INLA vs (g)lm
54 views
Skip to first unread message

Thierry Onkelinx
Apr 2, 2021, 3:28:14 AM4/2/21
to R-inla discussion group
Dear all,
I'm finding a few issues when I compare INLA with lm() and glm(). Could I have feedback on the issues listed below?
Thanks a lot,
Thierry
library(INLA)
ds <- data.frame(
y = c(36831.6112941944, 35948.9994876759, 35919.1918049138, 36030.3590884849,
35672.7335285873, 35219.7770663821, 34125.928752802),
x = 1:7
)
inla(y ~ x, family = "gaussian", data = ds) # inla crashes
# scaling y makes inla work and the results match lm output
ds$y_scaled <- ds$y / 1000
summary(inla(y_scaled ~ x, family = "gaussian", data = ds))
summary(lm(y_scaled ~ x, data = ds))
# glm standard errors are five times smaller
# point estimates match
summary(inla(y ~ x, family = "gamma", data = ds))
summary(glm(y ~ x, family = Gamma(link = "log"), data = ds))
# the discrepancies remain after scaling
summary(inla(y_scaled ~ x, family = "gamma", data = ds))
summary(glm(y_scaled ~ x, family = Gamma(link = "log"), data = ds))
ds <- data.frame(
y = c(36831.6112941944, 35948.9994876759, 35919.1918049138, 36030.3590884849,
35672.7335285873, 35219.7770663821, 34125.928752802),
x = 1:7
)
inla(y ~ x, family = "gaussian", data = ds) # inla crashes
# scaling y makes inla work and the results match lm output
ds$y_scaled <- ds$y / 1000
summary(inla(y_scaled ~ x, family = "gaussian", data = ds))
summary(lm(y_scaled ~ x, data = ds))
# glm standard errors are five times smaller
# point estimates match
summary(inla(y ~ x, family = "gamma", data = ds))
summary(glm(y ~ x, family = Gamma(link = "log"), data = ds))
# the discrepancies remain after scaling
summary(inla(y_scaled ~ x, family = "gamma", data = ds))
summary(glm(y_scaled ~ x, family = Gamma(link = "log"), data = ds))
ir. Thierry Onkelinx
Statisticus / Statistician
Vlaamse Overheid / Government of Flanders
INSTITUUT VOOR NATUUR- EN BOSONDERZOEK / RESEARCH INSTITUTE FOR NATURE AND FOREST
Team Biometrie & Kwaliteitszorg / Team Biometrics & Quality Assurance
thierry....@inbo.be
Havenlaan 88 bus 73, 1000 Brussel
www.inbo.be
INSTITUUT VOOR NATUUR- EN BOSONDERZOEK / RESEARCH INSTITUTE FOR NATURE AND FOREST
Team Biometrie & Kwaliteitszorg / Team Biometrics & Quality Assurance
thierry....@inbo.be
Havenlaan 88 bus 73, 1000 Brussel
www.inbo.be
///////////////////////////////////////////////////////////////////////////////////////////
To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of. ~ Sir Ronald Aylmer Fisher
The plural of anecdote is not data. ~ Roger Brinner
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data. ~ John Tukey
///////////////////////////////////////////////////////////////////////////////////////////
The plural of anecdote is not data. ~ Roger Brinner
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data. ~ John Tukey
///////////////////////////////////////////////////////////////////////////////////////////


Finn Lindgren
Apr 2, 2021, 4:39:08 AM4/2/21
to Thierry Onkelinx, R-inla discussion group
Hi,
the scaling of the linear problem is 1) incompatible with the specified priors (the default fixed effect prior precision is 0.001, i.e. std.dev. 30, and the lm()-estimated -350 is more than 10 times larger) and 2) causes numerical issues.
1) is a model misspecification problem, which can be fixed by changing the fixed effect precision and likely also the prior for the observation precision, but that still leaves 2) causing issues, and
2) is best solved by the rescaling (what also brings the model within reasonable range of the default priors)
For the Gamma case, I'm inclined to guess it's mostly a difference between frequentist standard error and Bayesian posterior standard deviation. For large n I'd expect them to be more similar, but this sample is quite small.
Finn
Finn
--
You received this message because you are subscribed to the Google Groups "R-inla discussion group" group.
To unsubscribe from this group and stop receiving emails from it, send an email to r-inla-discussion...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/r-inla-discussion-group/CAJuCY5zocYNGo3dztMVLkQxx1nAGiB-0NVOJ2BbmiNLbnYHz-A%40mail.gmail.com.

