display nominal value into prediction file
80 views
Skip to first unread message

Millen Xu
May 23, 2020, 11:40:42 AM5/23/20
to python-weka-wrapper
my dataset has a nominal attribute and this is an example of my dataset
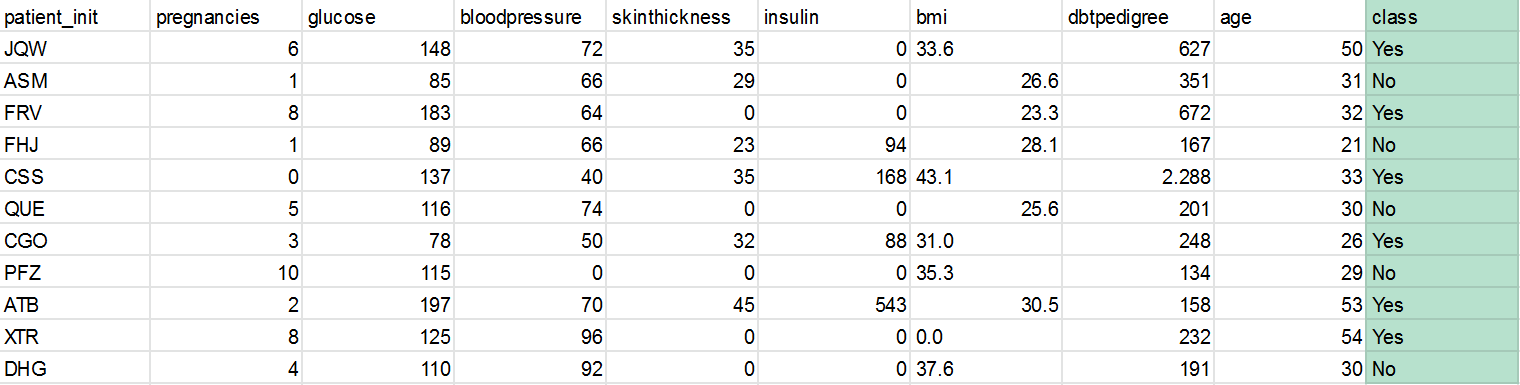
I use this weka example to save the prediction
helper.print_title("recording/outputting predictions separately")
outputfile = helper.get_tmp_dir() + "/pima90.csv"
output = PredictionOutput(classname="weka.classifiers.evaluation.output.prediction.CSV", options=["-distribution", "-suppress", "-file", outputfile])
output.header = test
output.print_all(cls, test)
helper.print_info("Predictions stored in:" + outputfile)
print(output.buffer_content())
outputfile = helper.get_tmp_dir() + "/pima90.csv"
output = PredictionOutput(classname="weka.classifiers.evaluation.output.prediction.CSV", options=["-distribution", "-suppress", "-file", outputfile])
output.header = test
output.print_all(cls, test)
helper.print_info("Predictions stored in:" + outputfile)
print(output.buffer_content())
What code should I write to show patient_init inside output file? Thank you

Peter Reutemann
May 24, 2020, 12:03:57 AM5/24/20
to python-weka-wrapper
> my dataset has a nominal attribute and this is an example of my dataset
The screenshot was too small to see anything.
> I use this weka example to save the prediction
>
> helper.print_title("recording/outputting predictions separately")
> outputfile = helper.get_tmp_dir() + "/pima90.csv"
> output = PredictionOutput(classname="weka.classifiers.evaluation.output.prediction.CSV", options=["-distribution", "-suppress", "-file", outputfile])
> output.header = test
> output.print_all(cls, test)
> helper.print_info("Predictions stored in:" + outputfile)
> print(output.buffer_content())
>
> What code should I write to show patient_init inside output file? Thank you
the -p option as per documentation:
https://weka.sourceforge.io/doc.dev/weka/classifiers/evaluation/output/prediction/CSV.html
Cheers, Peter
--
Peter Reutemann
Dept. of Computer Science
University of Waikato, NZ
+64 (7) 858-5174
http://www.cms.waikato.ac.nz/~fracpete/
http://www.data-mining.co.nz/
Millen Xu
May 25, 2020, 4:52:23 AM5/25/20
to python-weka-wrapper
thanks sir it works! If I apply data splitting and build classifier beside attribute selection should it be like:
train, test = data.train_test_split(80.0, Random(30))
classifier = Classifier(classname="weka.classifiers.meta.AttributeSelectedClassifier")
aseval = ASEvaluation(classname="weka.attributeSelection.GainRatioAttributeEval")
assearch = ASSearch(classname="weka.attributeSelection.GreedyStepwise", options=["-B"])
base = Classifier(classname="weka.classifiers.trees.J48")
base.build_classifier(train)
or just put data splitting and build classifier in def main? And is it a must to do attribute selection in every classifier?
train, test = data.train_test_split(80.0, Random(30))
classifier = Classifier(classname="weka.classifiers.meta.AttributeSelectedClassifier")
aseval = ASEvaluation(classname="weka.attributeSelection.GainRatioAttributeEval")
assearch = ASSearch(classname="weka.attributeSelection.GreedyStepwise", options=["-B"])
base = Classifier(classname="weka.classifiers.trees.J48")
base.build_classifier(train)
or just put data splitting and build classifier in def main? And is it a must to do attribute selection in every classifier?
Peter Reutemann
May 25, 2020, 5:38:02 AM5/25/20
to python-weka-wrapper
AttributeSelectedClassifier does that automatically - as long as you
set search/eval/base classifier:
classifier.set_property("classifier", base.jobject)
classifier.set_property("evaluator", aseval.jobject)
classifier.set_property("search", assearch.jobject)
Millen Xu
May 29, 2020, 5:03:04 AM5/29/20
to python-weka-wrapper
Sir, does nominal attribute can affect heap space?
I have 2 version of my file, file A only contains numeric [57 mb] and file B has nominal attribute (± 30 characters) [59 mb].
My plan is to display nominal attribute alongside prediction result.
There's no problem to run file A. It worked without adding max_heap_size
When I run file B and set max_heap_size to 5g because can't work using 4g (my ram: 8gb).
it succeeded at first but then I got 'the kernel appears to have died' after run it again.
What are causes of this problem? Should I subset dataset?

Peter Reutemann
May 29, 2020, 5:31:00 AM5/29/20
to python-we...@googlegroups.com
Millen Xu
May 29, 2020, 6:48:08 AM5/29/20
to python-weka-wrapper
Naive bayes and j48. I use 'Yes/No' for labelling instead of 0/1
Peter Reutemann
May 29, 2020, 6:12:29 PM5/29/20
to python-we...@googlegroups.com
On May 29, 2020 10:48:08 PM GMT+12:00, Millen Xu <mill...@gmail.com> wrote:
>Naive bayes and j48. I use 'Yes/No' for labelling instead of 0/1
Well, NaiveBayes uses a different estimator for nominal values, which can explain different memory usage. Not 100% sure about J48, but the splitting criteria for a nominal attribute might use more memory as well (preparing for multiway splits). You may have been quite close to the maximum heap size before and changing the attributes might have just been a bit too much then.
>Naive bayes and j48. I use 'Yes/No' for labelling instead of 0/1
Reply all
Reply to author
Forward
0 new messages