Splitted Jobs are mixing in Job Shop
807 views
Skip to first unread message

Rick Tielen
Aug 18, 2021, 5:42:07 AM8/18/21
to or-tools-discuss
Hi all,
I have a problem regarding the Job Shop Scheduling Problem. My system contains multiple machines that are available in shifts. This is different for each machine. Some have weekend shifts, some are available 10 hours per day during weekdays, some are available 15 hours per day during weekdays and 10 hours in the weekend etc. When a machine ends a shift, the operations stops and continues when the shift of the machine starts again.
I used job splitting to implement this. One problem that arises is that the machine works on job 0, then job1 and then continues with job 0. This is not possible in my production facility. https://github.com/google/or-tools/issues/1223 Mentioned the problem, but I don't understand the solution. I assume that I need to add a certain constraint but can't figure out which.
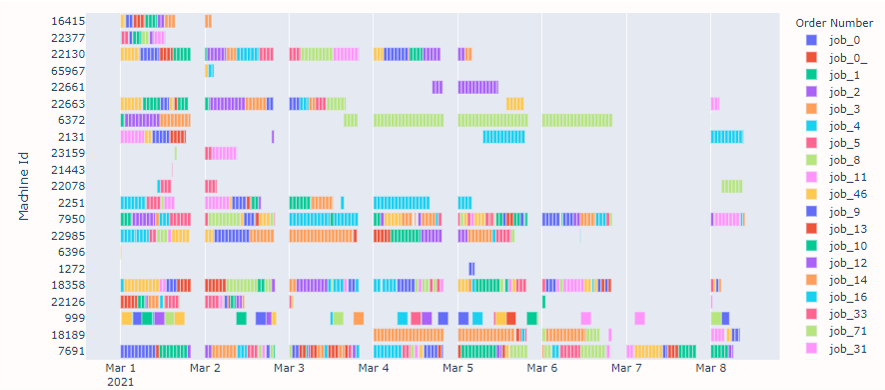
In the figure below it is visible that machine 18189 first processes the orange job, then other jobs and then continues with orange again. I want it to finish the orange job first.
In the figure below an entire schedule is shown.
Message has been deleted
Rick Tielen
Aug 18, 2021, 7:44:19 AM8/18/21
to or-tools-discuss
I thought that https://github.com/google/or-tools/issues/1223 addressed the problem earlier but I can't find it anymore. However, https://github.com/google/or-tools/issues/1798#issuecomment-568165350 had the same problem and referred to https://github.com/google/or-tools/issues/1223. I think I made a mistake in giving the correct link.
https://github.com/google/or-tools/issues/1798#issuecomment-568165350 is having kind of the same problem as I do. I think the difference is that he wants to work on the job until completion regardless of lunch breaks and weekends. Unfortunately he does not provide the full model including data, so no solution has been found yet.
Op woensdag 18 augustus 2021 om 11:42:07 UTC+2 schreef Rick Tielen:
Op woensdag 18 augustus 2021 om 11:42:07 UTC+2 schreef Rick Tielen:
Rick Tielen
Aug 18, 2021, 12:03:10 PM8/18/21
to or-tools-discuss
After another day of trying different things I still can't come up with a solution. I having this problem for several weeks. Maybe a view on my code will help.
machineList = []
machineList = list(machineAvailability)[1:]
machineList = list(map(int, machineList))
class SolutionPrinter(cp_model.CpSolverSolutionCallback):
"""Print intermediate solutions."""
def __init__(self):
cp_model.CpSolverSolutionCallback.__init__(self)
self.__solution_count = 0
self.__solution_limit = math.inf
def on_solution_callback(self):
"""Called at each new solution."""
print('Solution %i, time = %f s, objective = %i' %
(self.__solution_count, self.WallTime(), self.ObjectiveValue()))
self.__solution_count += 1
if self.__solution_count >= self.__solution_limit:
print('Stop search after %i solutions' % self.__solution_limit)
self.StopSearch()
def jobshop_with_maintenance():
"""Solves a jobshop with maintenance on one machine."""
