mean disaggregation

Sujan Raj Adhikari
Sujan Raj Adhikari

Michele Simionato
Sujan Raj Adhikari
Sujan Raj Adhikari
Sujan Raj Adhikari
Michele Simionato
Sujan Raj Adhikari

Merrick Taylor
Does OpenQuake do this?

Gianluca Regina
Merrick Taylor
"DisallowedHost at /public/wix-new-website/pdf-collections-wix/publications/OQ Hazard Science 1.0.pdfInvalid HTTP_HOST header: 'storage-scw1.globalquakemodel.org'. You may need to add 'storage-scw1.globalquakemodel.org' to ALLOWED_HOSTS." etc.

Peter Pažák

Marco Pagani
Merrick,
The problem is now fixed. You should be able to download the documentation at the following link
https://www.globalquakemodel.org/oq-get-started
Marco
--
You received this message because you are subscribed to the Google Groups "OpenQuake Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openquake-use...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openquake-users/09ad982c-8eb8-44ba-b02d-adac8e6a0b03n%40googlegroups.com.
Sujan Raj Adhikari
Merrick Taylor
Gianluca Regina
which provides lots of details on the OQ disaggregation.

Michele Simionato
Michele Simionato
Gianluca Regina
I can see the problem with handling all those files! I was lucky enough to have only 54 realizations (thus 432=54*8 csv files) for 4 POE, which I later post-processed. The way I handled the files, though, was a bit lame, meaning that I performed the analyses one POE at a time, such that I had the results in separate folders. I am unfamiliar with the HDF5 format, but for the csv format I agree that maybe some results could be joined together, but not necessarily per column. For instance, since the POE are usually limited (maybe corresponding to return periods of 2500, 1460, 75, 50 years and so on) you could separate those results per sheet. If only one POE is used, then the csv would have one sheet, and so on. This way, considering the example you illustrated you would have 70000/5 = 14000 files, which is still a huge number, but more manageable. If the number of sites and disaggregation types needed by the user are also low, then this sheet methodology could be also used, but it would fail otherwise, as you would have a csv file with N*P*t sheets (where t is the number of disaggregation types you need). On the other hand, if you have M>P, so more IMTs than POEs, you would have 70000/10 = 7000 files each one with 10 sheets, for M=10.
I do not know if it is possible and how intuitive might be, but maybe the user could have the option to decide how to join the results. In my case, it would have been great to have the results of different POEs in different sheets. Another user maybe would find it more interesting to join them for site (e.g. they only have 1 POE).
I think that a couple of csv files containing the information of ALL the results might be confusing, unless the columns are really well organized. In addition, there is the parsing problem you mentioned.
However, if the mean disaggregation is done internally, there would be no need at all to export all the realizations, unless for verification problems. As it is now, I think is a good compromise, as you divide the total number by R.
Merrick Taylor
For post-processing to determine conditional ground motion intensity parameters (e.g. for conditional spectrum, or conditional CAV, AI, PGV etc), would require Mag_Dist_Eps_TRT, or at least Mag_Dist_TRT (the latter allowing epsilon to be calculated manually for each M-R bin using GMPEs corresponding to the different TRTs). Can this be added to a wish list for the next update to the disaggregation calculator? (it is admittedly beyond my humble coding capability)

