Bulk Insert
158 views
Skip to first unread message

Vikram Roopchand
Jul 31, 2022, 7:27:38 AM7/31/22
to projectnessie
Hello There,
Hope you are doing well. We have recently started using Iceberg along with Nessie (Spark 3.3).
Is there a way we can insert rows in bulk and the commit is performed on the whole set atomically ?
thanks,
best regards,
Vikram

Ajantha Bhat
Aug 1, 2022, 1:30:52 AM8/1/22
to Vikram Roopchand, projectnessie
Hi Vikram,
Nessie commits are directly mapped to Iceberg's transactions (commits).
Regarding the bulk insert support in Iceberg, I saw your question on Iceberg slack too.
I don't remember having bulk insert support (similar to Hudi), let's continue tracking that in Iceberg slack.
That being said, In Nessie,
we can create a temp_branch from the original_branch and do multiple normal insert operations in temp_branch
and merge them back to the original_branch as a single atomic commit (just a metadata operation).
Thanks,
Ajantha
Nessie commits are directly mapped to Iceberg's transactions (commits).
Regarding the bulk insert support in Iceberg, I saw your question on Iceberg slack too.
I don't remember having bulk insert support (similar to Hudi), let's continue tracking that in Iceberg slack.
That being said, In Nessie,
we can create a temp_branch from the original_branch and do multiple normal insert operations in temp_branch
and merge them back to the original_branch as a single atomic commit (just a metadata operation).
Thanks,
Ajantha
--
You received this message because you are subscribed to the Google Groups "projectnessie" group.
To unsubscribe from this group and stop receiving emails from it, send an email to projectnessi...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/projectnessie/c8748ad8-6f09-4eb9-8a7c-20cf5a805e6bn%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Vikram Roopchand
Aug 1, 2022, 3:09:00 AM8/1/22
to Ajantha Bhat, projectnessie
Dear Ajantha,
Thank you for replying.
Regarding the bulk insert support in Iceberg, I saw your question on Iceberg slack too.
I don't remember having bulk insert support (similar to Hudi), let's continue tracking that in Iceberg slack.
Yes, the thing is since an atomic commit is done per insert (hence a new snapshot) the data insertion is taking a long time and our 'E' layer works on SQL inserts. I wanted to avoid snapshots until the entire 'insert' cycle is complete.
That being said, In Nessie,
we can create a temp_branch from the original_branch and do multiple normal insert operations in temp_branch
and merge them back to the original_branch as a single atomic commit (just a metadata operation).
Oh super, but will this avoid snapshots in the temp_branch ? This is critical.
Presently we write Parquets and operate directly on those, another approach we are considering is using the Nessie API ( by way of Table > Transaction > Append > Commit) however, this is going slow since there aren't any many decent samples around or the documentation :) ... But that's okay, part of S/W development. Quick question here too, would you have any idea if Transaction.newAppend() >> DataFile >> Commit will use the same file or create a copy of the data in that file and we can delete the temp file ...
Thanks again,
best regards,
Vikram
Ajantha Bhat
Aug 1, 2022, 3:34:00 AM8/1/22
to Vikram Roopchand, projectnessie
Oh super, but will this avoid snapshots in the temp_branch ? This is critical.
No, temp_branch will have a snapshot, but it is not visible for origin_branch. Only for merge, it will be visible in the origin_branch
Presently we write Parquets and operate directly on those, another approach we are considering is using the Nessie API ( by way of Table > Transaction > Append > Commit) however, this is going slow since there aren't any many decent samples around or the documentation :) ... But that's okay, part of S/W development.
If SQL level support is not needed, It is advisable to use the NessieCatalog.java which uses NessieTableOperstions.java for transactions.
Also, do you mean that documentation is not enough to use the NessieCatalog API? Where do you feel the gap is there? we can improve it.
Also, do you mean that documentation is not enough to use the NessieCatalog API? Where do you feel the gap is there? we can improve it.
Quick question here too, would you have any idea if Transaction.newAppend() >> DataFile >> Commit will use the same file or create a copy of the data in that file and we can delete the temp file ...
Catalog is only responsible for metadata management. Data file writing logic will be common for all the catalogs.
In Iceberg, all data files are immutable. So, it cannot append to the same files. And Iceberg slack is the right place to dig down on the Iceberg specific internals.
Thanks,
Ajantha
In Iceberg, all data files are immutable. So, it cannot append to the same files. And Iceberg slack is the right place to dig down on the Iceberg specific internals.
Thanks,
Ajantha
Vikram Roopchand
Aug 1, 2022, 6:27:37 AM8/1/22
to Ajantha Bhat, projectnessie
Dear Ajantha,
I couldn't find a proper sample to help me out. We have created a sample to test out the APIs, however during development (of the sample) the (catalog) state seemed to have become inconsistent and we keep getting a "java.lang.IllegalStateException: Cannot commit transaction: last operation has not committed". Is there any way to rollback all transactions and come to a clean state.
Here is the outline of the code:
NessieCatalog d = new NessieCatalog();
d.setConf(s.sparkContext().hadoopConfiguration());
d.initialize("nessie", ImmutableMap.of(
"ref", "main",
"uri", "http://localhost:19120/api/v1",
"warehouse", "hdfs://voyager:9000/DI/warehouse"));
String tblName = "testtable8";
s.sqlContext().sql("create table nessie." + tblName + " (col0 string, col1 string, col2 string, col3 string, col4 string) " +
"using iceberg location 'hdfs://voyager:9000/DI/warehouse/mylocation/" + tblName + "'");
TableIdentifier tt = TableIdentifier.parse(tblName);
Table t = d.loadTable(tt);
Transaction transaction = t.newTransaction();
AppendFiles files = transaction.newAppend();
//Tried this approach #1
// AppendFiles files = t.newAppend();
String fileLocation = "hdfs://voyager:9000/DI/warehouse/" + tblName;
int numRecords = writeDummyData("temp_" + tblName);
DataFile file = DataFiles.builder(t.spec())
.withRecordCount(numRecords)
.withPath(fileLocation)
.withFormat(FileFormat.PARQUET)
.withFileSizeInBytes(Files.localInput(fileLocation).getLength())
.build();
//#1 approach , did not work, select count(*) did not show numRecords
// files.appendFile(file).commit();
files.appendFile(file);
transaction.commitTransaction(); //Raises Exception java.lang.IllegalStateException: Cannot commit transaction: last operation has not committed"
s.sqlContext().sql("select count(*) from nessie." + tblName).show();
thanks for all your help,
best regards,
Vikram
Ajantha Bhat
Aug 1, 2022, 7:42:19 AM8/1/22
to Vikram Roopchand, projectnessie
I think there is no need to open a transaction.
Try like below,
more info:
https://github.com/apache/iceberg/blob/master/hive-metastore/src/test/java/org/apache/iceberg/hive/HiveTableTest.java#L525
Try like below,
table.newAppend().appendFile(file).commit();
more info:
https://github.com/apache/iceberg/blob/master/hive-metastore/src/test/java/org/apache/iceberg/hive/HiveTableTest.java#L525
Vikram Roopchand
Aug 1, 2022, 8:51:54 AM8/1/22
to Ajantha Bhat, projectnessie
Dear Ajantha,
I did this. But the data did not get appended. Let me try again tonight. I checked the metadata files also, no entry was in them either.
Best regards,
Vikram
Vikram Roopchand
Aug 2, 2022, 3:28:26 AM8/2/22
to Ajantha Bhat, projectnessie
Dear Ajantha,
I tried this,
AppendFiles files = t.newAppend();
String fileLocation = "hdfs://voyager:9000/DI/warehouse/" + tblName;
int numRecords = writeDummyData("temp_" + tblName);
DataFile file = DataFiles.builder(t.spec())
.withRecordCount(numRecords)
.withPath(fileLocation)
.withFormat(FileFormat.PARQUET)
.withFileSizeInBytes(Files.localInput(fileLocation).getLength())
.build();
//#1 approach , did not work, select count(*) did not show numRecords
files.appendFile(file).commit();Followed by a select count(*) ,
s.sqlContext().sql("select count(*) from nessie." + tblName).show();
However, it did not update the count to expected record count. The nessie catalog however does show an "append" commit , but we really cant see any records. Do you have a working standalone sample I can run here ?
best regards,
Vikram
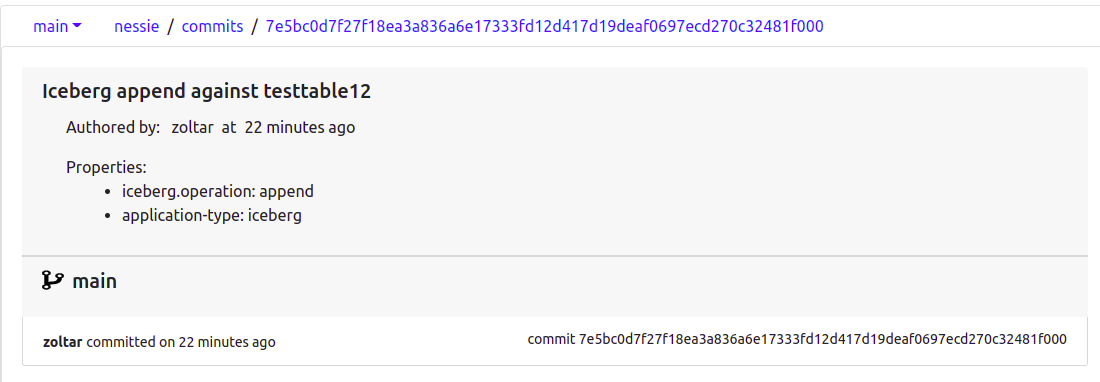{kind=link}
Ajantha Bhat
Aug 2, 2022, 4:43:47 AM8/2/22
to Vikram Roopchand, projectnessie
Was the same thing working with other Catalogs? (like HiveCatalog?)
I am suspecting some configuration problem.
I would manually debug and check whether the append files are added to the metadata properly or not (verifying the path)
I am suspecting some configuration problem.
I would manually debug and check whether the append files are added to the metadata properly or not (verifying the path)
Vikram Roopchand
Aug 2, 2022, 7:04:10 AM8/2/22
to Ajantha Bhat, projectnessie
Dear Ajantha,
I did not use other catalogs. I checked the metadata and I could not see these files there. I managed to do the same thing in another way though, I used the source_ds_via_parquet.writeTo(iceberg_ds).append() .. this was similar to a "broad level commit" and I also managed to get it to work using the "add_file" procedure. Both give similar results with the exception of a data copy. Now we have to choose the right way to go ...
Thanks a lot for all your help, you were magnificent :) ...
best regards,
Vikram
Reply all
Reply to author
Forward
0 new messages