How to easily delete words with low count?
144 views
Skip to first unread message

Richard Jošek
Mar 4, 2021, 11:55:04 AM3/4/21
to OpenRefine
Hello,
I'm still earing open refine and currently I'm trying to delete every row, that has a low-count word in it - meaning when I use word facet and sort it by count, I want to delete every row that contains a word with count 4 or less.
I've tried several things I found on the internet but nothing worked. My dataset is too large to delete them by selecting every word manually.
Do you know any solution to this? Thank you for your answers.

Tom Morris
Mar 4, 2021, 2:17:20 PM3/4/21
to openr...@googlegroups.com
If you create a word facet and scroll down to the bottom of the list, you'll see a (well-hidden) hyperlink labeled "Facet by number of choices", which will bring up a standard numerical facet that you can select a numerical range with.
If your number of words is long enough to make creating the intermediary facet unwieldy (or impossible), the GREL expression it uses is facetCount(value.split(' '), "value.split(' ')", "YOUR COLUMN NAME") and you could use that as the basis for a boolean facet that was true/false based on whether the count was under/over your limit.
Hope that helps!
Tom
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/3c6d3c1c-a890-4bd3-bb62-38b56ce508f1n%40googlegroups.com.
Richard Jošek
Mar 5, 2021, 9:13:19 AM3/5/21
to OpenRefine
I found the "Facet by number of choices" hyperlink and the GREL expression facetCount(value.split(' '), "value.split(' ')", "YOUR COLUMN NAME"), but I don't understand how it works.
I tried adding >4 or >=5 to value.split columns but it doesn't filter out the words with low count. How should I use this expression, if I only want to filter words who occur 5 to 1890 times in my dataset? (or delete all rows with words that occur 4 times or less)
Dne čtvrtek 4. března 2021 v 20:17:20 UTC+1 uživatel tfmo...@gmail.com napsal:

Owen Stephens
Mar 5, 2021, 11:00:48 AM3/5/21
to OpenRefine
Hi Richard,
I think the direct use of the GREL facetCount(value.split(' '), "value.split(' ')", "YOUR COLUMN NAME") was being suggested by Tom only if creating a Word Facet, and then selecting "Facet by choice counts" was a problem (e.g. if the Word Facet turned out to be so large it led to performance issues). However, if you wanted to use this approach I think I'd use the following approach:
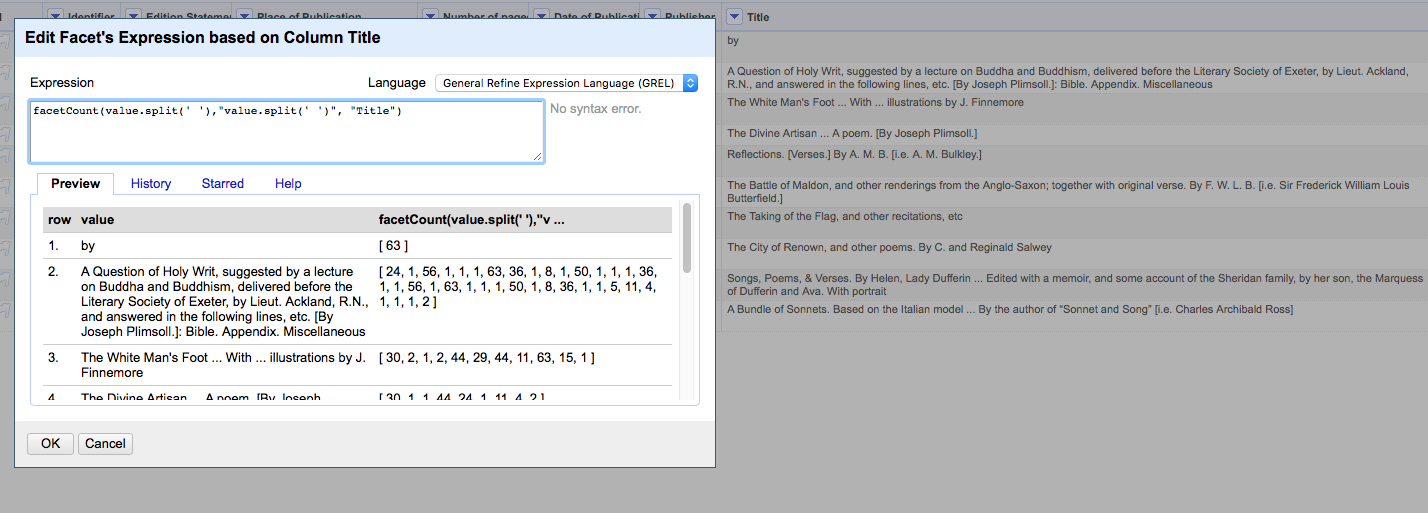
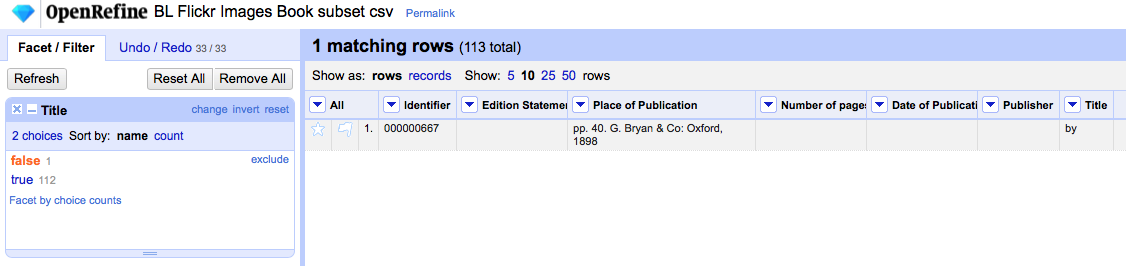
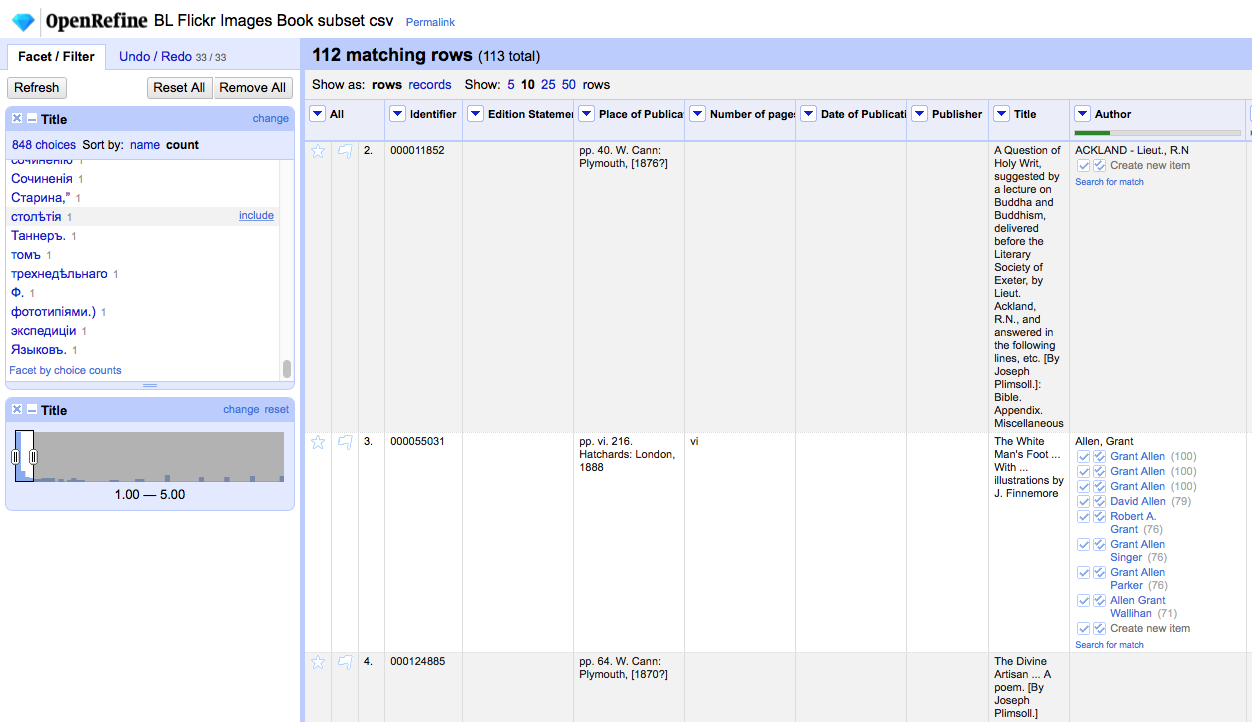
