INLA for Skewed Distribution
51 views
Skip to first unread message

Noah Silverman
Nov 9, 2022, 5:49:43 AM11/9/22
to R-inla discussion group
Hello,
I have some data where the dependent variable is best described by a skewed Student-T distribution. (It is not centered on zero, has right skew, etc...)
INLA has the Student-T family. But, I don't see anything that would handle the skew. Do I need to "T standardize" my dependent variable first? Or, is there another way to handle this?
I was wondering what you think of the following options:
I have some data where the dependent variable is best described by a skewed Student-T distribution. (It is not centered on zero, has right skew, etc...)
INLA has the Student-T family. But, I don't see anything that would handle the skew. Do I need to "T standardize" my dependent variable first? Or, is there another way to handle this?
I was wondering what you think of the following options:
- Just fit the model with the T family and skewed dependent variable
- Un-skew the dependent variable, using a form of Box-Cox for T distribution
- Normalize the dependent variable to Guassian and fit a standard normal mode
Additionally, given the three choices above, what would be the best model summary statistic to determine the "best" one?
Any ideas or suggestions would be greatly appreciate.
Thank You!!!

Finn Lindgren
Nov 9, 2022, 12:22:22 PM11/9/22
to R-inla discussion group
Hi Noah,
since the observation family applies to the _conditional_ distribution
of the response/dependent variable (or to the regression residuals in
the case of additive error observation families) and not to the
marginal distribution, neither of those options would directly help
with your problem.
In some cases, transforming the marginal distribution of the data as
in your option 2 may be sensible, but that's highly problem dependent.
I would suggest trying option 1 and then looking at the residuals to
see how skewed they are; this is not something one can tell from the
raw observation data; it is a model output.
If the residuals aren't very skewed, it's likely ok. If they are, you
would need to consider further options. (I have some in mind, but they
would be research projects, so not available off-the-shelf...)
Finn
> --
> You received this message because you are subscribed to the Google Groups "R-inla discussion group" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to r-inla-discussion...@googlegroups.com.
> To view this discussion on the web, visit https://groups.google.com/d/msgid/r-inla-discussion-group/ee35255b-0a48-4f92-b689-e6edda029b33n%40googlegroups.com.
--
Finn Lindgren
email: finn.l...@gmail.com
since the observation family applies to the _conditional_ distribution
of the response/dependent variable (or to the regression residuals in
the case of additive error observation families) and not to the
marginal distribution, neither of those options would directly help
with your problem.
In some cases, transforming the marginal distribution of the data as
in your option 2 may be sensible, but that's highly problem dependent.
I would suggest trying option 1 and then looking at the residuals to
see how skewed they are; this is not something one can tell from the
raw observation data; it is a model output.
If the residuals aren't very skewed, it's likely ok. If they are, you
would need to consider further options. (I have some in mind, but they
would be research projects, so not available off-the-shelf...)
Finn
> You received this message because you are subscribed to the Google Groups "R-inla discussion group" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to r-inla-discussion...@googlegroups.com.
> To view this discussion on the web, visit https://groups.google.com/d/msgid/r-inla-discussion-group/ee35255b-0a48-4f92-b689-e6edda029b33n%40googlegroups.com.
--
Finn Lindgren
email: finn.l...@gmail.com

Helpdesk (Haavard Rue)
Nov 9, 2022, 2:49:48 PM11/9/22
to Finn Lindgren, R-inla discussion group
On Wed, 2022-11-09 at 17:22 +0000, Finn Lindgren wrote:
> I would suggest trying option 1 and then looking at the residuals to
the most recent testing version actually have deviance residuals
> I would suggest trying option 1 and then looking at the residuals to
implemented, its for testing only....
inla(..., control.compute=list(residuals=TRUE))
--
Håvard Rue
he...@r-inla.org

JJ Hubbard
Nov 9, 2022, 5:18:24 PM11/9/22
to R-inla discussion group
Are the deviance residuals comparable across data that have been transformed and are on different scales? Or we do need to apply the inverse transform to them?
Noah Silverman
Nov 9, 2022, 10:30:45 PM11/9/22
to R-inla discussion group
Thanks Finn,
I appreciate it.
Helpdesk (Haavard Rue)
Nov 10, 2022, 2:19:35 AM11/10/22
to JJ Hubbard, R-inla discussion group
deviance residuals, in the frequentist sense, are defined as
sign * sqrt(saturated.deviance)
where 'sign' is usually taken as the sign of y-y.predicted
all this is pr observation, so I avoid the _i notation.
In the Bayesian framework, there is no natural definition of residuals,
but we can define it as
sign * sqrt(E(saturated.deviance))
where the E() is over the posterior, like integrating out
hyperparameter(s) and the uncertainty of the linear predictor.
the 'sign' is a different story, as there is no definition of the 'sign'
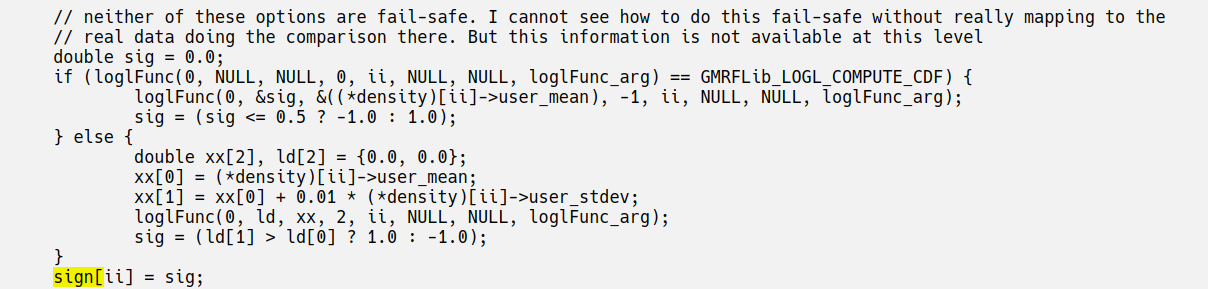
now. it is defined as attached, which is 'very likely' in correspondance
with the freq.definition. Another issue, is that I do not know, in this
part of the code, if data are discrete or not, so...
well, I know all this is a little 'loose', but it is anyhow useful to
have some kind of 'residuals' available, although they should not be
used for any kind of ''testing''-purpose.
of'course, for some models, like binary data, then all this make less
sense, but this is well know
If anyone has other options or other comments, please let us know
Best
H
{kind=link}
JJ Hubbard
Nov 10, 2022, 8:20:48 PM11/10/22
to R-inla discussion group
Thank you very much, I will look into the deviance residuals.
Finn, you said that observation family applies to the _conditional_ distribution, so the family argument in inla() is not determined by the distribution of your target variable, but by the conditional distribution of Y given the predictors?
Finn Lindgren
Nov 11, 2022, 1:25:12 AM11/11/22
to JJ Hubbard, R-inla discussion group
Yes. That’s how virtually all regression models work (it’s not an inla specific thing)
Finn
On 11 Nov 2022, at 01:20, JJ Hubbard <jordanj...@gmail.com> wrote:
Thank you very much, I will look into the deviance residuals.
--
You received this message because you are subscribed to the Google Groups "R-inla discussion group" group.
To unsubscribe from this group and stop receiving emails from it, send an email to r-inla-discussion...@googlegroups.com.
To view this discussion on the web, visit https://groups.google.com/d/msgid/r-inla-discussion-group/343daa9e-e852-452e-8f4a-7e97f04674f4n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages