Algorithm for environmental puzzles? (Doors and switches etc.)

Rune Skovbo Johansen
I've been trying to come up with an algorithm for creating puzzles with doors and switches (or similar environmental puzzles) but haven't been able to find a solution.
The image at the bottom shows examples of the kind of puzzles I'm interested in. (The 3 puzzles in the image follows the same pattern I came up with that can be expanded to any number of doors, but it doesn't generalize to more varied puzzles.)
Doors and switches are just examples of elements; there could also be boulders and pressure plates and various other puzzle elements. I'm looking for something rather game-agnostic though that can be represented as a graph or similar. E.g. Sokoban puzzles are a bit too specific, in how they only work as top-down grid-based games.
Simple "locked doors and keys" structures as described on squidi.net are easy enough to do but they don't really work as proper puzzles. They can be solved by just repeatedly looking for keys to collect and doors to unlock; you don't have to give it any thought. I'm also not sure how grammar-based approaches could be used to create proper puzzles.
It seems like something that could be broadly useful - this type of puzzles are used in many different games. It also seems like a task that procedural generation should be able to handle fine, but after reading lots of papers on procedural level design and other procedural elements, I still haven't found anything that fits the bill.
This is for runtime generation by the way. I read that answer set programming can do almost anything (explored a bit here) but that it's still too slow (and memory-hungry) to generate stuff on the fly.
Do any of you have any ideas for how to approach this?

Thanks,
Rune
(Question also posted to reddit)

Ian Badcoe
...and you can expand that with a lot of key-like/door-like generalisations.
However I am not sure that a "puzzle" is quite the same thing as a dungeon. The only thought I have had about puzzle generation was originally about "burr" puzzles, (I have seen a write-up somewhere on automatic burr-puzzle design; search for "burr puzzle automatic generation") but the same idea generalises to sokoban etc. For that I was thinking an evolutionary or tree-search approach, where the utility function is the number of moves in a successful solution. It wouldn't be quick, because it would need a nested tree-search to solve each candidate, but as long as you were looking at puzzles with small number of components it could work...
...BUT not in a run-time manner such as you asked for. Actually I can't tell exactly what you want to generate from this. You say you want "puzzles" but then give examples that you say are insufficiently "puzzling" because they can be solved by picking up any key and opening any door. Can you give an example of what would be a satisfactory puzzle so that I can tell what approach might achieve it. Rewrite rules can do a lot with the right formulation... e.g. they can do the things in your picture.
Increased puzzlingness could be achieved e.g. by multiple one-use keys of the same type, so that you have to open the doors in the right order, but it is probably still not very satisfying...
Ian
Ian
From: Rune Skovbo Johansen <ru...@runevision.com>
To: procedur...@googlegroups.com
Sent: Sunday, 5 January 2014, 13:48
Subject: [pcg] Algorithm for environmental puzzles? (Doors and switches etc.)
---
You received this message because you are subscribed to the Google Groups "Procedural Content Generation" group.
To unsubscribe from this group and stop receiving emails from it, send an email to proceduralcont...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.

Adam Smith
Rune Skovbo Johansen

Julian Togelius
puzzle, but I think it risks encompassing a bit too much. To begin
with, almost any labyrinth or maze with a reasonable branching factor
would be a satisfying puzzle according to this definition, as there
are many non-trivial dead ends in state space, namely the dead ends in
the maze. Maybe you are looking for problems where dead ends in action
space outnumber dead ends in physical space? This implies that it is
not enough to get to the right place, but you also need to get to the
right place in the right sequence.
Given that you have a function for measuring the puzzle-ness of a
problem/environment/level, you could easily adopt a search-based
approach. (Of course, you all knew I was going to say this...) Simply
use your puzzle-ness function as an evaluation function. ASP might be
better for this problem, but I'm pretty sure evolution would work as
well, and whatever works works.
>
> ---
> You received this message because you are subscribed to the Google Groups
> "Procedural Content Generation" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to proceduralcont...@googlegroups.com.
> For more options, visit https://groups.google.com/groups/opt_out.
--
Associate Professor
IT University of Copenhagen
Rued Langgaards Vej 7, 2300 Copenhagen, Denmark
mail: jul...@togelius.com, web: http://julian.togelius.com
mobile: +46-705-192088, office: +45-7218-5277
Rune Skovbo Johansen
That's an interesting definition of what makes something feel like a
puzzle, but I think it risks encompassing a bit too much. To begin
with, almost any labyrinth or maze with a reasonable branching factor
would be a satisfying puzzle according to this definition, as there
are many non-trivial dead ends in state space, namely the dead ends in
the maze.
Maybe you are looking for problems where dead ends in action
space outnumber dead ends in physical space? This implies that it is
not enough to get to the right place, but you also need to get to the
right place in the right sequence.
Given that you have a function for measuring the puzzle-ness of a
problem/environment/level, you could easily adopt a search-based
approach. (Of course, you all knew I was going to say this...) Simply
use your puzzle-ness function as an evaluation function. ASP might be
better for this problem, but I'm pretty sure evolution would work as
well, and whatever works works.
Adam Smith

--
Rune Skovbo Johansen
---
You received this message because you are subscribed to a topic in the Google Groups "Procedural Content Generation" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/proceduralcontent/bFTkuSv2EUE/unsubscribe.
To unsubscribe from this group and all of its topics, send an email to proceduralcont...@googlegroups.com.