dfGanttChart = pd.DataFrame(columns = ['Order Number','Machine Id', 'START', 'FINISH', 'Deadline'])
dfSequence = pd.DataFrame(columns = ['Order Number','Machine Id'])
# Create the model.
model = cp_model.CpModel()
# Computes horizon dynamically as the sum of all durations.
horizon = sum(task[1] for job in jobs_data for task in job)
machines_count = 1 + max(task[0] for job in jobs_data for task in job)
all_machines = range(machines_count)
# Named tuple to store information about created variables.
task_type = collections.namedtuple('Task', 'start end deadline interval')
# Named tuple to manipulate solution information.
assigned_task_type = collections.namedtuple('assigned_task_type',
'start job index duration')
# Creates job intervals and add to the corresponding machine lists.
all_tasks = {}
machine_to_intervals = collections.defaultdict(list)
for job_id, job in enumerate(jobs_data):
for task_id, task in enumerate(job):
machine = task[0]
duration = task[1]
deadline = task[2]
suffix = '_%i_%i' % (job_id, task_id)
start_var = model.NewIntVar(0, horizon, 'start' + suffix)
end_var = model.NewIntVar(0, horizon, 'end' + suffix)
interval_var = model.NewIntervalVar(start_var, duration, end_var,
'interval' + suffix)
deadline_var = model.NewIntVar(deadline, deadline,
'deadline' + suffix)
all_tasks[job_id, task_id] = task_type(start=start_var,
end=end_var, deadline=deadline_var,
interval=interval_var)
machine_to_intervals[machine].append(interval_var)
# Add weekend
for machine in uniqueMachines:
for i in range(0, 15):
try:
einde = int(machineAvailability.at[i+1, 'Datum'])
lengte = 1440 - int(machineAvailability.at[i, str(machine)])
start = einde - lengte
machine_to_intervals[machine].append(model.NewIntervalVar(start, lengte, einde, 'weekend'))
except:
...
# Create and add disjunctive constraints.
for machine in machineList:
if machine != 999:
model.AddNoOverlap(machine_to_intervals[machine])
# Precedences inside a job.
for job_id, job in enumerate(jobs_data):
for task_id in range(len(job) - 1):
model.Add(all_tasks[job_id, task_id + 1].start >= all_tasks[job_id, task_id].end)
# Makespan objective.
#obj_var = model.NewIntVar(0, horizon, 'makespan')
#model.AddMaxEquality(obj_var, [all_tasks[job_id, len(job) - 1].end for job_id, job in enumerate(jobs_data)])
#model.Minimize(obj_var)
model.Minimize(cp_model.LinearExpr.Sum([all_tasks[job_id, len(job) - 1].end for job_id, job in enumerate(jobs_data)]))
# Solve model.
solver = cp_model.CpSolver()
solver.parameters.num_search_workers=10
solver.parameters.max_time_in_seconds = 40*60
solution_printer = SolutionPrinter()
status = solver.Solve(model, solution_printer)
#print(status)
if status == cp_model.MODEL_INVALID:
print('INVALID')
if status == cp_model.INFEASIBLE:
print('INFEASIBLE')
if status == cp_model.UNKNOWN:
print('UNKNOWN')
if status == cp_model.OPTIMAL:
print('OPTIMAL')
# Output solution.
if status == cp_model.OPTIMAL or status == cp_model.FEASIBLE:
print('FEASIBLE')
# Create one list of assigned tasks per machine.
assigned_jobs = collections.defaultdict(list)
for job_id, job in enumerate(jobs_data):
for task_id, task in enumerate(job):
machine = task[0]
assigned_jobs[machine].append(
assigned_task_type(start=solver.Value(
all_tasks[job_id, task_id].start),
job=job_id,
index=task_id,
duration=task[1]))
#print(job_id, task[0], task[2])
# Create per machine output lines.
output = ''
for machine in uniqueMachines:
# Sort by starting time.
assigned_jobs[machine].sort()
sol_line_tasks = 'Machine ' + str(machine) + ': '
sol_line = ' '
for assigned_task in assigned_jobs[machine]:
name = 'job_%i_%i' % (assigned_task.job, assigned_task.index)
# Add spaces to output to align columns.
sol_line_tasks += '%-10s' % name
start = assigned_task.start
duration = assigned_task.duration
new_row = {'Order Number':assigned_task.job ,'Machine Id': machine}
dfSequence = dfSequence.append(new_row, ignore_index = True)
sol_tmp = '[%i,%i]' % (start, start + duration)
