Dúvida - Contagem de valores nulos por Trimestre
13 views
Skip to first unread message

thayane sviercoski
Apr 24, 2023, 11:45:25 AM4/24/23
to Python Brasil
Pessoal estou com uma dúvida em um exercício.
Tenho um banco com os dados das precipitações por hora, de 2011 até 2020.
Preciso fazer a contagem de NaN por Trimestre.
Segue o que eu fiz até agora:
dataframe = pd.read_csv('dataset_reg_chuva_santa_maria_2011_2020.csv', sep =";")
dataframe = dataframe.set_index(pd.to_datetime(dataframe['DT_MEDICAO']))
dataframe.drop(columns = ['DT_MEDICAO']) #apaga a coluna
print(dataframe['CHUVA'].unique()) #Verifica os valores "estranhos" #unique printa os numeros somente uma vez
num_nans = dataframe['CHUVA'].isna().sum() #valores Not a Number (NAN)
print("Numero de NANs: ", num_nans) #printa numero de NANs
# identificação dos valores nulos
mask = dataframe['CHUVA'].isna()
# obtenção dos índices dos valores nulos
null_indices = dataframe.loc[mask].index
print(null_indices)
dataframe['CHUVA'] = dataframe['CHUVA'].str.replace(',', '.') #substituo os numeros com virgula por ponto
dataframe['CHUVA'] = pd.to_numeric(dataframe['CHUVA'], errors='coerce') #Aqui converte pra numérico
dataframe['CHUVA'] = dataframe['CHUVA'].astype(float) #converte os numeros pra float
dataframe['CHUVA'] = dataframe['CHUVA'].fillna(value=0) #preenche os valores que realmente não são números com zeros
dataframe['DT_MEDICAO'] = pd.to_datetime(dataframe['DT_MEDICAO'])
print("TAMANHO DATAFRAME: ", dataframe.shape[0])
diai=int(1)
mesi=int(1)
anoi=int(2011)
datai=date(anoi,mesi,diai)
diaf=int(31)
mesf=int(12)
anof=int(2020)
dataf=date(anof,mesf,diaf)
delta_1dia=timedelta(days=1)
data_atual = datai
vetor_com_todas_as_datas=[]
while ( data_atual<=dataf ):
vetor_com_todas_as_datas.append(data_atual)
