OSL and OIIO optimization for non Arnold renderer
254 views
Skip to first unread message

Changsoo Eun
Apr 4, 2020, 5:46:18 PM4/4/20
to OSL Developers
This is a post from Vlado from VRay.
"My results are like this:Scanline renderer, multithreading OFF, Standard material:
OSL Bitmap - 1m 14s; Bitmap - 37s; VRayHDRI - 37s
V-Ray, fixed sampling 2 subdivs, no GI, VRayMtl material:
OSL Bitmap - 43s, Bitmap - 33s, VRayHDRI - 31sThe scanline renderer has very poor CPU utilization with multithreading for simple scenes, so I turned multithreading OFF in order to get more accurate comparisons. The V-Ray render was multithreaded as usual. Rendered at 7680x4320 on an i7-6820HQ (8 logical cores) and 3ds Max 2021. Each version was rendered 3 times and the result was averaged."
And,, this...
"The OSL library and the OpenImageIO library each add some overhead; having seen the code for both, there is certainly room for improvement, if someone wants to do it. A certain downside is that the code is a bit complicated and changes are somewhat difficult to introduce."
I tested with Arnold. But, Arnold seems show less problem.
If OSL to be the "standard" of shader, I think this need to be improved.
Even considering the benefit of compatibility, the taxing on the render time is too much for ordinary users.

Larry Gritz
Apr 4, 2020, 6:48:43 PM4/4/20
to OSL Developers List
If Arnold shows less of a problem ( what does that mean? a smaller factor difference between using OSL+OIIO texture versus just a straight bitmap in memory?), then doesn't that strongly indicate that there might be something particularly sub-optimal with the way VRay is setting up and calling its OSL and OIIO usage? Because if it were strictly that the oiio texture system was just horribly slow, you would expect that to show up roughly equally in all renderers.
You also need to remember an important design choice of the OIIO texture system: it was not designed to be super fast on small benchmark tests, or even full scenes that "ordinary users" will construct. It was designed to make it *possible* to render the biggest scenes that the big VFX studios have to render for their most complex films. For example, handling a scene that references 1.5 TB of texture, but loading tiles only if and when needed and keeping the in-core memory footprint to less than 4GB so that the rest of memory can be completely filled with the geometry of an enormous scene.
What does it mean when you say "OSL bitmap" versus "bitmap"? Are they really trying to do the same thing? Or is one doing simple sampling on an image that is preloaded in memory as one block, and the other is doing demand loading of texture and a more costly (but higher quality) bicubic filtering with an anisotropic filter region? Is the OIIO case preparing the texture file (via maketx, so it's tiled and mipmapped) the way it is meant to be optimal? Or is it using a "flat" untiled/unmipped file, that by design works basically, but is known to be slow because that's not the way it was designed to be used?
If we can better establish exactly what this test is and that you are truly comparing to "apples to apples", and show that there is a specific case in which it's not as fast as the *equivalent* operation, then I'm definitely interested in chasing that down and improving it.
But usually when people make that complaint, it turns out upon investigation that they were not equivalent tests after all. I would love to be shown wrong so that I can fix it.
-- lg
Changsoo Eun
Apr 4, 2020, 9:08:11 PM4/4/20
to OSL Developers
VRay and Scanline renderer both using OSL via 3dsMax shader API.
Arnold does own magic. It only took OSL code and do own thing.
So, I assume there is another overhead in 3dsMax, too.
I accept the fact that there would be some overhead.
All I want is reduce that overhead as much as possible.
It is good to know that OIIO is more gear toward to memory savings
Then, it might be a good trade off that user can choose.
Next time I'll next the memory usage,too
I'll run more realistic test and report here.
"OSL bitmap" means the OSL shader in 3dsMax that just wrapper of texture() function.
"Bitmap" is 3dsMax native C++ shader for loading texture.
All test is done with "flat" untiled/unmipped file.
I was thinking about this and will test .tx file, too.
It might be just this.
The test was simple, we only used one 4K maps as diffuse(base) map on a few objects which filled entire scene and rendered as 7680x4320.
So, essentially there is nothing going on other than loading a texture and render full screen image.
So, essentially there is nothing going on other than loading a texture and render full screen image.
Larry Gritz
Apr 4, 2020, 9:33:34 PM4/4/20
to OSL Developers List
There are many possibilities for explanation and improvement here. You are seeing about a 2x difference (1:14 vs 0:37) on what I assume is a small concentrated test that tries to isolate texture performance for this one case. (Remember that in a "real" render with lots of geometry, I/O, and complex shaders and materials, the raw timing of texture is only a portion of render time.)
First of all, I can't tell if the times you are quoting are inclusive or exclusive of overheads such as compile/JIT of the OSL shader itself (which the built-in bitmap "shader" does not need to do), or of the I/O of the texture file (the OSL/OIIO one is reading texture in the middle of the render "on demand"; is it possible that the Max native one has pre-loaded the textures and hidden the I/O time before the render even starts?).