# Add spaces to output to align columns.
sol_line += '%-10s' % sol_tmp
name = name[:-2]
deadline = jobNumber.at[assigned_task.job, 'Deadline']
new_row = {'Order Number':name ,'Machine Id': machine, 'START': start, 'FINISH': start+duration, 'Deadline':deadline}
dfGanttChart = dfGanttChart.append(new_row, ignore_index = True)
sol_line += '\n'
sol_line_tasks += '\n'
output += sol_line_tasks
output += sol_line
# Finally print the solution found.
print('Optimal Schedule Length: %i' % solver.ObjectiveValue())
print('Statistics')
print(' - conflicts : %i' % solver.NumConflicts())
print(' - branches : %i' % solver.NumBranches())
print(' - wall time : %f s' % solver.WallTime())
print(output)
jobshop_with_maintenance()
Op woensdag 18 augustus 2021 om 13:44:19 UTC+2 schreef Rick Tielen:

Laurent Perron
Aug 20, 2021, 10:37:00 AM8/20/21
to or-tools-discuss
One approach is for each job, pre-compute all possible starts (basically not during a break, maybe not just before a break).
Then for each start, compute all possible durations. There should be 2 values (does it overlap one break or not).
Then link the start and the duration using this code: https://github.com/google/or-tools/blob/stable/ortools/sat/doc/integer_arithmetic.md#python-code-2
The main idea is that once start and durations are defined this way, you do not need to have break intervals in your resource. the intervals will span over the breaks.
--
You received this message because you are subscribed to the Google Groups "or-tools-discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to or-tools-discu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/or-tools-discuss/39c08743-4791-4f4f-b450-e7b4e330ae8an%40googlegroups.com.
Rick Tielen
Aug 31, 2021, 3:57:30 AM8/31/21
to or-tools-discuss
I implemented this solution and it is working now. Thanks!
Op vrijdag 20 augustus 2021 om 16:37:00 UTC+2 schreef Laurent Perron:
Laurent Perron
Aug 31, 2021, 4:35:32 AM8/31/21
to or-tools-discuss
It would be super nice if you could contribute a small code sample.
To view this discussion on the web visit https://groups.google.com/d/msgid/or-tools-discuss/f6435f3b-ae57-4a6e-9893-91bfe9e63bean%40googlegroups.com.
Rick Tielen
Sep 23, 2021, 4:55:02 AM9/23/21
to or-tools-discuss
The figure below shows the amount of minutes that a machine is available for each day, at the start of the day.

- Starting times without break
- Starting times with break
- Starting times with weekend break
First I calculate the break times (both normal break and weekend break) and store them in a dictionary for each machine using:
for machine in uniqueMachines:
for i in range(0, 20):
breakTime = 1440 - int(machineAvailability.at[1, str(machine)])
weekendBreakTime = breakTime
if int(machineAvailability.at[i, str(machine)]) == 0 and int(machineAvailability.at[i + 1, str(machine)]) == 0:
weekendBreakTime = weekendBreakTime + 2880
breakTimeMachines[str(machine)] = [breakTime, weekendBreakTime]
break
if int(machineAvailability.at[i, str(machine)]) == 0:
weekendBreakTime = weekendBreakTime + 1440
breakTimeMachines[str(machine)] = [breakTime, weekendBreakTime]
break
breakTimeMachines[str(machine)] = [breakTime, weekendBreakTime]
I also store the intervals that a machines is available using:
for machine in uniqueMachines:
for i in range(0, 20):
try:
einde = int(machineAvailability.at[i+1, 'Datum'])
lengte = 1440 - int(machineAvailability.at[i, str(machine)])
start = einde - lengte
if einde - 1440 == start:
...
else:
machine_available[str(machine)].append([einde - 1440, start])
except:
print('No succes')
Next, I calculate the intervals where a job can start in.
startZonderBreakTask = {}
startMetBreakTask = {}
startMetWeekendBreakTask = {}
b0_dict = {}
b1_dict = {}
b2_dict = {}
for job_id, job in enumerate(jobs_data):
for task_id in range(len(job)):
machine = str(all_tasks[job_id, task_id].machine)
if machine == 1:
...
