Spark Config
2 views
Skip to first unread message

Thad Guidry
Jan 5, 2021, 11:05:36 AM1/5/21
to openref...@googlegroups.com
Hi Antonin,
I cannot seem to get the Spark Context to acknowledge my env SPARK_LOCAL_DIRS
Log Output Snippet:
09:09:35.782 [..ckManagerMasterEndpoint] BlockManagerMasterEndpoint up (1ms)
09:09:35.799 [..torage.DiskBlockManager] Created local directory at C:\Users\thadg\AppData\Local\Temp\blockmgr-0348ea0c-995b-4731-bf1b-46664acc6be6 (17ms)
Looking at the code of Spark itself (BTW, the 2.4.5 docs are missing DiskBlockManager class, but it's described in older version docs of Spark API):
https://github.com/apache/spark/blob/14c2edae7e8e02e18a24862a6c113b02719d4785/core/src/main/scala/org/apache/spark/storage/DiskBlockManager.scala#L34
https://github.com/apache/spark/blob/14c2edae7e8e02e18a24862a6c113b02719d4785/core/src/main/scala/org/apache/spark/storage/DiskBlockManager.scala#L34
I've set my SPARK_LOCAL_DIRS=F:\SPARK_TEMP so that it uses my fastest SSD NVME disk drive.
But yet when I startup with refine /m 16G, it's not using that dir but as you can see in the log output snippet above, instead is always using the system property default for java.io.tmpdir
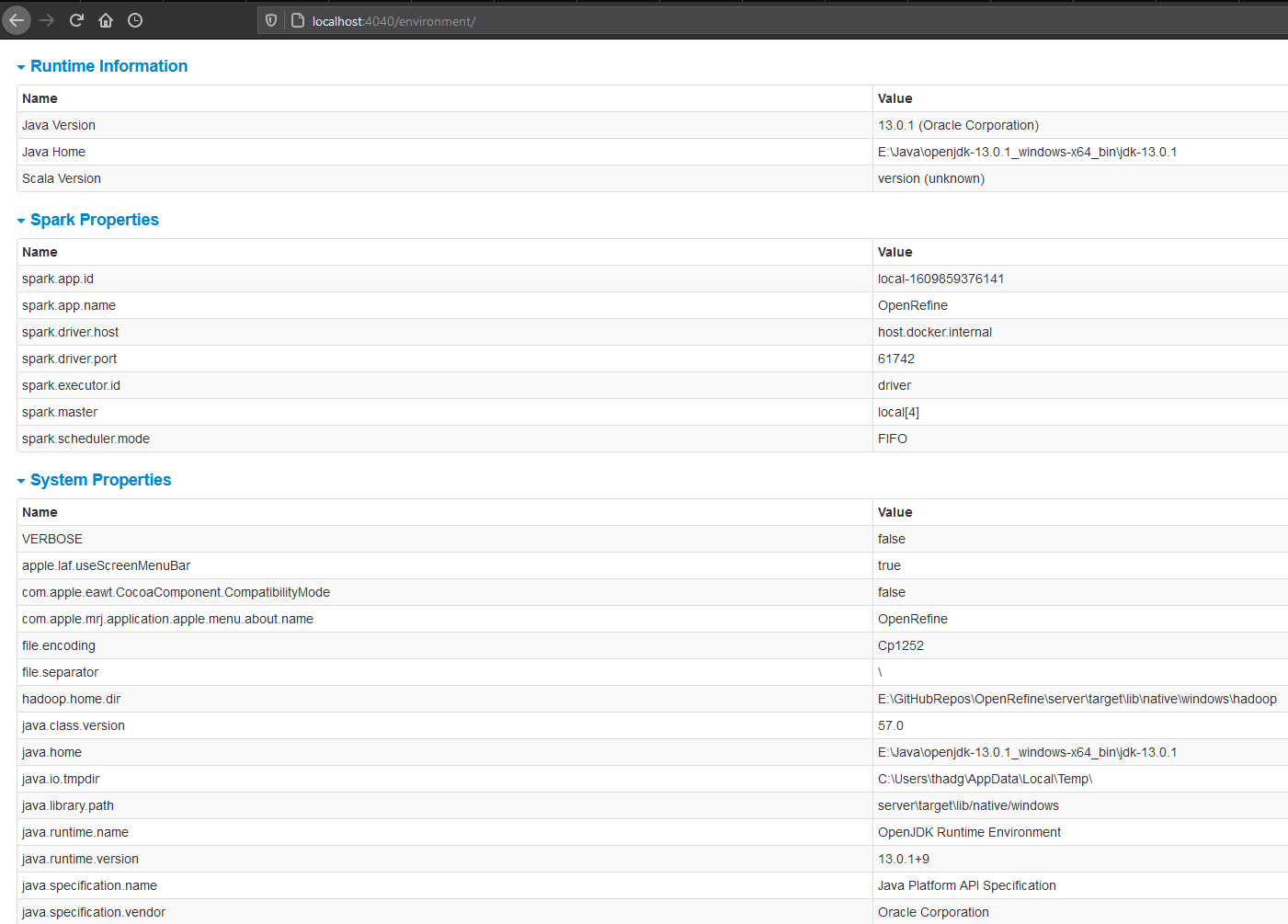
Thoughts?
