618228283.479199,"logger":"controller-runtime.metrics","msg":"metrics server is starting to listen","addr":":9782"}
{"level":"info","ts":1618228283.4807096,"logger":"setup","msg":"started controller"}
{"level":"info","ts":1618228283.4807374,"logger":"setup","msg":"starting manager"}
I0412 11:51:23.481055 1 leaderelection.go:243] attempting to acquire leader lease do-rabbitmq-ritm0297645/rabbitmq-cluster-operator-leader-election...
{"level":"info","ts":1618228283.5812995,"logger":"controller-runtime.manager","msg":"starting metrics server","path":"/metrics"}
I0412 11:51:40.772596 1 leaderelection.go:253] successfully acquired lease do-rabbitmq-ritm0297645/rabbitmq-cluster-operator-leader-election
{"level":"info","ts":1618228300.7728503,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228301.5742908,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228301.574399,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228301.5744224,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228301.574461,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228302.0586257,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228302.3029594,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228302.4038348,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting EventSource","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","source":"kind source: /, Kind="}
{"level":"info","ts":1618228302.5051785,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting Controller","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster"}
{"level":"info","ts":1618228302.5052876,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Starting workers","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","worker count":1}
{"level":"info","ts":1618228302.6558177,"logger":"controller-runtime.manager.controller.rabbitmqcluster","msg":"Start reconciling","reconciler group":"rabbitmq.com","reconciler kind":"RabbitmqCluster","name":"rabbitmqcluster","namespace":"do-rabbitmq-ritm0297645","spec":"{\"replicas\":3,\"image\":\"gcr.io/sccstgl-saas-gke1-1/sccstglsaasgke1/rabbitmq-operator/rabbitmq:3.8.14\",\"service\":{\"type\":\"LoadBalancer\",\"annotations\":{\"cloud.google.com/load-balancer-type\":\"Internal\",\"cloud.google.com/neg\":\"{\\\"ingress\\\": true}\",\"networking.gke.io/internal-load-balancer-allow-global-access\":\"true\"}},\"persistence\":{\"storageClassName\":\"standard\",\"storage\":\"10Gi\"},\"resources\":{\"limits\":{\"cpu\":\"1\",\"memory\":\"2Gi\"},\"requests\":{\"cpu\":\"1\",\"memory\":\"2Gi\"}},\"rabbitmq\":{\"additionalPlugins\":[\"rabbitmq_sharding\",\"rabbitmq_stomp\",\"rabbitmq_shovel\",\"rabbitmq_federation\",\"rabbitmq_federation_management\"],\"additionalConfig\":\"# vm_memory_high_watermark.relative = 0.7\\ncluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s\\nlog.console.level = debug\\n\"},\"tls\":{},\"override\":{}}"}
E0412 11:51:42.658101 1 runtime.go:78] Observed a panic: "invalid memory address or nil pointer dereference" (runtime error: invalid memory address or nil pointer dereference)
goroutine 708 [running]:
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:74 +0x95
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:48 +0x86
panic(0x16687c0, 0x241b080)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).podTemplateSpec(0xc0011485c0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/workspace/internal/resource/statefulset.go:691 +0x1536
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).Update(0xc0011485c0, 0x1ab2488, 0xc001150500, 0x0, 0x0)
/workspace/internal/resource/statefulset.go:135 +0x217
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1.1(0x0, 0x181f041)
/workspace/controllers/rabbitmqcluster_controller.go:197 +0x44
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.mutate(0xc0010eb888, 0xc00051c690, 0x17, 0xc00051cb10, 0x16, 0x1ab2488, 0xc001150500, 0x1ab2488, 0xc001150500)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:327 +0x2b
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.CreateOrUpdate(0x1a90780, 0xc000c18420, 0x1aa39b8, 0xc000347f40, 0x1ab2488, 0xc001150500, 0xc0010eb888, 0x167e300, 0x167e300, 0x1aa5e18, ...)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:203 +0x1c5
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1(0xaf40af, 0xc000338fa0)
/workspace/controllers/rabbitmqcluster_controller.go:196 +0xab
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:51 +0x3c
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:211 +0x69
k8s.io/apimachinery/pkg/util/wait.ExponentialBackoff(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0xc0010eb9e0, 0x0, 0x0)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:399 +0x55
k8s.io/client-go/util/retry.OnError(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0x193bb40, 0xc0010ebbb8, 0x182135f, 0x9)
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:50 +0xa6
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:104
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile(0xc000341260, 0x1a90780, 0xc000c18420, 0xc0010207f8, 0x17, 0xc00059b010, 0xf, 0xc000c18420, 0xc000030000, 0x16f8ae0, ...)
