1:M vs M:M debate for locations and services
12 views
Skip to first unread message

Rory G
Feb 5, 2015, 11:18:51 AM2/5/15
to OpenRe...@googlegroups.com
Hello, thought I'd create a thread here to add my 2 cents and take the conversation out of the awkward commenting system in Google Docs.
Earlier today I had a chat with Greg and explained a bit about what we ended up doing with our Clackmannanshire fork, as follows:
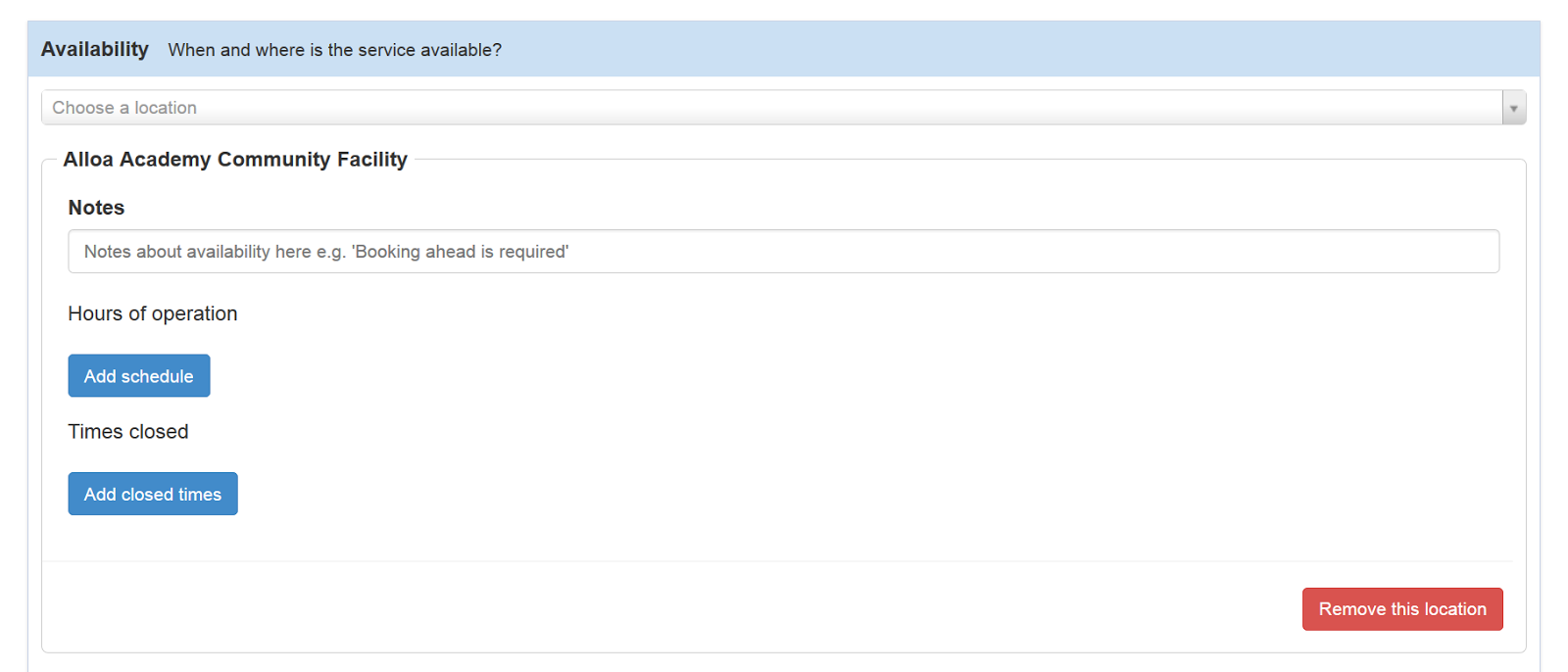
Here's a screen shot of the sort of thing we've got in the admin:
Earlier today I had a chat with Greg and explained a bit about what we ended up doing with our Clackmannanshire fork, as follows:
Ah, I'm glad you've brought this up. You see, we have implemented the m:m model in our fork.
I was hesitant to diverge from the original code much at first but there are several instances where we have essentially the same service at different locations. The result was I was asked to make this change by several of my test users.
Instead of ServiceAtLocation we've got a table called 'Availabilities', it's essentially the same thing though, I just thought it natural to say 'service x is available at location y'.
We've found that this is works well enough for data entry. You create a service, and then you select where it is available. This means you don't need to repeat yourself when you want to list essentially the same service at another location. Also, consider what you have to do when a service moves to a different location. Under this system you just need to remove an availability and add another one.
