Worked example for "using-time-series-as-alert-thresholds" blog posts?
53 views
Skip to first unread message

William Hargrove
Jan 13, 2022, 3:30:39 PM1/13/22
to Prometheus Users
Is anyone able to share some worked examples based from Brian's blog post (https://www.robustperception.io/using-time-series-as-alert-thresholds), specifically related to setting differing disk space thresholds and alerting from those?
I'm struggling to apply this article - perhaps I am finding the concept a little abstract.
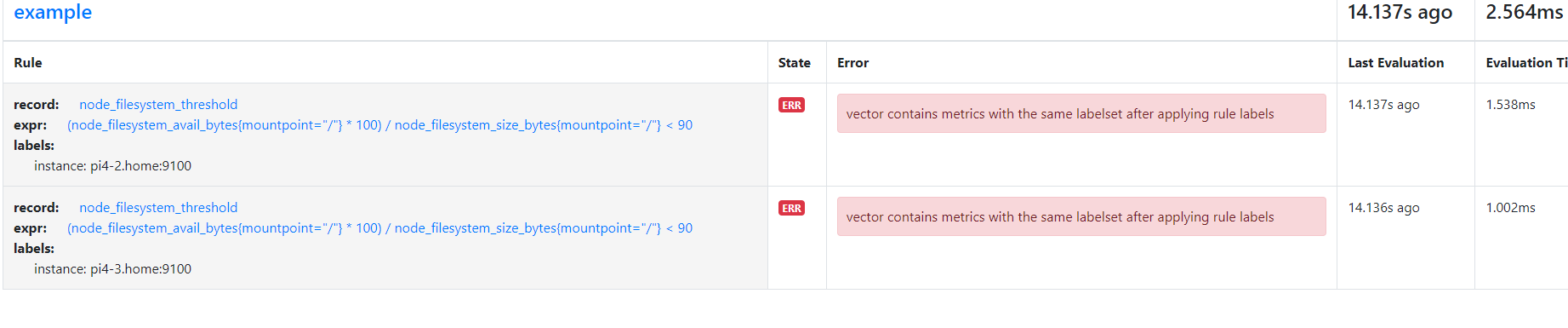
I have tried to construct the example illustrated below, but this doesn't work and the recording rules error with "vector contains metrics with the same labelset after applying rule labels".
I have three example systems, one should be monitored by the "default" threshold in the alert rule definition (instance: pi4-1.home:9100), the other two should have threshold set via recording rules (instance: pi4-2.home:9100 adn pi4-3.home:9100). I want to set thresholds per instance. Am I correct in thinking that I need a rule per instance as I am setting the override on the instance label?
Alert:
- alert: HostOutOfDiskSpace
expr: |
# Alert on per instance thresholds, with a default
(node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"}
< on (instance) group_left()
(
node_filesystem_threshold
or on(instance)
count by (instance)(node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} * 0 + 70
)
for: 5s
labels:
severity: critical
notification: slack
annotations:
summary: "{{ $labels.alertname }} on {{ $labels.instance }}"
description: "Disk is almost full {{ humanize $value }}% on {{ $labels.mountpoint }}"
expr: |
# Alert on per instance thresholds, with a default
(node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"}
< on (instance) group_left()
(
node_filesystem_threshold
or on(instance)
count by (instance)(node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} * 0 + 70
)
for: 5s
labels:
severity: critical
notification: slack
annotations:
summary: "{{ $labels.alertname }} on {{ $labels.instance }}"
description: "Disk is almost full {{ humanize $value }}% on {{ $labels.mountpoint }}"
Recording rules:
groups:
- name: example
rules:
- record: node_filesystem_threshold
expr: (node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} < 90
labels:
instance: pi4-2.home:9100
- record: node_filesystem_threshold
expr: (node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} < 90
labels:
instance: pi4-3.home:9100
- name: example
rules:
- record: node_filesystem_threshold
expr: (node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} < 90
labels:
instance: pi4-2.home:9100
- record: node_filesystem_threshold
expr: (node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"} < 90
labels:
instance: pi4-3.home:9100
This gives the error below:
If anyone is able to help me build out/correct this example I would be most grateful.
Thanks.
Reply all
Reply to author
Forward
0 new messages