I definitely expect a fairly large overhead if you are directly using an untiled/unmipped texture, because OIIO's TextureSystem is very much designed around the use of tiled mip-mapped textures, and it when it the files have not been prepared that way, it does some awkward emulation of tiling/mipmapping. That can be expensive (maybe accounting for much of the 2x?). There are some parameters that control the way this is done, and it's possible that Max is not setting them in an optimal way.
I'm not super familiar with Max, to be honest. Is its native bitmap shader doing things at a lower quality level? Like, maybe it's just a simple trilinear mipmap, and so of course OIIO's default of anisotropic with a potentially bicubic filter is just doing more math and will be more expensive. Maybe what Max needs is a setting on the OSL bitmap shader that is "use the faster and lower quality settings" for users who don't need all the bells and whistles?
Does Zap want to comment on any of this? Maybe he knows what the settings are or exactly what the native Max bitmap texturing is doing underneath.
Changsoo, you can look at the memory, but you aren't going to see a difference with one or a few textures. You will mainly see a difference when you are using so much texture in the scene that they can't possibly all fit in memory. I'm not sure what Max does in that circumstance, but OIIO won't even blink or slow down. If you ask the average lookdev or lighting artist in my studio how much texture is used in a typical scene they render, I bet they can't even tell you. They probably can't even guess within a factor of 10. Because it DOESN'T MATTER to them. There is no such thing as too much texture.
Is there an option for you to print the full OSL and OIIO statistics output that you can show us? If I see those numbers, I will know how some of the options are affecting the performance and can make suggestions for how to speed it up.
-- lg
--
You received this message because you are subscribed to the Google Groups "OSL Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to osl-dev+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/osl-dev/dc047245-aac8-49a8-b840-6cea28ea41ee%40googlegroups.com.
Changsoo Eun
Apr 4, 2020, 10:38:31 PM4/4/20
to OSL Developers
I'm sure Zap will give you some answer.
I think he is enjoying his weekend after all those crazy delivery.
I have a few scenes that were go beyond 128G ram. so, I think I can check with that kinds of scenes.
OIIO statistics output sounds interesting.
That I'll definitely ask Zap if we can output.
The ultimate goal for me is make more users to use OSL.
Often if users find out any "regression"(his case render time) in new stuff.
They simply choose to ignore the entire features.
If there is trade off as you say or expected workflow to utilize OSL 100%.
I need to know and have numbers to tell users what is pros and cons.
To unsubscribe from this group and stop receiving emails from it, send an email to osl...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/osl-dev/dc047245-aac8-49a8-b840-6cea28ea41ee%40googlegroups.com.
Larry Gritz
Apr 5, 2020, 12:43:32 AM4/5/20
to OSL Developers List
I'm definitely interested in sorting out what's going on. I bet some parameter adjustment can get us much of the way there, and if there are still substantial differences I certainly want to take a look.
-- lg
To unsubscribe from this group and stop receiving emails from it, send an email to osl-dev+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/osl-dev/d3593d8c-a0d5-49ae-a15e-eba1fed9691c%40googlegroups.com.

Master Zap
Apr 5, 2020, 10:44:47 AM4/5/20
to OSL Developers
Changsoo,
Not only was Zap enjoying his weekend, he was asleep.
Now, the test being set up is pretty unfair the way it is made.
Scanline renderer calling a max legacy Bitmap is almost - but not quite - as simple as a function call that looks up a single in-memory piece of data. It's not that simple (there's some trilinear-ish sampling - that max calls "Pyramid" - going on), but that's roughly it.
Calling OSL bitmap from scanline, means that a scanline "ShadeContext" class has to be rearranged into a an OSL "ShaderGlobal" class. There's not a giant amount of work, but its' also non-zero.
Then, OSL bitmap calls OIIO which, as Larry correctly pointed out, gives you - through a clever layer of demand loading cache magic - a beufitul bicubically interpolated pixel. Which is definitely also more work.
I'm guessing the reason it's closer in Arnold is probably because Arnold is doing the Arnold OSL thing (not using the OSL in max itself), which is probably fairly optimal (since the shading language was written with (SPI version of) Arnold in mind originally). It probably has little to nothing to do to re-juggle the Arnold "AtShaderGlobals" into OSL "ShaderGlobals" (which the name alone would suggest). Or maybe Arnold is using a different filtering as a default - I actually don't know....
Then, OSL bitmap calls OIIO which, as Larry correctly pointed out, gives you - through a clever layer of demand loading cache magic - a beufitul bicubically interpolated pixel. Which is definitely also more work.
I'm guessing the reason it's closer in Arnold is probably because Arnold is doing the Arnold OSL thing (not using the OSL in max itself), which is probably fairly optimal (since the shading language was written with (SPI version of) Arnold in mind originally). It probably has little to nothing to do to re-juggle the Arnold "AtShaderGlobals" into OSL "ShaderGlobals" (which the name alone would suggest). Or maybe Arnold is using a different filtering as a default - I actually don't know....