Cameron Browne
Rune Skovbo Johansen
They mention that their "virtual player" can look three steps forward, but I can only make sense out of that if it's combined with some heuristic of how close a given state is to the goal state. More difficult puzzles would then perhaps be puzzles that require going though low-scoring states - similar to a maze where the solution path requires going in the direction away from the goal. If that's a correct interpretation of their method, then I'm curious what their state scoring heuristic is and whether it's underlying principle can be transferred to other types of puzzles.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bedrich Benes
Bedrich Benes
Associate Professor of Computer Graphics Technology
Purdue University
Rune Skovbo Johansen
I'm digging up this old thread just to mention that the PuzzleGraph tool that I mentioned I had begun working on is now released, free and open source.
Article: http://www.gamasutra.com/blogs/RuneSkovboJohansen/20160406/269732/Working_with_puzzle_design_through_state_space_visualization.php
Video: https://youtu.be/NeTjbfAbNyA
Tool itself: https://runevision.itch.io/puzzlegraph
Source code: https://bitbucket.org/runevision/puzzlegraph
It's not procedural generation as such, but as discussed in this thread, might be an interesting foundation to build procedural puzzle generation on top of, though I didn't get far with that myself so far.
Rune
Ian Badcoe
Sent: Thursday, April 7, 2016 11:04 PM
Subject: Re: [pcg] Algorithm for environmental puzzles? (Doors and switches etc.)
I'm digging up this old thread just to mention that the PuzzleGraph tool that I mentioned I had begun working on is now released, free and open source.
Article: http://www.gamasutra.com/blogs/RuneSkovboJohansen/20160406/269732/Working_with_puzzle_design_through_state_space_visualization.php
Video: https://youtu.be/NeTjbfAbNyA
Tool itself: https://runevision.itch.io/puzzlegraph
Source code: https://bitbucket.org/runevision/puzzlegraph
It's not procedural generation as such, but as discussed in this thread, might be an interesting foundation to build procedural puzzle generation on top of, though I didn't get far with that myself so far.
Rune
On Friday, January 17, 2014 at 6:49:01 PM UTC+1, Rune Skovbo Johansen wrote:
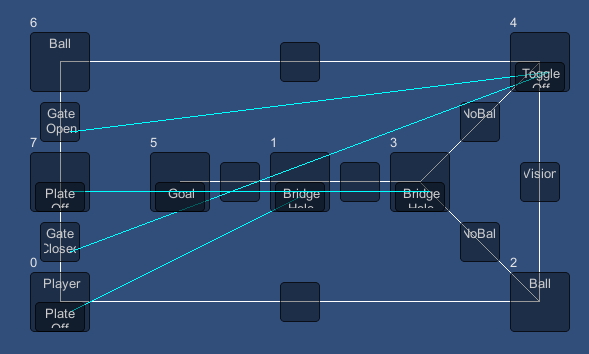
The good thing about this definition for a "good" puzzle is that it's very general and could be applied to a very large variety of puzzles. If the number and lengths of dead ends can be controlled, it would also be easy to control the difficulty that way, by specifying more difficult puzzles as having more dead ends, and longer solution path(s) and dead ends. I don't know enough about ASP to know if it's a viable kind of criteria to use there but I'm guessing it probably is.I also analyzed the middle puzzles from the image in my first post in this thread, and found that it peculiarly had one long solution and only one long dead end. Basically, if you happened to make the right move from the beginning you'd go down a route to the solution more or less automatically, while if you made the wrong move from the beginning, you'd go down the route of a dead end. That makes for an peculiar kind of hit-and miss puzzle experience that's probably not very desirable.The theory I'm working with is that a puzzle feels like an actual satisfying puzzle if there are multiple non-trivial dead ends in the state space, where non-trivial means they are longer than a few state changes long. I tried to model a puzzle in the framework over a puzzle from the game Lara Croft and the Guardian of Light (graph pictured in the attached image) and when I analyzed it, I found that the solution path was rather long and there were at least a handful long dead ends. In contrast, a "key and door" binary tree as described on squidi.net always have no non-trivial dead ends regardless of the number of doors and keys. It's basically just one long solution path.Now, with this state space graph available it's possible to find the shortest solution path and other things. By doing a depth first search and marking states as dead ends if they either lead to no other states or back to already explored states, we can get an overview over how long the shortest solution path is; if there's more than one solution, and how many dead ends there are, and how long they are (= how many state changes they involve). I design the puzzle graphs such that there are preferably not two nodes that are trivially connected with an always accessible edge - such two nodes can just as well be collapsed to a single one. This helps pruning "filler" state changes form the state space which don't add any real complexity anyway.As for how to define the problem, I'm beginning to gain an understanding of what probably makes a puzzle feel like a puzzle. I'm working on a Puzzle Graph framework and tool to define environmental puzzles in the form of graphs with different types of nodes and edges. An edge could be a locked gate and some node could be a pressure plate that opens