Have you tried to override the temp dir using that env variable and got it working?
Hmm, I'm wondering if just setting the spark.local.dir property would work better overall?
Or better still, modifying the launch script so that it can take a new argument `--conf` and just like Spark's spark-submit https://spark.apache.org/docs/latest/configuration.html
Another alternative might be allowing a configuration directory and specifying that from the refine script so that it can read the files such as https://gist.github.com/thadguidry/9a76f6867d7f79b954e4f5f8d2f1ed91 ?
https://spark.apache.org/docs/latest/configuration.html#overriding-configuration-directory
https://spark.apache.org/docs/latest/configuration.html#overriding-configuration-directory
Thad Guidry
Jan 5, 2021, 11:28:21 AM1/5/21
to openref...@googlegroups.com
Well, I finally did get it to recognize and change using the spark.local.dir property if I specify it within the JVM context using our refine.ini file.
So I guess any spark property can just be added into refine.ini for the standalone cluster config, but since .ini is not a multiline format that can be read, it probably makes sense to allow reading Spark config files from a given conf directory specified by refine.sh or refine.ini
Anyways, this is the workaround for me now on my Windows testing:
JAVA_OPTIONS=-Dspark.local.dir=F:\SPARK_TEMP
10:21:28.933 [..ckManagerMasterEndpoint] BlockManagerMasterEndpoint up (0ms)
10:21:28.942 [..torage.DiskBlockManager] Created local directory at F:\SPARK_TEMP\blockmgr-0c6feaf0-bb37-4a0a-ba84-3d6e1df5ad3c (9ms)
10:21:28.961 [..rage.memory.MemoryStore] MemoryStore started with capacity 9.4 GB (19ms)
Thad Guidry
Jan 5, 2021, 1:34:46 PM1/5/21
to openref...@googlegroups.com
Hmm, looks like we also still need to contend with Hadoop's binaries needed as I described before on issue 1433 comment
10:21:28.400 [..pache.hadoop.util.Shell] Failed to locate the winutils binary in the hadoop binary path (39ms)
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
A large CSV file imported on my Windows 10 machine but notice the Hadoop exception after it completed all the stages and final job.
We can see that we'll need to also deal with task reduction later, but for now need to focus on the Hadoop binaries and the best way to package that as part of the refine build process.
Any thoughts on how best to incorporate the Hadoop binaries as part of the build for any kind of user, including me on Windows?
