Develop: new Bottom Vision / Fiducial Locator assignment

ma...@makr.zone
> shouldn't the part bottom vision pipelines be at the "packages" tab
Absolutely, and that's very high on my list.
I'll even go one step further: The pipeline should not be in the package either, but multiple "Bottom Visions" should be defined in the Vision tree:
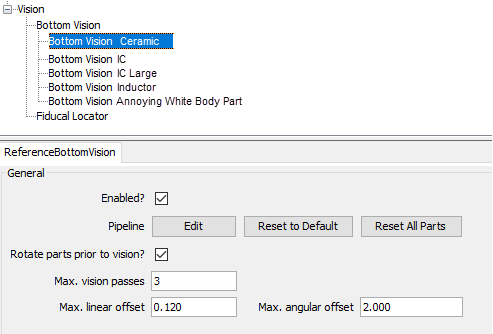
Each Bottom Vision setup would define the settings and pipeline together, optimized for each other (no change from today).
My assumption is, that if done well, you only ever need a handful of different pipeline/alignment setups. One of the setups would be marked as the "Default". Obviously you would define "Default" for the most widely used setup (probably the one for small passives).
In the Package you would then select one of the Bottom Visions setups
from a combo-box, if (and only if) anything other than the "Default" is
needed.
In the Part the same, but with the default given by the Package.
So we get a dynamically inherited assignment: Default -> Package -> Part.
The migration of existing machine.xml would be the most difficult part to implement this. The migration algorithm must group all equal (Pipeline + "Pre-Rotate") settings, create Bottom Vision setups from them,
find the "Default" as the most commonly used one, on both the Machine and
Package level, and assign the non-defaults where they don't match.
Fiducials the same way.
What do you think?
_Mark

bert shivaan
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/c690532c-8c06-4295-9303-5e97adcce4edn%40googlegroups.com.

geo0rpo
geo0rpo

james.edwa...@gmail.com
Hi, Bert. This is a side question from your comment. What is the “canonical” way to find which part (or package) is on the nozzle for the bottom vision pipeline. Do you have a separate pipeline for each package, or is there a way to determine for instance that the current part is a 0402 or a 0603 or …
Thanks a lot, Jim
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNzr3Wf8B84SshROen9sO5C3Sy21UTJ%2BFPp6-vch%2Bh6QEw%40mail.gmail.com.

johanne...@formann.de
ma...@makr.zone
> No tree under Bottom vision.
This is just a mock-up of how it could look in the future.
_Mark
You received this message because you are subscribed to a topic in the Google Groups "OpenPnP" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openpnp/7DeSdX4cFUE/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/b386729c-1f0d-4fdf-9275-b48d6545e00en%40googlegroups.com.

Jason von Nieda
--
ma...@makr.zone
- The first (few) times a part is recognized it would collect statistical info about the vision result and store those per Package, optionally per Part.
- For instance it would record average width/height of a RotatedRectangle that is returned.
- It can observe visions result properties in terms of both average values and variance.
- This could go as far as to record and average expected
template images, i.e. how the part/package is supposed to
look.
- Then after a configurable amount of training, it would start complaining if the vision result is unexpected taking into account the observed variance.
- The settings for this (number of training rounds/level of confidence) would again be configurable on the common Vision setup.
- Future option: while training, it could even interactively ask the user "does this look OK to you?"
How does this sound, Bert?
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNzr3Wf8B84SshROen9sO5C3Sy21UTJ%2BFPp6-vch%2Bh6QEw%40mail.gmail.com.
ma...@makr.zone
> Do you see the pipelines being editable at all at the Part / Package level, or only selectable from the list of defined ones?
This is open for discussion.
Ideal Solution
Ideally Pipelines are not be editable on the
Part/Package level. Maybe I'm mistaken, but I get the impression
that tweaking pipelines is quite hard for the average user anyway.
Each Pipeline typically has a few very specific properties that
need trimming routinely. Thresholds of all sorts, sometimes
dimensions such as mask diameters, min/max feature sizes etc. If I
think about Bottom Vision and Fiducial Locator pipelines, I see
maybe three to six properties per pipeline, or even less if you
have multiple preconfigured setups to choose from.
These properties could be exposed as per Package/per Part
trimming controls. If the body of your IC is shiny, you can trim
the cutoff threshold. If this nearby contact gets mistaken as a
fiducial, trim the mask diameter down.
These trim controls could look like the camera properties in the
OpenPnpCaptureCamera. With an "auto" checkbox (default) and a
slider to tweak.
As seen in the OpenPnpCaptureCamera, a slider can equally control
discreet (boolean) choices. So it should be reasonably easy to
wire stage properties to sliders in a generic way.
Each trim would have a stage name, property name plus a range for
Doubles/Integers (allowed to reverse upper/lower bound to make
some adjustments more intuitive). It could optionally have a
second stage name for the Result image you want to display.
Each trim control change would immediately re-trigger the
transiently cloned and modified pipeline and show the result image
in the camera view. So if you trim a mask diameter, you
immediately see it applied in the pipeline. After a timeout, it
would again display the end result image, hopefully with the
pipeline now nailing the subject.
These trim controls could live inside a new Machine Controls
tabs: So if a vision op fails inside the job, the controls could
become available immediately, without having to navigate to the
Package/Part. A message box where you can choose between "Fail
Vision", "Trim Package Vision" or "Trim Part Vision", perhaps.
I believe this could eventually lead to a level of abstraction,
where we could ship many specific high quality pipelines
with OpenPnP (for "Juki", "Samsung", etc.) and where the need for
users to really dig into them is greatly reduced or eliminated.
Easier Solution
There could be a "clone and adjust" button on both part and
package. It would clone the current (inherited) Vision setup,
assign it to the part/package and enter the Pipeline Editor (as
today). Some clever auto-naming by package or part could take
place.
If the Setup was already cloned earlier (i.e. single Part/Package
assignment), it would just re-open the existing Pipeline instead
of creating another duplicate.
Maybe these ad-hoc setups could be marked as such and be subject
to a mass cleanup routine after the job is done, i.e. to keep the
list tidy. A clone would have to remember the id of the template,
to restore the original assignment in the part/package (including
null to inherit the default), when it is deleted.
_Mark
You received this message because you are subscribed to a topic in the Google Groups "OpenPnP" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openpnp/7DeSdX4cFUE/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jzps8DMvPC8uPxe%3D4AA-6ijOR%2BBZZ85d3aedybKxP0WVA%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/398545fa-1903-aac8-a3dd-5ca9405f0160%40makr.zone.