the gate if you roll a boulder onto it, and things like that. The state of the graph and changes to the state are defined in a strict way that makes it possible to search the state space for the graph. The state space is a graph in itself - often much larger than the graph of the puzzle itself.Hi Adam,Thanks for the reply. I've been meaning to give the Potassco project tools a try when I get some time for it; if nothing else then to learn about procedural generation from another angle than I'm used to. I've heard independently from several people that ASP programming is too slow and memory intensive for runtime generation, but of course the specifics depend on the problem at hand. But that said, I need a solution that works in C# for my own purposes, and you said on twitter back in June that "Most ASP solvers are in C++, so you'd have to try Google's PNaCl or Emscriptem to get them into a browser-based game." - which is not really an option for me, since I'm using Unity and need a pure C# solution.
The Puzzle Graph framework and tool is still a work in progress, but the plan is to make it freely available once it's in a usable state.Rune
On 17 January 2014 01:38, Adam Smith wrote:
Hi Rune,You should look at the gem-and-altar example from this PCG textbook chapter on ASP: http://pcgbook.com/wp- content/uploads/2013/10/ chapter8.pdf The mechanics for gems and altars (that you have to pick up the gem and put it in the altar before you can use the exit tile) aren't exactly the same as locks and keys (where bringing the lock to the key toggles traversability of the lock itself), but the difference is minor.
The important thing to get from the example comes near the end. What makes a puzzle design appropriate in that example is not just that it is solvable, but that enacting a solution implies certain unavoidable properties across all possible solutions. In the example, the property is spending a minimum amount of time/distance between each step in solving the level (finding the gem, bringing it to the altar, finding the exit). This is just an example property, and any efficiently checkable property of a solution path could replace it.There's no new algorithm, but to customize the example to a new domain you need to:- define a set of constraints on valid level designs (for your example: just that they have n locks and n keys over a discrete set of rooms)- define a space of solutions for a given level design (for your example: that the solution describes a start-to-finish traversal of the map that touches locks and keys in a valid order, keys before locks)- define a property of solutions that you want to require (for your example: that half of the rooms are touched at least once and that a quarter are touched two or more times? that the locks were opened in an order coherent with a story? that the solution path draws a certain kind of picture on a mini-map?)From there, you've (implicitly) defined a combinatorial search problem in Sigma_2^P, and any algorithm for that class of problem is available as your content generation algorithm. Different answer set solvers use different algorithms, so they'll run in different amounts of time and use different amounts of memory. Saying ASP is too memory hungry is like saying functional programming is too memory hungry; statements at the level of programming paradigms (as opposed to specific programs in specific languages with specific runtimes) don't make sense.
If you prefer to roll your own generator for this type of problem formulation, an easy way is to glue together two simpler search algorithms that work like independent constraint solvers. I'll follow the naming convention from this paper: https://adamsmith.as/ papers/fdg2013_shortcuts.pdf First, find some algorithm to play the role of Elise, the level designer. You could use a SAT solving algorithm like DPLL or a Feasible-Infeasible constraint solving genetic algorithm. To play the role of Fiona, the design assistant, you could use plain old A* to search for solutions (depending on what solution property you are trying to required). Plug these together in a generate-and-test process, and you've got yourself a (possibly approximate) solver for anything in the relevant class of problems. If something is to slow... precomputation, caching, sampling, and learning are possible roads to investigate next.
If you take anything specific away from this email, it should be to focus on how to define your problem (as opposed to how to design an algorithm). While you can heuristically judge the quality of a project-specific content generation algorithm by eyeballing example outputs, this approach doesn't work when trying to develop generic tools (where a quirky stylistic bias of an algorithm in one game might mean a pace-ruining bias in another game).Adam
---
You received this message because you are subscribed to the Google Groups "Procedural Content Generation" group.
To unsubscribe from this group and stop receiving emails from it, send an email to proceduralcont...@googlegroups.com.
For more options, visit