RESTful API Live Discussion Summary
9 views
Skip to first unread message

David Days
Jul 8, 2016, 11:51:21 PM7/8/16
to plots-dev, plots-gsoc
Greetings, all!
I wanted to put up a quick run down of the Live Discussion that we had today, where I presented a mix of design considerations, code walk-through, and live demo of the RESTful API, new typeahead functionality, and the web-service-based search system.
(Some of this has been discussed before in other posts, and some is new to this particular discussion. So if you feel your eyes glazing over halfway through...my apologies. :-) )
I started the discussion with a little bit of conceptual background in regards to search functionality and RESTful services. We also went over some of the "gotchas" that go along with developing web services, and how we could mitigate those problems.
Documentation
The first part of the discussion was introducing the grape-swagger documentation system. One issue with developing web services is two-fold: documentation of what APIs are running, and "Where the heck did my endpoint go?" The first part is normal for any API development in just about any language. You write code for a web service or a library, and you end up commenting or documenting it somewhere else. Eventually, changes pile up in the actual web services that aren't written in the documentation, so you end up with an API guide that is out of date and a pain to correct.
At the same time, it is often difficult to even figure out if you have set up your API correctly--is it not working, or am I putting the wrong URL in. In Ruby and ruby-grape, especially, there are tons of configurable options, and quite a few of them will drastically alter the URL needed to access the web service. This can slow down development quite a bit, and turns a lot of people off of web service development altogether. (My experience with heavy development includes WCF, node.js, and Java--they all have the same issue.)
Enter grape-swagger. This little "gem" (pun intended) parses the grape web service implementations at runtime and produces a specifically-formatted JSON return that documents all the running endpoints. Below is a screenshot:

This is set up to respond if you go to "/api/swagger_doc.json". By including this, developers can get a quick look at the available endpoints, see the parameters required or optional, and immediately start testing out calls to the API system. If we keep the code documentation up as we develop, it will help future developers figure out how to use the services provided.
Typeahead & Search
If you look at the "paths" node of the swagger_doc.json screenshot, you will see that there are two basic types of endpoints that have been implemented: typeahead and "srch" (The word "search" has already been claimed throughout the plots2 code, so for namespace management and to distinguish between "regular" search capabilities and RESTful search, we went with the shortened "srch" or "Srch" for all RESTful-oriented code and URLs.).
Currently, typeahead is used to perform a general search of the system, returning the most likely matches to what a user is currently entering into an input field. This functionality is replicated by calls to the endpoint "/api/typeahead/all". However, it's conceivable that many people will want to look for specific subsets of information: Only profiles, or only questions, or only tag values. To support that, it was very easy to replicate the "all" function and only return area-specific typeahead information. So if someone is looking to add tags as part of the Rich Editor project (@jeff and I discussed this during the call), there is already a RESTful service at "/api/typeahead/tags" which will suggest matching tags as users type, leaving out non-tag suggestions.
The javascript to use this is actually already written and will go into the main fork once testing is complete. The code comments in /assets/javascript/restful_typeahead.js explain how to get area-specific typeahead information.
The other type of RESTful endpoint that we created was a set of search endpoints. Again, we replicated the general search with the "all" operation, but also added area-specific ways to query the system. So, as with typeahead, if you want to just perform a search of the questions (especially with the new Q&A system under development), you can call "/api/srch/questions" with the appropriate parameters and get what you need. To demonstrate some of this, we created a new page for the SearchesController, called "dynamic". This is basically a mini-Google page, where the user begins typing in search terms, and the page live-updates as they go along. (Screenshot below):

Unlike the general typeahead, though, the actual search page is updated every time the user does one of the following: Hit a "space", hit "Enter", or click the search button. So if someone is typing a long set of terms, the results will update as they go, possible giving them quick feedback on how effective their search is going to be.
Another change is that the "tags" function can now operate differently: The search terms entered are "converted" so that matching tags and associated documents are display. (Screenshot below). This means that if you enter, for example, "plots2 riffle spectrometry", you will get a list of documents that are tagged by "plots2" and any that are tagged by "riffle" and any that are tagged by "spectrometry". Between the typeahead suggest above and the tagging-specific search, it's possible for new and experienced users to quickly zero in on the set of documents that they are looking for.
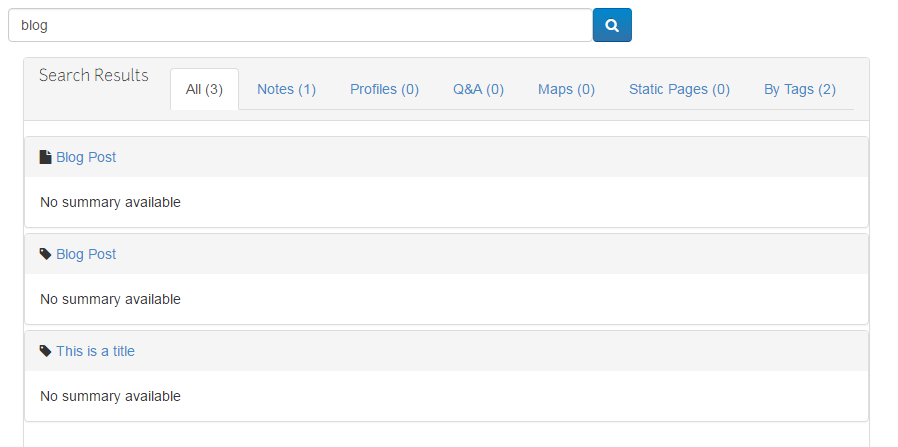
Another thing to note is that, also the dynamic search page is performing a general search against "all", the javascript is separating the results into the various types of result. So enter a search term but are not sure of where the result lives (or the type of document you are actually looking for), then this will help point the way.
Internal Usage
Another requirement is that, as best possible, the search capabilities should be internally useful (within Ruby code) as well as externally. We believe we've achieved this through several steps: First, all of the actual search functionality (both typeahead and general search calls) are implemented in the /app/services/typeahead_service.rb and /app/services/search_service.rb code. The methods all return the same objects (lists of documents and lists of tag objects), and the RESTful endpoint merely does some book keeping and translation.
The next part that supports this is that, to make a class "RESTful", you just add a specific subclass to it, with a few settings on what values can go out over the wire. This means that any internal Ruby class definition can be used as part of a RESTful endpoint operation, and any RESTful object can also be used completely within Controllers and Views, as necessary. This will allow a lot of flexibility within the development system.
Summary (of the summary)
With some additional testing, the Advanced search team believes that this is ready for a Pull Request in the near future. This will get the basic system in the hands of the users and the Public Lab admins, who can then give feedback and direction on additional capabilities. For example, Ujitha has implemented a search logging system that we are planning on turning into an improved (or additional) type of typeahead suggest; this would allow the users to see the top 5 (for example) most recent popular searches that match their entry. It will also give the admins a good idea of what kind of subjects are receiving more scrutiny of late. Overall, we think this will help the community.
With all of this, however, our work is only halfway finished. The RESTful API brings a lot of popularity, but the underlying search system is actually just a reuse of the old search calls (for the most part). Our stated goal for the project includes improved search performance--getting better answers out faster. Now that the front end of the data pipeline is set up, we are going to turn our attention to improving the back end efficiency. We're also going to be working closely with the Public Lab admins and the other projects, in order to make sure that we supply their search requirements, as well as reduce code redundancy.
That about covers it. The code is at https://github.com/david-days/plots2, and people are welcome to browse, view, and comment as necessary.
Reply all
Reply to author
Forward
0 new messages