ozzy_sv
Jim Freeman
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNwz7Ubt4ZyYCEfbO-W6v7G4E4X_3kiNqsJvjPMp_bY5SA%40mail.gmail.com.

Clemens Koller
On 29/01/2021 18.02, ozzy_sv wrote:
> my choice is two way, because some parts behave strangely / differently and for them it is necessary to adjust the piping individually.
MatchTemplate is way more precise, if setup properly.
> But at this stage, I would ask to add the ability to copy the properties of the pipeline to a group of selected parts, since it is tedious to make changes for several tens of resistor values.
However, some could work with groups of parts. In my EDA workflow, I can handle PartNames + Values + Footprints + ... each separately. They are all stored in a MariaDB database. I am even thinking to store the Vision Pipelines with the Parts in the database, where
they could be handled automatically when I create a 4.7k R-1005M Resistor from a 1k one.
Clemens
On 29/01/2021 18.02, ozzy_sv wrote:
> my choice is two way, because some parts behave strangely / differently and for them it is necessary to adjust the piping individually.
> But at this stage, I would ask to add the ability to copy the properties of the pipeline to a group of selected parts, since it is tedious to make changes for several tens of resistor values.
>
> пятница, 29 января 2021 г. в 19:41:57 UTC+3, ma...@makr.zone:
>
> This is open for discussion.
>
>
> Ideally Pipelines are *not *be editable on the Part/Package level. Maybe I'm mistaken, but I get the impression that tweaking pipelines is quite hard for the average user anyway.
> Each Pipeline typically has a few very specific properties that need trimming routinely. Thresholds of all sorts, sometimes dimensions such as mask diameters, min/max feature sizes etc. If I think about Bottom Vision and Fiducial Locator pipelines, I see maybe three to six properties per pipeline, or even less if you have multiple preconfigured setups to choose from.
>
> These properties could be exposed as per Package/per Part trimming controls. If the body of your IC is shiny, you can trim the cutoff threshold. If this nearby contact gets mistaken as a fiducial, trim the mask diameter down.
>
> These trim controls could look like the camera properties in the OpenPnpCaptureCamera. With an "auto" checkbox (default) and a slider to tweak.
>
> As seen in the OpenPnpCaptureCamera, a slider can equally control discreet (boolean) choices. So it should be reasonably easy to wire stage properties to sliders in a generic way.
>
> Each trim would have a stage name, property name plus a range for Doubles/Integers (allowed to reverse upper/lower bound to make some adjustments more intuitive). It could optionally have a second stage name for the Result image you want to display.
>
> Each trim control change would immediately re-trigger the transiently cloned and modified pipeline and show the result image in the camera view. So if you trim a mask diameter, you immediately see it applied in the pipeline. After a timeout, it would again display the end result image, hopefully with the pipeline now nailing the subject.
>
> These trim controls could live inside a new Machine Controls tabs: So if a vision op fails inside the job, the controls could become available immediately, without having to navigate to the Package/Part. A message box where you can choose between "Fail Vision", "Trim Package Vision" or "Trim Part Vision", perhaps.
>
>
> *
> *
>
> *Easier Solution*
> There could be a "clone and adjust" button on both part and package. It would clone the current (inherited) Vision setup, assign it to the part/package and enter the Pipeline Editor (as today). Some clever auto-naming by package or part could take place.
>
> If the Setup was already cloned earlier (i.e. single Part/Package assignment), it would just re-open the existing Pipeline instead of creating another duplicate.
>
> Maybe these ad-hoc setups could be marked as such and be subject to a mass cleanup routine after the job is done, i.e. to keep the list tidy. A clone would have to remember the id of the template, to restore the original assignment in the part/package (including null to inherit the default), when it is deleted.
>
> _Mark
>
> Am 29.01.2021 um 16:12 schrieb Jason von Nieda:
>> Hi Mark,
>>
>> Thanks for diving into this. I have a bunch of thoughts on it, but let me start with one (okay two) question: Do you see the pipelines being editable at all at the Part / Package level, or only selectable from the list of defined ones? And since I suspect the answer is "No", I'd ask what the workflow would look like if someone is running a job and one particular part just keeps acting weird. Do they create a new pipeline in the Machine Setup and then select it for the part?
>>
>> Thanks,
>> Jason
>>
>>
>> On Fri, Jan 29, 2021 at 7:00 AM ma...@makr.zone <ma...@makr.zone> wrote:
>>
>> Hi everybody
>>
>>
>> *This is my take of things, if you think that's a bad idea, please speak up:*
>>
>> /> s//houldn't the part bottom vision pipelines be at the "packages" tab/
>> Absolutely, and that's very high on my list.
>>
>> I'll even go one step further: The pipeline should not be in the package either, but multiple "Bottom Visions" should be defined in the Vision tree:
>>
>>
>> Each Bottom Vision setup would define the settings and pipeline together, optimized for each other (no change from today).
>>
>> My assumption is, that if done well, you only ever need a handful of different pipeline/alignment setups. One of the setups would be marked as the "Default". Obviously you would define "Default" for the most widely used setup (probably the one for small passives).
>>
>> In the Package you would then select one of the Bottom Visions setups from a combo-box, if (and only if) anything other than the "Default" is needed.
>>
>> In the Part the same, but with the default given by the Package.
>>
>> So we get a dynamically inherited assignment: Default -> Package -> Part.
>>
>> The migration of existing machine.xml would be the most difficult part to implement this. The migration algorithm must group all equal (Pipeline + "Pre-Rotate") settings, create Bottom Vision setups from them, find the "Default" as the most commonly used one, on both the Machine and Package level, and assign the non-defaults where they don't match.
>>
>> Fiducials the same way.
>>
>> What do you think?
>>
>> _Mark
>>
>> --
>> You received this message because you are subscribed to the Google Groups "OpenPnP" group.
>> To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
>> --
>> You received this message because you are subscribed to a topic in the Google Groups "OpenPnP" group.
> --
> You received this message because you are subscribed to the Google Groups "OpenPnP" group.
> To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/1c4816a7-b59f-483a-8349-40fd1e179d62n%40googlegroups.com <https://groups.google.com/d/msgid/openpnp/1c4816a7-b59f-483a-8349-40fd1e179d62n%40googlegroups.com?utm_medium=email&utm_source=footer>.
ma...@makr.zone
In some default pipeline there is a Canny Edge detection in front
of HoughCircleDetection. But HoughCircleDetection has its own
built-in Canny edge detection. The double Canny leads to doubling
of the edges. The circles will therefore "wobble" between the
doubled edges. This should be fixed but my time is limited :)
_Mark
Jason von Nieda
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/398545fa-1903-aac8-a3dd-5ca9405f0160%40makr.zone.
