Alerts are getting auto resolved automatically
1,099 views
Skip to first unread message

Venkatraman Natarajan
Jun 25, 2022, 8:27:22 AM6/25/22
to Prometheus Users
Hi Team,
We are having two prometheus and two alert managers in separate VMs as containers.
Alerts are getting auto resolved even though the issues are there as per threshold.
For example, if we have an alert rule called probe_success == 0 means it is triggering an alert but after sometime the alert gets auto-resolved because we have enabled send_resolved = true. But probe_success == 0 still there so we don't want to auto resolve the alerts.
Could you please help us on this.?
Thanks,
Venkatraman N

Brian Candler
Jun 25, 2022, 11:35:03 AM6/25/22
to Prometheus Users
If probe_success becomes non-zero, even for a single evaluation interval, then the alert will be immediately resolved. There is no delay on resolving, like there is for pending->firing ("for: 5m").
Conversely, use the query
probe_success{instance="xxx"} != 0
to look at a particular timeseries, as identified by the label9s), and see if there are any dots shown where the label is non-zero.
To make your alerts more robust you may need to use queries with range vectors, e.g. min_over_time(foo[5m]) or max_over_time(foo[5m]) or whatever.
As a general rule though: you should consider carefully whether you want to send *any* notification for resolved alerts. Personally, I have switched to send_resolved = false. There are some good explanations here:
You don't want to build a culture where people ignore alerts because the alert cleared itself - or is expected to clear itself.
You want the alert condition to trigger a *process*, which is an investigation of *why* the alert happened, *what* caused it, whether the underlying cause has been fixed, and whether the alerting rule itself was wrong. When all that has been investigated, manually close the ticket. The fact that the alert has gone below threshold doesn't mean that this work no longer needs to be done.
Venkatraman Natarajan
Jul 5, 2022, 3:35:04 AM7/5/22
to Brian Candler, Prometheus Users
Thanks Brian. I have used last_over_time query in our expression instead of turning off auto-resolved.
Also, we have two alert managers in our environment. Both are up and running. But Nowadays, we are getting two alerts from two alert managers. Could you please help me to sort this issue as well.?
Please find the alert manager configuration.
Also, we have two alert managers in our environment. Both are up and running. But Nowadays, we are getting two alerts from two alert managers. Could you please help me to sort this issue as well.?
Please find the alert manager configuration.
alertmanager0:
image: prom/alertmanager
container_name: alertmanager0
user: rootuser
volumes:
- ../data:/data
- ../config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/data/alert0'
- '--cluster.listen-address=0.0.0.0:6783'
- '--cluster.peer={{ IP Address }}:6783'
- '--cluster.peer={{ IP Address }}:6783'
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "2"
ports:
- 9093:9093
- 6783:6783
networks:
- network
image: prom/alertmanager
container_name: alertmanager0
user: rootuser
volumes:
- ../data:/data
- ../config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/data/alert0'
- '--cluster.listen-address=0.0.0.0:6783'
- '--cluster.peer={{ IP Address }}:6783'
- '--cluster.peer={{ IP Address }}:6783'
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "2"
ports:
- 9093:9093
- 6783:6783
networks:
- network
Regards,
Venkatraman N
--
You received this message because you are subscribed to the Google Groups "Prometheus Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to prometheus-use...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/prometheus-users/68bff458-ee79-42ce-bafb-facd239e26aen%40googlegroups.com.

Stuart Clark
Jul 5, 2022, 3:49:09 AM7/5/22
to promethe...@googlegroups.com, Venkatraman Natarajan, Brian Candler, Prometheus Users
Two alerts suggests that the two instances aren't talking to each other. How have you configured them? Does the UI show the "other" instance?
--
Sent from my Android device with K-9 Mail. Please excuse my brevity.
Sent from my Android device with K-9 Mail. Please excuse my brevity.
Venkatraman Natarajan
Jul 5, 2022, 4:28:01 AM7/5/22
to Stuart Clark, Prometheus Users, Brian Candler
Hi Stuart,
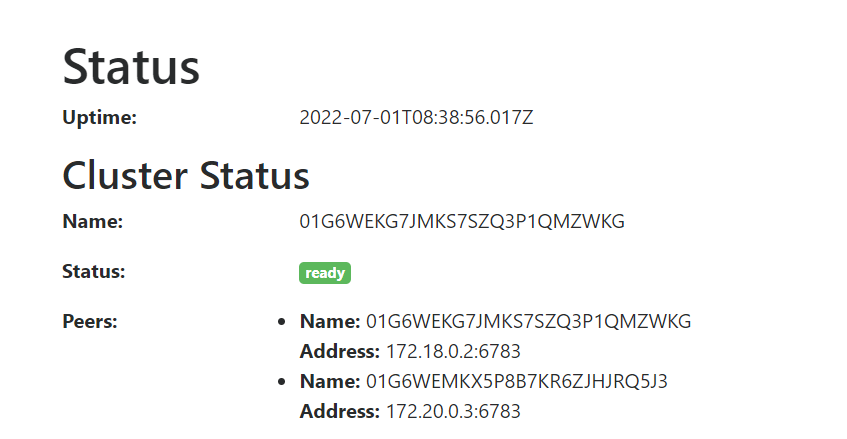
Yes I can see both cluster peers and showing information like the cluster is ready.
Thanks,
Venkatraman N
Reply all
Reply to author
Forward
0 new messages