prototype "fold explorer" ready

SPE Stani's Python Editor
I have written a prototype of the 'fold explorer'. It is quite
wonderful as there is no python specific code in it: everything is
generic. Even to keep to lexing coloring scheme unbiased, I throw in a
picasso lexer which colours the code by inspiration of the moment. So
everytime you start the prototype you will get another color scheme.
It is not useful, but this saves me of writing down colour schemes for
all the 78 languages Scintilla supports.
Some remarks:
- the speed is fast, but I am not sure it is faster than a line
parser. I tried with a file of 6000+ lines and it gave no problems. I
guess when I implement real-time updating we can see how fast is.
- in order to lex the whole document I have first let the control jump
to the last line
- of course besides classes and definitions, everything else which has
folding is also shown like if statements etc.. But if most of the code
is encapsulated in functions and classes it looks (almost) like a
class explorer
- I guess it will only be usable for a (small) subset of the 78
languages as not all languages have folding support and with others it
might not make so much sense. Still it means whatever language gets
folding support by Scintilla, it is immediately exposed to Python
- The hierarchy is extracted in a recursive data class Node by the
scintilla editor of which the root is passed to a wxTreeCtrl. So this
should make easy to port it to other gui toolkits which have a
scintilla control.
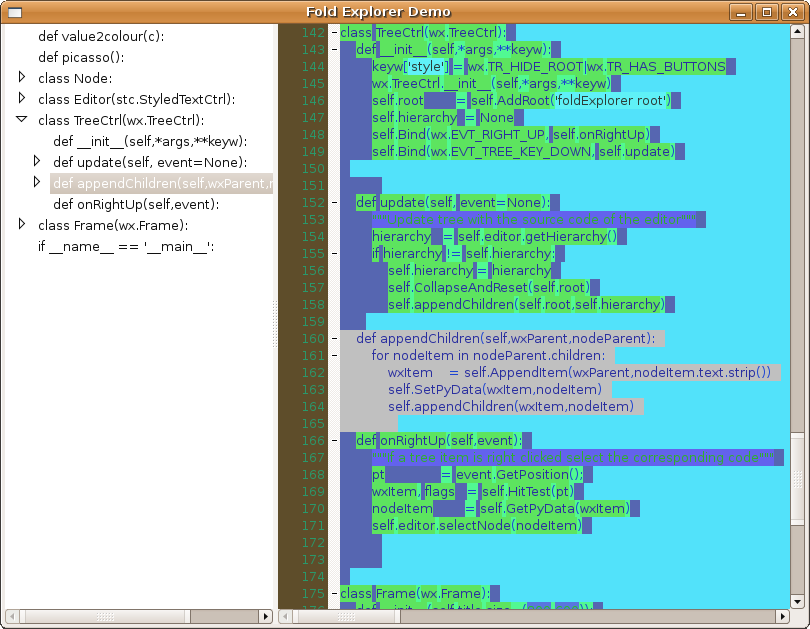
- What is collected of the folding nodes is the folding level, text
and start & end line. As a demonstration: if you right click on a tree
item, the corresponding source is selected (gray in screenshot). This
makes it possible with some further coding to drag and drop code by a
treecontrol. Leo has also this functionality but leaves comments in
the source code.
- If the tree control is active and you press any key, the tree ctrl
gets updated.
- For sure the code can be improved, so any remarks or feedback are welcome.
- It would be nice if some of you try it out with all kind of
languages which have folding support.
Thanks in advance,
Stani

Josiah Carlson
Hi All,
I have written a prototype of the 'fold explorer'. It is quite
wonderful as there is no python specific code in it: everything is
generic. Even to keep to lexing coloring scheme unbiased, I throw in a
picasso lexer which colours the code by inspiration of the moment. So
everytime you start the prototype you will get another color scheme.
It is not useful, but this saves me of writing down colour schemes for
all the 78 languages Scintilla supports.
