Point ID - SPC forces

L D
Hello,
Firstly, thank you again for your previous help. If you have a few minutes, I would love your advice on the following issue.
I’m trying to extract the OP2 equivalent of this f06 table:

Composed of 85 lines and therefore 85 point ID.
The first red flag I got was that through the get_op2_stats function, I obtained a table way out of proportion, 19585 instead of 85 :
spc_forces[1]
isubcase = 1
type=RealSPCForcesArray nnodes=19585, table_name=OQG1
data: [t1, t2, t3, r1, r2, r3] shape=[1, 19585, 6] dtype=float32
node_gridtype.shape = (19585, 2)
sort1
lsdvmns = [1]
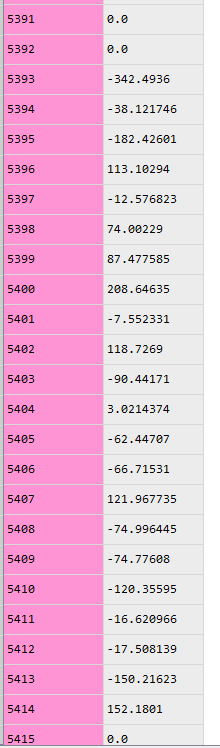
When I try to extract t1 for example through pd.DataFrame(model_OP2.spc_forces[subcase_id].data_frame.t1) , I have two issues:
- It provides a column for t1 with the 85 correct values and the rest of the 19585 lines full of zero
- The index is not corresponding at all to the Point ID. For the first value for example, I have a value of 5393 instead of 201101
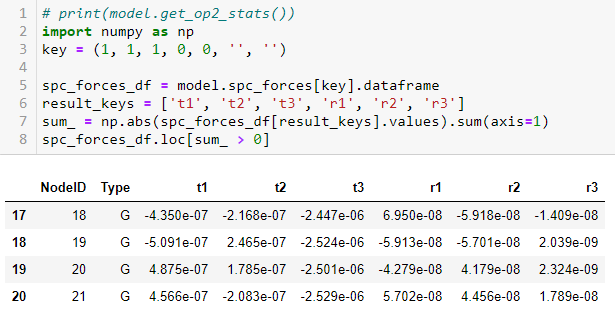
The first problem I managed to solve like this:
list_SPC_try =
pd.DataFrame([model_OP2.spc_forces[subcase_id].data_frame.t1,
model_OP2.spc_forces[subcase_id].data_frame.t2,
model_OP2.spc_forces[subcase_id].data_frame.t3,
model_OP2.spc_forces[subcase_id].data_frame.r1,
model_OP2.spc_forces[subcase_id].data_frame.r2,
model_OP2.spc_forces[subcase_id].data_frame.r3
])
list_SPC_try = list_SPC_try.T
list_SPC_try = list_SPC_try[list_SPC_try.t1 !=0]
Which provides me a database in all way similar to the one I want except for the index:

I’ve tried to find similitudes between the index and the point ID (for example between 5393 and 201101) in the .F06 file but cannot find anything.
The index values seem to be linked to the GRID cards:
5393- GRID 139157 100003 2.58980 0.54375 0.63661 0
But none of those values (GRID ID, or coordinate systems) seem to be linked to the Point ID (in this case 201101).
I tried to extract the Points ID through the .point_ids formula which I found in the documentation but without success.
This issue didn’t happen neither for Von Mises nor Hill which both gave me the correct Element ID (and not Point ID) in my dataframes.
Would you know how to extract the correct point IDs?
Thank you very much for your help.
Best regards,
Laurène

Steven Doyle
--
You received this message because you are subscribed to the Google Groups "pyNastran Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to pynastran-disc...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/pynastran-discuss/9e91d0bc-d019-4a25-bce4-718f6819a2f7n%40googlegroups.com.
L D
