degraded performance: 2021-04-27 800-2100 UTC
72 views
Skip to first unread message

pre.commit.ci
Apr 27, 2021, 5:22:07 PM4/27/21
to pre-commit ci
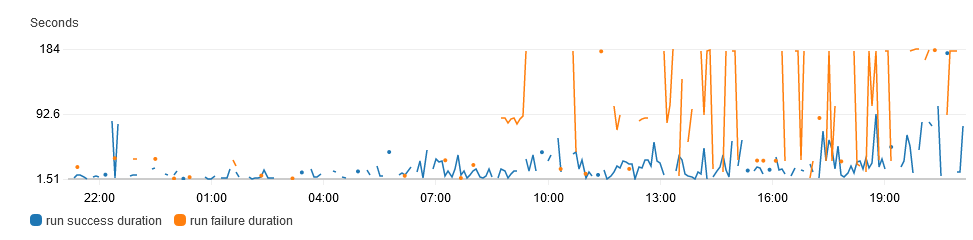
during this period there was degraded performance for pre-commit.ci runs
it is suspected there was a noisy neighbor for one or more of the aws instances as rotating hosts has seemingly fixed the issue (and there were no code changes during that period)
to re-trigger a failed pull request run, comment "pre-commit.ci run" or "pre-commit.ci autofix"
I'll be following up in a few hours with a postmortem once I'm sure this is resolved
for more information see: https://github.com/pre-commit-ci/issues/issues/62
Anthony
pre.commit.ci
Apr 27, 2021, 7:56:40 PM4/27/21
to pre-commit ci
marking this all clear, run times have returned to normal after mitigation
postmortem
root cause
unknown
- no code changes occurred before or after the incident or to mitigate the incident
- observable host level metrics (cpu / io) were not elevated on any of the affected hosts
what went well
- run-level metrics were extremely helpful for identifying the affected timeframe and validating the fix
- host rotation was quick and easy (already scripted)
- helpful issue created by @matthewfeickert alerting to the problem
what didn't go well
- detection: slow and entirely manual
- prevention: unknown what caused the actual root issue
follow-up
- detection: add automated alerting for elevated timing
- prevention: investigate larger ec2 instance sizes for performance and to lessen "noisy neighbor" effects
Anthony
Reply all
Reply to author
Forward
0 new messages