Helpdesk
Apr 2, 2021, 9:35:56 AM4/2/21
to Finn Lindgren, Thierry Onkelinx, R-inla discussion group
to follow up this:
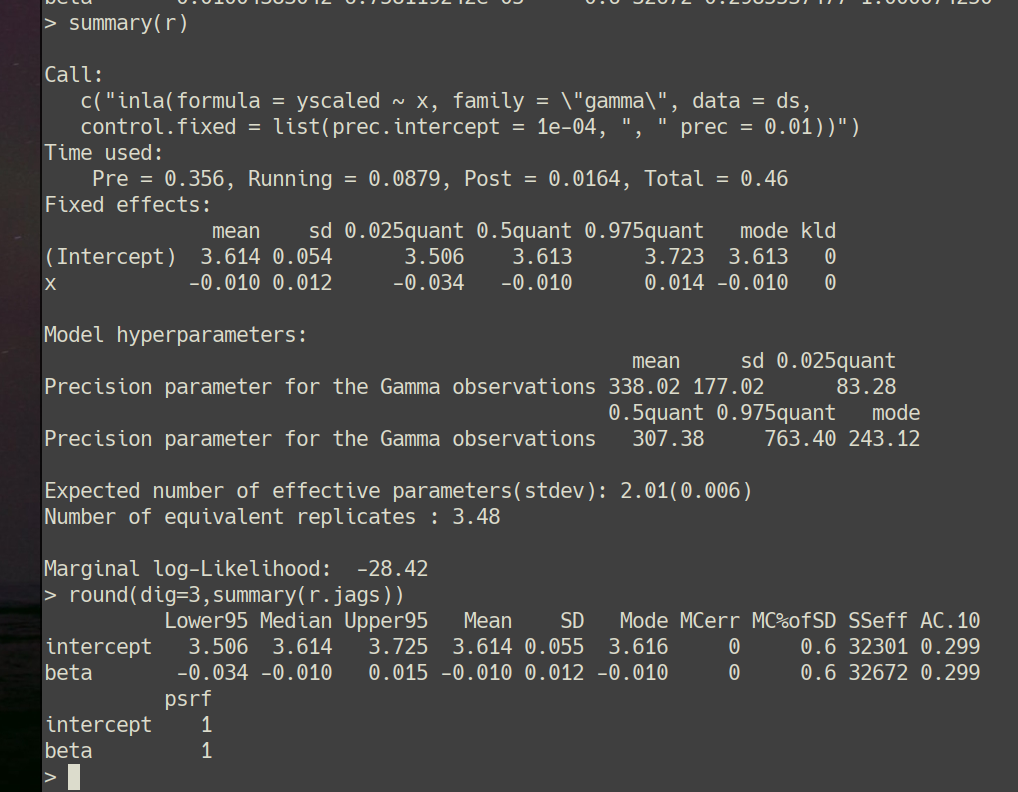
for #2, its a glm() issue, see attached comparison with INLA and JAGS
in this case data are few and glm() does not produce decent uncertainty
results. this is not 'an error' with glm() but a 'feature', as it only
guaranteed to produce good results in the asymptotic limit. The only
issue is that the definition is circular: one is within the 'asymptotic
limit' when the ``results are good''.
about #1, yes there is an issue about scaling, and INLA assumes a
'reasonable input'.
although it would be possible to internally scale everything, this only
will work for straight forward models. joint models, etc, will be hard
to scale automatically.
Best
H
he...@r-inla.org
for #2, its a glm() issue, see attached comparison with INLA and JAGS
in this case data are few and glm() does not produce decent uncertainty
results. this is not 'an error' with glm() but a 'feature', as it only
guaranteed to produce good results in the asymptotic limit. The only
issue is that the definition is circular: one is within the 'asymptotic
limit' when the ``results are good''.
about #1, yes there is an issue about scaling, and INLA assumes a
'reasonable input'.
although it would be possible to internally scale everything, this only
will work for straight forward models. joint models, etc, will be hard
to scale automatically.
Best
H
> > --
> > You received this message because you are subscribed to the Google
> > Groups "R-inla discussion group" group.
> > To unsubscribe from this group and stop receiving emails from it,
> > send
> > an email to r-inla-discussion...@googlegroups.com.
> > To view this discussion on the web, visit
> > https://groups.google.com/d/msgid/r-inla-discussion-group/CAJuCY5zocYNGo3dztMVLkQxx1nAGiB-0NVOJ2BbmiNLbnYHz-A%40mail.gmail.com
> > .
>
>
--
Håvard Rue
> > You received this message because you are subscribed to the Google
> > Groups "R-inla discussion group" group.
> > To unsubscribe from this group and stop receiving emails from it,
> > send
> > an email to r-inla-discussion...@googlegroups.com.