Clemens Koller
On 29/01/2021 20.38, ma...@makr.zone wrote:
> /> HoughCircleDetection //
> In some default pipeline there is a Canny Edge detection in front of HoughCircleDetection.
> But HoughCircleDetection has its own built-in Canny edge detection. The double Canny leads to doubling of the edges. The circles will therefore "wobble" between the doubled edges. This should be fixed but my time is limited :)
I am talking about the performance of the (latest-test build) DetectCirclesHough CvStage. I am on OpenCV 4.3.0 or 4.5.1.
I personally wish to be able to use a standalone Hough-Transform and deal with the Hough-Space manually. Off course it is necessary to understand what the Hough-Transform mathematically does!
Usually, a Hough-Transform on its own should achieve superb sub-pixel resolution and precision (depending of the amount of features in the image to transform) if exercised properly. But in our case, I see a jitter of several pixels in the position detected.
I might have to have a closer look into this after some assembly is done. It might be an idea to play around with the dp value, which seems to be directly fed to the Imgproc.HoughCircles().
A good explanation of the parametes are here: https://dsp.stackexchange.com/questions/22648/in-opecv-function-hough-circles-how-does-parameter-1-and-2-affect-circle-detecti
(I did not yet focus on computational efficiency... that's a different story.)
In the meanwhile, I can stick to MatchTemplate, which is way more precise than the Hough*Stuff for what I need (i.e. nozzle tip calibration).
Clemens
On 29/01/2021 20.38, ma...@makr.zone wrote:
> /> HoughCircleDetection //
> /
ma...@makr.zone
I agree, I see that jitter too, despite having cleaned up the
pipeline stages. It seems to exist on a pixel level so I assume it
is some kind of "rounding" artifact. It never bothered me in real
applications, my camera resolution is too high.
I leave that to you!
_Mark
ma...@makr.zone
Hi Jason
Your explanations make a lot of sense, though I have some remarks:
- I agree to almost everything, therefore consider us mostly on
the same page. :)
- I can see how it makes sense to encapsulate single jobs in a
large manufacturing environment. But I would argue that most of
us users are still not in that environment. For true DIY users
you would probably want to carry your adjustments into the next
job and not start from scratch each time. If you have a
prototyping shop, you might want to encapsulate the project, but
not the job of that particular prototype revision, so again,
tweaked settings would carry into the next job of that project
(but not into other projects). So I think the unit of
encapsulation should be determinable by the user.
- I would suggest a simple "Database" approach. A database would
contain Parts and Packages. It could be as simple as a
sub-directory. The user could Open.., Safe, Close, Safe as...
the database.
- A job has an association with the database. If you open the
job, it will automatically open the right database. If none is
assigned yet, it would associate itself with the current
Database. If none is open, it could trigger the Open.. dialog.
You can reassign a job, by Opening another database, while the
job is loaded. You can make an existing database job specific,
by Saving it as a new database.
- A global setting could make job specific databases the
standard and perhaps make it so that the files of job, parts and
packages are saved side-by-side with the job name as a common
prefix. You could then save the bunch on a cloud drive etc.
- I agree that Part and Package specific Pipelines, or vision
parameters should be saved in the Parts, Packages i.e. in the
database.
- I do not agree that all the Pipelines, or vision parameters,
should automatically be copied to the Parts and Packages and no
longer inherit defaults (your point 1). If such a "snapshot" is
really needed, it should be made a deliberate user action
"Freeze all part and package visions settings".
- Personally, I am very confident, that I can make my pipelines
fool-proof and I will never clone them on a package or part
level (just assign them by reference, maybe trim some values).
- For my situation (and I think this would be the same for many
users), if a pipeline has to be modified, it is probably due to
a global change, like when I finally replace that
crappy LED ring with a better one, or when the OpenPnP version
evolves and has better stages, or when I bought parts that look
differently. I would absolutely hate the maintenance nightmare
of not being able to evolve a handful of pipelines centrally.
- One tough nut, you postponed "I have an idea of how this works for feeders, but let's not get into it for now"...
- I do see difficult feeder to part association problems, once
we have multiple databases. The feeders remain physically loaded
on the machine. But if the part in the feeder vanishes because I
load a different database, OpenPnP has a problem.
- We have some slot feeders etc. but in most DIY/prototyping
environments we don't have these job specific feeder trolleys
where you can afford to reserve ten-thousands of dollars worth
of feeders and parts for one job alone and dock the trolley into
the machine whenever you work on that particular job.
- The only solution I see at the moment would drag missing Parts
and Packages referenced from Feeders over into any new database
that OpenPnP touches. This also means that OpenPnP would always
have to remember what database it had loaded before. And it
would have a problem, if that database vanished...
_Mark
Hi Mark,
Here are some rough, quick thoughts. This is a topic I'd like to really dive into because it's starting to approach the stuff I'm really interested in changing in OpenPnP. So, some quick thoughts now to move the conversation along and then we can dig in more as we reach consensus:
To start with, a recap of my "vision": I eventually want to get to the point where a job is entirely self contained with regards to parts and packages. Changing some properties of a part when running job A should not have an effect when running job B. I know this is somewhat controversial, but this is based on real world experience of hundreds of hours of job setup and thousands of hours of machine operation.
Once a job works correctly, you want it to work like that every time you load it. Job setup and machine operation are often performed by different people. The operator will likely have to make tweaks as a job runs for the first production run, and it's critical they can do that while knowing they aren't blowing up their other jobs. Oftentimes those tweaks will not be "good". They are going to make little tweaks based on what is going on that day and it's highly likely those tweaks are not applicable to another job, even for the same part. We can wish that the operator will give deep thought to every change they make, but that is not the reality when deadlines approach.
An example of this is some of the recent issues with feeders and deleted parts. This should never happen. If one person comes along and deletes a part because they think it's not being used, or they are sick of the clutter, and that breaks another job, that is a bad result.
So, with that out of the way:
- Pipelines, or vision parameters, should ultimately move into the job file, along with part, package, (I have an idea of how this works for feeders, but let's not get into it for now)
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jyjV9XwZ2JxicqU-_cmHutt7Vpff0SenMESZ%3D0A9GZkQA%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/2854b455-2850-68da-d467-d73595a7ebf9%40makr.zone.
ma...@makr.zone
See points 2 and 8.