Once you have clicked the "Facet by choice counts" link you should get a numeric facet with a slider at each end. If you move the righthand slider down to the number you want (e.g. 5) then you'll be filtering the rows in the data grid down to only those rows that contain "low count words" (i.e. words that appear in the column in 5 or less rows)
In this screenshot I've done this and you can see for my data set this includes 112 rows out of a total of 113 (i.e. all but one row contains a "low count word")
I think the direct use of the GREL facetCount(value.split(' '), "value.split(' ')", "YOUR COLUMN NAME") was being suggested by Tom only if creating a Word Facet, and then selecting "Facet by choice counts" was a problem (e.g. if the Word Facet turned out to be so large it led to performance issues). However, if you wanted to use this approach I think I'd use the following approach:
In a column dropdown menu select "Facet" -> "Custom text facet"
In the expression editor put the GREL:
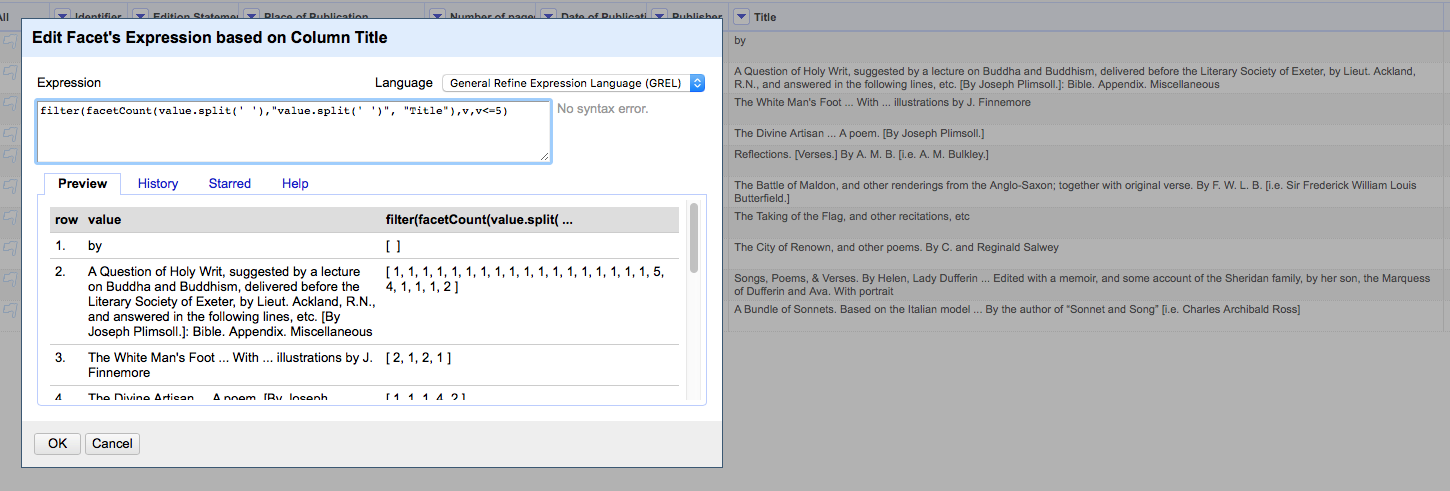
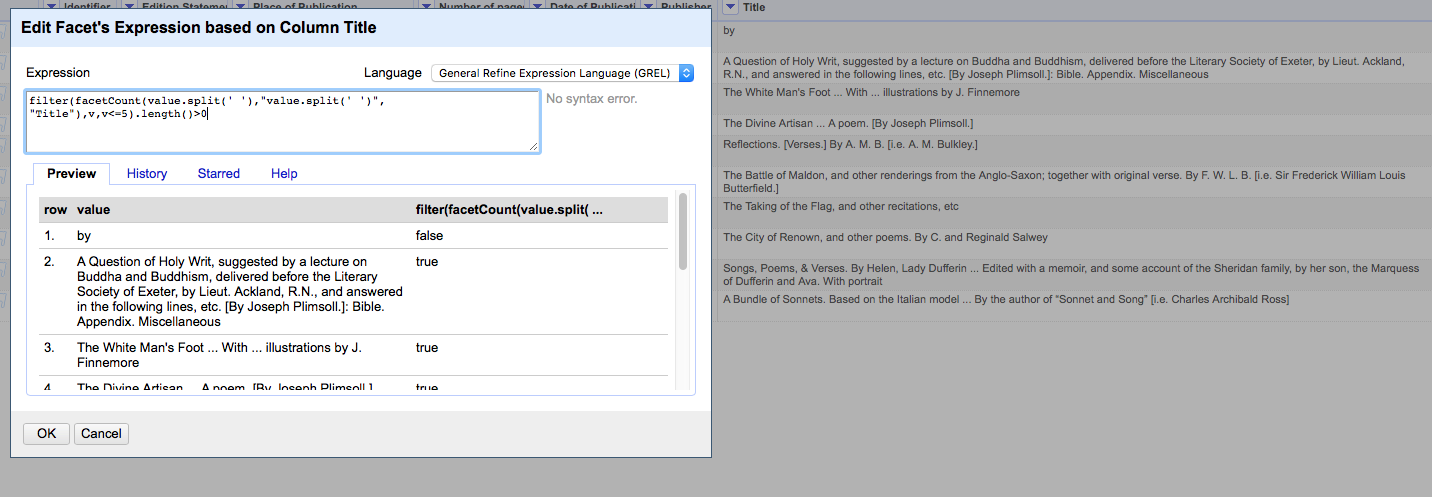
filter(facetCount(value.split(' '),"value.split(' ')", "YOUR COLUMN NAME"),v,v<=5).length()>0
This should give you a true/false value where "true" means that the cell contains a word that occurs in 5 or fewer rows.