11:12:29.705 [ refine] GET /command/core/get-models (27ms)
11:12:29.731 [ refine] POST /command/core/get-all-preferences (26ms)
11:12:29.800 [ refine] GET /command/core/get-history (69ms)
11:12:29.804 [ refine] POST /command/core/get-rows (4ms)
11:12:29.816 [ refine] GET /command/core/get-history (12ms)
11:12:37.570 [..cheduler.TaskSetManager] Stage 182 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (7754ms)
11:13:11.944 [..cheduler.TaskSetManager] Stage 183 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (34374ms)
11:13:20.840 [..cheduler.TaskSetManager] Stage 184 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8896ms)
11:13:56.412 [..cheduler.TaskSetManager] Stage 185 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (35572ms)
11:14:30.975 [..cheduler.TaskSetManager] Stage 186 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (34563ms)
11:14:39.780 [..cheduler.TaskSetManager] Stage 187 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8805ms)
11:14:48.543 [..cheduler.TaskSetManager] Stage 188 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8763ms)
11:14:57.057 [..cheduler.TaskSetManager] Stage 189 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8514ms)
11:15:06.596 [..cheduler.TaskSetManager] Stage 190 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9539ms)
11:15:15.281 [..cheduler.TaskSetManager] Stage 191 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8685ms)
11:15:24.048 [..cheduler.TaskSetManager] Stage 192 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8767ms)
11:15:32.443 [..cheduler.TaskSetManager] Stage 193 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8395ms)
11:15:41.209 [..cheduler.TaskSetManager] Stage 194 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8766ms)
11:15:49.819 [..cheduler.TaskSetManager] Stage 195 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8610ms)
11:15:58.609 [..cheduler.TaskSetManager] Stage 196 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8790ms)
11:16:07.505 [..cheduler.TaskSetManager] Stage 197 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8896ms)
11:16:17.914 [..cheduler.TaskSetManager] Stage 198 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (10409ms)
11:16:26.981 [..cheduler.TaskSetManager] Stage 199 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9067ms)
11:16:36.050 [..cheduler.TaskSetManager] Stage 200 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9069ms)
11:16:44.498 [..cheduler.TaskSetManager] Stage 201 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8448ms)
11:16:53.376 [..cheduler.TaskSetManager] Stage 202 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8878ms)
11:17:02.339 [..cheduler.TaskSetManager] Stage 203 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8963ms)
11:17:11.565 [..cheduler.TaskSetManager] Stage 204 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9226ms)
11:17:20.203 [..cheduler.TaskSetManager] Stage 205 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8638ms)
11:17:28.906 [..cheduler.TaskSetManager] Stage 206 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8703ms)
11:17:37.573 [..cheduler.TaskSetManager] Stage 207 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8667ms)
11:21:40.251 [..cheduler.TaskSetManager] Stage 208 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (242678ms)
11:22:09.829 [..spark.executor.Executor] Exception in task 2.0 in stage 208.0 (TID 260) (29578ms)
java.io.IOException: (null) entry in command string: null chmod 0644 C:\Users\thadg\AppData\Roaming\OpenRefine\2164326080469.project\initial\grid\_temporary\0\_temporary\attempt_20210105112131_0108_m_000002_0\part-00002.gz
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:762)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:859)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:842)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:661)
at org.apache.hadoop.fs.ChecksumFileSystem$1.apply(ChecksumFileSystem.java:501)
at org.apache.hadoop.fs.ChecksumFileSystem$FsOperation.run(ChecksumFileSystem.java:482)
at org.apache.hadoop.fs.ChecksumFileSystem.setPermission(ChecksumFileSystem.java:498)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:467)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:433)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:908)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:801)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:135)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.initWriter(SparkHadoopWriter.scala:230)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:120)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:83)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:411)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:830)
11:12:29.731 [ refine] POST /command/core/get-all-preferences (26ms)
11:12:29.800 [ refine] GET /command/core/get-history (69ms)
11:12:29.804 [ refine] POST /command/core/get-rows (4ms)
11:12:29.816 [ refine] GET /command/core/get-history (12ms)
11:12:37.570 [..cheduler.TaskSetManager] Stage 182 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (7754ms)
11:13:11.944 [..cheduler.TaskSetManager] Stage 183 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (34374ms)
11:13:20.840 [..cheduler.TaskSetManager] Stage 184 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8896ms)
11:13:56.412 [..cheduler.TaskSetManager] Stage 185 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (35572ms)
11:14:30.975 [..cheduler.TaskSetManager] Stage 186 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (34563ms)
11:14:39.780 [..cheduler.TaskSetManager] Stage 187 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8805ms)
11:14:48.543 [..cheduler.TaskSetManager] Stage 188 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8763ms)