_Mark
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNxE96pXhr_O1dFhHPHziDO7UXBgNGk%3Dr0gMq4OEbUg08w%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/0bf7139e-1518-0f45-3ffd-efd245d73b4f%40makr.zone.

John Plocher
One of the setups would be marked as the "Default". Obviously you would define "Default" for the most widely used setup (probably the one for small passives).
- Packages by themselves have a strong affinity to vision pipelines, with variations possibly coming into play for individual components (consider a 0603 package, with R,C,L, black body, blue body, tan body...)
- Generalizations are important. There should be (if possible) a single pipeline for "small rectangular passives" instead of a dozen specialized pipelines for [0805, 0603, 0402, 0201] X [R,C,L]
- (That may mean smartness in the generic pipeline that can identify and use those specialized sub-cases, but don't unnecessarily expose them to the job operator!)
- There is a finite and bounded set of required pipelines needed to support the vast majority of jobs, probably on the order of a dozen or less
- Packages and BOMs used between jobs may be based on the same component library (and thus share learnings...), or may not (at which point, any previous learnings are invalid)
- Consider a color sensitive pipeline with Job 1's R/0805 using grungy old stock black resistors, and job 2's R/0805 using automotive grade blue resistors...
ma...@makr.zone
Hi John
Thanks for the feedback. I'm very interested in practical experiences and therefore I'd like to ask some questions back:
So far I keep being surprised that custom pipelines are such an
issue. The usual pipeline uses the contacts to recognize the part,
whether those are pins, pads or balls, they are typically metal
and shiny, so if you have your proper diffusor in from of the
camera, the contacts will create nice bright reflective spots. It
is true that I haven't worked with a wide variety of parts yet,
but so far I only ever defined one pipeline and it worked without
individual tweaking for all parts, from the smallest passive to
the largest IC I have. The body of a part is completely
irrelevant, I have bright white ceramic, brown ceramic, black
matte plastic, ... everything is clearly less bright than
contacts. So I'm really surprised if you say we have to account
for different body colors.
Again, my experience is severely limited, so I'm really
interested what the practical issues are.
Sometimes I wonder if people have their camera exposure too high.
My camera image is quite dark for human perception, the dynamic
range must cover the contacts' reflections, so they can be
properly discriminated, there must be no clipping
even for the shiniest contacts.
https://github.com/openpnp/openpnp/wiki/Bottom-Vision#tips
_Mark
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CAKFrcko0WoEoYOevu4B6OOX5Moa8Pdaa2Yqac2HF0JN1mPPN-g%40mail.gmail.com.
Jason von Nieda
Hi Jason
Your explanations make a lot of sense, though I have some remarks:
- I agree to almost everything, therefore consider us mostly on the same page. :)
- I can see how it makes sense to encapsulate single jobs in a large manufacturing environment. But I would argue that most of us users are still not in that environment. For true DIY users you would probably want to carry your adjustments into the next job and not start from scratch each time. If you have a prototyping shop, you might want to encapsulate the project, but not the job of that particular prototype revision, so again, tweaked settings would carry into the next job of that project (but not into other projects). So I think the unit of encapsulation should be determinable by the user.
- I would suggest a simple "Database" approach. A database would contain Parts and Packages. It could be as simple as a sub-directory. The user could Open.., Safe, Close, Safe as... the database.
- A job has an association with the database. If you open the job, it will automatically open the right database. If none is assigned yet, it would associate itself with the current Database. If none is open, it could trigger the Open.. dialog. You can reassign a job, by Opening another database, while the job is loaded. You can make an existing database job specific, by Saving it as a new database.
- A global setting could make job specific databases the standard and perhaps make it so that the files of job, parts and packages are saved side-by-side with the job name as a common prefix. You could then save the bunch on a cloud drive etc.
- I agree that Part and Package specific Pipelines, or vision parameters should be saved in the Parts, Packages i.e. in the database.
- I do not agree that all the Pipelines, or vision parameters, should automatically be copied to the Parts and Packages and no longer inherit defaults (your point 1). If such a "snapshot" is really needed, it should be made a deliberate user action "Freeze all part and package visions settings".
- Personally, I am very confident, that I can make my pipelines fool-proof and I will never clone them on a package or part level (just assign them by reference, maybe trim some values).
- For my situation (and I think this would be the same for many users), if a pipeline has to be modified, it is probably due to a global change, like when I finally replace that crappy LED ring with a better one, or when the OpenPnP version evolves and has better stages, or when I bought parts that look differently. I would absolutely hate the maintenance nightmare of not being able to evolve a handful of pipelines centrally.
- One tough nut, you postponed "I have an idea of how this works for feeders, but let's not get into it for now"...
- I do see difficult feeder to part association problems, once we have multiple databases. The feeders remain physically loaded on the machine. But if the part in the feeder vanishes because I load a different database, OpenPnP has a problem.
- We have some slot feeders etc. but in most DIY/prototyping environments we don't have these job specific feeder trolleys where you can afford to reserve ten-thousands of dollars worth of feeders and parts for one job alone and dock the trolley into the machine whenever you work on that particular job.
- The only solution I see at the moment would drag missing Parts and Packages referenced from Feeders over into any new database that OpenPnP touches. This also means that OpenPnP would always have to remember what database it had loaded before. And it would have a problem, if that database vanished...
_Mark
Am 29.01.2021 um 21:11 schrieb Jason von Nieda:
Hi Mark,You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/398545fa-1903-aac8-a3dd-5ca9405f0160%40makr.zone.
--
You received this message because you are subscribed to a topic in the Google Groups "OpenPnP" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/openpnp/7DeSdX4cFUE/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jyjV9XwZ2JxicqU-_cmHutt7Vpff0SenMESZ%3D0A9GZkQA%40mail.gmail.com.
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/2854b455-2850-68da-d467-d73595a7ebf9%40makr.zone.
John Plocher
Hi John
Thanks for the feedback. I'm very interested in practical experiences and therefore I'd like to ask some questions back:
So far I keep being surprised that custom pipelines are such an issue. The usual pipeline uses the contacts to recognize the part, whether those are pins, pads or balls, they are typically metal and shiny, so if you have your proper diffusor in from of the camera, the contacts will create nice bright reflective spots. It is true that I haven't worked with a wide variety of parts yet, but so far I only ever defined one pipeline and it worked without individual tweaking for all parts, from the smallest passive to the largest IC I have. The body of a part is completely irrelevant, I have bright white ceramic, brown ceramic, black matte plastic, ... everything is clearly less bright than contacts. So I'm really surprised if you say we have to account for different body colors.