> > To view this discussion on the web, visit
> > https://groups.google.com/d/msgid/r-inla-discussion-group/CAJuCY5zocYNGo3dztMVLkQxx1nAGiB-0NVOJ2BbmiNLbnYHz-A%40mail.gmail.com
> > .
>
>
--
he...@r-inla.org
{kind=link}
Thierry Onkelinx
Apr 2, 2021, 11:02:32 AM4/2/21
to Helpdesk, Finn Lindgren, R-inla discussion group
Dear Håvard and Finn,
I ran a little simulation study comparing glm and inla for the gam family. For large sample sizes, both methods yield comparable results. For smaller samples, INLA provides more robust estimates for the Gamma precision.
Best regards,
Thierry
library(INLA)
run_simulation <- function(
n_data = 1e2, trend = -0.1, start_value = 35000, precision = 700, n_sim = 1e3
) {
replicate(n_sim, {
ds <- data.frame(
x = seq(0, 10, length = n_data)
)
ds$mu <- log(start_value) + log(1 + trend) * ds$x
ds$b <- precision * ds$mu
ds$a <- ds$mu * ds$b
ds$y <- exp(rgamma(n_data, shape = ds$a, rate = ds$b))
frequentist <- glm(y ~ x, family = Gamma(link = "log"), data = ds)
bayesian <- inla(y ~ x, family = "gamma", data = ds)
cf <- coefficients(summary(frequentist))[, c("Estimate", "Std. Error")]
cf <- data.frame(cf)
colnames(cf) <- c("mean", "sd")
c(
unlist(bayesian$summary.fixed[, c("mean", "sd")] / cf),
freq_prec = 1 / (summary(frequentist)$dispersion * precision),
bayes_prec = bayesian$summary.hyperpar$mean / precision
)
})
}
summary(t(run_simulation(n_data = 10)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :0.9999 Min. :1.259 Min. :1.252 Min. :0.3525 Min. :0.2702
# 1st Qu.:1 1st Qu.:1.0000 1st Qu.:1.563 1st Qu.:1.561 1st Qu.:0.8143 1st Qu.:0.4195
# Median :1 Median :1.0000 Median :1.720 Median :1.719 Median :1.0959 Median :0.4701
# Mean :1 Mean :1.0000 Mean :1.814 Mean :1.813 Mean :1.3614 Mean :0.4724
# 3rd Qu.:1 3rd Qu.:1.0000 3rd Qu.:1.994 3rd Qu.:1.994 3rd Qu.:1.6728 3rd Qu.:0.5321
# Max. :1 Max. :1.0001 Max. :4.138 Max. :4.139 Max. :9.0343 Max. :0.6707
summary(t(run_simulation(n_data = 100)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :1 Min. :1.041 Min. :1.040 Min. :0.680 Min. :0.6372
# 1st Qu.:1 1st Qu.:1 1st Qu.:1.063 1st Qu.:1.062 1st Qu.:0.915 1st Qu.:0.8272
# Median :1 Median :1 Median :1.069 Median :1.069 Median :1.000 Median :0.8972
# Mean :1 Mean :1 Mean :1.070 Mean :1.070 Mean :1.023 Mean :0.9117
# 3rd Qu.:1 3rd Qu.:1 3rd Qu.:1.077 3rd Qu.:1.077 3rd Qu.:1.119 3rd Qu.:0.9915
# Max. :1 Max. :1 Max. :1.115 Max. :1.115 Max. :1.661 Max. :1.3680
summary(t(run_simulation(n_data = 1000)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :1 Min. :1.003 Min. :1.002 Min. :0.8815 Min. :0.8764
# 1st Qu.:1 1st Qu.:1 1st Qu.:1.006 1st Qu.:1.006 1st Qu.:0.9710 1st Qu.:0.9647
# Median :1 Median :1 Median :1.007 Median :1.006 Median :1.0017 Median :0.9950
# Mean :1 Mean :1 Mean :1.007 Mean :1.006 Mean :1.0037 Mean :0.9971
# 3rd Qu.:1 3rd Qu.:1 3rd Qu.:1.007 3rd Qu.:1.007 3rd Qu.:1.0359 3rd Qu.:1.0283
# Max. :1 Max. :1 Max. :1.010 Max. :1.010 Max. :1.1695 Max. :1.1579
run_simulation <- function(
n_data = 1e2, trend = -0.1, start_value = 35000, precision = 700, n_sim = 1e3
) {
replicate(n_sim, {
ds <- data.frame(
x = seq(0, 10, length = n_data)
)
ds$mu <- log(start_value) + log(1 + trend) * ds$x
ds$b <- precision * ds$mu
ds$a <- ds$mu * ds$b
