tornadostreamform big file upload
553 views
Skip to first unread message

Cong Wang
Aug 18, 2016, 7:50:09 AM8/18/16
to Tornado Web Server
Hi,
I am trying to use the form tornadostreamform.Which is a form trying to transfer some big file from client to server.
And trying to run the test 01_multipart_streamer.py.But I can't make sure where do I store the file ,I try to change the "is moved" parameter,but here comes this problem.

How can I store the file to the directory of server.Thanks!
The tornadostreamform is here:https://bitbucket.org/nagylzs/tornadostreamform
I am so eager to know that,thanks!
Best regards

Kevin LaTona
Aug 18, 2016, 11:39:30 AM8/18/16
to python-tornado@googlegroups.com Server
From a quick look at the code my guess is your file path may not be correct and the temp file can’t be written.
Try adding this to line 56 of 01_multipart_streamer.py’s create_part method to see if works for you
return TemporaryFileStreamedPart(self, headers, tmp_dir=os.path.dirname(os.path.dirname(__file__)))
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Ben Darnell
Aug 18, 2016, 11:42:17 PM8/18/16
to python-...@googlegroups.com
Looking at the original version of the example that you've modified, this line talks about finalizing the parts:
I think you can't call move() until after calling data_complete() in post().
-Ben
--
Cong Wang
Aug 23, 2016, 9:55:12 PM8/23/16
to python-...@googlegroups.com, b...@bendarnell.com, li...@studiosola.com
Hi,
I have uploaded my code to https://github.com/congfairy/leaf_tornado.git, you can clone it here.
I have tried your suggestion, and when I run http://localhost:8888,here comes no problem but I did see nothing in the temporary directory,so what is the problem?
And what I really want to do is that the client can send some command or parameters (for example:ls dir_name) to the server and the server receive the command,do something by itself and send some files to the client.All the data I want to send in binary and can be divided into blocks. How can I do that ?I think that perhaps I can change some of this code and fulfill the function..
And the file I want to send is much bigger(perhaps 1G) ,I have found that tornado will put all the file it want to send to the memory ,perhaps 100M,so how can I send some file much bigger ,do you have some good suggestion? Thanks a lot!
Best regards,
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornado+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Kevin LaTona
Aug 24, 2016, 2:12:17 PM8/24/16
to python-tornado@googlegroups.com Server
On Aug 23, 2016, at 6:54 PM, Cong Wang <congfa...@gmail.com> wrote:I have tried your suggestion, and when I run http://localhost:8888,here comes no problem but I did see nothing in the temporary directory,so what is the problem?
Did you run this code as is and what was it’s result?
return TemporaryFileStreamedPart(self, headers, tmp_dir=os.path.dirname(os.path.dirname(__file__)))
That code should put the file in the same folder level that you are calling it from within the Tornado server for the test.
Once you figure out if the code you have is working or not, you can then change the storage folder path latter.
>> TMP_DIR = '/root/tmp' # Path for storing streamed temporary files. Set this to a directory that receives the files.
Check your user permission and groups etc?
Is your current user name in the group that has permission and can access this folder?
Something to verify as without permission level access you can’t write to the folder which might be why you are seeing the file.
I would of thought that Tornado would have choked and said something, but do verify your user group and permissions are correct.
-Kevin
Kevin LaTona
Aug 24, 2016, 10:39:32 PM8/24/16
to python-tornado@googlegroups.com Server
Cong,
I still don’t fully understand the problem you are wanting to solve, and or all the limitations around why you are wanting to do it this way.
Having said that you and depending on your limitations, you could always just write your own TCP IOStream server and client to handle this… pretty simple and gives you lots of total control over the entire process. Some days HTTP is kludge that gets in the way, no reason you have to stick with HTTP is here?
Wha about FTP or SFTP?
What using Tornado’s AsyncHTTPClien to move your file if you can control the client side with your onw Python code vs HTML.
Or what about using Rsync to transfer the file?
Rsync just might do what you need with a bit of Python and or Bash to get it up and moving your files accross the wire with very little effort on your part. You could use Tornado or even Nginx to recieve the file.
Some ideas to consider or look at to see how they could fit into your problem.
-Kevin
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Cong Wang
Aug 25, 2016, 3:03:51 AM8/25/16
to python-...@googlegroups.com, li...@studiosola.com
HI,
What I would like to do is below:
We would like to fulfill a long-distance file system .The client can read and write files as if the filesystem is local such as AFS. We want to use http protocol because ftp has some firewall limitation and the users need to log in to use something .
When the client want do the ls action ,then it will send some parameter to the server (such as uid,gid,key,filename ) ,the server search the information by stat(provided by the system),and send all the information back to client(for example:all the information in json format,and parse it by the client).Then the client use information and fulfill the metadata and other part to build a local filesystem.
The files we would like to transfer is around 1G,so when the client want to read or write some big files,I need to transfer these data to the client.I would like to know how do I use the thread pool to manage all the threads .And how can I transfer the data in chunks and in binary.I hope you can understand my question.
All the information client can get is by curl:(such as :http://localhost:8000/leaf?filename=/var/www/html&uid=500&gid=220&key=1122),then it will get the stat information in json format,or use another curl command to get the file in binary in protobuf format.
Now I choose tornado as a web framwork,and use http protocol.and use json as serialization protocol for ls or cat.use protobuf for big binary data.I don't know if this is a good way to fulfill this part of the system.And which part in tornado I can use most in my system.Thanks!
Best regards,
Kevin LaTona
Aug 25, 2016, 11:08:57 AM8/25/16
to python-tornado@googlegroups.com Server
Spend some time on google as this subject has been addressed numerous times before and everyone has their own twist on how why they solve it the way they do.