/workspace/controllers/rabbitmqcluster_controller.go:194 +0x946
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x16bec00, 0xc000391540)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:298 +0x30d
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x0)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:253 +0x205
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start.func1.2(0x1a906d8, 0xc000342000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0x37
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:155 +0x5f
k8s.io/apimachinery/pkg/util/wait.BackoffUntil(0xc0010ebf50, 0x1a603a0, 0xc000c183c0, 0xc000342001, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:156 +0x9b
k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc000810f50, 0x3b9aca00, 0x0, 0x1, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:133 +0x98
k8s.io/apimachinery/pkg/util/wait.JitterUntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00, 0x0, 0x1)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0xa6
k8s.io/apimachinery/pkg/util/wait.UntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:99 +0x57
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:213 +0x40d
E0412 11:51:42.658230 1 runtime.go:78] Observed a panic: "invalid memory address or nil pointer dereference" (runtime error: invalid memory address or nil pointer dereference)
goroutine 708 [running]:
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:74 +0x95
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:48 +0x86
panic(0x16687c0, 0x241b080)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:55 +0x109
panic(0x16687c0, 0x241b080)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).podTemplateSpec(0xc0011485c0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/workspace/internal/resource/statefulset.go:691 +0x1536
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).Update(0xc0011485c0, 0x1ab2488, 0xc001150500, 0x0, 0x0)
/workspace/internal/resource/statefulset.go:135 +0x217
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1.1(0x0, 0x181f041)
/workspace/controllers/rabbitmqcluster_controller.go:197 +0x44
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.mutate(0xc0010eb888, 0xc00051c690, 0x17, 0xc00051cb10, 0x16, 0x1ab2488, 0xc001150500, 0x1ab2488, 0xc001150500)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:327 +0x2b
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.CreateOrUpdate(0x1a90780, 0xc000c18420, 0x1aa39b8, 0xc000347f40, 0x1ab2488, 0xc001150500, 0xc0010eb888, 0x167e300, 0x167e300, 0x1aa5e18, ...)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:203 +0x1c5
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1(0xaf40af, 0xc000338fa0)
/workspace/controllers/rabbitmqcluster_controller.go:196 +0xab
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:51 +0x3c
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:211 +0x69
k8s.io/apimachinery/pkg/util/wait.ExponentialBackoff(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0xc0010eb9e0, 0x0, 0x0)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:399 +0x55
k8s.io/client-go/util/retry.OnError(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0x193bb40, 0xc0010ebbb8, 0x182135f, 0x9)
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:50 +0xa6
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:104
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile(0xc000341260, 0x1a90780, 0xc000c18420, 0xc0010207f8, 0x17, 0xc00059b010, 0xf, 0xc000c18420, 0xc000030000, 0x16f8ae0, ...)