OpenPnP has the idea of pipelines that encompass a bunch of, let's say, basic optical functionality and cleanup issues. They also handle (in conjunction with other stuff) package identification/recognition, component rotation/alignment, polarity and verification. (Maybe we need different words here instead of overloading 'pipeline', but you get the point...)That former thing should be considered basic hygiene, and squarely within the realm of the machine creator to get right. That is, if your lights don't illuminate correctly, if your camera isn't calibrated or doesn't have good depth of field or ... yadda ... , your machine and its pipelines aren't ready for "production" use, and nothing built on top of those pipelines will ever work well.The latter assumes that the basic camera/vision/pipeline functionality just works, and that it can be used as a foundation for higher level services, such as OCR and QR recognition, tombstone detection, polarity detection, rotation/alignment, etc. These high level features will depend on underlying pipelines - and they may extend them with additional stages that encompass their own custom functionality...The machines I've used don't expose many "pipeline setup" details to the operator (other than as part of machine calibration/verification...).
Operators are exposed (as a list to choose from) as part of the BOM import/job setup process - the idea being that the operator is given a small set of predetermined functionality to choose from. Changing and tuning the machine's underlying configuration is a job for the tech/engineer/machine owner....
Much of this thread feels like machine design stuff, and not operator stuff. That's OK, just don't conflate the two too much :-) One of the Chinesium Software hell comes from poor choices in that differentiation - too much, not enough, ... Hopefully OpenPnP will evolve to "just right" :-)
Again, my experience is severely limited, so I'm really interested what the practical issues are.
Sometimes I wonder if people have their camera exposure too high. My camera image is quite dark for human perception, the dynamic range must cover the contacts' reflections, so they can be properly discriminated, there must be no clipping even for the shiniest contacts.
John Plocher
It is important that we remember that OpenPnP is not just for DIY.
- I would suggest a simple "Database" approach. A database would contain Parts and Packages.
- Customers generally provide
- Boards (physical pcbs fab'd from some CAD system design)
- BOMs (a list of the components that go on a Board - Centroids, partID, [value, package], x, y, rotation....)
- A Fab operation generally provides
- Inventory (a logical source of available components, indexed by [value, package])
- Many Inventories have more items than can fit in the available Feeders,
- the same item may be available in more than one Feeder, and
- many different Inventory items may map to a single [value, package] component (e.g., 2k2, 2K2, 2.2K, 2200, 2K...)
- Feeders (a physical source for components in my inventory - reels, strips, trays, yadda that can be matched to the [value, package] tuple found in the Inventory).
- Machine (a device that can access a set of feeders, Boards and nozzles),
- Job Definition (a file that pulls all these together)
- Produced by an "operator", combines a customer's artifacts with the fab operation's capacity
- creating a Job definition: importing a BOM, choosing components from my Inventory, associating it with a Machine, and selecting which Feeders and nozzles I wish to use, and
- running a job: importing a Job definition, mounting the "Feeders" in the Machine as per the job's requirements, calibrating everything, then cycling thru placing components on a set of Boards
I think we may have different ideas of simple :) That sounds like a lot of mental load to me, although I don't think we're too far off from agreeing. In my mind, the job "database" is just the part information embedded in the job. Just to reiterate, I very much want to get to a single file job. No more board.xml, no more dependency on parts.xml or packages.xml. All of that information is in the job. An entire OpenPnP setup to run a job should consist of machine.xml and job.xml. The job is self-contained and includes everything it needs to run - it just needs hardware (machine.xml) to run on.
For what it's worth, in the production shop I work in, we reload most of the feeders for each job, or move around the ones that are already loaded with a part we're going to use. Here's a concrete example that I think actually applies very well to DIY:- I've just finished job A, so the machine is set up for job A and the feeders are all loaded with parts for job A.- It's time to set up job B. I go through the loaded feeders and remove any that aren't in job B, and move the ones that are into the correct slots if they are different.- I unload the extraneous feeders, and reload them with parts for job B, and put them back on the machine.
bert shivaan
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CAKFrckr_MyHyUYGs8UyNR_fpT7szJnqREakVQJHYNuzjWDj_ig%40mail.gmail.com.
ma...@makr.zone
Hi Jason
I'm a bit confused now. :-)
- On one hand you describe this central database with an "authoritative set of parameters", push pull capability, etc. that I assume can even go across multiple machines and certainly across jobs.
- On the other hand you proclaim "no more dependency on
parts.xml or packages.xml".
How do these two go together??
I certainly embrace the first goal, but I don't see how that
second goal can ever be achieved (at least before we all have
these feeder trolleys ;-).
> The [info] that should be copied into the parts /
packages is not the pipeline, but the trimmable values.
Good to know. In fact, may I offer another variant?
- Parts, Packages are still global and separate from jobs. They
only have the canonical Vision setup assigned.
- The trimmable values would live inside the job as job
specific Part/Package tweaks (lookup table).
Personally, I would still want them to have inheritance. I still
believe that most adjustments needed in DIY are global and
permanent. But we can have a "freeze in job" option for those that
want it.
> The resulting trimmable settings should be stored with the part, not the package. I don't think we need another layer of abstraction here. I still want to eventually merge part and most of package.
I agree, not another layer of abstraction, but please reconsider to merge the other way around! All settings to the package, nothing on the part. Even my DIY project has 34 parts on the R0402 package, they all look perfectly the same. I don't want to trim 34 sliders when one vision property is wrong! ;-)
If one part is special, clone the assigned package and tweak it.
We can provide a one-click function on the part for that, and we
could optionally make it permanent, i.e. not to be overwritten in
the next ECAD import.
> I go through the loaded feeders and remove any that aren't in job B, and move the ones that are into the correct slots if they are different.
I still believe that DIY and prototyping users have a much more
continuous usage of their feeders. The most likely scenario are a
handful of evolving projects and products created with the same
ECAD tools and libraries. The same engineer(s) doing things in
similar ways each time, using proven parts and sub-circuits.
Agreed, that's completely different from the assembly shop that
does contract work for hundreds of customers. But I really hope
OpenPnP will never abandon us hobbyists and prototypers. <:-/
Yes there still those that user StripFeeders and simlar... I
think it speaks for itself.
Most DIY feeders that are slot feeders in theory frankly don't
look like they're quickly replaced or moved. Even those that have
pro feeders can't usually afford to buy a feeder for each part and
they will have to unload/reload reels. Judging from some videos,
this is also no snap.