data_atual=data_atual+delta_1dia
print('Numero de datas entre 2011 e 2020 e ',len(vetor_com_todas_as_datas))
num_medidas=len(vetor_com_todas_as_datas)*24
print('Números de linhas que deveria ter o Dataframe: ' ,num_medidas)
num_linhas_dataframe = len(dataframe)
diferenca = num_medidas - num_linhas_dataframe
print("Número de dados faltantes no Dataframe: ", diferenca)
import pandas as pd
dataframe_trimestral = dataframe.resample('Q').sum(numeric_only=True)
dataframe_trimestral.reset_index(inplace=True)
# Selecionar apenas as colunas 'trimestre' e 'precipitacao' e armazenar em um novo DataFrame
dataframe_trimestral_selecionado = dataframe_trimestral.loc[:, ['DT_MEDICAO', 'CHUVA']]
# Exibir o novo DataFrame com apenas as duas colunas selecionadas
print(dataframe_trimestral_selecionado)
dataframe.to_csv('valores_cumulativos.csv', index=False) #salva um CSV com os dados tratados

Paul Eipper
Apr 24, 2023, 12:45:21 PM4/24/23
to python...@googlegroups.com
Fiz um teste e perguntei para o ChatGPT, veja se atende:
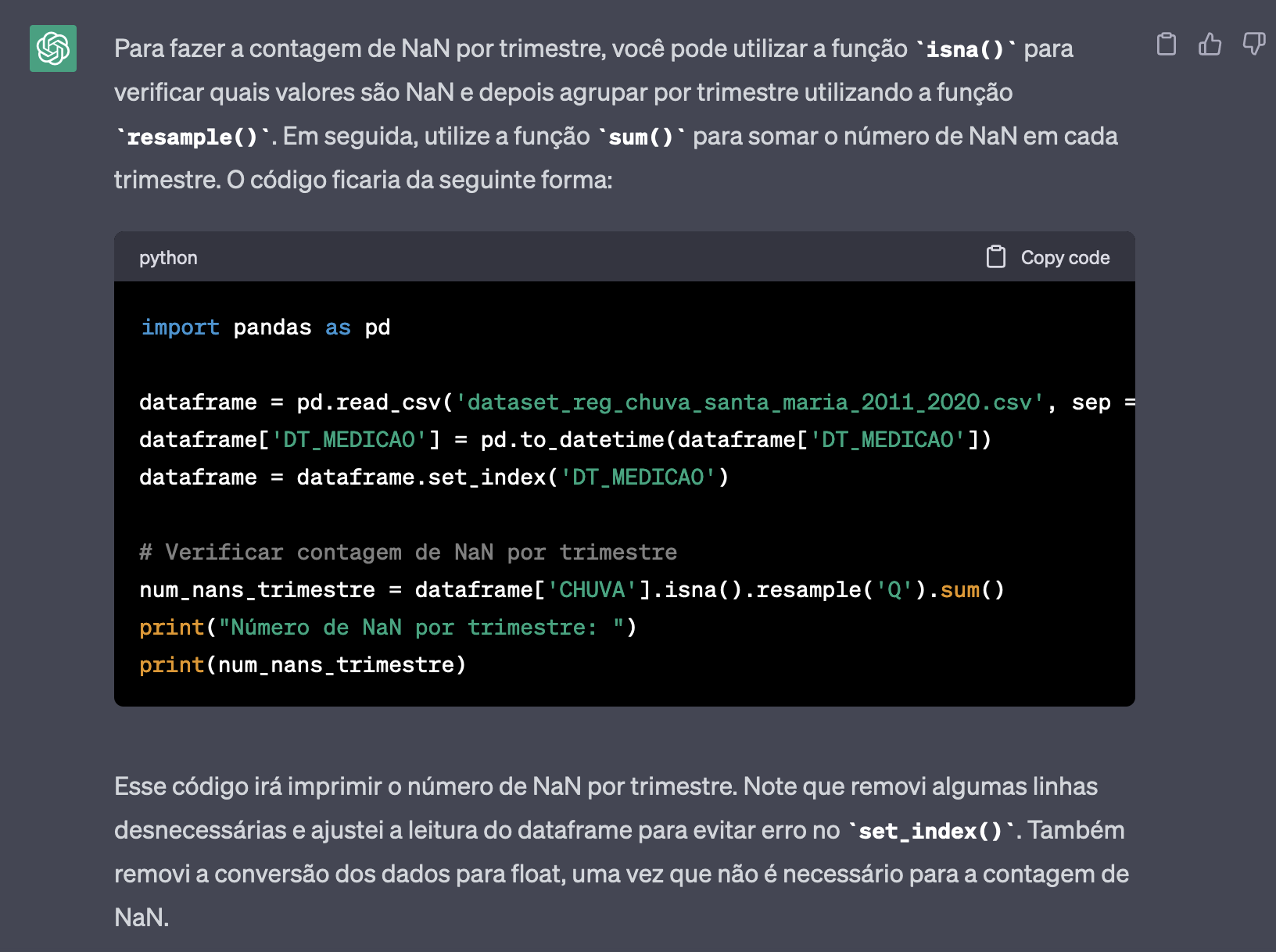
att,
--
Paul Eipper
Paul Eipper
--
--
------------------------------------
Grupo Python-Brasil
https://wiki.python.org.br/AntesDePerguntar
<*> Para visitar o site do grupo na web, acesse:
http://groups.google.com/group/python-brasil
<*> Para sair deste grupo, envie um e-mail para:
python-brasi...@googlegroups.com
---
Você recebeu essa mensagem porque está inscrito no grupo "Python Brasil" dos Grupos do Google.
Para cancelar inscrição nesse grupo e parar de receber e-mails dele, envie um e-mail para python-brasi...@googlegroups.com.
Para ver essa discussão na Web, acesse https://groups.google.com/d/msgid/python-brasil/e98f7e3d-f1e8-4f69-8641-ffdbea27169fn%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages