Looking more deeply at Levenshtein performance in OpenRefine
3 views
Skip to first unread message

Thad Guidry
Nov 22, 2020, 11:34:37 PM11/22/20
to openref...@googlegroups.com
I ran some performance benchmarking this weekend on the current Levenshtein algorithm we use from TeamCohen on OpenRefine 3.4.1 release.
I think we could do better using the already provided Apache algorithm (which should be able to better take advantage directly of some CPU SSE4.2 instructions.
I even tried myself to nestle the org.apache.commons.text.similarity.LevenshteinDistance into the DistanceFactory but had problems and not entirely confident on Super's if it was needed or not. (my Java Fu sucks and will never get better).
So hopefully someone else can quickly nestle the Apache library into place or advise me how it could possibly be done?
GC's on the Heap like crazy because of (I think a combination of things, but mostly) non vectorizable custom StringWrapper from TeamCohen
(vectorizable meaning able to utilize CPU intrinsic functions to increase performance within limits)
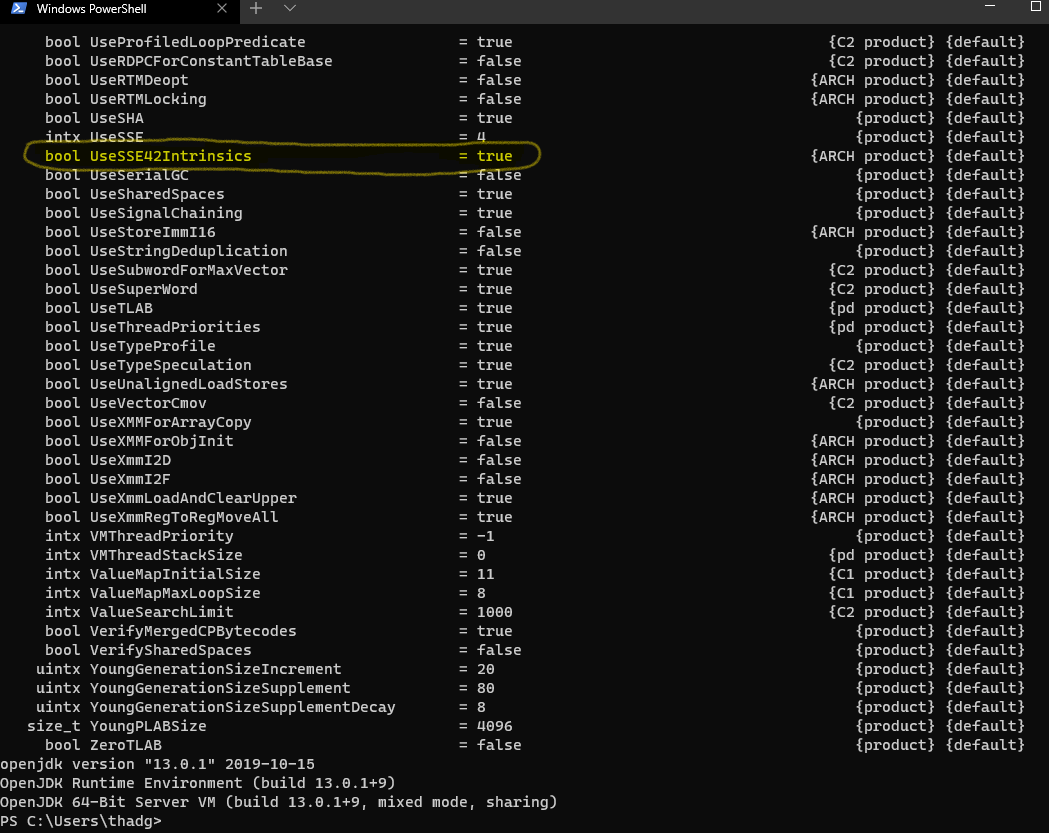
to see if intrinsic methods are being utilized or not and where in compiled code, you can add: -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