/workspace/controllers/rabbitmqcluster_controller.go:194 +0x946
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x16bec00, 0xc000391540)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:298 +0x30d
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x0)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:253 +0x205
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start.func1.2(0x1a906d8, 0xc000342000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0x37
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:155 +0x5f
k8s.io/apimachinery/pkg/util/wait.BackoffUntil(0xc0010ebf50, 0x1a603a0, 0xc000c183c0, 0xc000342001, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:156 +0x9b
k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc000810f50, 0x3b9aca00, 0x0, 0x1, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:133 +0x98
k8s.io/apimachinery/pkg/util/wait.JitterUntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00, 0x0, 0x1)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0xa6
k8s.io/apimachinery/pkg/util/wait.UntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:99 +0x57
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:213 +0x40d
panic: runtime error: invalid memory address or nil pointer dereference [recovered]
panic: runtime error: invalid memory address or nil pointer dereference [recovered]
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x14b3196]
goroutine 708 [running]:
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:55 +0x109
panic(0x16687c0, 0x241b080)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/runtime/runtime.go:55 +0x109
panic(0x16687c0, 0x241b080)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).podTemplateSpec(0xc0011485c0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/workspace/internal/resource/statefulset.go:691 +0x1536
github.com/rabbitmq/cluster-operator/internal/resource.(*StatefulSetBuilder).Update(0xc0011485c0, 0x1ab2488, 0xc001150500, 0x0, 0x0)
/workspace/internal/resource/statefulset.go:135 +0x217
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1.1(0x0, 0x181f041)
/workspace/controllers/rabbitmqcluster_controller.go:197 +0x44
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.mutate(0xc0010eb888, 0xc00051c690, 0x17, 0xc00051cb10, 0x16, 0x1ab2488, 0xc001150500, 0x1ab2488, 0xc001150500)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:327 +0x2b
sigs.k8s.io/controller-runtime/pkg/controller/controllerutil.CreateOrUpdate(0x1a90780, 0xc000c18420, 0x1aa39b8, 0xc000347f40, 0x1ab2488, 0xc001150500, 0xc0010eb888, 0x167e300, 0x167e300, 0x1aa5e18, ...)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/controller/controllerutil/controllerutil.go:203 +0x1c5
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile.func1(0xaf40af, 0xc000338fa0)
/workspace/controllers/rabbitmqcluster_controller.go:196 +0xab
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:51 +0x3c
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:211 +0x69
k8s.io/apimachinery/pkg/util/wait.ExponentialBackoff(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0xc0010eb9e0, 0x0, 0x0)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:399 +0x55
k8s.io/client-go/util/retry.OnError(0x989680, 0x3ff0000000000000, 0x3fb999999999999a, 0x5, 0x0, 0x193bb40, 0xc0010ebbb8, 0x182135f, 0x9)
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:50 +0xa6
/go/pkg/mod/k8s.io/clie...@v0.20.2/util/retry/util.go:104
github.com/rabbitmq/cluster-operator/controllers.(*RabbitmqClusterReconciler).Reconcile(0xc000341260, 0x1a90780, 0xc000c18420, 0xc0010207f8, 0x17, 0xc00059b010, 0xf, 0xc000c18420, 0xc000030000, 0x16f8ae0, ...)
/workspace/controllers/rabbitmqcluster_controller.go:194 +0x946
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x16bec00, 0xc000391540)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:298 +0x30d
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem(0xc0002472c0, 0x1a906d8, 0xc000342000, 0x0)
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:253 +0x205
sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start.func1.2(0x1a906d8, 0xc000342000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0x37
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:155 +0x5f
k8s.io/apimachinery/pkg/util/wait.BackoffUntil(0xc0010ebf50, 0x1a603a0, 0xc000c183c0, 0xc000342001, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:156 +0x9b
k8s.io/apimachinery/pkg/util/wait.JitterUntil(0xc000810f50, 0x3b9aca00, 0x0, 0x1, 0xc0003ea000)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:133 +0x98
k8s.io/apimachinery/pkg/util/wait.JitterUntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00, 0x0, 0x1)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:185 +0xa6
k8s.io/apimachinery/pkg/util/wait.UntilWithContext(0x1a906d8, 0xc000342000, 0xc000edc5a0, 0x3b9aca00)
/go/pkg/mod/k8s.io/apimac...@v0.20.5/pkg/util/wait/wait.go:99 +0x57
/go/pkg/mod/sigs.k8s.io/controlle...@v0.8.3/pkg/internal/controller/controller.go:213 +0x40d
Thanks,
Anjitha M.

Michal Kuratczyk
Apr 12, 2021, 9:12:20 AM4/12/21
to rabbitm...@googlegroups.com
Hi,
I'm pretty sure the crash is caused by the partial upgrade you performed - you say you "haven't made any changes to crd, rbac or any other files" - you can't upgrade like that. The new operator version assumes what the CRD looks like but in your deployment, the CRD is still old.
The new services are instead of, not apart from, the old ones - we dropped "rabbitmq-client" from the name and replaced "rabbitmq-headless" with "nodes" for the headless service. For newly deployed instances you will only see these two new services but you are trying to upgrade a RabbitMQ cluster deployed with an alpha version of the Operator that was clearly labelled as not ready for production and with no upgrade support. Hence, the Operator does not perform any migration of the old to the new.