I understand that this causes an issue when you want to transfer things in a flat format like a spreadsheet. However, I think it's an issue that can be overcome. In particular, it can be overcome with the help of automation.
A further possibility the 'Availability' entries could provide for is the time information - so an availability record could say 'this service is available at this location at these times'. However, in my fork I haven't gone down that route, keeping the schedule tables intact, mainly to avoid over-complicating things.
Here's a screen shot of the sort of thing we've got in the admin:

Moncef Belyamani
Feb 5, 2015, 11:23:04 AM2/5/15
to Rory G, OpenRe...@googlegroups.com
Thanks, Rory!
I just finished creating a spreadsheet that summarizes the issue and provides the pros and cons of each solution. Rory's comments confirm what I say in the Conclusion. In Rory's situation, he is treating every Service as exactly the same across Locations. For that specific use case, n:m is perfect. However, as far as I can tell, his implementation does not allow for certain Service attributes to be different in one Location versus another. In OpenReferral, we absolutely have to design for that scenario since it is pretty much guaranteed that at least one attribute will be different. Rory acknowledges that with respect to hours of operation (one of many attributes that could be different), but says he has not implemented it stating over-complication as a reason.
The fact remains that implementing n:m while allowing some Service attributes to be shared and others to be unique is inevitably complicated; a lot more than 1:n.
As Rory stated, and as I concluded in my spreadsheet, the main reason why people are requesting n:m is to make it easier to enter data in an admin interface. As I explained in my spreadsheet, it is easier to create an admin interface that takes care of the duplication for you (so you don't have to manually enter stuff over and over) while keeping 1:n than implementing n:m.
I would be more than happy to update the Ohana API Admin interface to solve the duplication problem.
Cheers,
Moncef
--
You received this message because you are subscribed to the Google Groups "OpenReferral" group.
To unsubscribe from this group and stop receiving emails from it, send an email to OpenReferral...@googlegroups.com.
To post to this group, send email to OpenRe...@googlegroups.com.
Visit this group at http://groups.google.com/group/OpenReferral.
For more options, visit https://groups.google.com/d/optout.

Greg Bloom
Feb 5, 2015, 11:35:55 AM2/5/15
to OpenRe...@googlegroups.com
Thanks, Rory and Moncef.
We should step back and provide some from-the-top context to folks here.
First of all, this is all in regards to this thread in the version 0.9 document. It's a doozy; in fact, this appears to be the primary contention left to resolve between 0.9 and 1.0 of our spec.
I've done my best to summarize this pretty technical issue below. (I assume the technical folks will check my work and offer helpful clarifications :)
Here we go:
The v0.9 model of our spec, called HSDS, basically says that one location can have multiple services, and that each service 'belongs' to a single location. This reflects the architecture of the Ohana API. The Ohana team's reasoning for this is that one organization might provide the same type of service at multiple locations, but those services will have different phone numbers, addresses, hours of operation, etc. So, they reason, services provided at different locations should be treated as distinct services, each associated with its specific location. (In database terms, this is called ‘denormalization.' In this specific context, it's described as a 1:m relationship between locations and services.)
This has met with shared disagreement from commenters (representing most of the stakeholders in our pilot projects) who say that a service should be able to be associated with multiple locations (described in the thread as an n:m relationship between services and locations, and described by Rory in the subject line of this email as m:m). They observe a few problems with the renormalization approach. It potentially makes it harder to do data entry, and it yields what appears to be duplications in the database. Also, though it may be simpler in the context of a schema, it doesn’t seem to reflect how people in the field (organizations, service providers, etc) understand their own world. Finally, they point out that it’s harder to go from ‘flat’ (denormalized) data to 'structured' (renormalized) data than to flatten data that is already structured — and this would effectively prevent these stakeholders from exchanging data in the Open Referral format.
One alternative proposal is to have the differences between services offered at multiple locations be stored in another object. The ‘anti-denormalization’ side (Declan, Neil, et al) say that this keeps things simpler for data entry and for the end-user; the ‘pro-denormalization’ side (Ohana) says this increases the complexity of a system overall, making it slower, and possibly making it more complicated to produce data via spreadsheets. (However; iCarol claims that its current system scales in performance fine; and there seems to be disagreement about which approach is more complicated for data entry). The pro-denormalization side also suggests that the data at stake here (services offered at multiple locations) represents a small segment of the records (8% in San Mateo).
It seems like we're approaching a consensus here -- though there will be serious decisions that we have yet to make in any case. Before we make a decision (which will be based on a combination of what we're hearing from our stakeholders -- especially those in our pilots -- and the judgment of our lead data modeler, Sophia) it will be great to get another round of feedback.