to see if intrinsic methods are being utilized or not and where in compiled code, you can add: -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
and then watch the console output when performing Clustering operations as well as VisualVM CPU profiling
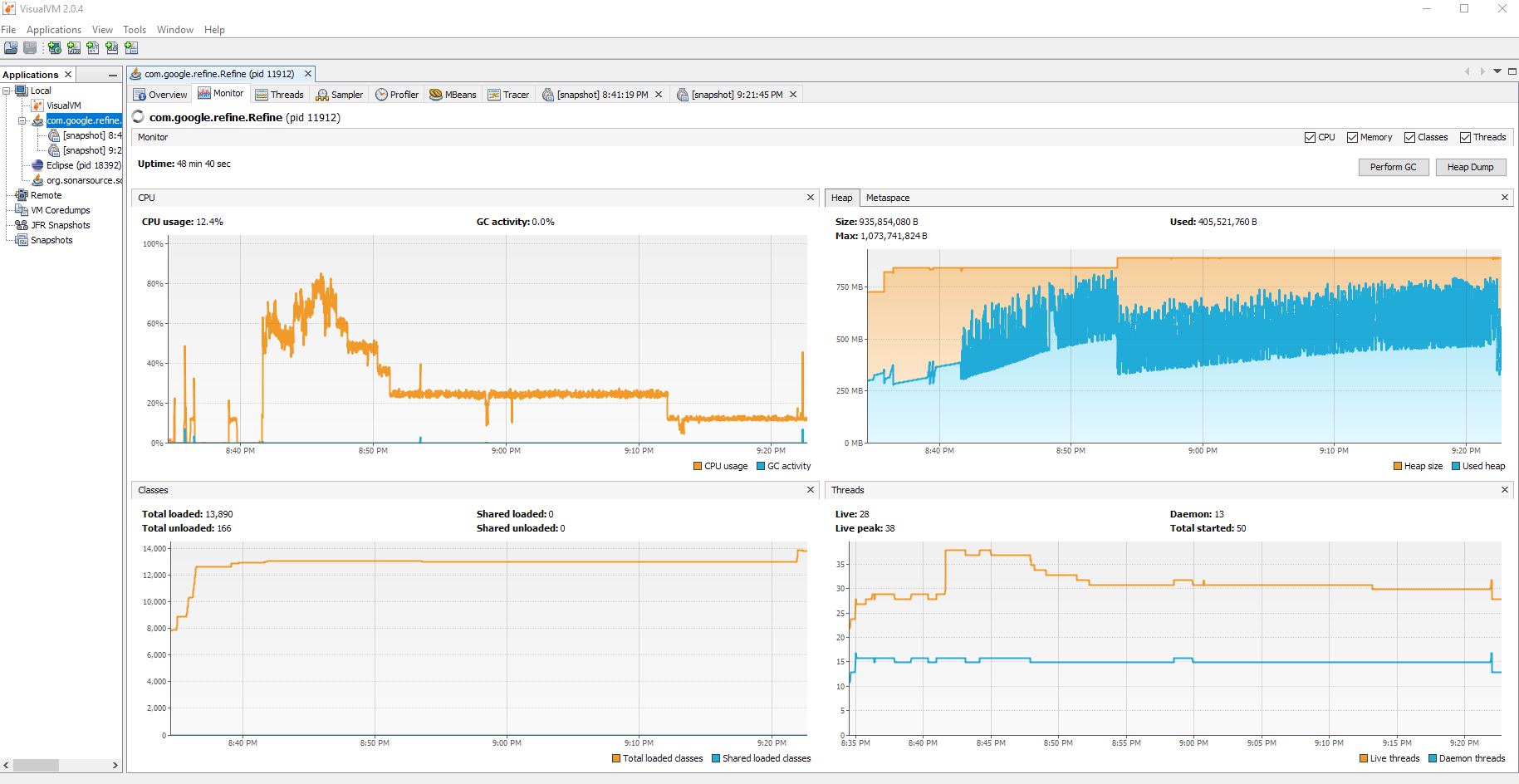
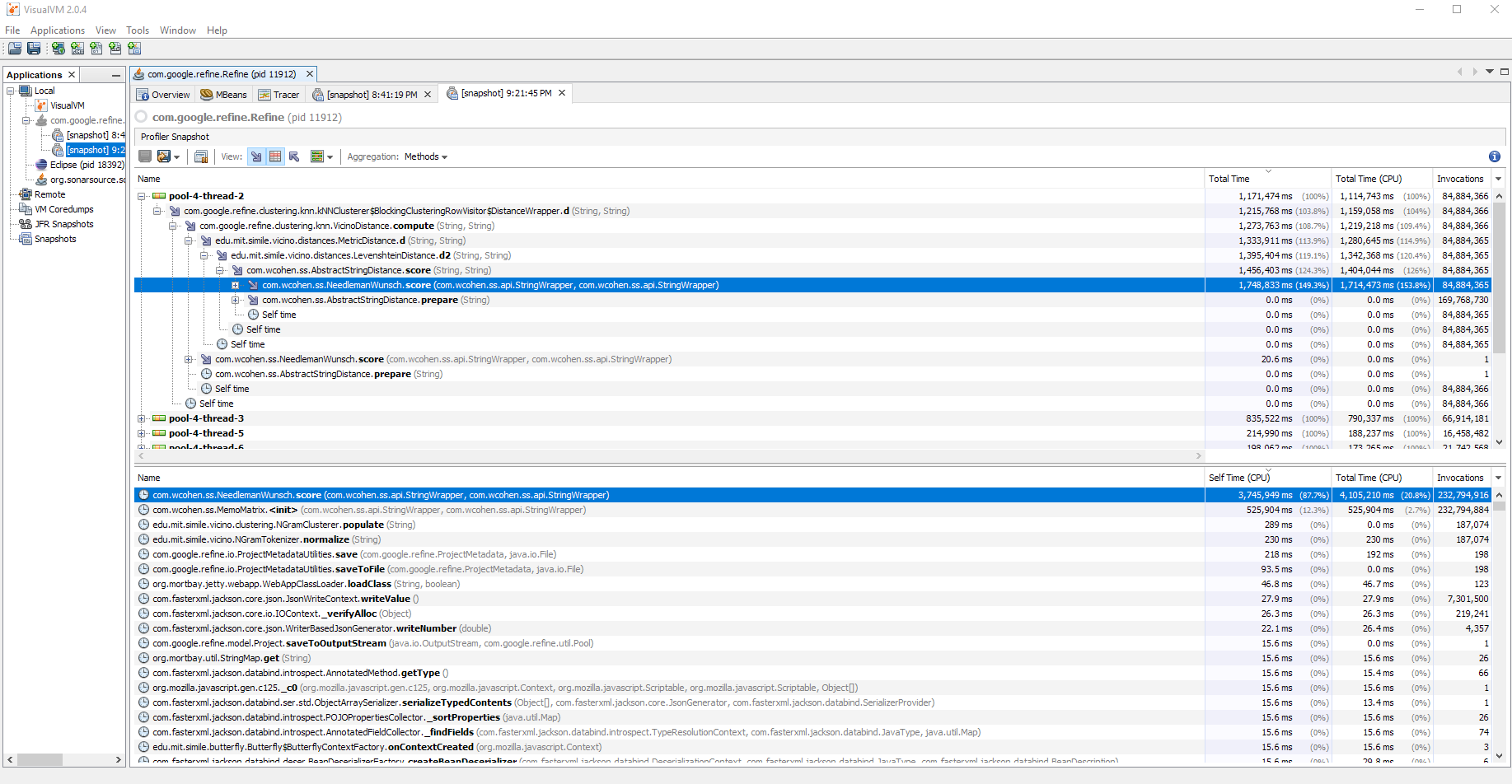
I would be more than happy to help anyone who can code, much better than my old eyes, what we need and to benchmark it, which is not for the faint of heart.
Reply all
Reply to author
Forward
0 new messages