The only thing we can recommend is to get rid of all the remains of the old version of the Operator and deploy the new version and similarly - delete the old cluster and deploy a new one. You are in uncharted and unsupported territory if you try to do it any other way.
Just to be clear - this is not how we expect you to upgrade the Operator these days. The Operator is not alpha anymore so even if we change anything, a new Operator version can handle and upgrade an older deployment. I only recommend a completely fresh deployment because you are using such an old alpha version.
Best,
--
You received this message because you are subscribed to the Google Groups "rabbitmq-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to rabbitmq-user...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/ab816153-35a5-402e-b025-5e8befa27aa1n%40googlegroups.com.
Michał
RabbitMQ teamAnjitha M
Apr 12, 2021, 11:25:44 AM4/12/21
to rabbitmq-users
Hi Michal,



Thanks for guiding me through this. I'm really new to rabbitmq so am facing a lot of confusion on how to proceed.
What I have done after getting your reply -
1. I manually applied the latest crd in my GKE cluster - can see that the operator pod is stable now so that issue is resolved.
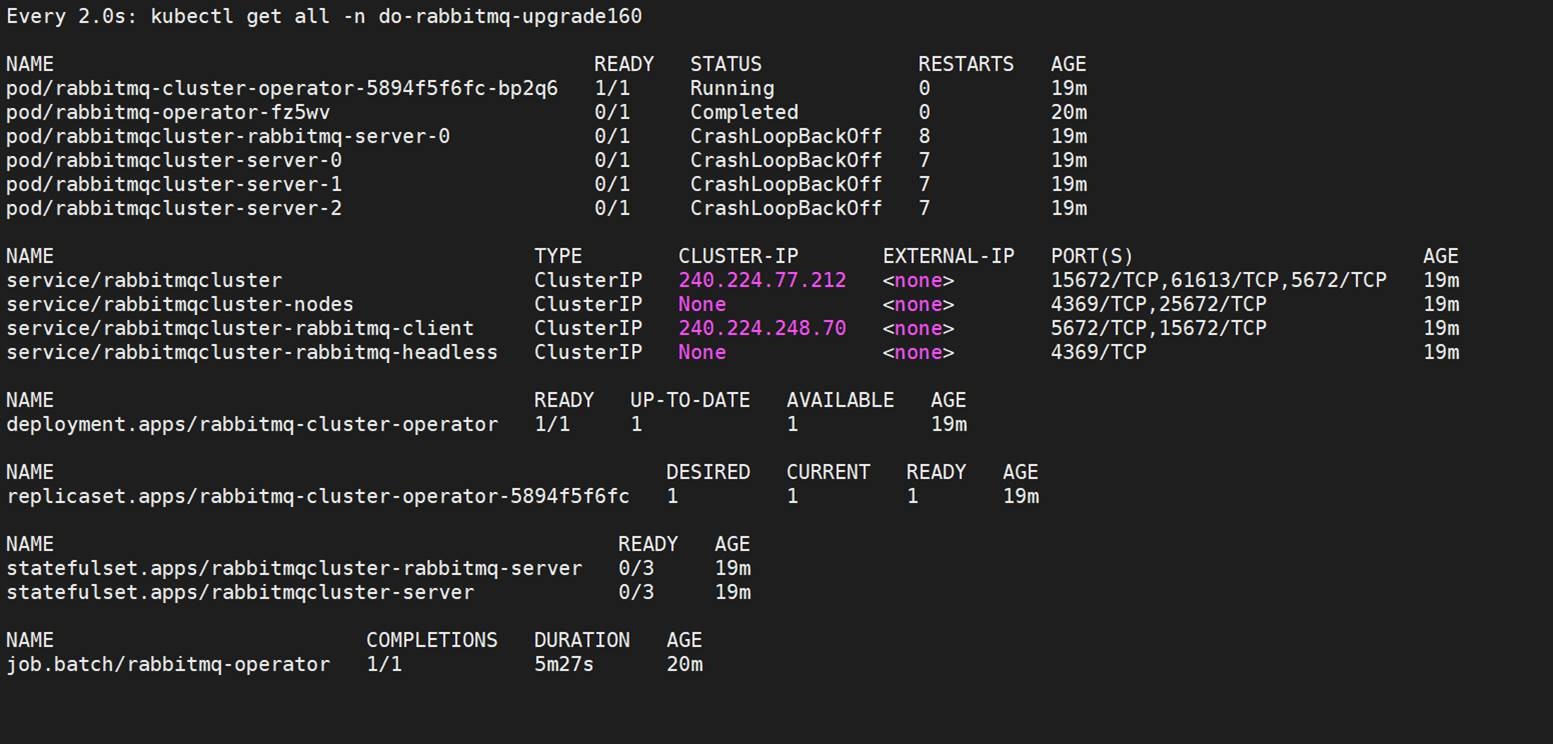
2. However, when I am applying my cr.yaml, I am again seeing errors like, all the pods go into crashloop after coming up. Posting a few screenshots below:
I am confused as to why the pods are either in crash or completed state. Also, if you can see, we are getting the old services here as well.