Okay - thanks for reading -- if you're still with us, now you may want to return to the top of the thread to re-read Rory and Moncef's discussion.
~greg
Rory G
Feb 5, 2015, 11:37:02 AM2/5/15
to OpenRe...@googlegroups.com, giann...@gmail.com
Hiya,
On Thursday, 5 February 2015 16:23:04 UTC, Moncef Belyamani wrote:
Thanks, Rory!I just finished creating a spreadsheet that summarizes the issue and provides the pros and cons of each solution. Rory's comments confirm what I say in the Conclusion. In Rory's situation, he is treating every Service as exactly the same across Locations. For that specific use case, n:m is perfect. However, as far as I can tell, his implementation does not allow for certain Service attributes to be different in one Location versus another.
That's right, but only thing I'd say is, this method gives you the option of treating services as exactly the same across all locations. If certain properties differ then you can always create another service / location / whatever.
In OpenReferral, we absolutely have to design for that scenario since it is pretty much guaranteed that at least one attribute will be different. Rory acknowledges that with respect to hours of operation (one of many attributes that could be different), but says he has not implemented it stating over-complication as a reason.
Sorry, I should clarify my post about the schedule. The hours of operation are related to the availabilities. So the times can be different for the same location at different locations. What I meant was you could potentially put schedule or other availability related data in the availabilities table (e.g. I have a field called 'notes').
Rory G
Feb 5, 2015, 11:40:05 AM2/5/15
to OpenRe...@googlegroups.com, giann...@gmail.com
Woops let me correct that, that should read*:
Sorry, I should clarify my post about the schedule. The hours of operation are related to the availabilities. So the times can be different for the same service* at different locations. What I meant was you could potentially put schedule or other availability related data in the availabilities table (e.g. I have a field called 'notes').
Moncef Belyamani
Feb 5, 2015, 12:15:34 PM2/5/15
to Rory G, OpenRe...@googlegroups.com
That's right, but only thing I'd say is, this method gives you the option of treating services as exactly the same across all locations. If certain properties differ then you can always create another service / location / whatever.
It is much more likely for a service to be different than for it be exactly the same. If a service is indeed exactly the same, that option is available as well in 1:n. If you're going to end up creating another service as you mention if properties differ, then you might as well use 1:n.
Here are some relevant questions:
1. In your dataset, what percentage of services are offered at more than one location?
2. Of those, what is the greatest number of locations where the same service is provided? How many Services are offered at that maximum amount of Locations?
3. Of those in #1, what is the most common number of locations? In other words, when a Service is offered at more than one Location, is it typically 2? 3? 5?
4. Out of #1, how many are exactly the same across all Locations, including phone number, contacts, and hours of operation?
5. Out of #4, how many are guaranteed to never change any of the attributes defined in the Services table, as well as the associated tables such as phones, contacts, regular schedules, and holiday schedules?
Rory
Feb 5, 2015, 1:10:09 PM2/5/15
to Moncef Belyamani, OpenRe...@googlegroups.com
1 - Yes, the case where a service which operates at multiple locations is in the minority.
2 & 3 - Around 3 so far.
4 - In my case, all the same apart from hours of operation (which has been handled).
5 - They are not never guaranteed to change, but I don't see this as a problem. If they diverge sufficiently they can become separate.
I think what you're asking in 5 reveals quite a bit. Some contacts / phones / details are there to coordinate the service at any and all locations. Some may be there to coordinate the service at a single location, however, mostly they still coordinate the service and would be able to help someone access that service. Consequently, users are unlikely to consider those details as being 'sufficiently separate' to merit a whole new service.
So that's why we've found it's a bit unintuitive for them create another service. So far, when handling the availability of a service at a location, no user has asked to differentiate it by anything other than operating hours.
So that's why we've found it's a bit unintuitive for them create another service. So far, when handling the availability of a service at a location, no user has asked to differentiate it by anything other than operating hours.
Hope that helps.
Moncef Belyamani
Feb 5, 2015, 10:41:58 PM2/5/15
to Rory, OpenRe...@googlegroups.com
Thank you for those insightful answers, Rory. They confirm my theory that the duplication issue is a minor one in the grand scheme of things given how few services need to be associated with multiple locations.
I have some follow-up questions, please.
1. Would it be fair to say that the main reason why you implemented n:m in your instance of Ohana API was to make it easier for users of the admin interface to associate a service with multiple locations?
