
David Collins
I read somewhere in another post that I should be using a StreamingPartRetriever. Perhaps that would resolve the issue with larger PDFs.
Beyond that, I also have the requirement to work with annotations, so I believe I need to be using the ReaderControl (?)
Is there an example of how to use the StreamingPartRetriever with the ReaderControl, or could you provide some sample code?
Thanks in advance,
David Collins
Matt Parizeau
David Collins
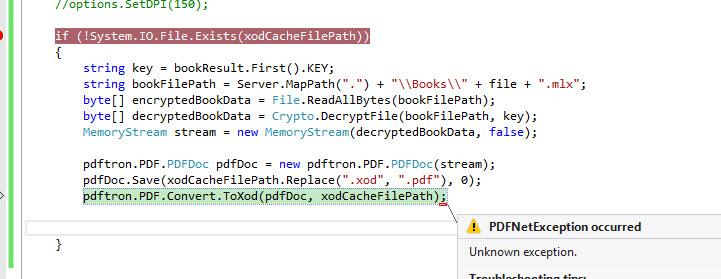{kind=link}
{kind=link}
Matt Parizeau
Support
http://www.pdftron.com/ID-f94ls2-edm0aqZ/PDFNetDotNet4.zip
http://www.pdftron.com/ID-f94ls2-edm0aqZ/PDFNet64DotNet4.zip
http://www.pdftron.com/ID-f94ls2-edm0aqZ/PDFNetC.zip
http://www.pdftron.com/ID-f94ls2-edm0aqZ/PDFNetC64.zip
Support
Support
Support
Although streaming seems attractive on first look it could put a heavy burden on servers (e.g. if there are many users viewing docs at the same time). A more efficient alternative is to cache converted XOD files. You can either do either a full mirror of the entire library or partial cache (e.g. storing last 1000 files or something like that).
This will remove the strain from the server and will also improve viewing experience (better performance, instant access to random pages etc.).