Daniel Klassen
Merrick Taylor
The closest I have been able to 'fudge' is to use Lon-Lat-Mag, and Lon-Lat-TRT with a closely spaced Lon-Lat Binning (as close as the deisaggregation calculator will allow, and you may need to limit the maximum distance to get the precision required - in my case I needed to reduce to 200km max distance, even though the calculator happily gave M-R disaggregation to 500km distance) to allow you to manually approximate the M-R disaggregation from Lon-Lat-TRT (through calculating R from the site Lon-Lat and the source Lon-Lat using the Haversine formula). Then do the same for Lon-Lat-TRT with the same distance binning. By comparing the two disaggregation plots you can estimate the % contribution for a particular distance that is from shallow crustal vs subduction slab vs interface. By comparing the two plots, you wont know the exact breakdown by magnitude, and you will have to make some broad assumptions and apply weights based on the contributions reported in the plots e.g. to calculate epsilon manually for each M-R bin, and undertake intensity measure correlations, but it is as close as one can get for now with OpenQuake I believe.
Michele Simionato
Thanks Marco for fixing the link, I have successfully downloaded the document.I realise now from reading your responses, that my question above has confused two aspects related to the disaggregation.1) The way OpenQuake provides disaggregation output. Yes I have also read Damiano Monelli's post to calculate the traditional % contribution. The mean magnitude and distance (or mode) can be determined from this output, per B&C99. As Gianluca advises, this conversion is described in mathematical notation in the hazard science document.2) However, my current issue I am trying to understand/ resolve is that when a GMPE logic tree is adopted, OpenQuake does not calculate the disaggregation from the mean (or some fractal such as the median) hazard curve, but the hazard curve of the realisation closest to the mean. For a non-trivial logic tree (e.g. adopting 3x GMPE for each TRT: shallow crustal, s. slab, s. int) it will not be clear which realisation (i.e. which branch of the logic tree) is selected as being 'closest to the mean', for performing the disaggregation, or how the disaggregation should be calculated (i.e. different GMPE will result in different % contributions, and different epsilon values for the same mean hazard curve - they need to be weighted appropriately to obtain the mean).I presume that one could extract disaggregation data from each realisation (potentially many results for complex logic trees!) and manually calculate weighted contributions for each M, R, epsilon bin across all realisations. It's a bit laborious to do this, and it would be good if there were an option for the OpenQuake engine to provide the option to deliver this output - perhaps a wish list for now. I need to think and learn how I can combine the available disaggregation outputs, e.g. (M, Lat, Lon) & (TRT, Lat, Lon) across all realisations to obtain sufficient information to calculate the required M, R, epsilon statistics where a complex GMPE logic tree is employed.
Sujan Raj Adhikari

Anne Hulsey
Michele Simionato
I third Merrick's request. I think this could be done with a new if clause: "elif key == 'Mag_Dist_TRT' and k == 0:" in the following function: https://github.com/gem/oq-engine/blob/95d5696c8bed50fc65dc267f733a7d8d98ca8e9a/openquake/calculators/disaggregation.py#L427. However, I am not sure how to include Mag_Dist_TRT in the oq.disagg_outputs or where else I might need to include additional modifications.Michele, in response to your question about how I want disaggregation outputs to be exported, I have switched to only using the .h5py as it is easier for handling all the realizations at once. However, there is an extra step to re-establish the original order of the realizations, using the best_rlz dataset. Would it be possible to add something like "all" or NaN as an input for num_rlzs_disagg? This would create a rlz_index from 0 to num_rlz-1, preserving the original order.

