Measuring scale/limits of OpenRefine

Owen Stephens

With 2Gb memory, it started to struggle around 1.35million rows, and failed to do the operations (although successfully loaded) on 1.55million rows

With 4Gb memory, there is no sudden up tick in time taken to do the operations - it just gradually increases until it failed to do the operations on 2.625million rows (n.b. the script allows you to do repeated loads of the same file size and take an average - I've not done this here which is probably why those spikes are in there)

The script is very basic and ideally I'd like to try doing some other type of test - like increasing the number of columns as well as rows, and trying loads of the same data in different formats (e.g. xls vs csv) - feel free to take the script and adapt it if you are interested. For example I've just done a test run with an 8 column file (1Gb memory) and in that case it failed slightly earlier at 600k rows. Also at the request of Scott Carlson on Twitter (https://twitter.com/scottythered) I ran a test where I loaded and exported the data, but didn't carry out any operations. I only did this with 1Gb memory assigned and found that it would keep loading the data up to around 1.5million rows (but good luck in doing anything with the data once it is OR!):

If anyone has done anything similar I'd be interested to know if you saw similar results. If you have a particular aspect of OpenRefine you'd like to see tested in terms of data volume, let me know or add an Issue to the script GitHub. Also feel free to take and develop the script if you want, or ask questions/make requests.
Best wishes
Owen

Thad Guidry

qi cui
Owen Stephens
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Thad Guidry
qi cui
- Data loading to spread the data set to HDFS
- Data processing using the spark. which means swapping out the operations current based on heap memory
- Front end change to use partial data to do the facet instead of using the whole data set
- A mechanism to use the sample data to design the operations before submitting to spark cluster
- Handling the redo/undo since the diff will not be stored locally
- Handing the fact that each time the data spreading(the number of worker node and the partition of the data set etc) is different. It will create some challenge to persistent the operations which are deterministic if the data set is loaded wholly in memory. For example, "change the cell(50,2) value from abc to cba".
Thad Guidry

Patrick Maroney
In one case I was able to complete numerous transformations (including python custom scripts) in hours vs. he days it was taking me on my local 32GB Mac OS X system. This time savings paid for whatever AWS charges I incurred by a couple orders of magnitude. Plus I didn't have to wait 30 minutes for each transform on a column to complete which really slows down the iterative interactive nature of developing OpenRefine transformation/enrichment processes. I have a snapshot of my Data Science Ubuntu Image (With all of my tools and frameworks installed) that I use to launch instantiations scaled to the task at hand. You can use CloudFormation templates, Vagrant, etc. to deploy your On Demand Data Science systems If you don't want to pay for the Snapshots.
Just keep your data sets on separate volumes and mount your EFS/EBS volumes or restore a snapshot of the Data Sets. When done, you delete the AWS Instance (Lesson Learned: Don't forget to delete the instance!!!!-- large scale syatems can cost upwards of $300/day)
Owen Stephens

Bertram Ludaescher
I might be misunderstanding, but in that case, why not just keep requesting more CPUs and more RAM and forget about other parallelization approaches?
I'm getting mixed messages here.. ;-)
Can someone shed some more light on this?
Thanks, cheers,
Bertram
Antonin Delpeuch (lists)
At the moment, no parallelism is used at all.
Scaling OR to handle larger projects is on our plans.
Antonin
> You received this message because you are subscribed to the Google
> Groups "OpenRefine" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to openrefine+...@googlegroups.com
Patrick Maroney
- You need to preposition your data sets.
- You need to get adept at firing up/tearing down/resizing AMI instances.
- Start with the best estimate of how much memory you need to load your data into OpenRefine
- Fire the instances up as soon as you are ready to work
- You can dynamically switch AWS instance types to scale up/down.
- Remember to power them down when your done*.
*If you inadvertently leave a p3.16xlarge running over a 3 day weekend, you'll have a $2,000 surprise on Tuesday morning. For a month: $17,000.
GPU Instances - Current Generation p3.16xlarge 64 188 488 EBS Only $ 17,870 $ 588 $ 24.48
Memory Optimized - Current Generation x1.32xlarge 128 349 1952 2 x 1920 SSD $ 9,737 $ 320 $ 13.34
Memory Optimized - Current Generation r4.16xlarge 64 195 488 EBS Only $ 3,107 $ 102 $ 4.26
General Purpose - Current Generation m4.16xlarge 64 188 256 EBS Only $ 2,336 $ 77 $ 3.20
General Purpose - Current Generation m4.10xlarge 40 124.5 160 EBS Only $ 1,460 $ 48 $ 2.00
Caveat Emptor: Of course, in general, there are scenarios where "more" actually results in diminishing returns (i.e., Java garbage collection issues).
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openrefine/-loChQe4CNg/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openrefine+...@googlegroups.com.