else:
machineAvailable = copy.deepcopy(machine_available[machine])
startZonderBreak = []#copy.deepcopy(machine_available[machine])
startMetBreak = []#copy.deepcopy(machine_available[machine])
startMetWeekendBreak = []
for i in range(len(machineAvailable)-1):
breakTime = machineAvailable[i+1][0] - machineAvailable[i][1]
tempZonderBreak = []
tempMetBreak = []
tempMetWeekendBreak = []
if breakTime <= 1440:
tempZonderBreak.append(machineAvailable[i][0])
tempZonderBreak.append(machineAvailable[i][1] - int(str(all_tasks[job_id, task_id].original_duration)))
startZonderBreak.append(tempZonderBreak)
#startZonderBreak[i][1] = startZonderBreak[i][1] - int(str(all_tasks[job_id, task_id].original_duration))
tempMetBreak.append(machineAvailable[i][1] - int(str(all_tasks[job_id, task_id].original_duration)) + 1)
tempMetBreak.append(machineAvailable[i][1])
startMetBreak.append(tempMetBreak)
#startMetBreak[i][0] = startMetBreak[i][1] - int(str(all_tasks[job_id, task_id].original_duration)) + 1
else:
tempMetWeekendBreak.append(copy.deepcopy(machineAvailable[i][1]) - int(str(all_tasks[job_id, task_id].original_duration)) + 1)
tempMetWeekendBreak.append(copy.deepcopy(machineAvailable[i][1]))
startMetWeekendBreak.append(tempMetWeekendBreak)
startZonderBreakTask[job_id, task_id] = startZonderBreak
startMetBreakTask[job_id, task_id] = startMetBreak
startMetWeekendBreakTask[job_id, task_id] = startMetWeekendBreak
b0_dict[job_id, task_id] = model.NewBoolVar('b0_%i_%i' % (job_id, task_id)) #NoBreak
b1_dict[job_id, task_id] = model.NewBoolVar('b1_%i_%i' % (job_id, task_id)) #ShiftEndBreak
b2_dict[job_id, task_id] = model.NewBoolVar('b2_%i_%i' % (job_id, task_id)) #WeekendBreak
And the last step is to add the constraints
for job_id, job in enumerate(jobs_data):
for task_id in range(len(job)):
machine = str(all_tasks[job_id, task_id].machine)
breakTime = breakTimeMachines[machine][0]
weekendBreakTime = breakTimeMachines[machine][1]
if machine == 1:
...
else:
model.AddLinearExpressionInDomain(all_tasks[job_id, task_id].start, cp_model.Domain.FromIntervals(startZonderBreakTask[job_id, task_id])).OnlyEnforceIf(b0_dict[job_id, task_id])
model.Add(all_tasks[job_id, task_id].duration == int(str(all_tasks[job_id, task_id].original_duration))).OnlyEnforceIf(b0_dict[job_id, task_id])
model.AddLinearExpressionInDomain(all_tasks[job_id, task_id].start, cp_model.Domain.FromIntervals(startMetBreakTask[job_id, task_id])).OnlyEnforceIf(b1_dict[job_id, task_id])
model.Add(all_tasks[job_id, task_id].duration == int(str(all_tasks[job_id, task_id].original_duration)) + breakTime).OnlyEnforceIf(b1_dict[job_id, task_id])
model.AddLinearExpressionInDomain(all_tasks[job_id, task_id].start, cp_model.Domain.FromIntervals(startMetWeekendBreakTask[job_id, task_id])).OnlyEnforceIf(b2_dict[job_id, task_id])
model.Add(all_tasks[job_id, task_id].duration == int(str(all_tasks[job_id, task_id].original_duration)) + weekendBreakTime).OnlyEnforceIf(b2_dict[job_id, task_id])
model.AddBoolOr([b0_dict[job_id, task_id], b1_dict[job_id, task_id], b2_dict[job_id, task_id]])
The combination of Dutch and English words might be a little bit confusing and also the quality of the code is probably not that great but for me this does the job. I think I will update and organize the code in the future.
Op dinsdag 31 augustus 2021 om 10:35:32 UTC+2 schreef Laurent Perron:
Reply all
Reply to author
Forward
0 new messages