11:14:57.057 [..cheduler.TaskSetManager] Stage 189 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8514ms)
11:15:06.596 [..cheduler.TaskSetManager] Stage 190 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9539ms)
11:15:15.281 [..cheduler.TaskSetManager] Stage 191 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8685ms)
11:15:24.048 [..cheduler.TaskSetManager] Stage 192 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8767ms)
11:15:32.443 [..cheduler.TaskSetManager] Stage 193 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8395ms)
11:15:41.209 [..cheduler.TaskSetManager] Stage 194 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8766ms)
11:15:49.819 [..cheduler.TaskSetManager] Stage 195 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8610ms)
11:15:58.609 [..cheduler.TaskSetManager] Stage 196 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8790ms)
11:16:07.505 [..cheduler.TaskSetManager] Stage 197 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8896ms)
11:16:17.914 [..cheduler.TaskSetManager] Stage 198 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (10409ms)
11:16:26.981 [..cheduler.TaskSetManager] Stage 199 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9067ms)
11:16:36.050 [..cheduler.TaskSetManager] Stage 200 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9069ms)
11:16:44.498 [..cheduler.TaskSetManager] Stage 201 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8448ms)
11:16:53.376 [..cheduler.TaskSetManager] Stage 202 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8878ms)
11:17:02.339 [..cheduler.TaskSetManager] Stage 203 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8963ms)
11:17:11.565 [..cheduler.TaskSetManager] Stage 204 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (9226ms)
11:17:20.203 [..cheduler.TaskSetManager] Stage 205 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8638ms)
11:17:28.906 [..cheduler.TaskSetManager] Stage 206 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8703ms)
11:17:37.573 [..cheduler.TaskSetManager] Stage 207 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (8667ms)
11:21:40.251 [..cheduler.TaskSetManager] Stage 208 contains a task of very large size (257401 KB). The maximum recommended task size is 100 KB. (242678ms)
11:22:09.829 [..spark.executor.Executor] Exception in task 2.0 in stage 208.0 (TID 260) (29578ms)
java.io.IOException: (null) entry in command string: null chmod 0644 C:\Users\thadg\AppData\Roaming\OpenRefine\2164326080469.project\initial\grid\_temporary\0\_temporary\attempt_20210105112131_0108_m_000002_0\part-00002.gz
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:762)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:859)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:842)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:661)
at org.apache.hadoop.fs.ChecksumFileSystem$1.apply(ChecksumFileSystem.java:501)
at org.apache.hadoop.fs.ChecksumFileSystem$FsOperation.run(ChecksumFileSystem.java:482)
at org.apache.hadoop.fs.ChecksumFileSystem.setPermission(ChecksumFileSystem.java:498)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:467)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:433)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:908)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:801)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:135)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.initWriter(SparkHadoopWriter.scala:230)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:120)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:83)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:411)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:830)

Antonin Delpeuch (lists)
Jan 6, 2021, 11:55:18 AM1/6/21
to openref...@googlegroups.com
Nice, well done! It will be useful to document this. Out of curiosity, why did you need to change this directory?
Antonin
--
You received this message because you are subscribed to the Google Groups "OpenRefine Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine-de...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine-dev/CAChbWaPPKym9LwFhiNJQrB2KkmgfH1QxJPYNsr%2B9zOjR7KiDag%40mail.gmail.com.
Antonin Delpeuch (lists)
Jan 6, 2021, 11:58:16 AM1/6/21
to openref...@googlegroups.com
Interesting, I thought that was solved now, but perhaps I broke
this in my merge with master. Can you add this to the GitHub
issue?
Concerning the large CSV imports, I am still working on making that more efficient. I want to make a separate thread about this.
Antonin
--
You received this message because you are subscribed to the Google Groups "OpenRefine Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openrefine-de...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openrefine-dev/CAChbWaP3Tf6pJPdVe%3DhxzMANZr%2BHZy54djjnpBU-PBJ%3Di3KEWw%40mail.gmail.com.
Thad Guidry
Jan 6, 2021, 1:53:09 PM1/6/21
to openref...@googlegroups.com
On Wed, Jan 6, 2021 at 10:55 AM Antonin Delpeuch (lists) <li...@antonin.delpeuch.eu> wrote:
Nice, well done! It will be useful to document this. Out of curiosity, why did you need to change this directory?
Antonin
I needed to change because I am testing with a large file (which ends up making lots of Records) and ran out of space on my C: drive which is being crushed by Windows 10 OS already :-) and it's not an SSD NVMe drive, but an older SSD.
My F: drive is new Samsung 960 EVO NVME
Thad Guidry
Jan 10, 2021, 2:13:20 PM1/10/21
to openref...@googlegroups.com
And of course... also something in the way...(sigh, so happy with Windows, and yet so sick of it in regards to cross platform development, which is getting easier, until someone decides to cut corners...LIKE HADOOP)
So it turns out there's a few decisions that we need to make as well for our Windows users for OpenRefine on Spark (standalone) for packaging some future release.