On Windows (though it should also work on *nix), you need to replace...
self.CollapseAndReset(self.root)
with:
self.DeleteChildren(self.root)
Also, on Windows, until the last bit of the file has actually been seen, it doesn't actually know the fold levels all the way there. Even waiting a few seconds doesn't actually get the latter portion of the file lexed. I've found that by replacing the two wx.CallAfter methods in .open and .setText with a pair of wx.FutureCalls seems to work ok. A single wx.FutureCall that forces the explorer.update, then scrolls back to the first line would probably be better.
Then again, it would be much better if we could get a message from the underlying control when it finished lexing, and/or had the ability to ask it to lex the whole file (and tell us when it was done).
- Josiah
SPE Stani's Python Editor
> On 3/4/07, SPE Stani's Python Editor <spe.st...@gmail.com> wrote:
> > Hi All,
> >
> > I have written a prototype of the 'fold explorer'. It is quite
> > wonderful as there is no python specific code in it: everything is
> > generic. Even to keep to lexing coloring scheme unbiased, I throw in a
> > picasso lexer which colours the code by inspiration of the moment. So
> > everytime you start the prototype you will get another color scheme.
> > It is not useful, but this saves me of writing down colour schemes for
> > all the 78 languages Scintilla supports.
> >
>
>
> Very Nifty.
>
> On Windows (though it should also work on *nix), you need to replace...
> self.CollapseAndReset(self.root)
> with:
> self.DeleteChildren(self.root)
> Also, on Windows, until the last bit of the file has actually been seen, it
> doesn't actually know the fold levels all the way there. Even waiting a few
> seconds doesn't actually get the latter portion of the file lexed. I've
> found that by replacing the two wx.CallAfter methods in .open and .setText
> with a pair of wx.FutureCalls seems to work ok. A single wx.FutureCall that
> forces the explorer.update, then scrolls back to the first line would
> probably be better.
Before I had this:
def setText(self,text):
self.SetText(text)
step = self.LinesOnScreen()
n = self.GetLineCount()
for line in range(0,n,step):
self.GotoLine(line) #make sure everything is lexed
wx.CallAfter(self.explorer.update)
But just going to the last line is fine on Linux. Another option would
be to open a file on the last line. Can you check if that works? But
of course it is not elegant.
> Then again, it would be much better if we could get a message from the
> underlying control when it finished lexing, and/or had the ability to ask it
> to lex the whole file (and tell us when it was done).
Yes, I agree totally but I didn't find any reference how that could be
provoked. Maybe a question for Neil.
Stani
--
http://pythonide.stani.be
http://pythonide.stani.be/screenshots
http://pythonide.stani.be/manual/html/manual.html
Josiah Carlson
self.GotoLine(self.GetLineCount()) #make sure everything is lexed
with:
self.Colourise(0, self.GetTextLength()) #make sure everything is lexed
...it seems to lex the full document on Windows and wxPython 2.6.3.2 and 2.8.0.1
For Windows users, you may want to consider passing the wx.TR_LINES_AT_ROOT style to the Tree control constructor. Without it, the top-level nodes with children aren't indented and don't have '+' next to them.
- Josiah

Rob McMullen
Here's a shot of what it does to a C++ file. Even though coming from
the python side we don't know how C++ is parsed, the folding seems to
give us a good idea of the structure. We could do some pattern
matching on the items in the tree and deduce classes and relationships
from there, rather than writing an entire C++ lexer in python. This
has huge potential.
I did have to change setText to the following, because apparently the
C++ file I chose (Editor.cxx from the Scintilla source) has some
characters outside the 7-bit ascii code, and I got:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xdd in position
32785: ordinal not in range(128)
def setText(self,text):
styled = "\0".join(text) + "\0"
self.Clear()
self.AddStyledText(styled)
self.Colourise(0, self.GetTextLength()) #make sure everything is lexed
wx.CallAfter(self.explorer.update)
I wonder if there's a way to determine from the python side which
languages support folding and which don't? HTML, for example, doesn't
produce any folding -- I had thought it might because of the nesting
of tags.