Also, the pods come up as 0/1 which seems strange? And, the two statefulsets as seen in the screenshots - is that expected?
This is the error I am seeing from the logs:
Hope you can provide answers to these as well!
Thanks,
Anjitha M.
Michal Kuratczyk
Apr 12, 2021, 11:34:47 AM4/12/21
to rabbitm...@googlegroups.com
Hi.
You still have some leftovers from the old cluster - that's why there are 2 statefulsets and why you still see "-client" and "-headless" services.
The last screenshot shows there is an error in the config file - error:{badkey, <<"hostname">>}. Can you show your cr.yml? It may also be caused by some interference of the old instance - not sure.
0/1 means that the pod is running but not ready. "completed" means it crashed too many times and is no longer being restarted. Both issues are probably because of the invalid configuration that causes a crash at startup.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/e8ec7db0-c481-4eb7-97de-48341f277931n%40googlegroups.com.
Michał
RabbitMQ teamAnjitha M
Apr 13, 2021, 5:44:10 AM4/13/21
to rabbitmq-users
Hi Michal,
Here's my cr.yaml for reference:
crYaml: |-
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: rabbitmqcluster
spec:
replicas: 3
image: gcr.io/<path>/rabbitmq:3.8.14
service:
type: LoadBalancer
annotations:
cloud.google.com/load-balancer-type: "Internal"
cloud.google.com/neg: '{"ingress": true}'
persistence:
storageClassName: standard
storage: 10Gi
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 1000m
memory: 2Gi
rabbitmq:
additionalPlugins:
- rabbitmq_sharding
- rabbitmq_stomp
- rabbitmq_shovel
- rabbitmq_federation
- rabbitmq_federation_management
additionalConfig: |
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
log.console.level = debug
override:
statefulSet:
spec:
template:
spec:
terminationGracePeriodSeconds: 7200
containers:
- name: rabbitmq
volumeMounts:
- mountPath: /opt/rabbitmq/community-plugins
name: community-plugins
volumes:
- name: community-plugins
emptyDir: {}
initContainers:
- command:
- sh
- -c
- |
curl -H "Authorization: Bearer <token>" <link to download> --output <output path here>
image: curlimages/curl
imagePullPolicy: IfNotPresent
name: copy-community-plugins
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 500m
memory: 1Gi
terminationMessagePolicy: FallbackToLogsOnError
volumeMounts:
- mountPath: /community-plugins/
name: community-plugins
Hope this helps.
Thanks,
Anjitha M.
Michal Kuratczyk
Apr 13, 2021, 9:53:27 AM4/13/21
to rabbitm...@googlegroups.com
Hi,
I don't know whether you still have a problem. Have you cleaned up your environment? From the screenshot you provided previously, I could see that you applied the same cr.yml with the old and the new Operator running - that's why you had pods named "rabbitmqcluster-rabbitmq-server-0" and "rabbitmqcluster-server-0".
As for that cr.yml - just two minor points:
- `terminationGracePeriodSeconds` - no need to do that in the override section (https://www.rabbitmq.com/kubernetes/operator/using-operator.html#TerminationGracePeriodSeconds)
- `cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s` can be removed - clustering is configured automatically
Neither of these should break anything - it just can be simplified.