Matt Fox

jamal assaf
Sujan Raj Adhikari
Action
13
asujan
disaggregation
MVDisaggregation580_10sites
failed
( failed )
12
asujan
disaggregation
MVDisaggregation250_10sites
complete
2022-03-27T13:51:14.37,INFO,MainProcess/2262,asujan running /home/asujan/openquake/demos/hazard/Canada/OQ580.ini [--hc=None]
2022-03-27T13:51:14.52,INFO,MainProcess/2262,Using engine version 3.11.5
2022-03-27T13:51:15.51,WARNING,MainProcess/2262,Using 4 cores on asujan
2022-03-27T13:51:15.72,INFO,MainProcess/2262,Validated CanadaSHM6trial_W_CANADA_simplified_collapsedRates_source_model_logic_tree.xml in 0.00 seconds
2022-03-27T13:51:15.91,INFO,MainProcess/2262,Checksum of the input files: 374779159
2022-03-27T13:51:16.02,INFO,MainProcess/2262,Reading the risk model if present
2022-03-27T13:51:16.16,INFO,MainProcess/2262,Read N=10 hazard sites and L=440 hazard levels
2022-03-27T13:51:16.38,INFO,MainProcess/2262,Total number of logic tree paths = 4_096
2022-03-27T13:51:16.50,INFO,MainProcess/2262,Reading the source model(s) in parallel
2022-03-27T13:51:17.14,INFO,MainProcess/2262,read_source_model 100% [1 submitted, 0 queued]
2022-03-27T13:51:17.24,INFO,MainProcess/2262,Received {'/home/asujan/openquake/demos/hazard/Canada/CanadaSHM6trial_W_CANADA_simplified_collapsedRates.xml': '92.23 KB'} in 0 seconds
2022-03-27T13:51:17.54,INFO,MainProcess/2262,There are 5 groups and 81 sources with len(et_ids)=1.00
2022-03-27T13:51:17.69,INFO,MainProcess/2262,Checking the sources bounding box
2022-03-27T13:51:17.99,ERROR,MainProcess/2262,source ACMWA: The buffer of 600 km is too large, the bounding box is larger than half the globe: 219 degrees
2022-03-27T13:51:18.27,INFO,MainProcess/2262,Rupture floating factor = 2.92
2022-03-27T13:51:18.38,INFO,MainProcess/2262,Rupture spinning factor = 6.12
2022-03-27T13:51:19.19,INFO,MainProcess/2262,Requiring 1.07 MB for full ProbabilityMap of shape (32, 10, 440)
2022-03-27T13:51:19.28,INFO,MainProcess/2262,Requiring 550 KB for max ProbabilityMap of shape (16, 10, 440)
2022-03-27T13:51:19.46,INFO,MainProcess/2262,Total output size: 94.64 GB
2022-03-27T13:51:19.57,INFO,MainProcess/2262,gzipping the input files
2022-03-27T13:51:19.75,INFO,MainProcess/2262,Sending <SiteCollection with 10/10 sites>
2022-03-27T13:51:21.21,INFO,MainProcess/2262,preclassical 7% [14 submitted, 0 queued]
2022-03-27T13:51:23.11,INFO,MainProcess/2262,preclassical 14% [14 submitted, 0 queued]
2022-03-27T13:51:23.29,INFO,MainProcess/2262,preclassical 21% [14 submitted, 0 queued]
2022-03-27T13:51:23.41,INFO,MainProcess/2262,preclassical 28% [14 submitted, 0 queued]
2022-03-27T13:51:23.53,INFO,MainProcess/2262,preclassical 35% [14 submitted, 0 queued]
2022-03-27T13:51:24.71,INFO,MainProcess/2262,preclassical 42% [14 submitted, 0 queued]
2022-03-27T13:51:25.02,INFO,MainProcess/2262,preclassical 50% [14 submitted, 0 queued]
2022-03-27T13:51:27.07,INFO,MainProcess/2262,preclassical 57% [14 submitted, 0 queued]
2022-03-27T13:51:27.22,INFO,MainProcess/2262,preclassical 64% [14 submitted, 0 queued]
2022-03-27T13:51:44.46,INFO,MainProcess/2262,preclassical 71% [14 submitted, 0 queued]
2022-03-27T13:51:44.97,INFO,MainProcess/2262,preclassical 78% [14 submitted, 0 queued]