Rob
SPE Stani's Python Editor
> This is great, Stani!
Thanks, I was suprised myself as well. Scintilla has already a lot of
functionality, which is not always fully exploited.
> Here's a shot of what it does to a C++ file. Even though coming from
> the python side we don't know how C++ is parsed, the folding seems to
> give us a good idea of the structure. We could do some pattern
> matching on the items in the tree and deduce classes and relationships
> from there, rather than writing an entire C++ lexer in python. This
> has huge potential.
Yes it seem to work quite well. I think indeed this is the best base
to fetch the documents hierarchy, maybe even for python. Things which
I had on my mind was:
- collect the styles of every line by splitting a line into words and
symbols and get the style of the first charachter of them
We could write a generic method which translates a list of styles of
the line into a 'style' for a tree item, which includes an icon
bitmap, text colour, ... This will pimp up the generic fold explorer
as if it was already a specific language class explorer. First we
should do as much generic as possible, as than the language specific
part will be reduced to a minimum. For the language specific part we
need clear guidelines so other people can easily write their own. Even
for the language specific class explorer, we could provide already
some tools. For example we should have a standard mechanism for fake
nodes: in python this is eg. if statements, try except, etc... Fake
nodes will be invisible in the explorer and the tree level of the
children is not increased, but is the same as the fake node.
For example:
def hello_world():
pass
if linux:
class Widget:
def __init__(self):
pass
Becomes in the tree:
def hello_world():
(if linux:) #invisible
class Widget:
def __init__(self):
I think by recognizing the fake nodes (with eg regular expression) we
can transform easily the fold explorer in the class explorer, but
still I think the fold explorer is still valuable on its own even if
there is also the class explorer implemented.
Labels are easy to implement, but are language specific. For a
language one can define a regular expression what defines a label (in
python most used is '#---label'). Than in getHierarchy we get:
if foldBits&stc.STC_FOLDLEVELHEADERFLAG:
(...)
elif re.sub(label):
(...)
We could define checkboxes with options what should appear in the
class explorer. For example todo could be inside or not (implemented
same as label). But for a seperate todo table, there is no need for
hierarchy. You just need a regular expression with finditer.
> I did have to change setText to the following, because apparently the
> C++ file I chose (Editor.cxx from the Scintilla source) has some
> characters outside the 7-bit ascii code, and I got:
> UnicodeDecodeError: 'ascii' codec can't decode byte 0xdd in position
> 32785: ordinal not in range(128)
>
> def setText(self,text):
> styled = "\0".join(text) + "\0"
> self.Clear()
> self.AddStyledText(styled)
> self.Colourise(0, self.GetTextLength()) #make sure everything is lexed
> wx.CallAfter(self.explorer.update)
Is this not more generic?
def open(self,fileName, language, encoding=DEFAULT_ENCODING, line=0):
self.setLanguage(language)
self.setText(open(fileName).read(),encoding)
wx.CallAfter(self.GotoLine,line)
def setText(self,text,encoding=DEFAULT_ENCODING):
self.encoding = encoding
self.SetText(text.decode(encoding))
self.Colourise(0, self.GetTextLength()) #make sure everything is lexed
wx.CallAfter(self.explorer.update)
> I wonder if there's a way to determine from the python side which
> languages support folding and which don't? HTML, for example, doesn't
> produce any folding -- I had thought it might because of the nesting
> of tags.
Me too. Josiah, any idea?
Realtime updating is also which belongs to the generic part. Therefore
we need to be able to diffs between a previous state and a current
state and to add a property expanded (True/False) to the nodes. Again
if we implement this in a generic way, we get everything for free for
all languages.
Another thing is that fold explorer will be a good tool for what I
will define local code blocks. For example now SPE compiles the whole
file to check for syntax errors which SPE underlines with a red
marker. With Scintilla we could get the visible lines on the screen,
fetch which codeblocks are involved from the fold explorer and than we
need only to compile these blocks to check for syntax errors. This
means for huge files only a very small proportion is shown on the
screen, so you could have realtime syntax checking there. Maybe with
subprocesses this could be done also for other languages as python.
This would be amazing.
Stani

{kind=link}
{kind=link}
Ali Afshar
> I wonder if there's a way to determine from the python side which
> languages support folding and which don't? HTML, for example, doesn't
> produce any folding -- I had thought it might because of the nesting
> of tags.
Is that any different from nested code blocks?
SPE Stani's Python Editor
> On 3/5/07, Rob McMullen <rob.mc...@gmail.com> wrote:
> > I wonder if there's a way to determine from the python side which
> > languages support folding and which don't? HTML, for example, doesn't
> > produce any folding -- I had thought it might because of the nesting
> > of tags.
> Me too. Josiah, any idea?
Value Folding? properties
wxSTC_LEX_ADA no no
wxSTC_LEX_ASP no see wxSTC_LEX_HTML
wxSTC_LEX_AUTOMATIC N.A. N.A.
wxSTC_LEX_AVE no? "fold" (not implemented?)
wxSTC_LEX_BAAN yes "styling.within.preprocessor"
"fold.comment"
"fold.compact"
wxSTC_LEX_BATCH no no
wxSTC_LEX_BULLANT no? "fold" (not implemented?)
wxSTC_LEX_CONF no no (Apache config files)
wxSTC_LEX_CONTAINER N.A. N.A.
wxSTC_LEX_CPP yes "styling.within.preprocessor"
"fold.comment"
"fold.preprocessor"
"fold.compact"
wxSTC_LEX_DIFF no no
wxSTC_LEX_EIFFEL yes no
wxSTC_LEX_EIFFELKW yes no
wxSTC_LEX_ERRORLIST no no
wxSTC_LEX_HTML no "asp.default.language" (javascript)
"fold.html"
"fold"
"fold.compact"
wxSTC_LEX_LATEX no no
wxSTC_LEX_LISP yes no
wxSTC_LEX_LUA yes "fold.compact"
wxSTC_LEX_MAKEFILE no no
wxSTC_LEX_MATLAB yes no
wxSTC_LEX_NNCRONTAB no no
wxSTC_LEX_NULL N.A. Null language just handles the protocol but does
nothing. Use for plain text.
wxSTC_LEX_PASCAL yes "fold.comment"
"fold.preprocessor"
"fold.compact"
wxSTC_LEX_PERL yes no
wxSTC_LEX_PHP no see wxSTC_LEX_HTML
wxSTC_LEX_PROPERTIES no no
wxSTC_LEX_PYTHON yes "fold.comment.python"
"fold.quotes.python"
"tab.timmy.whinge.level"
wxSTC_LEX_RUBY yes "tab.timmy.whinge.level"
wxSTC_LEX_SCRIPTOL Unknown Although defined, support doesn't exist.
wxSTC_LEX_SQL yes "fold"
wxSTC_LEX_TCL yes see wxSTC_LEX_CPP
wxSTC_LEX_VB yes no
wxSTC_LEX_VBSCRIPT yes no
wxSTC_LEX_XCODE Unknown Although defined, support doesn't exist. It's
for for DevelopMentor's GenX product.
wxSTC_LEX_XML no see wxSTC_LEX_HTML
But still a dynamic way would be better. I posted a question on the
scintilla mailing list.
Stani
--
http://pythonide.stani.be
SPE Stani's Python Editor
Hi Ali, nice to hear from you again.
> On 05/03/07, Rob McMullen <rob.mc...@gmail.com> wrote:
>
> > I wonder if there's a way to determine from the python side which
> > languages support folding and which don't? HTML, for example, doesn't
> > produce any folding -- I had thought it might because of the nesting
> > of tags.