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/0fca82ea-f17f-499e-9c18-e979c3c28c0en%40googlegroups.com.
Michał
RabbitMQ teamAnjitha M
Apr 27, 2021, 6:31:48 AM4/27/21
to rabbitmq-users
Hi Michal,
---------------------------------------------------------------------------------
It took us some time, but we are able to successfully deploy 1.6.0 version of rabbitmq operator (with rabbitmq:3.8.14) in a clean GKE environment. No issues this time around.
Now I wanted to run our actual use case by you and get your advice on how to proceed:
We already have rabbitmq-cluster having 3.8.3 or 3.8.5 versions of rabbitmq, with rabbitmq operator version 0.8.0 running in GKE, which is integrated with other applications. We don't want to delete them as they are in use, but we would like to upgrade these to the latest versions.
We are employing a system of Jenkins pipeline automation which will run the necessary kubectl apply commands to apply files like role.yaml, role-binding.yaml, operator.yaml, rabbitmq.yaml etc. What I have noticed is that, when I try to do this, operator.yaml gets applied without issues - which deletes the older operator pod and spins up a new pod which has the newer version.
However, in case of rabbitmq.yaml, it doesn't delete the older pods, but spins up the newer ones. Also, I have noticed that these new rabbitmq pods are going into crashloopbackoff (they're not stable) and when I check the list of services, I can see the services for old version and new version both.
Please see the screenshot attached for reference.
Is there any way I can do a rolling update of some sort (directly from versions as old as 3.8.3) to 3.8.14 without any crashes as observed here?
Points to note: we updated our role.yaml to be as given below:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/component: rabbitmq-cluster-operator
app.kubernetes.io/name: rabbitmq-cluster-operator
app.kubernetes.io/part-of: rabbitmq
name: rabbitmq-cluster-leader-election-role
rules:
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- watch
- create
- update
- patch
- delete
- apiGroups:
- ""
resources:
- configmaps/status
verbs:
- get
- update
- patch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- apiGroups:
resources:
- leases
verbs:
- get
- list
- watch
- create
- update
- patch
- delete
---------------------------------------------------------------------------------
Our jenkins logs is as given:
Processing deploy-cluster request at
Testing connection to Kubernetes namespace
NAME STATUS AGE
do-rabbitmq-forupgrade Active 5d16h
Applying rbac.yaml in do-rabbitmq-forupgrade namespace
Applying operator.yaml in do-rabbitmq-forupgrade namespace
deployment.apps/rabbitmq-cluster-operator configured
Found the running operator pod in do-rabbitmq-forupgrade
Applying rabbitmq.yaml in do-rabbitmq-forupgrade namespace
rabbitmqcluster.rabbitmq.com/rabbitmqcluster configured
------------------------------------------------------------------------------------------
{kind=link}
Michal Kuratczyk
Apr 27, 2021, 6:59:57 AM4/27/21
to rabbitm...@googlegroups.com
Hi,
The issues you see are not due to RabbitMQ upgrade (3.8.x -> 3.8.14) but due to differences in how RabbitMQ is deployed by the old Operator vs the new Operator. Basically all the changes to the StatefulSet, including (but not limited to) rename of the StatefulSet itself, rename of the Services and so on. You definitely need to delete the old StatefulSet and Services manually - because the new Operator version is not aware of these objects but I'm not saying this will solve all the problems. Ultimately, the I see two options:
* Upgrade using blue-green approach https://www.rabbitmq.com/blue-green-upgrade.html - this way you deploy a new cluster, switch your app to use it and the delete the old cluster (this approach is agnostic to whether you use Kubernetes Operator or not)
* Keep the persistent volumes from your old deployment and let the new Operator create new StatefulSet and other resources
As for "crashloopbackoff", this is a very generic symptom - you need to investigate why it happens.
I'm sorry but as I said many times before - you deployed an alpha version in production. It was clearly marked as unsupported and unupgradable. If you insist on upgrading it, please don't expect further support from us.
Best,
To view this discussion on the web, visit https://groups.google.com/d/msgid/rabbitmq-users/b18e456e-e309-436e-9498-4b21f657534an%40googlegroups.com.
Michał
RabbitMQ teamReply all
Reply to author
Forward
0 new messages