ds$y <- exp(rgamma(n_data, shape = ds$a, rate = ds$b))
frequentist <- glm(y ~ x, family = Gamma(link = "log"), data = ds)
bayesian <- inla(y ~ x, family = "gamma", data = ds)
cf <- coefficients(summary(frequentist))[, c("Estimate", "Std. Error")]
cf <- data.frame(cf)
colnames(cf) <- c("mean", "sd")
c(
unlist(bayesian$summary.fixed[, c("mean", "sd")] / cf),
freq_prec = 1 / (summary(frequentist)$dispersion * precision),
bayes_prec = bayesian$summary.hyperpar$mean / precision
)
})
}
summary(t(run_simulation(n_data = 10)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :0.9999 Min. :1.259 Min. :1.252 Min. :0.3525 Min. :0.2702
# 1st Qu.:1 1st Qu.:1.0000 1st Qu.:1.563 1st Qu.:1.561 1st Qu.:0.8143 1st Qu.:0.4195
# Median :1 Median :1.0000 Median :1.720 Median :1.719 Median :1.0959 Median :0.4701
# Mean :1 Mean :1.0000 Mean :1.814 Mean :1.813 Mean :1.3614 Mean :0.4724
# 3rd Qu.:1 3rd Qu.:1.0000 3rd Qu.:1.994 3rd Qu.:1.994 3rd Qu.:1.6728 3rd Qu.:0.5321
# Max. :1 Max. :1.0001 Max. :4.138 Max. :4.139 Max. :9.0343 Max. :0.6707
summary(t(run_simulation(n_data = 100)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :1 Min. :1.041 Min. :1.040 Min. :0.680 Min. :0.6372
# 1st Qu.:1 1st Qu.:1 1st Qu.:1.063 1st Qu.:1.062 1st Qu.:0.915 1st Qu.:0.8272
# Median :1 Median :1 Median :1.069 Median :1.069 Median :1.000 Median :0.8972
# Mean :1 Mean :1 Mean :1.070 Mean :1.070 Mean :1.023 Mean :0.9117
# 3rd Qu.:1 3rd Qu.:1 3rd Qu.:1.077 3rd Qu.:1.077 3rd Qu.:1.119 3rd Qu.:0.9915
# Max. :1 Max. :1 Max. :1.115 Max. :1.115 Max. :1.661 Max. :1.3680
summary(t(run_simulation(n_data = 1000)))
# mean1 mean2 sd1 sd2 freq_prec bayes_prec
# Min. :1 Min. :1 Min. :1.003 Min. :1.002 Min. :0.8815 Min. :0.8764
# 1st Qu.:1 1st Qu.:1 1st Qu.:1.006 1st Qu.:1.006 1st Qu.:0.9710 1st Qu.:0.9647
# Median :1 Median :1 Median :1.007 Median :1.006 Median :1.0017 Median :0.9950
# Mean :1 Mean :1 Mean :1.007 Mean :1.006 Mean :1.0037 Mean :0.9971
# 3rd Qu.:1 3rd Qu.:1 3rd Qu.:1.007 3rd Qu.:1.007 3rd Qu.:1.0359 3rd Qu.:1.0283
# Max. :1 Max. :1 Max. :1.010 Max. :1.010 Max. :1.1695 Max. :1.1579
ir. Thierry Onkelinx
Statisticus / Statistician
Vlaamse Overheid / Government of Flanders
INSTITUUT VOOR NATUUR- EN BOSONDERZOEK / RESEARCH INSTITUTE FOR NATURE AND FOREST
Team Biometrie & Kwaliteitszorg / Team Biometrics & Quality Assurance
thierry....@inbo.be
Havenlaan 88 bus 73, 1000 Brussel
www.inbo.be
INSTITUUT VOOR NATUUR- EN BOSONDERZOEK / RESEARCH INSTITUTE FOR NATURE AND FOREST
Team Biometrie & Kwaliteitszorg / Team Biometrics & Quality Assurance
thierry....@inbo.be
Havenlaan 88 bus 73, 1000 Brussel
www.inbo.be
///////////////////////////////////////////////////////////////////////////////////////////
To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of. ~ Sir Ronald Aylmer Fisher
The plural of anecdote is not data. ~ Roger Brinner
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data. ~ John Tukey
///////////////////////////////////////////////////////////////////////////////////////////
The plural of anecdote is not data. ~ Roger Brinner
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data. ~ John Tukey
///////////////////////////////////////////////////////////////////////////////////////////
Reply all
Reply to author
Forward
0 new messages