And unlike in pro shops, the changeover is not for a Million-PCBs
run, but for a few PCBs, so it must be doable in reasonable time.
All this leads to a strategy that will do everything to
keep as many feeders mounted and in place as possible. I really
strongly believe OpenPnP must continue to support this workflow
nicely.
_Mark
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jwLmpabpFSVbD0kNDjqRrXn9d4Y2s0Pvr_77Z_fZb3X9Q%40mail.gmail.com.
John Plocher
Hi Jason
I'm a bit confused now. :-)
- On one hand you describe this central database with an "authoritative set of parameters", push pull capability, etc. that I assume can even go across multiple machines and certainly across jobs.
- On the other hand you proclaim "no more dependency on parts.xml or packages.xml".
How do these two go together??
Jason von Nieda
Hi Jason
I'm a bit confused now. :-)
- On one hand you describe this central database with an "authoritative set of parameters", push pull capability, etc. that I assume can even go across multiple machines and certainly across jobs.
- On the other hand you proclaim "no more dependency on parts.xml or packages.xml".
How do these two go together??
I certainly embrace the first goal, but I don't see how that second goal can ever be achieved (at least before we all have these feeder trolleys ;-).
> The [info] that should be copied into the parts / packages is not the pipeline, but the trimmable values.
Good to know. In fact, may I offer another variant?
- Parts, Packages are still global and separate from jobs. They only have the canonical Vision setup assigned.
- The trimmable values would live inside the job as job specific Part/Package tweaks (lookup table).
Personally, I would still want them to have inheritance. I still believe that most adjustments needed in DIY are global and permanent. But we can have a "freeze in job" option for those that want it.
> The resulting trimmable settings should be stored with the part, not the package. I don't think we need another layer of abstraction here. I still want to eventually merge part and most of package.
I agree, not another layer of abstraction, but please reconsider to merge the other way around! All settings to the package, nothing on the part. Even my DIY project has 34 parts on the R0402 package, they all look perfectly the same. I don't want to trim 34 sliders when one vision property is wrong! ;-)
If one part is special, clone the assigned package and tweak it. We can provide a one-click function on the part for that, and we could optionally make it permanent, i.e. not to be overwritten in the next ECAD import.
> I go through the loaded feeders and remove any that aren't in job B, and move the ones that are into the correct slots if they are different.
I still believe that DIY and prototyping users have a much more continuous usage of their feeders. The most likely scenario are a handful of evolving projects and products created with the same ECAD tools and libraries. The same engineer(s) doing things in similar ways each time, using proven parts and sub-circuits. Agreed, that's completely different from the assembly shop that does contract work for hundreds of customers. But I really hope OpenPnP will never abandon us hobbyists and prototypers. <:-/
Yes there still those that user StripFeeders and simlar... I think it speaks for itself.
Most DIY feeders that are slot feeders in theory frankly don't look like they're quickly replaced or moved. Even those that have pro feeders can't usually afford to buy a feeder for each part and they will have to unload/reload reels. Judging from some videos, this is also no snap.
And unlike in pro shops, the changeover is not for a Million-PCBs run, but for a few PCBs, so it must be doable in reasonable time.
All this leads to a strategy that will do everything to keep as many feeders mounted and in place as possible. I really strongly believe OpenPnP must continue to support this workflow nicely.
Jason von Nieda
I took this to mean that as part of OpenPnP's job file creation process, the contents of the parts, packages and BOM/Centroid files were smartly merged together into a single "Job" file, such that the Job file became a stand alone item that contained everything necessary to run a Job on a machine that has a tuned and working machine.xml file. You would bring a zip stick with myjob.xml on it, and would not need to include any parts.xml or packages.xml "library" files as well to make use of it...
ma...@makr.zone
Hi Jason
(I really hope, this does not sound offending in any way. If it
does, please be assured it was not meant so! )
Now I understand, you want to redundantly copy everything into
jobs. Kind of like Eagle copies library parts/footprints into the
board/schematic.
John said:
> For me, the key is the ability to manage a parts
inventory independently from the Jobs - and to be able to have
existing Jobs take advantage of future changes to my
Inventory.
That would be absolutely essential for me too and it must be easy
and fast to use. But ...
Begin Advocatus
Diaboli.
So we'd have two Part and Package tabs, one central, one job
oriented? Or two separate executables, one for operation and setup
and one for library maintenance (like in those programs from the
Eighties)? Plus we need an "update parts from central"
functionality, and "push parts back to central"?
So the OpenPnP group would soon overflow with messages like: "Oh
no, I pushed the outdated footprints from that job I resurrected
from 2015 and overwrote central!", "Darn, I should have only
pulled in the new package (part?) nozzle tip
compatibilities, but left the job's custom vision trims alone,
now everything is overwritten. It took me two day to get those
right!".
To make this work without too much pain, you'd need full-fledged
three-way versioning between each job and the central database, so
you could push or pull only the changed and parts and attributes.
You's need conflict resolution, if the same parts/attributes were
changed on both sides. For cloud operation you'd also need very
far-reaching version independence both ways, no more "I don't
know this new attribute, so I give up" XML stubbornness.
We'd need super-complex push-pull dialogs where you can determine
which attributes to actually sync and which parts/packages to
include. And you'd still suffer from consequences when you didn't
think of that dependency between two attributes, or that
update of the database two weeks ago...
I agree that this would open many new possibilities, like sharing
part/package settings across very different machines and camera
setups. But it's one hell of an endeavor to develop. And it's
necessary complex to use (at least if you want it to be both safe
+ work efficient).
End Advocatus Diaboli.
IMHO, in comparison, the multiple Database approach does not
sound so complicated and frightening after all.
You can have multiple databases to reflect multiple sequential or parallel "evolutions" of your workflow. This "evolution" also reflects the OpenPnP version i.e. the capabilities/settings a version has at a time. You can let a job ride on the newest database, kind of like it is now common in software development with continuous integration. Or you can create a project/customer specific database to encapsulate it from other, completely different projects/customers. So it still evolves, but only when that project proceeds/customer orders, and as a separate "species". Or you can create a job "time capsule" with a momentary snapshot of your database (like I said this could be made into a self-contained file bundle). One day you might decide to bring that job back "to the future". You can, because you can re-associate it with an evolved database. But that would then be an all-or-nothing (you can't travel backwards in time). If you see it's too much work, you can choose a less far evolved database perhaps, or give up and connect it back to that old time capsule database, without ever overwriting or losing something. The only thing we'd do, is cloning missing parts/packages over into a newly associated database, i.e. purely non-destructive.