A few links to get you started.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Kevin LaTona
Aug 27, 2016, 12:08:53 AM8/27/16
to python-tornado@googlegroups.com Server
Cong,
I happened upon a failry nice and somewhat simple example gist today while looking for something else that might show you how to solve your problem.
It’s one of the simpler and cleaner examples of how one could set up a thread pool executor in tornado.
This is one way you could off load these large files to get uploaded and not kill off your whole server.
I found adding lots of threads ( Max_Workers ) usually has a diminishing effect once you've added too many threads, so you’ll need to play with that number to find one that works best for you.
-Kevin
import time
from tornado.concurrent import run_on_executor
from concurrent.futures import ThreadPoolExecutor # `pip install futures` for python2
MAX_WORKERS = 4
class Handler(tornado.web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
@run_on_executor
def background_task(self, i):
""" This will be executed in `executor` pool. """
time.sleep(10) # time.sleep blocks the thread
return i
@tornado.gen.coroutine
def get(self, idx):
""" Request that asynchronously calls background task. """
res = yield self.background_task(idx)
self.write(res)
# found in comments @ https://gist.github.com/methane/2185380
I happened upon a failry nice and somewhat simple example gist today while looking for something else that might show you how to solve your problem.
It’s one of the simpler and cleaner examples of how one could set up a thread pool executor in tornado.
This is one way you could off load these large files to get uploaded and not kill off your whole server.
I found adding lots of threads ( Max_Workers ) usually has a diminishing effect once you've added too many threads, so you’ll need to play with that number to find one that works best for you.
-Kevin
import time
from tornado.concurrent import run_on_executor
from concurrent.futures import ThreadPoolExecutor # `pip install futures` for python2
MAX_WORKERS = 4
class Handler(tornado.web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=MAX_WORKERS)
@run_on_executor
def background_task(self, i):
""" This will be executed in `executor` pool. """
time.sleep(10) # time.sleep blocks the thread
return i
@tornado.gen.coroutine
def get(self, idx):
""" Request that asynchronously calls background task. """
res = yield self.background_task(idx)
self.write(res)
# found in comments @ https://gist.github.com/methane/2185380
Cong Wang
Aug 27, 2016, 10:09:05 PM8/27/16
to Tornado Web Server, je...@mongodb.com
I have saw the code here: https://gist.github.com/ajdavis/5630959 .About bigfile upload and download
But I couldn't make it clear how could I transfer some real data from server to client?
In the example , which kind of data your are transfering from server to client.
I am trying to get some parameters from client by curl command such as(read position ,filename,uid,gid etc),the server get this parameters and send some files back to client,in binary and in chunk.How could I add this to the example??
Also,I really want to know how could the client receive these binary data and do some action with the data(for example store the data),in which function could I do this.
Thanks.
Best regards
Thanks!
在 2016年8月18日星期四 UTC+8下午7:50:09,Cong Wang写道:
Kevin LaTona
Aug 27, 2016, 11:23:51 PM8/27/16
to python-tornado@googlegroups.com Server
Jesse’s code is always solid most likey you will just need to get up todate how it works.
From a quick look his example had both the client and server calls.
As far as binary when you “open” a document path to save to use the ‘wb’ for binary data type.
Read up on how the open command works as it has multiple ways to both read and write.
With open(‘some/path/sample.txt’ , “‘wb”) as f:
f.write(your_data)
using the with context call you don’t have to close the document when done as it’s auto closed for you.
Cong Wang
Aug 28, 2016, 3:46:27 AM8/28/16
to python-...@googlegroups.com
Thanks for your answer.
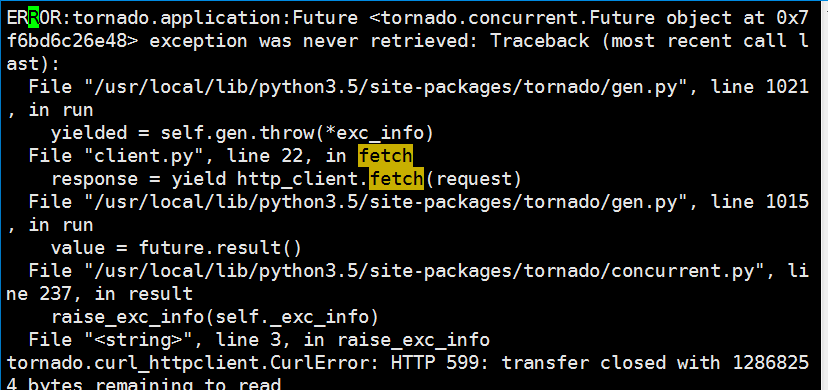
I have tried to fulfill my code like this:https://github.com/congfairy/leaf.git (server.py client.py and the log in logserver and logclientnew)
Here comes some problem:
I have tried to read the file logclient by chunks.and send them to the client.I have two problems to be solved as below:
1:the first is that how could I solve the problem I encountered above,is there something wrong with the threadpool?
2.I have made the chunk_size to 1024 ,the server send it in this size ,one 1024 then next 1024.But we can check in the logclientnew,that the downloaded size are not all 1024,sometimes this is 3072 or 16384 or something else.How could I control the client to read one 1024 after another?
Because the client would like to write some function to deal with the data by chunk ,so I hope that I can manage the sequence.
Thanks!
Best regards
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornado+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Kevin LaTona
Aug 28, 2016, 7:28:28 PM8/28/16
to python-tornado@googlegroups.com Server
It feels like you are not allowing Python to help you out here to chunk the file up for you.
Give this a try to see if it will get you closer to what you are after using the streamIO.