2022-03-27T13:51:46.72,INFO,MainProcess/2262,preclassical 85% [14 submitted, 0 queued]
2022-03-27T13:51:52.22,INFO,MainProcess/2262,preclassical 92% [14 submitted, 0 queued]
2022-03-27T13:52:14.27,INFO,MainProcess/2262,preclassical 100% [14 submitted, 0 queued]
2022-03-27T13:52:14.38,INFO,MainProcess/2262,Mean time per core=33s, std=12.1s, min=22s, max=53s
2022-03-27T13:52:14.50,INFO,MainProcess/2262,Received {2: '4.88 MB', 4: '2.66 MB', 1: '84.74 KB', 3: '34.97 KB', 0: '33.92 KB', 'calc_times': '6.85 KB', 'after': '200 B', 'before': '200 B'} in 54 seconds
2022-03-27T13:52:14.73,INFO,MainProcess/2262,tot_weight=22_982_099, max_weight=1_149_104
2022-03-27T13:52:15.07,INFO,MainProcess/2262,Sending 23 tasks
2022-03-27T13:52:15.32,INFO,MainProcess/2262,Sent 4 tasks, 3 MB in 0 seconds
2022-03-27T13:52:15.58,INFO,MainProcess/2262,classical 4% [5 submitted, 18 queued]
2022-03-27T13:52:15.80,INFO,MainProcess/2262,classical 8% [6 submitted, 17 queued]
2022-03-27T13:52:16.00,INFO,MainProcess/2262,classical 13% [7 submitted, 16 queued]
2022-03-27T13:52:16.27,INFO,MainProcess/2262,classical 17% [8 submitted, 15 queued]
2022-03-27T13:54:46.96,INFO,MainProcess/2262,classical 21% [9 submitted, 14 queued]
2022-03-27T13:54:51.44,INFO,MainProcess/2262,classical 26% [10 submitted, 13 queued]
2022-03-27T13:56:28.35,INFO,MainProcess/2262,classical 30% [11 submitted, 12 queued]
2022-03-27T13:56:28.92,INFO,MainProcess/2262,classical 34% [12 submitted, 11 queued]
2022-03-27T13:56:29.07,INFO,MainProcess/2262,classical 39% [13 submitted, 10 queued]
2022-03-27T13:56:29.22,INFO,MainProcess/2262,classical 43% [14 submitted, 9 queued]
2022-03-27T13:56:29.40,INFO,MainProcess/2262,classical 47% [15 submitted, 8 queued]
2022-03-27T14:04:45.58,INFO,MainProcess/2262,classical 52% [16 submitted, 7 queued]
2022-03-27T14:13:49.62,INFO,MainProcess/2262,classical 56% [17 submitted, 6 queued]
2022-03-27T14:46:19.83,INFO,MainProcess/2262,classical 60% [18 submitted, 5 queued]
2022-03-27T17:24:36.25,INFO,MainProcess/2262,classical 65% [19 submitted, 4 queued]
2022-03-27T19:04:42.87,INFO,MainProcess/2262,classical 69% [20 submitted, 3 queued]
2022-03-27T19:15:28.09,INFO,MainProcess/2262,classical 73% [21 submitted, 2 queued]
2022-03-27T19:45:23.00,INFO,MainProcess/2262,classical 78% [22 submitted, 1 queued]
2022-03-27T21:25:03.81,INFO,MainProcess/2262,classical 82% [23 submitted, 0 queued]
2022-03-27T22:20:42.13,INFO,MainProcess/2262,classical 86% [23 submitted, 0 queued]
2022-03-27T22:21:48.74,INFO,MainProcess/2262,classical 91% [23 submitted, 0 queued]
2022-03-27T23:23:52.35,INFO,MainProcess/2262,classical 95% [23 submitted, 0 queued]
2022-03-27T23:30:47.43,INFO,MainProcess/2262,classical 100% [23 submitted, 0 queued]
2022-03-27T23:30:47.58,INFO,MainProcess/2262,Mean time per core=32442s, std=2004.2s, min=30387s, max=34648s
2022-03-27T23:30:47.70,INFO,MainProcess/2262,Received {'rup_data': '1.38 GB', 'pmap': '2 MB', 'calc_times': '7.28 KB', 'extra': '2.35 KB'} in 34712 seconds
2022-03-27T23:30:48.60,INFO,MainProcess/2262,There are 4096 realization(s)
2022-03-27T23:30:48.74,INFO,MainProcess/2262,Storing by_task information
2022-03-27T23:30:48.90,INFO,MainProcess/2262,Total number of contexts: 2_227_301
