Prometheus Memory and Head Chunks growing
427 views
Skip to first unread message

frel...@gmail.com
Aug 26, 2018, 10:30:56 PM8/26/18
to Prometheus Users
I have a few Prometheus 2.3.2 servers and they are all running fine except for one. It is starting to run out of memory and the number of Head Chunks in the graph is continually growing unlike the other servers where it grows and shrinks. This is not a very busy server. I have included the graph of the performance.
Any insight would be appreciated. I can't find anything different on this server than on the others but obviously there must be something that I am missing.
By the way, this is all running in Docker.
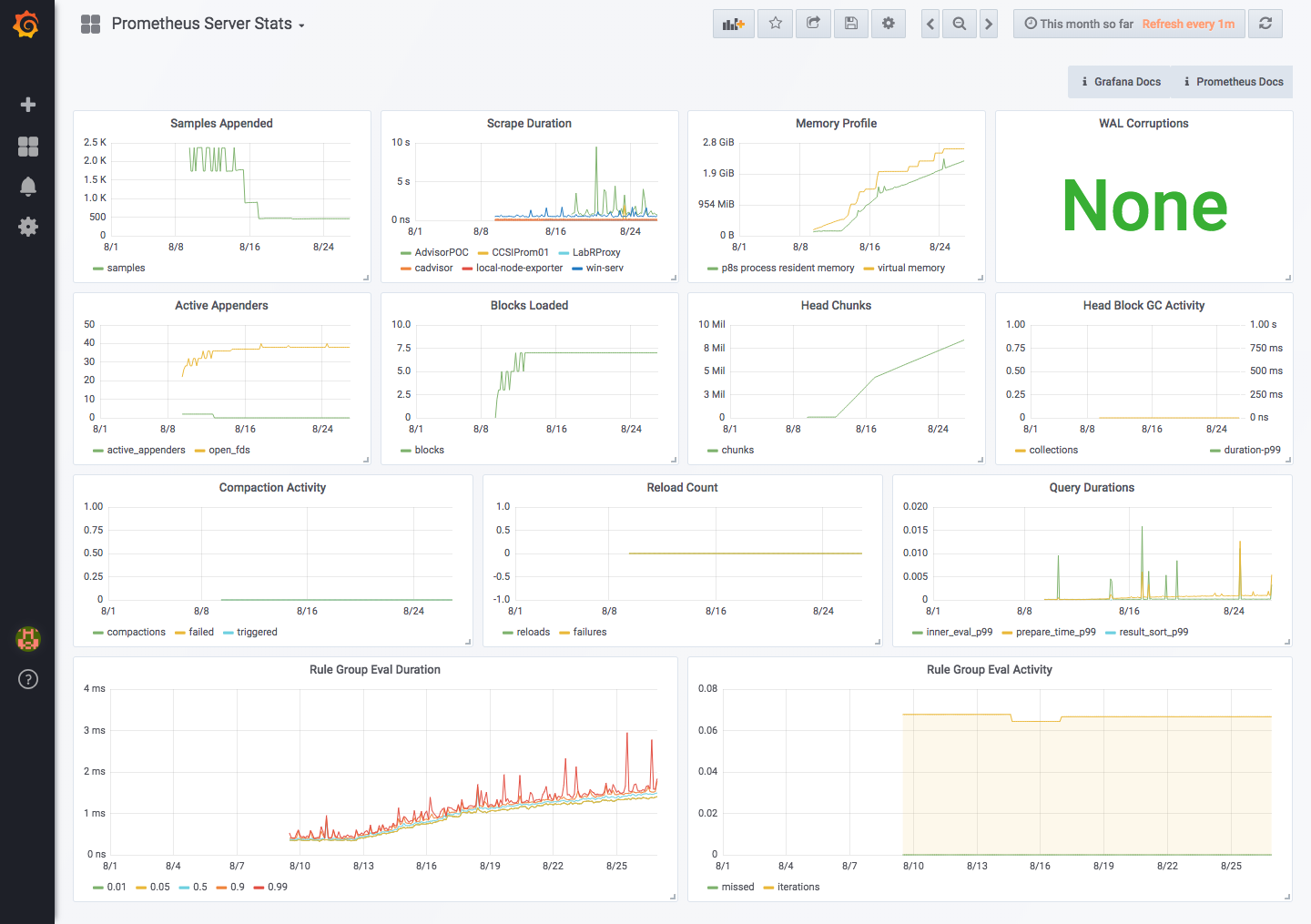
Thanks,
Joe

Goutham Veeramachaneni
Aug 27, 2018, 3:21:22 AM8/27/18
to frel...@gmail.com, Prometheus Users
Hi Joe,
Could you share the logs here? Usually a compaction error is what causes this. Also, could you tell if this server had a restart before this behaviour was first seen, and if the restart was clean.
Thanks,
Goutham.
On Aug 27 2018, at 8:00 am, frel...@gmail.com wrote:
I have a few Prometheus 2.3.2 servers and they are all running fine except for one. It is starting to run out of memory and the number of Head Chunks in the graph is continually growing unlike the other servers where it grows and shrinks. This is not a very busy server. I have included the graph of the performance.Any insight would be appreciated. I can't find anything different on this server than on the others but obviously there must be something that I am missing.By the way, this is all running in Docker.
Thanks,Joe--You received this message because you are subscribed to the Google Groups "Prometheus Users" group.To unsubscribe from this group and stop receiving emails from it, send an email to prometheus-use...@googlegroups.com.To post to this group, send email to promethe...@googlegroups.com.To view this discussion on the web visit https://groups.google.com/d/msgid/prometheus-users/c54b5730-1f16-4a56-8576-25ebabcacbe5%40googlegroups.com.For more options, visit https://groups.google.com/d/optout.
frel...@gmail.com
Aug 27, 2018, 7:52:44 AM8/27/18
to Prometheus Users
Goutham,
Thanks for the reply, I believe you are correct. I think I found the source of the problem. The server was made in AWS from an AMI and what used to be a clean snapshot of a data volume with no database. It appears the snapshot was updated and in the process it was updated with a data volume that already had data in the database from some other server.
I deleted the database and started from scratch and now it is looking much happier. I will keep an eye on it but it appear to be running properly now.
Thanks!!
Joe
Reply all
Reply to author
Forward
0 new messages