There’s lots of areas that it could be tweaked yet, as this really only is a proof of concept but is working for me so far as is.
Maybe some others might jump in here to suggest or share their ideas about it as well.
Oh I also dropped use of pycurl as right now I am not seeing any advantage why one might or would use it over Tornado's AsyncHTTP client calls.
Well that is my preference to keep things as simple as possible for now.
Give it a spin and let me know it’s not working for you or ?
-Kevin
————————————————————————————————————
client
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
total_downloaded = 0
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
# the OS blocks on file reads + writes -- beware how big the chunks is as it could effect things
with open(path, 'a+b') as f:
f.write(chunk)
@gen.coroutine
def writer(file_name):
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient()
response = yield http_client.fetch(request)
tornado.ioloop.IOLoop.instance().stop()
print("total bytes downloaded was", total_downloaded)
if __name__ == "__main__":
writer('test78.jpg')
tornado.ioloop.IOLoop.instance().start()
————————————————————————————————————
server
import tornado.ioloop
import tornado.web
from tornado import gen
GB = 1024 * 1024 * 1024
chunk_size = 1024
def read_in_chunks(infile, chunk_size=1024*64):
chunk = infile.read(chunk_size)
while chunk:
yield chunk
chunk = infile.read(chunk_size)
class StreamingRequestHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
@gen.coroutine
def get(self):
# ideally you would send in the get request what file you want to send
# back as right now this is limited to what is hard coded in
total_sent = 0
with open('/path/to/big/file', 'rb') as infile:
for chunk in read_in_chunks(infile):
self.write(chunk)
yield gen.Task(self.flush)
total_sent += len(chunk)
print("sent",total_sent)
self.finish()
if __name__ == "__main__":
tornado.options.parse_command_line()
application = tornado.web.Application([(r"/", StreamingRequestHandler),])
application.listen(8880)
tornado.ioloop.IOLoop.instance().start()
Give this a try to see if it will get you closer to what you are after using the streamIO.
There’s lots of areas that it could be tweaked yet, as this really only is a proof of concept but is working for me so far as is.
Maybe some others might jump in here to suggest or share their ideas about it as well.
Oh I also dropped use of pycurl as right now I am not seeing any advantage why one might or would use it over Tornado's AsyncHTTP client calls.
Well that is my preference to keep things as simple as possible for now.
Give it a spin and let me know it’s not working for you or ?
-Kevin
————————————————————————————————————
client
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
total_downloaded = 0
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
# the OS blocks on file reads + writes -- beware how big the chunks is as it could effect things
with open(path, 'a+b') as f:
f.write(chunk)
@gen.coroutine
def writer(file_name):
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient()
response = yield http_client.fetch(request)
tornado.ioloop.IOLoop.instance().stop()
print("total bytes downloaded was", total_downloaded)
if __name__ == "__main__":
writer('test78.jpg')
tornado.ioloop.IOLoop.instance().start()
————————————————————————————————————
server
import tornado.ioloop
import tornado.web
from tornado import gen
GB = 1024 * 1024 * 1024
chunk_size = 1024
def read_in_chunks(infile, chunk_size=1024*64):
chunk = infile.read(chunk_size)
while chunk:
yield chunk
chunk = infile.read(chunk_size)
class StreamingRequestHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
@gen.coroutine
def get(self):
# ideally you would send in the get request what file you want to send
# back as right now this is limited to what is hard coded in
total_sent = 0
with open('/path/to/big/file', 'rb') as infile:
for chunk in read_in_chunks(infile):
self.write(chunk)
yield gen.Task(self.flush)
total_sent += len(chunk)
print("sent",total_sent)
self.finish()
if __name__ == "__main__":
tornado.options.parse_command_line()
application = tornado.web.Application([(r"/", StreamingRequestHandler),])
application.listen(8880)
tornado.ioloop.IOLoop.instance().start()
Kevin LaTona
Aug 28, 2016, 8:45:06 PM8/28/16
to python-tornado@googlegroups.com Server
Cong,
While in theory that code works I am still not convinced using the StreamIO is the best way to upload large multiple GB files like how you are wanting.
If it was me, I would be looking at how to work with Tornado and the ThreadPoolExecutor calls.
Moving large files is a pain as read and writes will block the main IOLoop thread which is why passing it off to a thread pool should make better sense.
The code you had and I tweaked is still using Tornado’s main ioLoop thread.
Spend sometime on Google as there is lots of examples out there to give ideas how of using Tonrado and ThreadPoolExecuto can go.
Or maybe someone else wiill jump in here to share other ideas as well.
-Kevin
While in theory that code works I am still not convinced using the StreamIO is the best way to upload large multiple GB files like how you are wanting.
If it was me, I would be looking at how to work with Tornado and the ThreadPoolExecutor calls.
Moving large files is a pain as read and writes will block the main IOLoop thread which is why passing it off to a thread pool should make better sense.
The code you had and I tweaked is still using Tornado’s main ioLoop thread.
Spend sometime on Google as there is lots of examples out there to give ideas how of using Tonrado and ThreadPoolExecuto can go.
Or maybe someone else wiill jump in here to share other ideas as well.