2. If the answer to #1 is “yes”, why did you choose the n:m solution? Was it the first or perhaps the only one you thought of, or did you try multiple solutions and concluded that n:m was the best one?
3. If you only tried the n:m solution, and if another solution was available that made it easy to achieve the same result, but kept the Ohana API database unchanged, would you use it?
Thanks!
Moncef
I have some follow-up questions, please.
1. Would it be fair to say that the main reason why you implemented n:m in your instance of Ohana API was to make it easier for users of the admin interface to associate a service with multiple locations?
2. If the answer to #1 is “yes”, why did you choose the n:m solution? Was it the first or perhaps the only one you thought of, or did you try multiple solutions and concluded that n:m was the best one?
3. If you only tried the n:m solution, and if another solution was available that made it easy to achieve the same result, but kept the Ohana API database unchanged, would you use it?
Thanks!
Moncef
Rory
Feb 6, 2015, 6:06:58 AM2/6/15
to Moncef Belyamani, OpenRe...@googlegroups.com
More or less yes to all those. Implemented it after users asked for the change and it seems to work.
One thing I'd add though, is that this was also in the context of the search app we were building. Primarily it searches / filters through services, presents them and then the locations (just like in Declan's example). This was the other thing I had in mind.
One thing I'd add though, is that this was also in the context of the search app we were building. Primarily it searches / filters through services, presents them and then the locations (just like in Declan's example). This was the other thing I had in mind.
Carol Wood
Feb 6, 2015, 9:53:49 AM2/6/15
to Moncef Belyamani, openreferral
In our small database, we have 1,230 site records, 1,828 program records, 567 agency records, and 2,480 program at site records - what you are calling availability. Most services are associated with a variety of locations and each location's records show only those services available at that location. If eligibility changes based on that location, we keep track of that as well. Etc.
For comparison purposes, we handle 30,000+ calls, 17,000+ website sessions per year for a population of about 300,000 residing in five counties in rural New York State.
Carol
Carol Wood
Director, 2-1-1 HELPLINE
Institute for Human Services, Inc.
Tel: 607.776.9467 ext. 219
Fax: 607.776.9482
Email: wo...@ihsnet.org
Web: ihsnet.org
Join the Provider mailing list
Comprehensive Information and Referral
Volunteer Clearinghouse & Resource Center
Steuben, Chemung, Allegany, Schuyler & Yates Counties
Tel: 2-1-1 or 1-800-346-2211
Web: 211helpline.org
Twitter: @211helpline
For comparison purposes, we handle 30,000+ calls, 17,000+ website sessions per year for a population of about 300,000 residing in five counties in rural New York State.
Carol
Carol Wood
Director, 2-1-1 HELPLINE
Institute for Human Services, Inc.
Tel: 607.776.9467 ext. 219
Fax: 607.776.9482
Email: wo...@ihsnet.org
Web: ihsnet.org
Join the Provider mailing list
Comprehensive Information and Referral
Volunteer Clearinghouse & Resource Center
Steuben, Chemung, Allegany, Schuyler & Yates Counties
Tel: 2-1-1 or 1-800-346-2211
Web: 211helpline.org
Twitter: @211helpline
Greg Bloom
Feb 19, 2015, 4:14:42 PM2/19/15
to openreferral, openreferra...@googlegroups.com
Hi folks - Thanks to everyone for your patience, and thanks for all those who've shared feedback.
This is the final issue we've been debating before moving spec to version 1.0. To recap again, here is my summary and here is the thread where most of the debate has taken place.
We appear to have reached consensus that the data model should specify a n:m (many to many) relationship between locations and services, with a ServiceAtLocation table for data that is specific to services at particular sites. Declan has proposed an edit to the HSDS schema, visible here: https://docs.google.com/drawings/d/1j9bdhQ1FK56NYJScO9CtglrFSbJIAn3O1ysJxe2u2Gg/edit <- this has received approval from the participants in the discussion so far.
I still want another day to hear from some more folks in our pilot projects. That said, barring new revelations, this decision will be considered made by Monday.
Looking ahead to next Friday (2/27) I'm going to schedule an Assembly for us to behold version 1.0 and discuss what comes next (to be immediately followed by an accompanying conversation among Ohana deployers about what comes next for Ohana). I'll send a standalone email about that, but you can go ahead and indicate your availability for that conversation here: http://doodle.com/hazsih2nnahq6f8p
In the meantime, if anyone has any questions or new comments -- feel free to comment in the document with Declan's proposed change, or even contact me directly at 202.643.3648.
Thanks again for a lively and insightful discussion,
Greg
Reply all
Reply to author
Forward
0 new messages