It *does*, if you change this:
def setFoldMargin(self):
self.SetProperty("fold", "1")
self.SetProperty("fold.html","1")
(...)
> Is that any different from nested code blocks?
How do you mean?
SPE Stani's Python Editor
> On 3/5/07, Ali Afshar <aaf...@gmail.com> wrote:
> Hi Ali, nice to hear from you again.
>
> > On 05/03/07, Rob McMullen <rob.mc...@gmail.com> wrote:
> >
> > > I wonder if there's a way to determine from the python side which
> > > languages support folding and which don't? HTML, for example, doesn't
> > > produce any folding -- I had thought it might because of the nesting
> > > of tags.
> It *does*, if you change this:
> def setFoldMargin(self):
> self.SetProperty("fold", "1")
> self.SetProperty("fold.html","1")
> (...)
http://pythonide.stani.be
Stani
Josiah Carlson
Realtime updating is also which belongs to the generic part. Therefore
we need to be able to diffs between a previous state and a current
state and to add a property expanded (True/False) to the nodes. Again
if we implement this in a generic way, we get everything for free for
all languages.
I actually implemented a variant of 'diff in place' method for trees after seeing yours. It doesn't handle renames very well (it ends up recreating the subtree of a named node), but it seemed to speed up the tree manipulations that PyPE was doing. I need to release a new version of PyPE soon, so I'll let everyone know where the code can be found when it is available.
Another thing is that fold explorer will be a good tool for what I
will define local code blocks. For example now SPE compiles the whole
file to check for syntax errors which SPE underlines with a red
marker. With Scintilla we could get the visible lines on the screen,
fetch which codeblocks are involved from the fold explorer and than we
need only to compile these blocks to check for syntax errors. This
means for huge files only a very small proportion is shown on the
screen, so you could have realtime syntax checking there. Maybe with
subprocesses this could be done also for other languages as python.
This would be amazing.
I have considered local code blocks, but I don't believe that they are really all that practical. You end up needing to update line numbers for all later code blocks anyways, so you may as well just do the entire thing.
What I have found works reasonably well is to update syntax errors and trees after a delay that is a function of how long it took to generate the information the last time. When generating, I have a secondary thread do the compilation, etc., to allow the main thread to do its business of letting people edit, etc., then taking control to update controls, etc. The only issue is that you can't use the standard STCStyleEditor.py to handle style setting, as it uses the wx.FileConfig class, which seems to have threading issues (http://lists.wxwidgets.org/cgi-bin/ezmlm-cgi?11:mss:47836:200602:nmkejbkeoodckphegicd ). If you switch to the StyleSetter.py that is included with PyPE, you should be able to use multiple threads at the same time (PyPE has been doing so for over a year now).
- Josiah
SPE Stani's Python Editor
> > Realtime updating is also which belongs to the generic part. Therefore
> > we need to be able to diffs between a previous state and a current
> > state and to add a property expanded (True/False) to the nodes. Again
> > if we implement this in a generic way, we get everything for free for
> > all languages.
>
> I actually implemented a variant of 'diff in place' method for trees after
> seeing yours. It doesn't handle renames very well (it ends up recreating
> the subtree of a named node), but it seemed to speed up the tree
> manipulations that PyPE was doing. I need to release a new version of PyPE
> soon, so I'll let everyone know where the code can be found when it is
> available.
process could be optimized as you do not need to 'diff in place' for
nodes or create subtrees, only when they are expanded. Does your
implementation have this 'lazy diff in place'? For doing diffs I was
also wondering maybe to provide the tree and nodes with a __str__
method so you can use the diff functionality from the standard diff in
the hope that is well written, optimized code.
> > Another thing is that fold explorer will be a good tool for what I
> I have considered local code blocks, but I don't believe that they are
> really all that practical. You end up needing to update line numbers for
> all later code blocks anyways, so you may as well just do the entire thing.
