DUVIDAS NO PANDAS
18 views
Skip to first unread message

juarezr...@gmail.com
May 5, 2022, 6:48:26 AM5/5/22
to Python Brasil
Pessoal, estou quebrando a cabeça a alguns dias com uma dúvida.
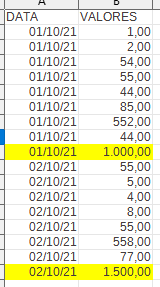
Tenho uma planilha, que quero levar para o pandas e fazer alguns filtros.
Entre eles, eu preciso pegar sempre o valor da ultima linha de cada data.
Nesse exemplo, eu preciso criar um novo dataframe, com o ultimo valor do dia 01/10/21 e do dia 02/1021.
Alguém tem alguma sugestão de como fazer?

Lauriano Elmiro Duarte
May 5, 2022, 5:26:49 PM5/5/22
to python...@googlegroups.com
Opa, boa noite Juarez,
Eu tenho uma idéia,
Se você notar, você quer pegar sempre o maior valor diário da tabela,
1000 é o maior valor diário de 01/10/2021 e 1500 é o maior diário de 02/10/2021.
Eu não tenho certeza se essa lógica se aplica a essa tabela, não tenho acesso a toda planilha.
Mas a dica é só você enumerar a data baseada nos valores, o pandas faz isso.
Aqui está um exemplo do que estou me referindo, qualquer dúvida se não for isso, pergunte novamente .
Abraços
--
--
------------------------------------
Grupo Python-Brasil
https://wiki.python.org.br/AntesDePerguntar
<*> Para visitar o site do grupo na web, acesse:
http://groups.google.com/group/python-brasil
<*> Para sair deste grupo, envie um e-mail para:
python-brasi...@googlegroups.com
---
Você recebeu essa mensagem porque está inscrito no grupo "Python Brasil" dos Grupos do Google.
Para cancelar inscrição nesse grupo e parar de receber e-mails dele, envie um e-mail para python-brasi...@googlegroups.com.
Para ver essa discussão na Web, acesse https://groups.google.com/d/msgid/python-brasil/5d6a7eb2-0f33-4418-952a-8a07ba6aa6b8n%40googlegroups.com.
Juarez Roncalli
May 6, 2022, 7:37:51 AM5/6/22
to python...@googlegroups.com
Ontem descobri uma forma de fazer, como eu precisava do saldo da última linha de cada data, usei o código abaixo:
novo_df = df.drop_duplicates(subset='Data', keep='last')
Nele, são excluídas as linhas duplicadas da data, deixando apenas a última.
Para ver essa discussão na Web, acesse https://groups.google.com/d/msgid/python-brasil/CA%2B4MiHREShUG1Cou_JjdnNYi8hTCLV8O%2BAuQjcGT2K%3DfxXG3DA%40mail.gmail.com.

Henrique Pougy
May 6, 2022, 9:40:18 AM5/6/22
to python...@googlegroups.com
Olá bom dia.
Primeiro, dê df = df.reset_index() para jogar o índice como uma coluna. Ou então df['indice'] = df.index
Em seguida, ordene o dataframe pela coluna de data em primeiro lugar e pelo índice em segundo lugar:
df = df.sort_values(by=['DATA', 'indice'])
Agora, agrupe o dataframe pela pela coluna de data:
grouped = df.groupby(by=['DATA'])
Por fim, selecione apenas os primeiros registros para cada subgrupo (ou seja, cada data):
grouped.first()
--
Henrique Pougy
May 6, 2022, 9:44:01 AM5/6/22
to python...@googlegroups.com
Em tempo: você queria o último valor, não o primeiro. Então selecione grouped.last()
Reply all
Reply to author
Forward
0 new messages