facetCount(value.split(' '),"value.split(' ')", "YOUR COLUMN NAME") creates an array for a cell which has one integer value for each word in the cell, that integer is how many cells/rows the word appears in, in the specified column.
In the screenshot you can see - for the first row there is just "by" which gets [ 63 ] - i.e. the word "by" appears in 63 cells in this column. In the second row, we have "A Question of Holy Writ ..." and [ 24, 1, 56, 1, 1 etc. That is "A" appears in 24 cells, "Question" appears in 1 cell, "of" appears in 56 cells, "Holy" appears in 1 cell, "Writ" appears in one cell etc. etc.
The filter removes any integers from that array that are 5 or less.
So now in the first line we have just [ ] (an empty array) - because it only had one number, which was "63" because "by" is a commonly occurring word. In the second line we can see that the larger numbers (24, 56 etc) are gone (being larger than 5) but there are still plenty of low numbers because the second row contains a mixture of commonly occurring words, and uncommon words (Question, Holy, Writ, etc.)
Finally we can now test the length of the array - if it is zero, then it means all the words in the original cell occurred in 6 or more cells in the column - as per our first row - so if we test whether the length of the array is greater than zero, we get "false". But the other rows, because they had one or more "low count" words (ones that appear in 5 cells or less), still have some integers in the array we created, so the length of the array is >0 - so we get "true"
The final outcome of this is a facet of true/false where "true" means that the cell/row contains only words that appear in 6 or more rows, and false means that the cell/row contains at least one word that appears in five or less rows
So if I want to delete rows, then I can select "true" and remove all those rows, knowing that they contain at least one "low-count words"

Thad Guidry
Mar 5, 2021, 11:18:51 AM3/5/21
to openr...@googlegroups.com
To make everyone's lives easier in the future, we might take this use case and morph it into a future feature around a Word distribution facet to complement our existing one?
Tom Morris
Mar 5, 2021, 2:13:28 PM3/5/21
to openr...@googlegroups.com
On Fri, Mar 5, 2021 at 11:18 AM Thad Guidry <thadg...@gmail.com> wrote:
To make everyone's lives easier in the future, we might take this use case and morph it into a future feature around a Word distribution facet to complement our existing one?
Or we could just add the use case and the formula
filter(facetCount(value.split(' '),"value.split(' ')", "YOUR COLUMN NAME"),v,v<=5).length()>0
to the Cookbook.
Going back to the original question, the format of the input data isn't clear to me. I had assumed that there was one word per row/cell, while Owen's worked examples show multiword text strings per cell, which is quite a bit more complicated to deal with.
Richard - is your data one word per row or multiple?
Tom
Richard Jošek
Mar 5, 2021, 2:48:58 PM3/5/21
to OpenRefine
First of all - thank you all for your quick responses.
