Include GEOM tables in output OP2 files

Philip Moseley

Steven Doyle
--
You received this message because you are subscribed to the Google Groups "pyNastran Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to pynastran-disc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/6b21f294-2a12-4c4a-a2a1-f93ba17a3a72n%40googlegroups.com.
Philip Moseley

Steven Doyle
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/dcee45b0-5acc-45d2-b1af-86145af5034an%40googlegroups.com.

Cean Wang
I am playing with OP2 and found this post. I tried read_op2_geom() command. I got an error:

Look at the op2 file with a HEX editor, it shows after the NASTRAN_VERSION which is XXXXXXXX, they added one more version section which is 2020 0 0 before the record end (FF FF FF FF)

Sent from Mail for Windows
From: Philip Moseley
Sent: Monday, January 18, 2021 3:45 AM
To: pyNastran Discuss
Subject: Re: Include GEOM tables in output OP2 files
Hey Steve,
I've been playing around with the read_op2_geom() command, but I'm still having trouble getting pyNastran to write an OP2 that includes both the geometry and the results.
I've been trying lines like:
model = read_op2_geom(inp_file, include_results=['stress','strain','displacements'])
model.write_op2(out_file)
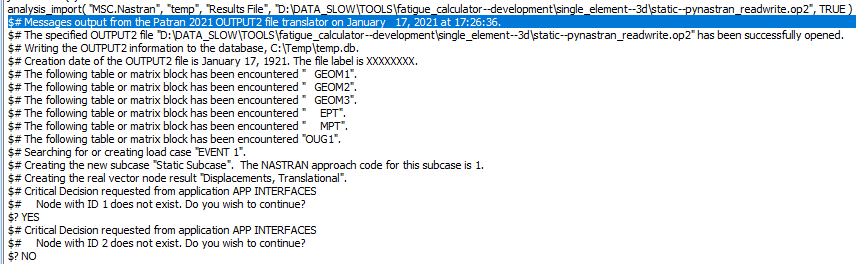
But I'm still not able to get MSC software to read these pyNastran OP2s correctly. Patran gives me the following log when I try to use the "Read Output2" file command with "Both Model Data and Result Entities":
I was able to exchange a few emails with an MSC Apex developer, they told me that Apex uses the same import code as Patran. But it seems like maybe MSC Apex is converting the file to an HDF format, and then importing it. I get the following error for the same pyNastran OP2 file:
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/dcee45b0-5acc-45d2-b1af-86145af5034an%40googlegroups.com.
Steven Doyle
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/531AEC5A-F2DD-4CD4-A47F-972EA720C824%40hxcore.ol.
Cean Wang
I am using pyNastran to read the single_element--3d.zip he provided. I think it was made with Apex. pyNastran can’t read the extra section - 2020 0 0. In the other way, OP2 generated by pyNastran doesn’t has this extra section, so Apex can’t read it. No idea about hdf5, it looks not too much format change.
From: Steven Doyle
Sent: Friday, August 4, 2023 3:29 PM
To: pynastra...@googlegroups.com
Subject: Re: Include GEOM tables in output OP2 files
That doesn't seem related to the previous question on hdf5. Please make a new question. Also, I probably need a small example,
On Thu, Aug 3, 2023 at 7:58 PM Cean Wang <cean...@gmail.com> wrote:
I am playing with OP2 and found this post. I tried read_op2_geom() command. I got an error:
Look at the op2 file with a HEX editor, it shows after the NASTRAN_VERSION which is XXXXXXXX, they added one more version section which is 2020 0 0 before the record end (FF FF FF FF)
Sent from Mail for Windows
From: Philip Moseley
Sent: Monday, January 18, 2021 3:45 AM
To: pyNastran Discuss
Subject: Re: Include GEOM tables in output OP2 files
Hey Steve,
I've been playing around with the read_op2_geom() command, but I'm still having trouble getting pyNastran to write an OP2 that includes both the geometry and the results.
I've been trying lines like:
model = read_op2_geom(inp_file, include_results=['stress','strain','displacements'])
model.write_op2(out_file)
But I'm still not able to get MSC software to read these pyNastran OP2s correctly. Patran gives me the following log when I try to use the "Read Output2" file command with "Both Model Data and Result Entities":


I was able to exchange a few emails with an MSC Apex developer, they told me that Apex uses the same import code as Patran. But it seems like maybe MSC Apex is converting the file to an HDF format, and then importing it. I get the following error for the same pyNastran OP2 file:
At least for the simple single-element problem, Apex manages to import the mesh, but it can't import the subcases, and therefore can't access the results.
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/CADJnEGF4fKOq5hzeOzs3XLPtEv9vYtL6w4%3D_Zu4aCvbtt%3Damaw%40mail.gmail.com.
Steven Doyle
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/4BAFFF59-DD6E-4E38-B3F4-C93A34F53173%40hxcore.ol.