-Kevin
> --
> You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
> You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
Cong Wang
Aug 29, 2016, 5:19:26 AM8/29/16
to python-...@googlegroups.com
yeah!It really works for me.I have tried to add something new to the code(for example check the uid and gid)
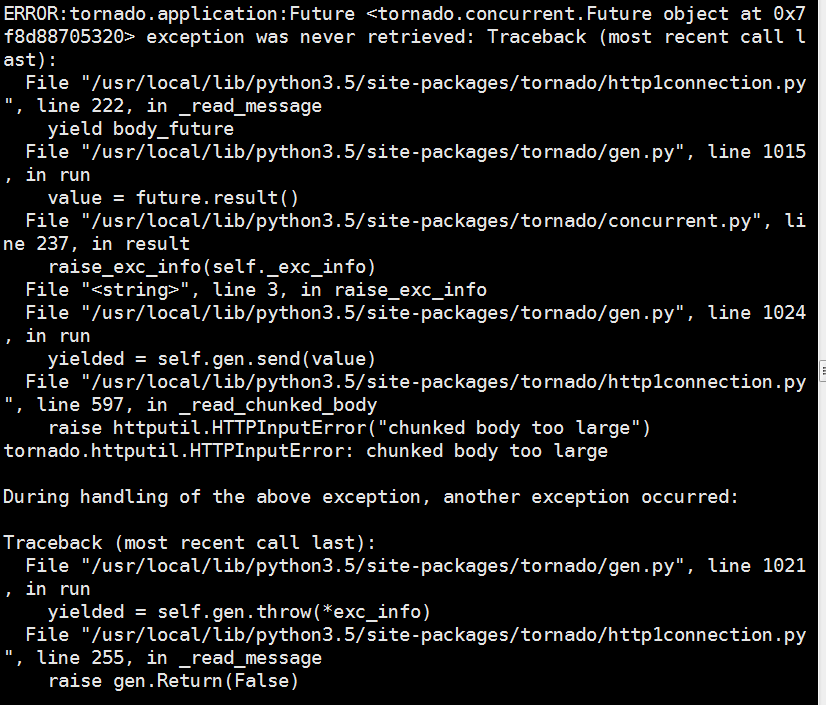
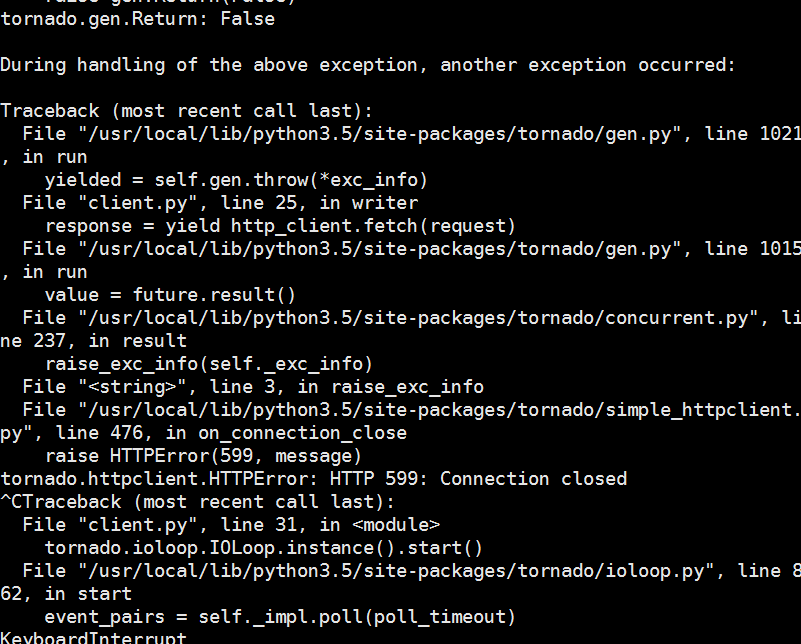
I have submitted the newest code to :https://github.com/congfairy/leaf.git
The problems I still have are:
1:In the server side,it tried to send data in 64K chunk,but on the client side ,the chunk size are all different,so how could we manage the chunk size the client receive?it seems that on the network,several chunks will be merged together?
2:so until now,in the StreamingRequestHandler side,all the file data are transfer in binary?I didn't to use some serializing or deserializing tools to trabsfer the data(such as protobuf)?
3:I don't think I can manage the async and threalpool very well,actually I didn't use this in the ListRequestHandler.If you have time,could you help me to change this function to async?I think this will help a lot for me to get familiar with async in tornado.Thanks
4:I have found that when I download some really big files ,here comes some problem,so where do you think the problems come from?
Best regards
Cong
> To unsubscribe from this group and stop receiving emails from it, send an email to python-tornado+unsubscribe@googlegroups.com.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Kevin LaTona
Aug 29, 2016, 11:54:01 AM8/29/16
to python-tornado@googlegroups.com Server
I just ran a few test here with that code on a much larger file than I had started with.
My test file gets to 104.9MB every itme and shuts down saying the file is too large (the same error message you are getting).
Time to re-think this code or approach on how to solve moving a big file this way.
-Kevin
On Aug 29, 2016, at 2:19 AM, Cong Wang <congfa...@gmail.com> wrote:
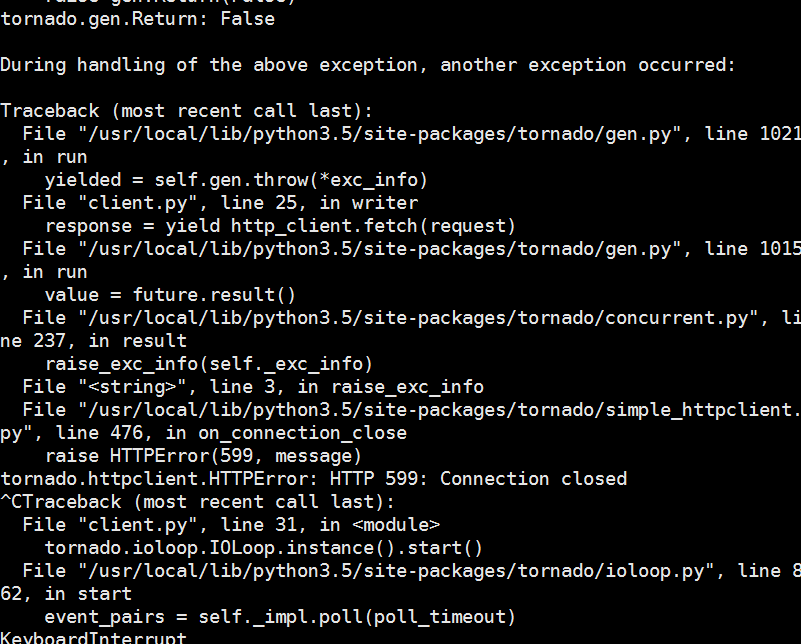
yeah!It really works for me.I have tried to add something new to the code(for example check the uid and gid)I have submitted the newest code to :https://github.com/congfairy/leaf.gitThe problems I still have are:1:In the server side,it tried to send data in 64K chunk,but on the client side ,the chunk size are all different,so how could we manage the chunk size the client receive?it seems that on the network,several chunks will be merged together?2:so until now,in the StreamingRequestHandler side,all the file data are transfer in binary?I didn't to use some serializing or deserializing tools to trabsfer the data(such as protobuf)?3:I don't think I can manage the async and threalpool very well,actually I didn't use this in the ListRequestHandler.If you have time,could you help me to change this function to async?I think this will help a lot for me to get familiar with async in tornado.Thanks4:I have found that when I download some really big files ,here comes some problem,so where do you think the problems come from?
<image.png><image.png>Best regardsCong
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Kevin LaTona
Aug 29, 2016, 8:30:49 PM8/29/16
to python-tornado@googlegroups.com Server
Look at Python.org’s example code for a ThreadPoolExecutor to give you some ideas https://docs.python.org/3/library/concurrent.futures.html#threadpoolexecutor-example
I did a few quick test with their example and with that server code from earlier it was downloading 6 - 500MB files in about 8 -10 seconds with both the client and server on the same computer.
I noticed that adding more worker threads only slowed things down for my test.
In the few quick test I did I found 2-4 workers with the server chunking the file up into 1Mb parts was the fastest.
Smaller chunks or larger were not as optimum in the test I did.
Again you would need to tweak things for you situation.
The TPE makes sense to me with what you have shared so far, as you could send the client a series of url paths in one request and than the client could go ahead and down loads that list which gives you plenty of time to write them locally.
The TPE still works in an Async mode but it’s not always showing that until you do lots of hits with smaller file request to really see it in action.
Big files like you are talking about is going to take control of the server, so you may want to look into running multiple instances of Tornado behind Nginx all hitting the same drive preferable a raid or SAN maybe.
Let us know how it all works out?
I have no time to look at why the client example from earlier was chocking with larger files, some how it's getting into a write problem. There must be a way around this, but idea right now.
Good Luck
-Kevin
On Aug 29, 2016, at 8:53 AM, Kevin LaTona <li...@studiosola.com> wrote:
I just ran a few test here with that code on a much larger file than I had started with.
My test file gets to 104.9MB every time and shuts down saying the file is too large (the same error message you are getting).
Time to re-think this code or approach on how to solve moving a big file this way.-Kevin
On Aug 29, 2016, at 2:19 AM, Cong Wang <congfa...@gmail.com> wrote:
yeah!It really works for me.I have tried to add something new to the code(for example check the uid and gid)I have submitted the newest code to :https://github.com/congfairy/leaf.gitThe problems I still have are:1:In the server side,it tried to send data in 64K chunk,but on the client side ,the chunk size are all different,so how could we manage the chunk size the client receive?it seems that on the network,several chunks will be merged together?
2:so until now,in the StreamingRequestHandler side,all the file data are transfer in binary?I didn't to use some serializing or deserializing tools to transfer the data(such as protobuf)?
3:I don't think I can manage the async and threalpool very well,actually I didn't use this in the ListRequestHandler.If you have time,could you help me to change this function to async?I think this will help a lot for me to get familiar with async in tornado.Thanks4:I have found that when I download some really big files ,here comes some problem,so where do you think the problems come from?<image.png><image.png>Best regardsCong
2016-08-29 8:44 GMT+08:00 Kevin LaTona <li...@studiosola.com>:
Cong,
While in theory that code works I am still not convinced using the StreamIO is the best way to upload large multiple GB files like how you are wanting.
If it was me, I would be looking at how to work with Tornado and the ThreadPoolExecutor calls.
Moving large files is a pain as read and writes will block the main IOLoop thread which is why passing it off to a thread pool should make better sense.
The code you had and I tweaked is still using Tornado’s main ioLoop thread.
Spend sometime on Google as there is lots of examples out there to give ideas how of using Tornado and ThreadPoolExecuto can go.
Or maybe someone else will jump in here to share other ideas as well.
Kevin LaTona
Aug 29, 2016, 8:49:45 PM8/29/16
to python-tornado@googlegroups.com Server
Just came upon 2 blog post about Python’s Concurrent futures to Tornado that some on the list might enjoy reading.
-Kevin
Ben Darnell
Aug 29, 2016, 9:21:17 PM8/29/16
to python-...@googlegroups.com
On Mon, Aug 29, 2016 at 5:19 PM Cong Wang <congfa...@gmail.com> wrote:
yeah!It really works for me.I have tried to add something new to the code(for example check the uid and gid)I have submitted the newest code to :https://github.com/congfairy/leaf.gitThe problems I still have are:1:In the server side,it tried to send data in 64K chunk,but on the client side ,the chunk size are all different,so how could we manage the chunk size the client receive?it seems that on the network,several chunks will be merged together?
Yes, the network will split and merge chunks; chunk boundaries are not preserved across the network. With streaming_callback you shouldn't see chunks larger than 64K, but you may see smaller ones.
2:so until now,in the StreamingRequestHandler side,all the file data are transfer in binary?I didn't to use some serializing or deserializing tools to trabsfer the data(such as protobuf)?
Yes, you're reading bytes from the file and writing bytes to the network. All network transfers are in bytes.
3:I don't think I can manage the async and threalpool very well,actually I didn't use this in the ListRequestHandler.If you have time,could you help me to change this function to async?I think this will help a lot for me to get familiar with async in tornado.Thanks
If this is a normal filesystem, you probably don't need a threadpool here. You might want to use `yield self.write()` instead of just `self.write()` in the loop, but I doubt it matters unless there are a very large number of files in the directory. If it's a network filesystem, you might want to use a threadpool:
thread_pool = ThreadPoolExecutor(4) # global
...
files = yield thread_pool.submit(os.listdir, base_dir)`
statinfo = yield thread_pool.submit(os.stat, base_dir + '/' + f)
4:I have found that when I download some really big files ,here comes some problem,so where do you think the problems come from?
Tornado limits the amount of data it will accept in a response to make it harder for users or attackers to fill up your memory or disk. To accept very large files, you need to pass max_body_size to the AsyncHTTPClient constructor.
-Ben
Best regardsCong
> To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornad...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Kevin LaTona
Aug 29, 2016, 11:04:43 PM8/29/16
to python-tornado@googlegroups.com Server
On Aug 29, 2016, at 6:21 PM, Ben Darnell <b...@bendarnell.com> wrote:Tornado limits the amount of data it will accept in a response to make it harder for users or attackers to fill up your memory or disk. To accept very large files, you need to pass max_body_size to the AsyncHTTPClient constructor.
Whoa…... thanks Ben…... for pointing that out as I missed it in the docs. Which by the way just keep getting better and better.
I figured something wacky was happening in the file write to disk that was causing the issue, but was not 100% sure how to track it down.
For what it’s worth I was seeing 104.59 MB before it shut down so for sure conceptualy it’s working as intended.
From the few simple tests I did today with a threadPool idea it seemed to hit a wall PDQ.
I know this is a wacky question given all the variables that will come into play, but from your usage have you seen a rule of thumb of how many larger sized streaming files that Tornado might handle at once before it all just slows down to a crawl?
The reason I ask like Cong there are times I need to move numerous large 500MB to 2GB files so any insights from anyone who moves larges files with Tornado is much appreciated.
Lastly if anyone has any thoughts on chunky if it could be tweaked or is there a better way to deal with the chunks coming in that need to get written to disk please add in here. I was concerned opening and closing a document so many times might have created an impact and as of right now it’s not seeming to be in the few test I’ve done.
Thanks
-Kevin
from tornado.httpclient import HTTPRequest, AsyncHTTPClient
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
import datetime
total_downloaded = 0
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
with open(path, 'a+b') as f:
f.write(chunk)
@gen.coroutine
def writer(file_name):
print('start reading')
s = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient(max_body_size=1024*1024*550) # 550MB file limit for this test
response = yield http_client.fetch(request)
tornado.ioloop.IOLoop.instance().stop()
e = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
print("total bytes downloaded was", total_downloaded)
print(s,e)
if __name__ == "__main__":
writer(‘biggy.zip')
tornado.ioloop.IOLoop.instance().start()
Cong Wang
Aug 30, 2016, 3:55:17 AM8/30/16
to python-...@googlegroups.com
1. Oh,thanks a lot for these reply ,I will do some amend to my code.
As there is so much information,I hope I got all.So the biggest problem for me is I need try to use threadpool and async together to transfer big file in case the the main IOLOOP blocks.Also,I need to look into running multiple instances of Tornado behind nginx.
2.About the max_body_size parameter,I didn't find the parameter in AsyncHTTPClient configure,I just found that on the
tornado.simple_httpclient.SimpleAsyncHTTPClient,how could I add this parameter to my client?3. from tornado.httpclient import HTTPRequest, AsyncHTTPClient
2: so this code has some problem to be solved? I couldn't run it.
Best regards,
cong
so this code has some problem to be solved?I couldn't run it.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Ben Darnell
Aug 30, 2016, 4:02:31 AM8/30/16
to python-...@googlegroups.com
On Tue, Aug 30, 2016 at 3:55 PM Cong Wang <congfa...@gmail.com> wrote:
1. Oh,thanks a lot for these reply ,I will do some amend to my code.As there is so much information,I hope I got all.So the biggest problem for me is I need try to use threadpool and async together to transfer big file in case the the main IOLOOP blocks.Also,I need to look into running multiple instances of Tornado behind nginx.2.About the max_body_size parameter,I didn't find the parameter in AsyncHTTPClient configure,I just found that on thetornado.simple_httpclient.SimpleAsyncHTTPClient,how could I add this parameter to my client?
AsyncHTTPClient.configure() accepts **kwargs, so you can pass max_body_size to it and it will be passed to SimpleAsyncHTTPClient's initializer.
This looks OK to me. How is it failing when you try to run it?
-Ben
--
To unsubscribe from this group and all its topics, send an email to python-tornad...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Cong Wang
Aug 30, 2016, 4:55:44 AM8/30/16
to python-...@googlegroups.com
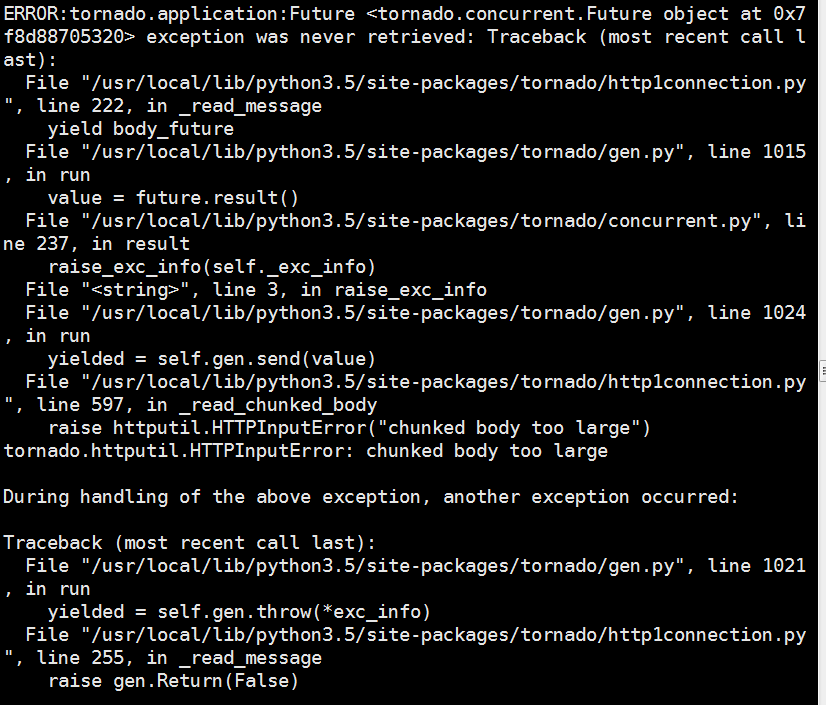
I just run the client code with my server in github.(https://github.com/congfairy/leaf.git)
Here comes the problem: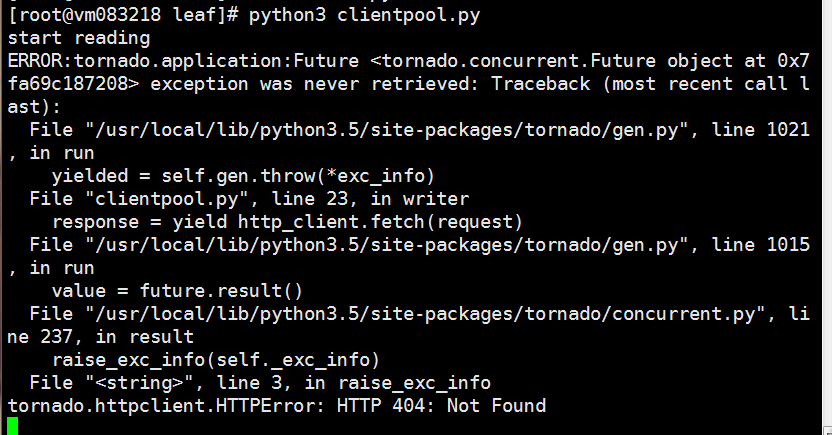
So what is the problem?
Best regards,
--
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornado+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Kevin LaTona
Aug 30, 2016, 5:06:53 AM8/30/16
to python-tornado@googlegroups.com Server
On Aug 30, 2016, at 12:55 AM, Cong Wang <congfa...@gmail.com> wrote:1. Oh,thanks a lot for these reply ,I will do some amend to my code.As there is so much information,I hope I got all.So the biggest problem for me is I need try to use threadpool and async together to transfer big file in case the the main IOLOOP blocks
Cong since Ben brought to light the file size limitation parameter and I adjusted it in my example code it’s been working just fine for me now.
Double check your server and file names as possible you are not sending those in correctly or ?????
As far as having to use the ThreadPoo idea it’s not appearing to me now that has much or any advanatge over this Async code now.
When I mentioned that earlier it was bacause I thought maybe the code I wrote was messing with the OS level file write and was causing the file to choke at 104MB. I was wrong.
I did do some test with the threadPool earlier today and I was not overly impressed with it’s preformance vs how this code now is working with the file size limitation adjusted as needed.
As far running behind Nginx I tossed that idea out as depending on how many people you have hitting the sever, how big the files are and the numbers being transfered that having multple Tornado instance behind Nginx acting as load balancer might help out under big loads.
No reason to do that starting out until you see the load you get, It was more a suggestion to let you know what others do in cases like that to add more power to Tornado.
-Kevin
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Kevin LaTona
Aug 30, 2016, 5:15:06 AM8/30/16
to python-tornado@googlegroups.com Server
> On Aug 30, 2016, at 1:55 AM, Cong Wang <congfa...@gmail.com> wrote:
> Here comes the problem:<image.png>
> So what is the problem?
You getting a 404 file not found… typically means your file path is not correct or breaking up so the server can not deliver it or find it.
Kevin LaTona
Aug 30, 2016, 6:47:45 AM8/30/16
to python-tornado@googlegroups.com Server
Here is an Async Await version of the client code.
So far not seeing any big adavantage over straight Tornado calls, but it does show the chunk size being pushed over the wire.
If any one sees any tweaks please mention them.
-Kevin
from tornado.httpclient import HTTPRequest, AsyncHTTPClient
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
import datetime
total_downloaded = 0
def spawn_callback(callback, *args, **kwargs):
with NullContext():
add_callback(callback, *args, **kwargs)
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
print(len(chunk), total_downloaded)
tornado.ioloop.IOLoop.instance().stop()
e = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
io_loop.spawn_callback(writer, ‘biggy.zip')
io_loop.instance().start()
So far not seeing any big adavantage over straight Tornado calls, but it does show the chunk size being pushed over the wire.
If any one sees any tweaks please mention them.