For syntax errors I still do think it is possible in the following
way. Ask scintilla the first and last visible line. Than we need to
find the top line equal or above the first line and the bottom line
equal or below the last line. If the first line is an except statement
we need to go up till the try statement, otherwise we can just use the
first visible line. What concerns the last line, we need to go down to
the first not folding node, again with the exception that every try
statement has to be closed. This is not tested and probably it has to
be corrected but maybe it should work.
As for class explorers the task is more difficult indeed. I am just
wondering if there are more hidden treasures in Scintilla for
notifications and identifying changes. I need to study this more.
Maybe it is crazy idea, but we could also invent a new way of dealing
with source editing:
- first we load the whole document so that scintilla can parse it
- than if a user (right) clicks on a tree item, it *only* displays
that code. If you want to have more overview, you click a higher node
etc...
- every time a user (right) clicks a node the editor substitutes the
new code with the previous selection between start and end
- why?
- sometimes it is nicer to work more zoomed in and you still have the
overview if you click on the root node which can be called 'whole
document'
- if the selection exceeds a certain number of lines (user preference)
realtime features are turned off (or switch to threading)
- this will be faster than any other method. Also threading as it only
works on part of the document
Maybe this is a nice idea, but a bit unconvential. Does anybody knows
an editor which works like this. Leo maybe? This could be also an
optional feature which can be turned or off at any time.
> What I have found works reasonably well is to update syntax errors and trees
> after a delay that is a function of how long it took to generate the
> information the last time. When generating, I have a secondary thread do
> the compilation, etc., to allow the main thread to do its business of
> letting people edit, etc., then taking control to update controls, etc. The
> only issue is that you can't use the standard STCStyleEditor.py to handle
> style setting, as it uses the wx.FileConfig class, which seems to have
> threading issues
> (http://lists.wxwidgets.org/cgi-bin/ezmlm-cgi?11:mss:47836:200602:nmkejbkeoodckphegicd
> ). If you switch to the StyleSetter.py that is included with PyPE, you
> should be able to use multiple threads at the same time (PyPE has been doing
> so for over a year now).
I would prefer to have a not-threading alternative. For example you
can not run SPE in Blender with threads. For compiling/syntax errors
you need only a few lines of output (error label, line number, etc..),
so it could also be done with a subprocess as most cpus become
multi-core and threading is only single-core.
Stani
--
http://pythonide.stani.be
Josiah Carlson
On 3/5/07, Josiah Carlson <josiah....@gmail.com> wrote:
> On 3/5/07, SPE Stani's Python Editor <spe.st...@gmail.com > wrote:
> > Realtime updating is also which belongs to the generic part. Therefore
> > we need to be able to diffs between a previous state and a current
> > state and to add a property expanded (True/False) to the nodes. Again
> > if we implement this in a generic way, we get everything for free for
> > all languages.
>
> I actually implemented a variant of 'diff in place' method for trees after
> seeing yours. It doesn't handle renames very well (it ends up recreating
> the subtree of a named node), but it seemed to speed up the tree
> manipulations that PyPE was doing. I need to release a new version of PyPE
> soon, so I'll let everyone know where the code can be found when it is
> available.
Interesting. Is it not somewhere in cvs or subversion?
I use a local subversion respository via TortoiseSVN, but it's not available generally.
I thought my
process could be optimized as you do not need to 'diff in place' for
nodes or create subtrees, only when they are expanded. Does your
implementation have this 'lazy diff in place'? For doing diffs I was
also wondering maybe to provide the tree and nodes with a __str__
method so you can use the diff functionality from the standard diff in
the hope that is well written, optimized code.
No, it updates the entire tree. For reference, it is able to update the tree for the currently 5600 line pype.py in .2 seconds on my machine. I honestly don't believe that dynamic rebuild time will be a serious issue.
> > Another thing is that fold explorer will be a good tool for what I
> I have considered local code blocks, but I don't believe that they are
> really all that practical. You end up needing to update line numbers for
> all later code blocks anyways, so you may as well just do the entire thing.