Jennifer Newcomer
Thad Guidry
Try increasing your setting for max memory for Refine in the refine.ini file (or openrefine.l4j.ini) to
--
You received this message because you are subscribed to the Google Groups "OpenRefine" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/e4a67cb0-5155-4980-976b-0c247b1d1326n%40googlegroups.com.
Owen Stephens
Your current configuration is set to use XXXXM of memory.
Jennifer Newcomer
You received this message because you are subscribed to a topic in the Google Groups "OpenRefine" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openrefine/-loChQe4CNg/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openrefine+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/492601bd-5f18-431f-98e7-518f7c66261fn%40googlegroups.com.
Jennifer Newcomer
Your current configuration is set to use XXXXM of memory.
You received this message because you are subscribed to a topic in the Google Groups "OpenRefine" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openrefine/-loChQe4CNg/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openrefine+...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/492601bd-5f18-431f-98e7-518f7c66261fn%40googlegroups.com.

Owen Stephens
Jennifer Newcomer
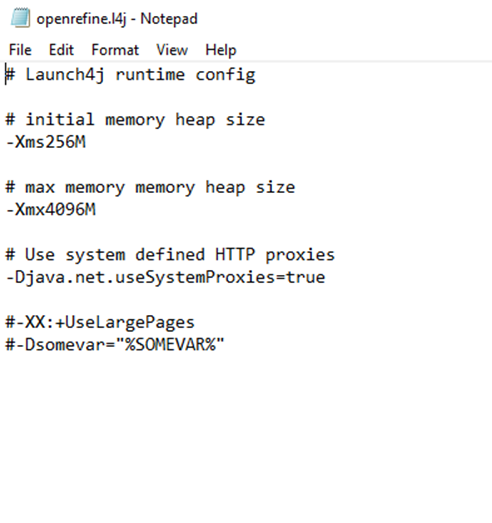
Hi Owen,I start OpenRefine by clicking the OpenRefine.exe, and have used openrefine.l4j.ini to change the memory. See below for how I have it configured.I'll try your recommendation and start OpenRefine by running refine.bat and configure the refine.ini file.Thanks again!Jennifer
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/8f75e253-abb3-463d-9cb4-9a43da5020f1n%40googlegroups.com.
--Jennifer NewcomerResearch DirectorPhD CandidateUniversity of Colorado, DenverUrban & Regional Planning | Geography
Jennifer Newcomer
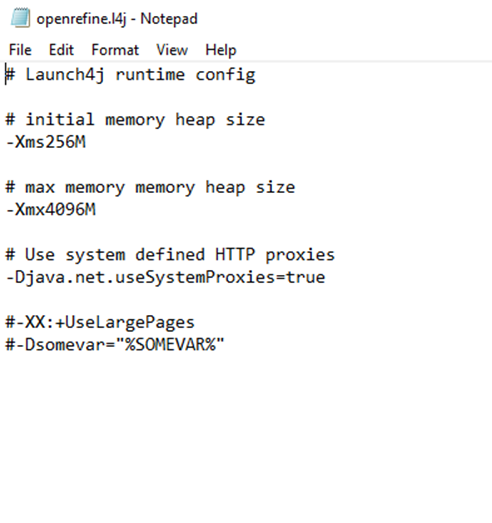
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/8f75e253-abb3-463d-9cb4-9a43da5020f1n%40googlegroups.com.
Owen Stephens
Jennifer Newcomer
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/ec14f2b9-adea-4042-b0e6-ebb9a0ce54c0n%40googlegroups.com.
Owen Stephens
Thad Guidry
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/da2b940e-9dd4-463a-a2f1-dcb6eb591de2n%40googlegroups.com.
Jennifer Newcomer
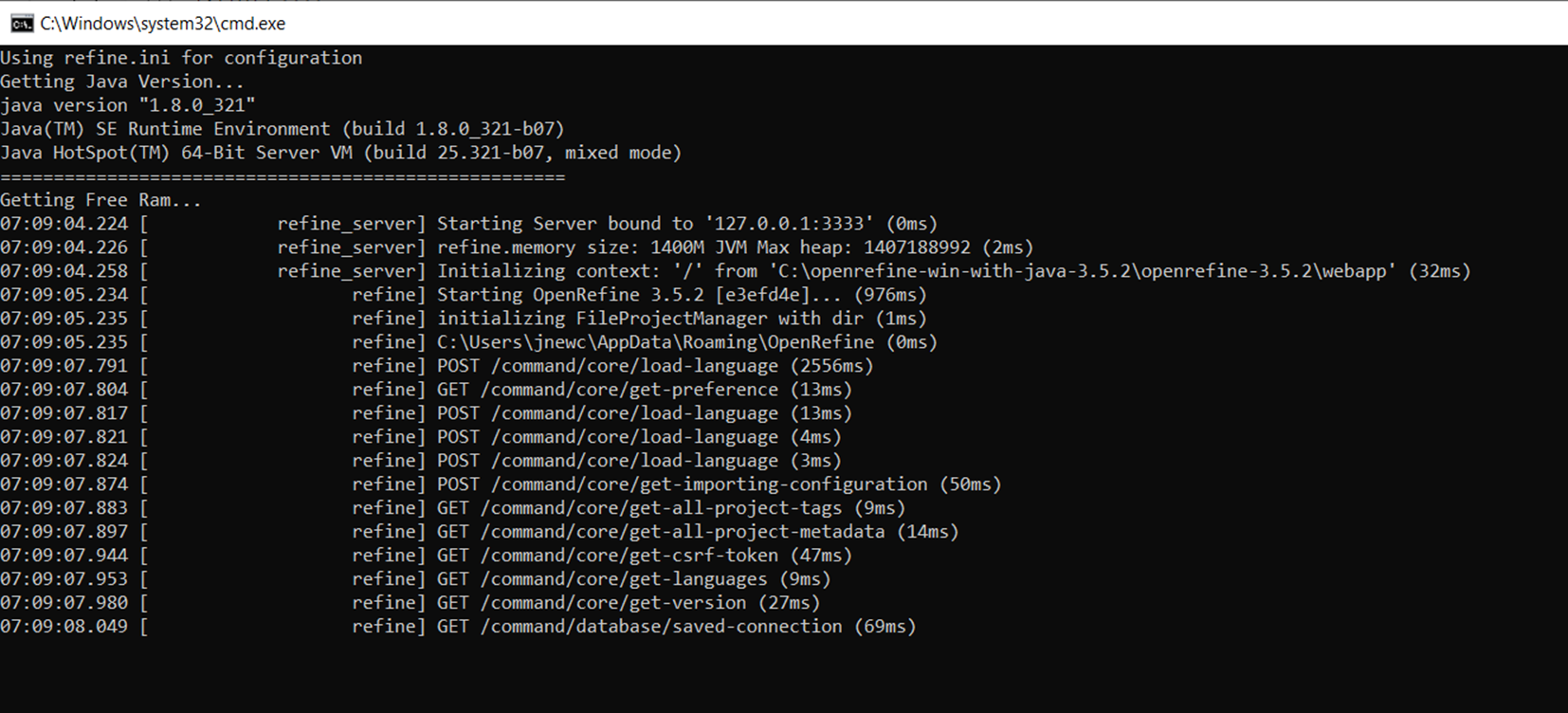