And it could be developed in sensible time.
Some of these databases could be cloud based. Communities could
form around a specific database (they'd all have to run the right
OpenPnP version). Backup/restore, versioning, sending in, etc. are
all straight-forward. Databases are just files/directories.
>> Even my DIY project has 34 parts on the R0402
package, they all look perfectly the same. I don't want to trim
34 sliders when one vision property is wrong! ;-)
> Is this your experience in practice? It isn't mine. A heavy 10uF 0805 responds very differently to speed, acceleration, vacuum pressure, etc. than a super light 0.1uF 0805.
Yes, I would say that is my experience (how "practical" it really is, is another question). My parts all look essentially the same per footprint. For the capacitor example you used, I know, because I actually wrote a small script in Eagle to automatically select the package based on capacitance and max voltage. I looked a Digikey and there is a very clear association between capacitance/voltage and footprint (at price). These parts grow in all dimensions, not just Z ;-). I guess part manufacturing is also easiest, when everything remains the same per package. This page even suggests its standardized:
Going beyond capacitors, packages are often already discriminated
in the ECAD. They're a different package, if they need that extra
cooling or mounting pad, or the extra pad clearance for higher
voltage, for example (all real world examples out of my project).
Increasingly, ECAD software also maintains 3D data, which further
drives package discrimination. Parts that are more "3D" and heavy
like inductors have proprietary footprints anyways. Admittedly, I
never planned with those tall electrolytic capacitors.
So 99 out of 100 times I would be quite confident that all parts
of a package can be handled in completely the same way by OpenPnP.
For the remaining 1% of the cases, I can clone-and-assign an extra
package in OpenPnP.
And for the next project I import, I don't want to go check which
of the R0402 are new, and config them from scratch.
I'm a bit surprised here. Is it really done like that in the pro
softwares you used?
Finally, I should also say, I was not the one advocating to put all the settings on one object, either Part or Package. I was fine with a dynamic inheritance. Set defaults globally, inherit to package. Override on the package, inherit to part. Override on the part, inherit to Part in Job. Override on Part in Job.
This may sound very complicated, but in fact the GUI could always
look exactly the same, users would just chose on what level to
override.
_Mark
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jwPZ9YXLcevZJJc8Xb1qKq_%3D1Ecb3%3DDMMuSPHcc%2BgaN-Q%40mail.gmail.com.
John Plocher
Jason von Nieda
Just a quick Sunday Morning comment:Just like with eCAD systems, where I have NO DESIRE to use someone else's "unvalidated by me" footprints, I believe the same will be true here.Having a Cloud Library source for footprints is great, as long as I can copy them to, and use them from a library of my own. You see, until I've validated it myself, I can't afford to trust anyone else's assumptions.I also doubt you would want any of my local tweeks to overwrite your cloud version, because that would invalidate other people's validated parts...
It may be that there are/needs to be TWO job files - a master job that is not bound to parts/packages yet, and a transportable job that has all the parts and package stuff in it. These could be ONE file if there was a function similar to EagleCad's "Update Library"...
-John
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CAKFrckoo6EWoWUFD-YGYfXj_9--euLLxo%2BN%3DuvqsrbL922ocHg%40mail.gmail.com.
Jason von Nieda
Hi Jason
(I really hope, this does not sound offending in any way. If it does, please be assured it was not meant so! )
Now I understand, you want to redundantly copy everything into jobs. Kind of like Eagle copies library parts/footprints into the board/schematic.
John said:
> For me, the key is the ability to manage a parts inventory independently from the Jobs - and to be able to have existing Jobs take advantage of future changes to my Inventory.
That would be absolutely essential for me too and it must be easy and fast to use. But ...
Begin Advocatus Diaboli.
So we'd have two Part and Package tabs, one central, one job oriented? Or two separate executables, one for operation and setup and one for library maintenance (like in those programs from the Eighties)? Plus we need an "update parts from central" functionality, and "push parts back to central"?
So the OpenPnP group would soon overflow with messages like: "Oh no, I pushed the outdated footprints from that job I resurrected from 2015 and overwrote central!", "Darn, I should have only pulled in the new package (part?) nozzle tip compatibilities, but left the job's custom vision trims alone, now everything is overwritten. It took me two day to get those right!".
To make this work without too much pain, you'd need full-fledged three-way versioning between each job and the central database, so you could push or pull only the changed and parts and attributes. You's need conflict resolution, if the same parts/attributes were changed on both sides. For cloud operation you'd also need very far-reaching version independence both ways, no more "I don't know this new attribute, so I give up" XML stubbornness.
We'd need super-complex push-pull dialogs where you can determine which attributes to actually sync and which parts/packages to include. And you'd still suffer from consequences when you didn't think of that dependency between two attributes, or that update of the database two weeks ago...
I agree that this would open many new possibilities, like sharing part/package settings across very different machines and camera setups. But it's one hell of an endeavor to develop. And it's necessary complex to use (at least if you want it to be both safe + work efficient).
End Advocatus Diaboli.
IMHO, in comparison, the multiple Database approach does not sound so complicated and frightening after all.
You can have multiple databases to reflect multiple sequential or parallel "evolutions" of your workflow. This "evolution" also reflects the OpenPnP version i.e. the capabilities/settings a version has at a time. You can let a job ride on the newest database, kind of like it is now common in software development with continuous integration. Or you can create a project/customer specific database to encapsulate it from other, completely different projects/customers. So it still evolves, but only when that project proceeds/customer orders, and as a separate "species". Or you can create a job "time capsule" with a momentary snapshot of your database (like I said this could be made into a self-contained file bundle). One day you might decide to bring that job back "to the future". You can, because you can re-associate it with an evolved database. But that would then be an all-or-nothing (you can't travel backwards in time). If you see it's too much work, you can choose a less far evolved database perhaps, or give up and connect it back to that old time capsule database, without ever overwriting or losing something. The only thing we'd do, is cloning missing parts/packages over into a newly associated database, i.e. purely non-destructive.
And it could be developed in sensible time.
Some of these databases could be cloud based. Communities could form around a specific database (they'd all have to run the right OpenPnP version). Backup/restore, versioning, sending in, etc. are all straight-forward. Databases are just files/directories.