Here's a test I would suggest you do that is fairer. Since the overhead I mention above is to "enter the world of OSL", and happens only once for an entire shade tree, you can try something like this:
Take two max Bitmap, and put them through, say, an RGB Multiply. Copy this entire shade tree, and take the output of both into another multiply, giving you the multiplied value of all four textures.
Take two max Bitmap, and put them through, say, an RGB Multiply. Copy this entire shade tree, and take the output of both into another multiply, giving you the multiplied value of all four textures.
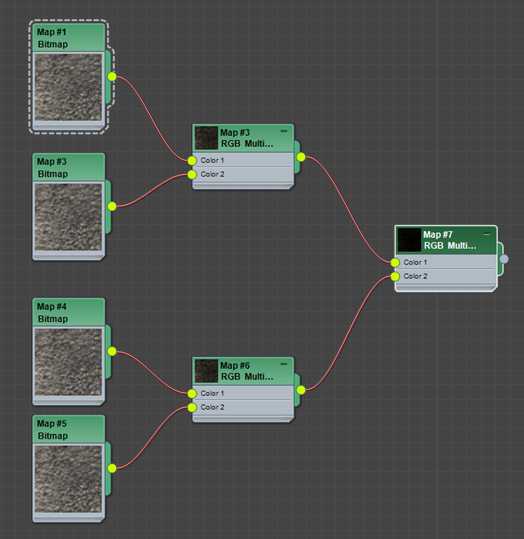
Right-click the rightmost node, and use "Render Map". Set some high resolution so you can get some good timings. Measure this time.
Now set up the equivalent OSL tree doing the same thing. Compare the timings.
Also, you can edit the OSL texture shader and change the texture lookup line so it reads:
Now set up the equivalent OSL tree doing the same thing. Compare the timings.
Also, you can edit the OSL texture shader and change the texture lookup line so it reads:
Col = texture(Filename, ulookup, vlookup, "wrap", WrapMode, "alpha", A, "interp", "linear");
This will test without the default bicubic filtering.
The idea with max's OSL support is that if your renderer supports OSL, use your renderers OSL (like Arnold is doing), which may potentially allow some kind of magical optimizations.
The OSL that can any renderer can execute via EvalColor using the classic C++ shader API also works fine - but the small-but-nonzero overhead to turn a ShadeContext into ShaderGlobals will be there. But that overhead is only once for an entire shade tree (if the whole tree is OSL). In practice, for any real world scene's real world shading, it's quite negligeble.
/Z
This will test without the default bicubic filtering.
The idea with max's OSL support is that if your renderer supports OSL, use your renderers OSL (like Arnold is doing), which may potentially allow some kind of magical optimizations.
The OSL that can any renderer can execute via EvalColor using the classic C++ shader API also works fine - but the small-but-nonzero overhead to turn a ShadeContext into ShaderGlobals will be there. But that overhead is only once for an entire shade tree (if the whole tree is OSL). In practice, for any real world scene's real world shading, it's quite negligeble.
/Z
-- lg
To view this discussion on the web visit https://groups.google.com/d/msgid/osl-dev/d3593d8c-a0d5-49ae-a15e-eba1fed9691c%40googlegroups.com.
Changsoo Eun
Apr 5, 2020, 2:25:24 PM4/5/20
to OSL Developers
Hehe.. I hope I didn't wake you up.
1) I was wondering if we can control the interpolation.
I'll test if it can make things faster.
BTW, I think you should expose the option to UI.
2) Going through other map is valid point since often I see a big shader tree.
I'll test that.
Master Zap
Apr 5, 2020, 2:53:14 PM4/5/20
to OSL Developers
Actually here's a trick you can try to make a fairer comparision:
Plug the legacy bitmap through an OSL "Color Value" map. This will add the (small - but nonzero) OSL overhead to the legacy bitmap also. Then you will be measuring more accurately the difference between OIIO lookupgs and Bitmap lookups.
But still, trying to get OIIO to be *faster* than a raw simple flat-memory read will be preeeetty difficult. But as Larry so clearly explains, that's also not it's purpouse.
But still, trying to get OIIO to be *faster* than a raw simple flat-memory read will be preeeetty difficult. But as Larry so clearly explains, that's also not it's purpouse.
/Z
Changsoo Eun
Apr 5, 2020, 3:08:55 PM4/5/20
to OSL Developers
I know we can not make "faster".
But, I want it to be "as fast as it can". :)
Also we need to explain clearly whats trade off.
The goal here is making more users to accept OSL as a new standard.
If we don't give them a clear picture what's going on, they will just stick with "OSL is just slow. Don't use it."
Reply all
Reply to author
Forward
0 new messages