-Kevin
from tornado.httpclient import HTTPRequest, AsyncHTTPClient
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
import datetime
total_downloaded = 0
with NullContext():
add_callback(callback, *args, **kwargs)
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
with open(path, 'a+b') as f:
f.write(chunk)
async def writer(file_name):
f.write(chunk)
print('start reading')
s = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient(max_body_size=1024*1024*550) # 550MB file limit
response = await http_client.fetch(request)
s = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient(max_body_size=1024*1024*550) # 550MB file limit
tornado.ioloop.IOLoop.instance().stop()
e = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
print(s,e)
if __name__ == "__main__":
io_loop = tornado.ioloop.IOLoop.instance()
if __name__ == "__main__":
io_loop.spawn_callback(writer, ‘biggy.zip')
io_loop.instance().start()
Kevin LaTona
Aug 30, 2016, 3:54:20 PM8/30/16
to python-tornado@googlegroups.com Server
Here is an Async Await version of the client code.
So far not seeing any big adavantage over straight Tornado calls, but it does show the chunk size being pushed over the wire.
If any one sees any tweaks please mention them.
So far not seeing any big adavantage over straight Tornado calls, but it does show the chunk size being pushed over the wire.
If any one sees any tweaks please mention them.
-Kevin
from tornado.httpclient import HTTPRequest, AsyncHTTPClient
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
import datetime
total_downloaded = 0
from tornado.httpclient import HTTPRequest, AsyncHTTPClient
import tornado.ioloop
import tornado.web
from tornado import gen
from functools import partial
import datetime
total_downloaded = 0
def spawn_callback(callback, *args, **kwargs):
with NullContext():
add_callback(callback, *args, **kwargs)
with NullContext():
add_callback(callback, *args, **kwargs)
def chunky(path, chunk):
global total_downloaded
total_downloaded += len(chunk)
print(len(chunk), total_downloaded)
global total_downloaded
total_downloaded += len(chunk)
with open(path, 'a+b') as f:
f.write(chunk)
async def writer(file_name):
f.write(chunk)
print('start reading')
s = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient(max_body_size=1024*1024*550) # 550MB file limit
response = await http_client.fetch(request)
s = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
request = HTTPRequest('http://127.0.0.1:8880/', streaming_callback=partial(chunky, file_name))
http_client = AsyncHTTPClient(max_body_size=1024*1024*550) # 550MB file limit
tornado.ioloop.IOLoop.instance().stop()
e = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S:%f')
print(s,e)
if __name__ == "__main__":
if __name__ == "__main__":
Cong Wang
Sep 25, 2016, 3:42:00 AM9/25/16
to python-...@googlegroups.com

The picture above is the difference between http1 and http2. So will tornado be able to use http2?
For the first line,http2 is binary instead of textual.That means that all the file that transferred by http1 is textual?or means that all the information transferred by http2 are transferred by binary?I am confused.
Thanks!
Ben Darnell
Sep 25, 2016, 6:08:05 AM9/25/16
to python-...@googlegroups.com
The file itself is transferred in binary in both HTTP/1 and 2. The binary vs textual distinction applies to the headers and framing elements of the protocol: these are textual in HTTP/1 and binary in HTTP/2.
There is an implementation of HTTP/2 for Tornado in https://github.com/bdarnell/tornado_http2
-Ben
On Sun, Sep 25, 2016 at 3:42 PM Cong Wang <congfa...@gmail.com> wrote:

To unsubscribe from this group and all its topics, send an email to python-tornad...@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornad...@googlegroups.com.
Cong Wang
Oct 8, 2016, 2:14:15 AM10/8/16
to python-...@googlegroups.com
Hi,
What is the difference between tornado web framework and http servers and clients?
About my system.I would like to use libcurl for the client part ,because in the client part,the system need to do something with the filesystem in c++ language.Now what I fulfill the data transfer is with web framework.(the code is here:https://github.com/congfairy/leaf.git)
But I don't think this code can be used as a lib by c++ .so I would like to use the libcurl.How could I fulfill this ?Thanks!
Best regards,
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
--
You received this message because you are subscribed to the Google Groups "Tornado Web Server" group.
To unsubscribe from this group and stop receiving emails from it, send an email to python-tornado+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
You received this message because you are subscribed to a topic in the Google Groups "Tornado Web Server" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/python-tornado/7trIoyCch5k/unsubscribe.
To unsubscribe from this group and all its topics, send an email to python-tornado+unsubscribe@googlegroups.com.
Message has been deleted

Markus Heidt
Nov 21, 2017, 6:42:13 PM11/21/17
to Tornado Web Server
Actually it is possible with your first approach.
# the TemporaryFileStreamedPart is using os.rename which doesn't work as good as shutil.move:
class UploadStreamPart(TemporaryFileStreamedPart):
def move(self, file_path):
if not self.is_finalized:
raise Exception("Cannot move temporary file: stream is not finalized yet.")
if self.is_moved:
raise Exception("Cannot move temporary file: it has already been moved.")
self.f_out.close()
shutil.move(self.f_out.name, file_path)
self.is_moved = True
class UploadPostDataStreamer(MultiPartStreamer):
percent = 0
def __init__(self, destinationPath, total):
self.destinationPath = destinationPath
super(UploadPostDataStreamer, self).__init__(total)
def create_part(self, headers):
return UploadStreamPart(self, headers, tmp_dir=None)
def data_complete(self):
super(UploadPostDataStreamer, self).data_complete()
for part in self.parts:
if part.get_size()>0:
destinationFilename = part.get_filename()
part.move(self.destinationPath + "/" + destinationFilename)
Reply all
Reply to author
Forward
0 new messages