Submitting MapReduce jobs with the Hadoop Shell (which is what Spark does as shown in stacktrace) indeed requires one of the following:
Use WINUTILS.exe
Where do we get WINUTILS.exe from?
- From https://github.com/cdarlint/winutils and we trust them?
- We built it ourselves from Hadoop sources using the official Hadoop guide: https://cwiki.apache.org/confluence/display/HADOOP2/Hadoop2OnWindows
- ???
Use the Pentaho Patch perhaps or something like it we do ourselves?
Stacktrace (new-architecture branch from OpenRefine) on Windows that needs a Hadoop built for Windows:
Caused by: java.io.IOException: (null) entry in command string: null chmod 0644 F:\OpenRefine_Workspace\2291466807251.project\initial\grid\_temporary\0\_temporary\attempt_20210110112649_0050_m_000000_0\part-00000.gz
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:762)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:859)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:842)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:661)
at org.apache.hadoop.fs.ChecksumFileSystem$1.apply(ChecksumFileSystem.java:501)
at org.apache.hadoop.fs.ChecksumFileSystem$FsOperation.run(ChecksumFileSystem.java:482)
at org.apache.hadoop.fs.ChecksumFileSystem.setPermission(ChecksumFileSystem.java:498)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:467)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:433)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:908)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:801)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:135)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.initWriter(SparkHadoopWriter.scala:230)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:120)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:83)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:411)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
Thad Guidry
Jan 10, 2021, 2:16:06 PM1/10/21
to openref...@googlegroups.com
Hmm... further thoughts... what if in SparkGridState we DID NOT save as a Hadoop file?
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:100)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopDataset$1(PairRDDFunctions.scala:1096)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1094)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$4(PairRDDFunctions.scala:1067)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1032)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$3(PairRDDFunctions.scala:1014)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1013)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$2(PairRDDFunctions.scala:970)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:968)
at org.apache.spark.rdd.RDD.$anonfun$saveAsTextFile$4(RDD.scala:1562)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1550)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile(JavaRDDLike.scala:558)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile$(JavaRDDLike.scala:557)
at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:45)
at org.openrefine.model.SparkGridState.saveToFile(SparkGridState.java:483)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopDataset$1(PairRDDFunctions.scala:1096)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1094)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$4(PairRDDFunctions.scala:1067)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1032)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$3(PairRDDFunctions.scala:1014)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1013)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$2(PairRDDFunctions.scala:970)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:968)
at org.apache.spark.rdd.RDD.$anonfun$saveAsTextFile$4(RDD.scala:1562)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1550)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile(JavaRDDLike.scala:558)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile$(JavaRDDLike.scala:557)
at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:45)
at org.openrefine.model.SparkGridState.saveToFile(SparkGridState.java:483)
Thad Guidry
Jan 10, 2021, 4:24:57 PM1/10/21
to openref...@googlegroups.com
Ok, there might perhaps be a 3rd option as I looked into it more.
Instead of RDD.saveAsTextFile()
We could instead use one of these new API methods to store to HDFS or any supported Hadoop storage system? but I'm not 100% sure if it will eliminate the Windows driver issue, would need to try out and test ...
-
saveAsNewAPIHadoopFile
public <F extends org.apache.hadoop.mapreduce.OutputFormat<?,?>> void saveAsNewAPIHadoopFile(String path, Class<?> keyClass, Class<?> valueClass, Class<F> outputFormatClass, org.apache.hadoop.conf.Configuration conf)Output the RDD to any Hadoop-supported file system.
-
saveAsNewAPIHadoopDataset
public void saveAsNewAPIHadoopDataset(org.apache.hadoop.conf.Configuration conf)
Output the RDD to any Hadoop-supported storage system, using a Configuration object for that storage system.- Parameters:
conf- (undocumented)
-
saveAsNewAPIHadoopFile
public <F extends org.apache.hadoop.mapreduce.OutputFormat<?,?>> void saveAsNewAPIHadoopFile(String path, Class<?> keyClass, Class<?> valueClass, Class<F> outputFormatClass)Output the RDD to any Hadoop-supported file system.
Reply all
Reply to author
Forward
0 new messages