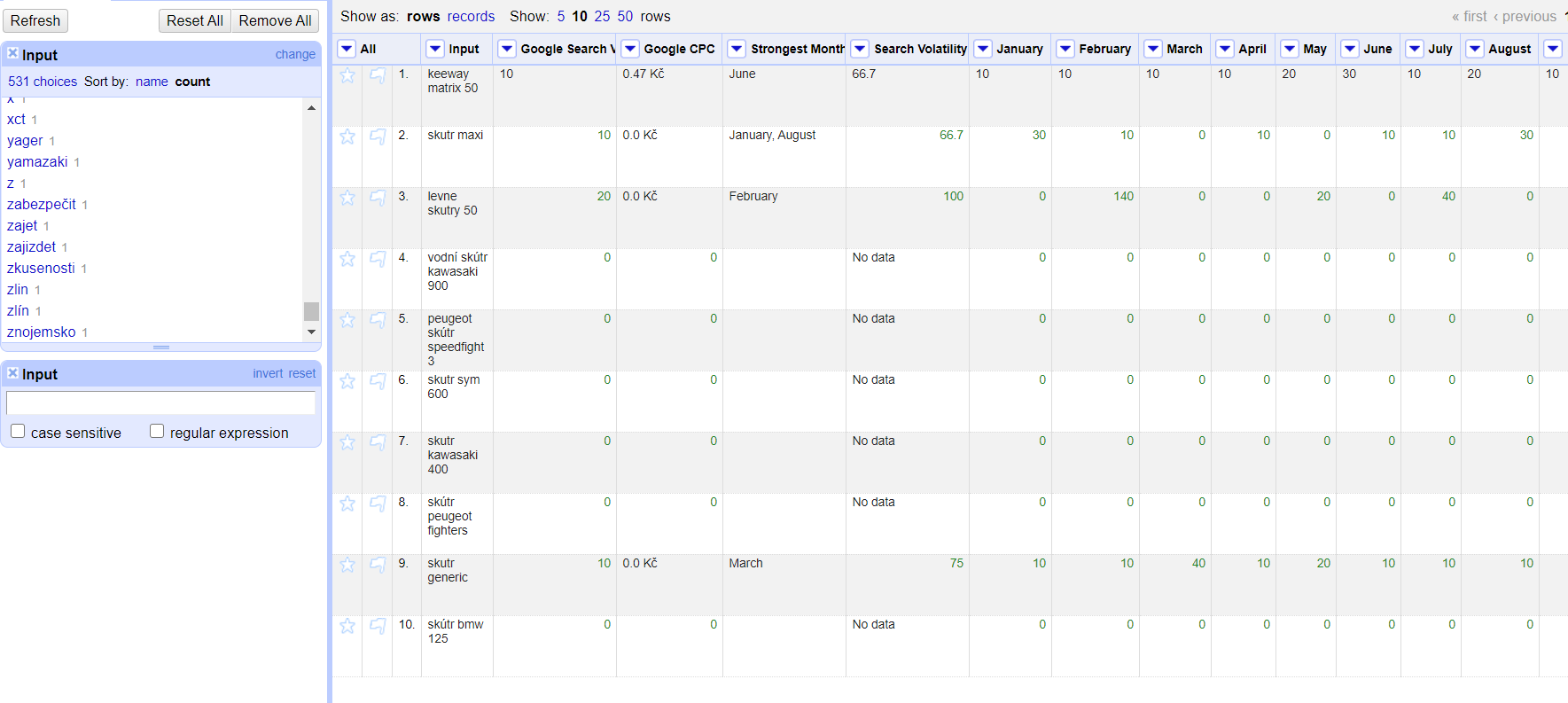
To be honest, I didn't realize this such a complex issue, so I'll try to explain everything. I use openrefine in marketing for keyword analysis for my clients ( mainly for clearing irrelevant phrases and categorization), therefore most of the rows have multiple words per row.
My dataset usually has 5-10k rows and looks like this (the important column is Input):
This screenshot is from a cleared dataset, but what I wanted to do when I started this conversation is to get rid of every row that contains one of those low-count words in the word facet on the left, because I noticed that a lot of low-count words are typos, more irrelevant phrases or URLs typed into search bar.
One last thing - I have basically no programming knowledge. I thought there would be some hidden tool or a 3 step solution that I didn't know about.
Hope this explains everything. If not, let me know.
Thank you all,
Richard
Dne pátek 5. března 2021 v 20:13:28 UTC+1 uživatel tfmo...@gmail.com napsal:
Tom Morris
Mar 5, 2021, 5:51:20 PM3/5/21
to openr...@googlegroups.com
The additional context is helpful. If the number of words is small enough (less than a few thousand?) that you can easily create a word facet, I'd:
- create a Word facet
- scroll to the bottom of the value list, click on "Facet by Choice Counts"
- Set the numeric range sliders to 0-5 (or whatever upper value you want)
- Delete (or flag) all the selected rows
Done!
Good luck,
Tom
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/a391215f-f04f-4156-bc8a-a5213a0c6ff7n%40googlegroups.com.
Richard Jošek
Mar 8, 2021, 8:18:54 AM3/8/21
to OpenRefine
I tried all of your suggestions I found Owens solution the best for my case.
The expression "filter(facetCount(value.split(' '),"value.split(' ')", "YOUR COLUMN NAME"),v,v<=5).length()>0" filtered the unwanted rows most accurately. I still don't know why, but the slider method didn't select all of the low count words.
Anyways, thank you all for your help! It now saves me at least 1-2 hours of work on each analysis!
Dne pátek 5. března 2021 v 23:51:20 UTC+1 uživatel tfmo...@gmail.com napsal:
Reply all
Reply to author
Forward
0 new messages