Jython setup to access external python modules
981 views
Skip to first unread message

colum....@btinternet.com
Dec 13, 2013, 5:35:32 AM12/13/13
to openr...@googlegroups.com
Hi,
I'm hoping someone can help. I looked through previous Jython-related posts on this forum, but couldn't find what I needed.
I'm using openrefine 2.6 beta 1
I was following this
StrippingHTML tutorial from the OpenRefine repo, but couldn't get the BeautifulSoup example at the end to work or this one either:
from beautifulsoup import beautifulsoup
soup = beautifulsoup(value)
return soup.get_text()
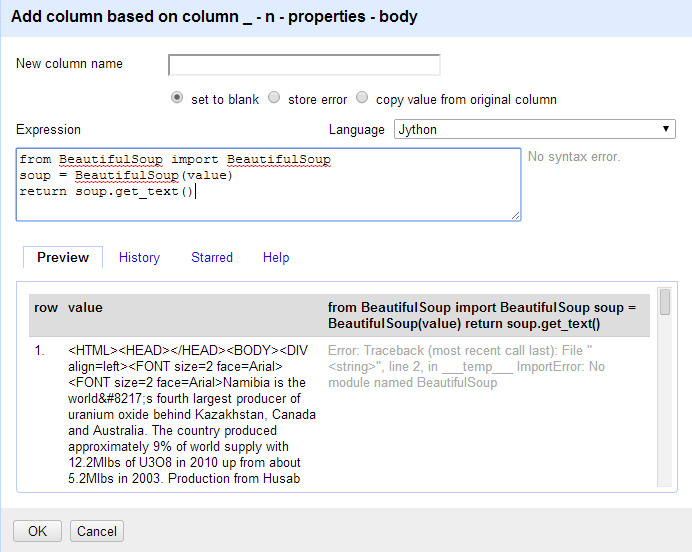
The error would suggest that it can’t find the module
BeautifulSoup .. eventhough it is installed globally in my python environment.

The instructions here aren’t
that clear (to me at least!), when it says drop a *.py into the path …. Which path? Does it
mean somewhere in my openrefine folder? ... such as somewhere under: ...openrefine-2.6-beta.1\webapp\extensions\jython?
I notice the jython-standalone-2.5.3.jar under C:\OpenRefine\openrefine-2.6-beta.1\webapp\extensions\jython\module\MOD-INF\lib
On jython.org, there is a 2.7beta1 that seems to address some of the short-comings related to not being able to run CPython-compiled python modules ... such as LXML, mentioned on the openrefine website. Does anyone know if 2.7beta1 addresses this .. and if so, if it's possible to replace the 2.5.3 jar with this new one?
Thanks for any pointers on these matters,
Colum

Tom Morris
Dec 13, 2013, 7:33:52 AM12/13/13
to openr...@googlegroups.com
On Fri, Dec 13, 2013 at 5:35 AM, <colum....@btinternet.com> wrote:
Hi,I'm hoping someone can help. I looked through previous Jython-related posts on this forum, but couldn't find what I needed.I'm using openrefine 2.6 beta 1
The error would suggest that it can’t find the module BeautifulSoup .. eventhough it is installed globally in my python environment.
Modules typically need to be installed separately for each different Python interpreter, so if you're running 2.7 and 3.x or CPython & Jython, there's not a single "global" Python environment.
You can figure out what your module import path is by opening a transform window and using this little Python snippet:
import sys
return sys.path
It should give you an array of directory paths in the preview window.
The instructions here aren’t that clear (to me at least!), when it says drop a *.py into the path …. Which path? Does it mean somewhere in my openrefine folder? ... such as somewhere under: ...openrefine-2.6-beta.1\webapp\extensions\jython?
It was a little more obvious where to put things when we distributed the bundled modules as a tree of .py files instead of wrapped all up in the single jar. You should be able to put them in any directory on the path (or modify sys.path to include a new directory of your choice). There's also a Jython FAQ which may help http://jython.org/archive/22/userfaq.html#my-modules-can-not-be-found-when-imported-from-an-embedded-application
Can you do us a favor and update the wiki with whatever your final solution is? Thanks!
Tom

John Little
Feb 3, 2015, 10:49:51 AM2/3/15
to openr...@googlegroups.com
I'm having trouble using BeautifulSoup. Can anyone give me some tips? I'm a non-Python users on Windows 7 using Google Refine 2.6-beta.1.
What I've tried:
Read docs. Tried the the example -- four line example at the bottom of the Wiki page on stripping HTML.
I've tried BeautifulSoup 3 and version 4, I've created and put the unzipped beautiful soup folder in the Extensions folder (as identified on this page -- which has this local path: C:\Users\jrl\AppData\Local\OpenRefine\extensions). And based on this thread, I tried putting the folder right in the Jython folder C:\Program Files\OpenRefine\openrefine-2.6-beta.1\webapp\extensions\jython\module\MOD-INF\lib\BeautifulSoup
But I don't have Python loaded separately on my machine and am wondering if I need to install Python?

