Skip to first unread message

CasperCLD
Apr 13, 2015, 6:20:59 AM4/13/15
to orient-...@googlegroups.com
Hi all,
Recently I asked the question if there was any performance difference with OSQL and Gremlin.
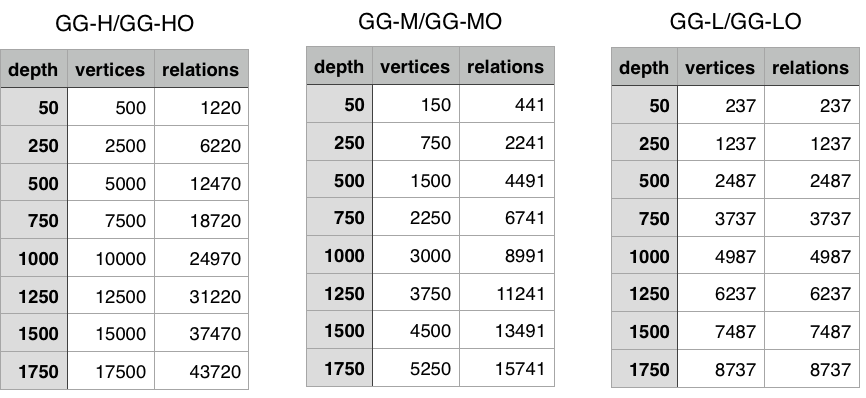
I've created a comparison between OSQL and Gremlin graph traversal. In this comparison I searched for all adjacent nodes of a vertex (depth 0) and the adjacent nodes of those (depth 1) etc.Three types of graphs were compared. These are: graphs with high interconnectivity, medium interconnectivity and low interconnectivity. For every type of graph a duplicate graph was created and filled with orphan nodes (not connected nodes). This was done in order to test the performance between the graph engines when orphan nodes were involved. The graphs were abbreviated to Generated Graph High/Medium/Low Orphan (GG-H/M/L O) and their composition is displayed below in tables:
GG-H/O consists of 1 million vertices and 5 million edges
GG-M/O consists of 1 million vertices and 3 million edges
GG-L/O consists of 1 million vertices and 1 million edges
The following code was used to traverse the vertices:
/**
* Traverse all vertices up until the specified depth. Edges are not returned
* GREMLIN
*/
public void traverseVerticesGremlin(Object vId, int depth, boolean logEnabled) {
Set x = new HashSet<Vertex>();Set e = new HashSet<Edge>();}
new GremlinPipeline<>()
.start(vId)
.as("s1")
.bothE()
.as("e")
.store(e)
.bothV()
.except("s1")
.except(x)
.store(x)
.loop("s1", o -> {
if (logEnabled)
System.out.println(((LoopPipe.LoopBundle) o).getObject().toString());
return ((LoopPipe.LoopBundle) o).getLoops() <= depth;
}).iterate();
edgeCounter = e.size();
vertexCounter = x.size();
/**
* Traverse all vertices up until the specified depth. Edges are not returned* OSQL
*/
public void traverseVerticesOSQL(Object vId, int depth, boolean logEnabled) {
if (queryType.equalsIgnoreCase("osql-traverse")) {
oSqlQuery = "SELECT FROM (traverse * from " + vId + " while $depth <= " + depth + " strategy BREADTH_FIRST) LIMIT -1";
}
((Iterable<Object>) ((OrientGraph) graph).command(new OSQLSynchQuery<>(oSqlQuery)).execute()).forEach(o -> {
if (logEnabled))
System.out.println(o);
if (o.getClass() == OrientVertex.class) vertexCounter++;
else if (o.getClass() == OrientEdge.class) edgeCounter++;
});}
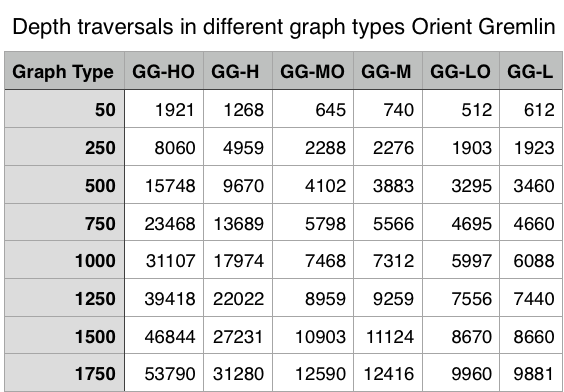
The results are shown below:
![]()
![]()
While the results are the same I see a huge performance drop, when I use Gremlin. The Gremlin command was fully optimised in discussion with Gremlin guru Daniel Kuppitz.
How can this performance be so different?
CasperCLD
Apr 13, 2015, 6:27:56 AM4/13/15
to orient-...@googlegroups.com
I see that the images are missing. Now included.
Additional info: the benchmarks were executed on a Virtual Machine, running Debian Wheezy 7 64-bit, i7 3615QM 4 Cores, 4GB RAM.

{kind=link}
{kind=link}
{kind=link}
Luca Garulli
Apr 13, 2015, 7:21:41 AM4/13/15
to orient-...@googlegroups.com
Hi Casper,
Gremlin query seems correct and efficient, maybe this is only due to the Gremlin layer on top of OrientDB.
Lvc@
--
---
You received this message because you are subscribed to the Google Groups "OrientDB" group.
To unsubscribe from this group and stop receiving emails from it, send an email to orient-databa...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Best Regards,
Luca Garulli
CEO at Orient Technologies LTD
the Company behind OrientDB
Reply all
Reply to author
Forward
0 new messages