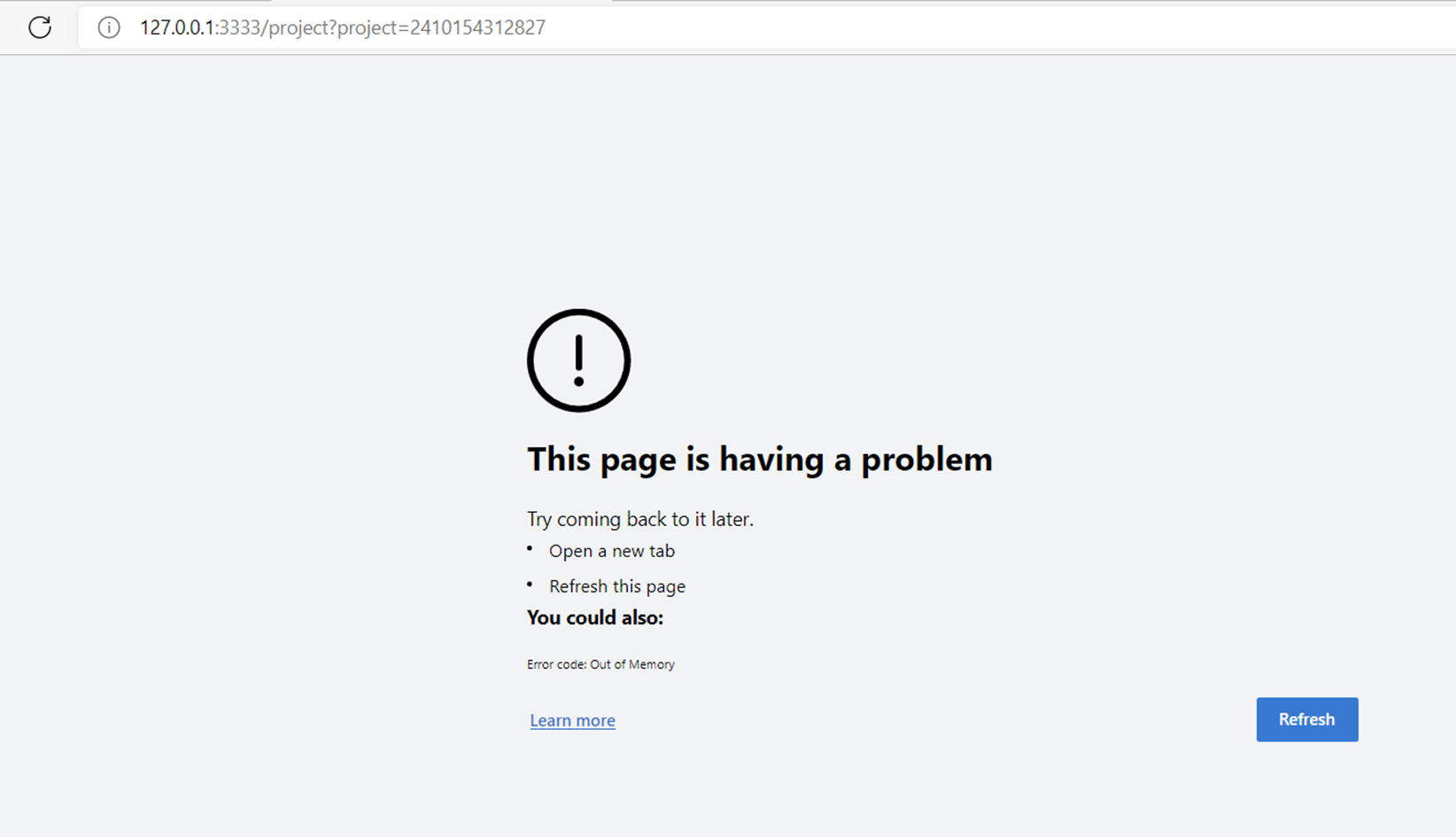
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/CAChbWaNSG_%2BbXNFNxN5xnFcL5r3bcrcAw1y8%2BXEZ_31er63oRw%40mail.gmail.com.
Owen Stephens
Jennifer Newcomer
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/7bbd06fd-5aa3-4397-8f5a-55f91eb2a906n%40googlegroups.com.
Owen Stephens
Jennifer Newcomer
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine/073a2952-7e4a-4882-a8cb-cf4682107090n%40googlegroups.com.
Owen Stephens
Hi Owen,