Thad Guidry
Feb 3, 2015, 11:38:08 AM2/3/15
to openrefine
You do not HAVE to install BeautifulSoup itself any longer, unless you really want to.
We have Jsoup integrated now in 2.6-beta.
On that same wiki page, you can follow my instructions on how to use the integrated GREL Jsoup commands:
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Owen Stephens
Feb 3, 2015, 11:41:36 AM2/3/15
to openr...@googlegroups.com
Can you describe what you are trying to do in terms of the data you are working with? It might be possible to achieve it without going to Jython/BeautifulSoup.
However, to use BeautifulSoup I think (maybe someone can confirm) you need to have it in a location which is in your PATH variable in order that OpenRefine can pick it up - I don't think putting it in the Extensions folder is what is needed.
Owen
John Little
Feb 3, 2015, 12:41:57 PM2/3/15
to openr...@googlegroups.com
Thanks for confirming that Thad. It's a big help. Confirming that I do not have to install BeautifulSoup confirms that my problem -- unfortunately -- lies with my understanding of how to accomplish what I want. So, responding to Owen (Hi Owen!)...
Owen: I'm trying to scrape some table values and elements from this page (and others like it): http://infogob.com.pe/Localidad/ubigeo.aspx?IdUbigeo=010102&IdLocalidad=84&IdTab=0
Specifically I want the TD values under "Cargo", "Nombre", and href attribute under "Nombre"
My goal is to then walk those href attributes and gather some more information. I've accomplished a lot so far, but this is where I'm stuck.
Basically I'm having some programming / conditional logic failures (and I was wondering if maybe my failure would be resolved by trying beautifulsoup although I suspected it was probably a logic and parsing problem). Any helps or tips on the logic and GREL statement would be a huge help. Let me know if you need me to be more specific.
John
Thad Guidry
Feb 3, 2015, 3:38:53 PM2/3/15
to openrefine
Here is how to get the 1st TD row:
Add a new column called "1st_row" based on:
value.parseHtml().select("table#ctl00_ContentPlaceHolder1_cab_ubigeo1_gvAutUbigeo tr td")[0].toString()
where [0] on the end is the 1st one...if you want the second one, use [1]
If it helps, then just Break up the chore by continuing to create a new columns based on the old one...(Add column based on...)
Where you need to use toString() on the end to output a string that parseHtml() can parse over.
So start by populating a single column for getting ALL the "td_rows" with (just omit the [0], which means "the first one"):
value.parseHtml().select("table#ctl00_ContentPlaceHolder1_cab_ubigeo1_gvAutUbigeo tr td").toString()
So you next column of "cargo" can then be created based on the "td"rows column and parsed again with:
value.parseHtml().select("td")[0].htmlText()
Also you can experiment with forEach() as well if you want to...learn and have fun !
Thad
John Little
Feb 3, 2015, 4:07:09 PM2/3/15
to openr...@googlegroups.com
Thanks.
I have actually been using the techniques you mention -- except I cannot create one column at a time based a slice of an array because there are some 10K URLs to construct and slurp.
Perhaps my biggest problem now is refining my syntax when using the forEach() with the htmlAttr() function -- so that I can precisely grab individual HTML elements and merge that with htmlTEXT(). Maybe I'm trying to do too much. Slurping data into a new column (add column based on URL fetching) and then processing the results (new column) has been working pretty well. But trying to improve beyond the few verbs and syntax I'm comfortable with has been relatively unproductive.
So thanks for the syntax examples specific to my problem. It's a big help! I
John
Thad Guidry
Feb 3, 2015, 5:13:40 PM2/3/15
to openrefine
Righto John,
And you don't HAVE to use forEach() unless you find that you cannot easily get a nice list or subset of table rows with the regular Jsoup syntax expression. (either because there are missing identifiers so you cannot hone in on what you want, etc). But I rarely hit upon that, and so almost never need to use forEach().
I would say spend some time learning the Jsoup CSS selector syntax as well. Here are the 2 documents that will help you much:
Owen Stephens
Feb 3, 2015, 5:23:57 PM2/3/15
to openr...@googlegroups.com
Hi John,
If you want to scrape data from a series of pages, following links etc. you could also consider going for a different tool (and bringing the results into OpenRefine at the end if necessary). One possibility would be trying morph.io to scrape the data - you can write scrapers on morph.io in Python, Ruby, PHP and Perl.
I've written one in Ruby that gets the names and URIs from the first table from the page you mentioned in case it helps in any way.
Feel free to post questions as github issues if you want to pursue this route
Owen
Reply all
Reply to author
Forward
0 new messages