For syntax errors I still do think it is possible in the following
way. Ask scintilla the first and last visible line. Than we need to
find the top line equal or above the first line and the bottom line
equal or below the last line. If the first line is an except statement
we need to go up till the try statement, otherwise we can just use the
first visible line. What concerns the last line, we need to go down to
the first not folding node, again with the exception that every try
statement has to be closed. This is not tested and probably it has to
be corrected but maybe it should work.
That's all well and good, and I suppose it could be made to work for those times when you want *immediate* notification; but I've honestly had good luck with a delayed check syntax mechanism. I find that when I'm programming, I usually come to a natural pause where I need to think through something, and the delayed syntax checking offers precisely what I need, more or less when I need it.
As for class explorers the task is more difficult indeed. I am just
wondering if there are more hidden treasures in Scintilla for
notifications and identifying changes. I need to study this more.
The documentation is my secret stash of information ;).
As an aside, one of the problems with using the STC-embedded fold flags, etc., is that it's not quite as easy to extract information and do the "parsing" in the background (in a thread, etc.) - the data is in a GUI widget, whose access methods must be called from the GUI thread. Even if this method were as fast as a line-based parser, there would still be delays in the parsing, in addition to the (required) delays in the tree update.
Maybe it is crazy idea, but we could also invent a new way of dealing
with source editing:
- first we load the whole document so that scintilla can parse it
- than if a user (right) clicks on a tree item, it *only* displays
that code. If you want to have more overview, you click a higher node
etc...
- every time a user (right) clicks a node the editor substitutes the
new code with the previous selection between start and end
That sounds a lot like the Code Browser editor: http://code-browser.sourceforge.net/ . There are certainly good ideas embedded in the project.
- why?
- sometimes it is nicer to work more zoomed in and you still have the
overview if you click on the root node which can be called 'whole
document'
- if the selection exceeds a certain number of lines (user preference)
realtime features are turned off (or switch to threading)
There isn't really any good reason not to use threading all the time. Stick with Queue to send information to the worker thread, and use wx.CallAfter or wx.PostEvent to get data back to the main thread. Alternatively, consider using the DelayedResult module available in recent wxPythons.
I would prefer to have a not-threading alternative. For example you
can not run SPE in Blender with threads. For compiling/syntax errors
you need only a few lines of output (error label, line number, etc..),
so it could also be done with a subprocess as most cpus become
multi-core and threading is only single-core.
So that's why you are hesitant to use threads. Though it's only marginally related to the topic, is it documented somewhere why threads + blender + external editor doesn't work?
Rob McMullen
> Becomes in the tree:
> def hello_world():
> (if linux:) #invisible
> class Widget:
> def __init__(self):
>
> I think by recognizing the fake nodes (with eg regular expression) we
> can transform easily the fold explorer in the class explorer, but
> still I think the fold explorer is still valuable on its own even if
> there is also the class explorer implemented.
At the very least, it makes the implementation of a class explorer
simpler by basing it on the fold explorer for the languages that
support folding. We can provide users with the ability to define
their own regular expressions for matching todos, fixmes, or whatever.
> Is this not more generic?
> def open(self,fileName, language, encoding=DEFAULT_ENCODING, line=0):
> self.setLanguage(language)
> self.setText(open(fileName).read(),encoding)
> wx.CallAfter(self.GotoLine,line)
>
> def setText(self,text,encoding=DEFAULT_ENCODING):
> self.encoding = encoding
> self.SetText(text.decode(encoding))
> self.Colourise(0, self.GetTextLength()) #make sure everything is lexed
> wx.CallAfter(self.explorer.update)
It still barfs on that source file. There's a \xdd character imbedded
in scintilla's Editor.cxx source file, and using the utf8 decoder as
above returns the error UnicodeDecodeError: 'utf8' codec can't decode
bytes in position 32785-32786: invalid data
I used the AddStyledText("\0".join(text) + "\0") hack because that
allowed me to use the stc as a generic binary datastore -- you can
e.g. store images in an STC if you use add data this way. That's how
I implemented my hex editor.