2022-03-27T23:30:49.04,INFO,MainProcess/2262,Average number of sites per context: 9
2022-03-27T23:30:49.29,INFO,MainProcess/2262,There were 4 slow tasks
2022-03-27T23:30:49.50,INFO,MainProcess/2262,Building hazard statistics
2022-03-27T23:32:12.45,INFO,MainProcess/2262,build_hazard 20% [5 submitted, 0 queued]
2022-03-27T23:32:12.60,INFO,MainProcess/2262,build_hazard 40% [5 submitted, 0 queued]
2022-03-27T23:32:12.74,INFO,MainProcess/2262,build_hazard 60% [5 submitted, 0 queued]
2022-03-27T23:32:12.89,INFO,MainProcess/2262,build_hazard 80% [5 submitted, 0 queued]
2022-03-27T23:32:13.35,INFO,MainProcess/2262,build_hazard 100% [5 submitted, 0 queued]
2022-03-27T23:32:13.48,INFO,MainProcess/2262,Received {'hcurves-rlzs': '139.84 MB', 'hmaps-rlzs': '5.59 MB', 'hcurves-stats': '141.26 KB', 'hmaps-stats': '7.02 KB'} in 83 seconds
2022-03-27T23:32:13.65,INFO,MainProcess/2262,Saving hcurves-rlzs
2022-03-27T23:32:13.84,INFO,MainProcess/2262,Saving hcurves-stats
2022-03-27T23:32:14.00,INFO,MainProcess/2262,Saving hmaps-rlzs
2022-03-27T23:32:14.16,INFO,MainProcess/2262,Saving hmaps-stats
2022-03-27T23:32:14.30,INFO,MainProcess/2262,The maximum hazard map values are {'PGA': 0.45560768, 'PGV': 42.149124, 'SA(0.05)': 0.69512427, 'SA(0.1)': 1.0195059, 'SA(0.2)': 1.053832, 'SA(0.3)': 0.95644706, 'SA(0.5)': 0.6939765, 'SA(1.0)': 0.3944167, 'SA(10.0)': 0.028240083, 'SA(2.0)': 0.24380504, 'SA(5.0)': 0.065096065}
2022-03-27T23:33:30.39,INFO,MainProcess/2262,Reading 2_227_301 ruptures
2022-03-27T23:34:45.61,INFO,MainProcess/2262,Maximum mean_std per task: (M=11) * (G=16) * (U=762_600) * (F=2) * 8 bytes = 2 GB
2022-03-27T23:34:45.75,INFO,MainProcess/2262,Estimated data transfer: 55.35 GB
2022-03-27T23:34:45.91,INFO,MainProcess/2262,Sent 31 tasks, 243.54 MB in 74 seconds
2022-03-27T23:40:57.02,INFO,MainProcess/2262,Received {'tot': '182.83 MB'} in 369 seconds
2022-03-27T23:41:09.06,CRITICAL,MainProcess/2262,
2022-03-27T23:41:32.42,CRITICAL,MainProcess/2262,Traceback (most recent call last): File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_pslinux.py", line 1390, in wrapper return fun(self, *args, **kwargs) File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_pslinux.py", line 1572, in create_time values = self._parse_stat_file() File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_common.py", line 337, in wrapper return fun(self) File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_pslinux.py", line 1429, in _parse_stat_file with open_binary("%s/%s/stat" % (self._procfs_path, self.pid)) as f: File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_pslinux.py", line 187, in open_binary return open(fname, "rb", **kwargs) FileNotFoundError: [Errno 2] No such file or directory: '/proc/2284/stat' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/__init__.py", line 368, in _init self.create_time() File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/__init__.py", line 699, in create_time self._create_time = self._proc.create_time() File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/_pslinux.py", line 1401, in wrapper raise NoSuchProcess(self.pid, self._name) psutil._exceptions.NoSuchProcess: psutil.NoSuchProcess process no longer exists (pid=2284) During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/engine/engine.py", line 261, in run_calc calc.run(exports=exports, **kw) File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/calculators/base.py", line 248, in run self.result = self.execute() File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/calculators/disaggregation.py", line 233, in execute return self.full_disaggregation() File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/calculators/disaggregation.py", line 308, in full_disaggregation return self.compute() File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/calculators/disaggregation.py", line 380, in compute results = smap.reduce(self.agg_result, AccumDict(accum={})) File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/parallel.py", line 827, in reduce return self.submit_all().reduce(agg, acc) File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/parallel.py", line 586, in reduce for result in self: File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/parallel.py", line 575, in __iter__ yield from self._iter() File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/parallel.py", line 554, in _iter memory_rss(pid) for pid in Starmap.pids)) / GB File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/parallel.py", line 554, in <genexpr> memory_rss(pid) for pid in Starmap.pids)) / GB File "/home/asujan/openquake/lib/python3.6/site-packages/openquake/baselib/performance.py", line 110, in memory_rss return psutil.Process(pid).memory_info().rss File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/__init__.py", line 341, in __init__ self._init(pid) File "/home/asujan/openquake/lib/python3.6/site-packages/psutil/__init__.py", line 381, in _init raise NoSuchProcess(pid, None, msg) psutil._exceptions.NoSuchProcess: psutil.NoSuchProcess no process found with pid 2284
Michele Simionato
Sujan Raj Adhikari
Sujan Raj Adhikari
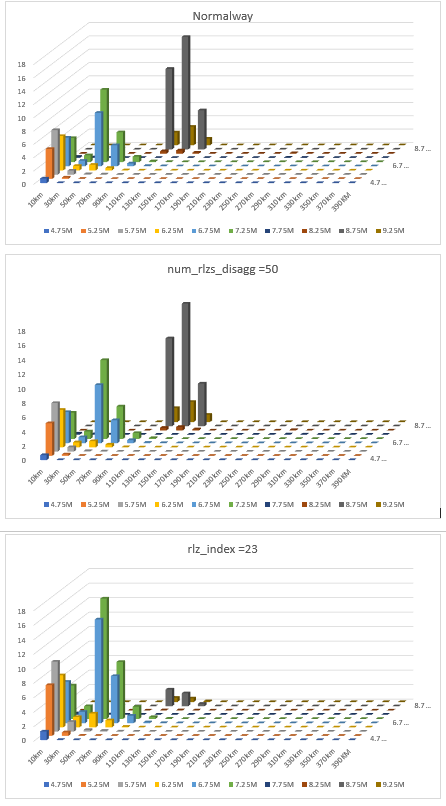
Michele Simionato
Hi Michele and friends,i am running the 3.11.5 engine.Apologies again for bugging you on this topic. I ran disaggregation three times on the same datasets, only modifying the disaggration parameter to understand how the engine calculates true mean disaggregation.The first one I ran in the normal way, as of manual the result is close to mean disaggration (got one file during calculation).The second one i ran assigning num_rlzs_disagg =50, (got 50 file during calculation and the the figure is based on 1 result file).The last one I ran assigning rlz_index =23,24 and got 2 file during the calculation, and the figure is based on 1 result file.Now my question is why figure 1 and 2 are exactly similler (i checked with other couple of (num_rlzs_disagg =50,) files, they are pretty much the same)the last figure is way different.I need your thoughts and comments on these .regardsSujan
Sujan Raj Adhikari
"Setting `num_rlzs_disagg=0` is now valid and it means considering all realizations in a disaggregation calculation"
Michele Simionato
Hi there,i saw new release chainlog and saw
"Setting `num_rlzs_disagg=0` is now valid and it means considering all realizations in a disaggregation calculation"does it means doing this give use the true mean disaggration as same as old versopn of oq 3.2.2.