Rob
Ali Afshar
> Hi All,
Hi All,
I have been playing with this demo, and it is very nice. Good work!
> - The hierarchy is extracted in a recursive data class Node by the
> scintilla editor of which the root is passed to a wxTreeCtrl. So this
> should make easy to port it to other gui toolkits which have a
> scintilla control.
Unfortunately, we don't have the scintilla control in PyGTK (well we
do, but we are forced to maintain it ourselves, and we never want to
be bound to use it). I am guessing the crux of the parsing etc is done
by the lexer for the editor, and then extracted. Unfortunately this
would be no good for non-scintilla based applications.
Has anyone done any work on creating a generic parser in Python, or
any other language with Python bindings? Or has anyone got any
knowledge about taking the parser out of Scintilla and running it
independently of the UI?
Thanks,
Ali
Ali Afshar
>
> On 3/5/07, Ali Afshar <aaf...@gmail.com> wrote:
> Hi Ali, nice to hear from you again.
Hi, likewise,
> > On 05/03/07, Rob McMullen <rob.mc...@gmail.com> wrote:
> >
> > > I wonder if there's a way to determine from the python side which
> > > languages support folding and which don't? HTML, for example, doesn't
> > > produce any folding -- I had thought it might because of the nesting
> > > of tags.
> It *does*, if you change this:
> def setFoldMargin(self):
> self.SetProperty("fold", "1")
> self.SetProperty("fold.html","1")
> (...)
>
> > Is that any different from nested code blocks?
> How do you mean?
Well, I was considering that tag nesting was analogous to code block nesting,
say:
<div>
<a href="banana>Bananas</a>
</div>
and:
Class Foo:
def blah():
Or perhaps I was misunderstanding the meaning of "nested tags".
Ali
SPE Stani's Python Editor
http://silvercity.sourceforge.net/
but it is not 100% python as it uses C code from scintilla. However I
think it is available multiplatform. But I don't know if it also
exports the folding capacity of scintilla. Brian Quinlan the developer
of silvercity is on this list, so maybe he can answer. Brian, are you
there?
And otherwise there is pygments but I also don't know if it does
folding or parsing.
Otherwise you have some generic ast modules in the stdlib but also
from logilab. Ast can be very interesting, but I wonder if it works
with code with syntax errors, which is quite normal when you are
editing and did not finish typingyour line. If you look at them it
would be good to share your thoughts. I think that parsing (well if we
don't use scintilla) is something we could share and develop together.
A good parser is the core of a good IDE. Than again the advantage of
silvercity/scintilla is that it is *generic* for a lot of languages
besides python if your editor aims not to be solely a python editor.
Maybe we can write a common api on scintilla and silvercity, which is
of course an extra dependency. On Linux this is not really a problem
as your package manager takes care of it. On windows if you use py2exe
it is also not an issue, except for increasing your download size.
Another question is if silvercity works with Mac. I guess gtk will run
on Mac in future and for now I see pida only supports linux and
windows if I am not wrong.
Stani
--
http://pythonide.stani.be
Ali Afshar
Thanks, I shall investigate all that stuff.
> Another question is if silvercity works with Mac. I guess gtk will run
> on Mac in future and for now I see pida only supports linux and
> windows if I am not wrong.
It barely runs on windows (which is poor design on my part since my
real-life work is all PyGTK on Windows), and runs under Mac using X,
but not really natively (yet).
Ali
Josiah Carlson
There is a package called Synopsis...though the issue with Synopsis is that different languages result in different kinds of nodes that represent the content of the file, with different attributes and methods.
The extracted scintilla lexers (silvercity) that Stani mentioned is probably the best choice. It supports fewer languages than vanilla scintilla, but it seems usable if you aren't including scintilla with your application.
- Josiah