>> Even my DIY project has 34 parts on the R0402 package, they all look perfectly the same. I don't want to trim 34 sliders when one vision property is wrong! ;-)
> Is this your experience in practice? It isn't mine. A heavy 10uF 0805 responds very differently to speed, acceleration, vacuum pressure, etc. than a super light 0.1uF 0805.
Yes, I would say that is my experience (how "practical" it really is, is another question). My parts all look essentially the same per footprint. For the capacitor example you used, I know, because I actually wrote a small script in Eagle to automatically select the package based on capacitance and max voltage. I looked a Digikey and there is a very clear association between capacitance/voltage and footprint (at price). These parts grow in all dimensions, not just Z ;-). I guess part manufacturing is also easiest, when everything remains the same per package. This page even suggests its standardized:
Going beyond capacitors, packages are often already discriminated in the ECAD. They're a different package, if they need that extra cooling or mounting pad, or the extra pad clearance for higher voltage, for example (all real world examples out of my project). Increasingly, ECAD software also maintains 3D data, which further drives package discrimination. Parts that are more "3D" and heavy like inductors have proprietary footprints anyways. Admittedly, I never planned with those tall electrolytic capacitors.
So 99 out of 100 times I would be quite confident that all parts of a package can be handled in completely the same way by OpenPnP. For the remaining 1% of the cases, I can clone-and-assign an extra package in OpenPnP.
The alternative is simply not feasible. I surely don't want to set nozzle tip compatibilities 34 times for the R0402 plus 14 times for C0402 (data from my project).
And for the next project I import, I don't want to go check which of the R0402 are new, and config them from scratch.
I'm a bit surprised here. Is it really done like that in the pro softwares you used?
Finally, I should also say, I was not the one advocating to put all the settings on one object, either Part or Package. I was fine with a dynamic inheritance. Set defaults globally, inherit to package. Override on the package, inherit to part. Override on the part, inherit to Part in Job. Override on Part in Job.
This may sound very complicated, but in fact the GUI could always look exactly the same, users would just chose on what level to override.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/ab294037-f01d-51e1-801b-81d7c1475938%40makr.zone.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jzxWhAE2FxsG8tHqCsB%3DoAgu%2B-nv5y6%2BibNQK-EbikUpg%40mail.gmail.com.
Jason von Nieda
Adding width and height as required, or at least suggested, gets us the ability to do better bottom vision, tombstone detection, bad pick detection, etc. without having to use pipeline hacks.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNzbLTgZUcgmQ2E_NxxXRJXPB%2BcSoov%3DXeF%2BE2rxA4_r8g%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jz08wGtucCHcYDOn3bZi3Gk9uao6ktfWsYjjBc9jOQMZw%40mail.gmail.com.
Jason von Nieda
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNxaX31TjF%2BC6YvTcgmK6ahfoAo8ZtdE%3D3_Z2O3FOAJ76w%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jxQKj6DLuE6PUdStjtizeFYMbQbHEvieDYHL9cvu4APuA%40mail.gmail.com.
John Plocher
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jxQKj6DLuE6PUdStjtizeFYMbQbHEvieDYHL9cvu4APuA%40mail.gmail.com.
Jason von Nieda
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BKNHNxa6LN6y-N8wMycmAFB0KF3J3aCv-k5Q9vdKAfks8p7jg%40mail.gmail.com.
Jason von Nieda
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CAKFrckqug6WV5KzTfRFiezWnEurS%3D%3D2reVa%2BOqeS%3D5YfMSR%2Bkg%40mail.gmail.com.
bert shivaan
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jwjP9LQT9UTo3EFK6Wzu%3DN2Fqq1mN_4BCXQBomH_uzW2Q%40mail.gmail.com.
ma...@makr.zone
Jason,
> The change is that this Nozzle Tips tab just
moves to the Part. So, yes, you do assign Nozzle Tips to a Part,
but remember, once you've done it for a part you never have to
do it again when you use that part, because it's in the
database.
I must really be missing something. Sorry, this idea really troubles me...
Steam emergency release: on.
So it would be expected of users to enter the same data over and
over again, for each of the sometimes dozens of parts
that belong to the same package? And if my database contains a
hundred R0402s after a while and I import a new project, I have to
take out the fine comb and go through all of my R0402s and find
the ones that still don't have a nozzle tip compatibility
assigned, and no speed and no vision, and no width and no length
and no height ... and enter it, manually? No more smart
feeder setup cloning based on the package level? And in the
future: no per package training data, no template image, no
pipeline trimming?
And if one day I want to add a second compatible nozzle tip to my
R0402s, or reassign them to an optimized vision setup, do I need
to go in there and manually change a hundred parts?
I do hope I am missing something veeery big and juicy.
Steam emergency release: off.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jz3v8%3DB1QGByUZ79AeZkp3iiXW4O4yZnLriBiPcoQL_1A%40mail.gmail.com.
Jason von Nieda
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/9305ade6-bcbe-b3d2-fca3-afb9649d3160%40makr.zone.
ma...@makr.zone
Hi John
Somehow I can't parse your Email (I'm not a native speaker).
The first sentence seems to be along Jason's line.
> One of the POORLY handled parts of eagle is the idea of a common package definition shared across parts.
But then you seem to say the opposite:
> Having parts define their own SOIC24 package info seems to be asking for confusion and errors..
What do you really mean?
I'm sure you know all this, but for the purpose of the discussion and for other readers, I'd like to elaborate. Eagle has even three levels:
Parts (with value)->Devices->Packages
(a Device also has one or more Symbols for the Schematic).
A device represents the "I2C chip or a H-Bridge or MCU" you
mention. The package stands for the "JEDIC et al footprint" (and
more). Some devices can be parametrized with a value (resistance,
capacitance etc., mostly for the passives), others have a fixed
value assigned. Each unique value/device/package combo will form a
separate part when imported in OpenPnP. Devices and packages are
fully independent, a package can be used by many devices, and vice
versa, a device can have multiple packages.
The pads/pins of each device associated package must be logically
wired up to the symbol pins, so I can switch the package any time,
without touching the schematic. I find this very useful, and KiCAD
missing this feature, is one of the reasons I'm not in a hurry to
jump (but I'm also still on pre-subscription Eagle 7.7 :-).
I'm not saying this is the best, I just know Eagle and a bit of
KiCAD.
Can you explain what you mean is "POORLY handled", John?
_Mark
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jwjP9LQT9UTo3EFK6Wzu%3DN2Fqq1mN_4BCXQBomH_uzW2Q%40mail.gmail.com.
ma...@makr.zone
> Did you read my response to your message from earlier, where I started with "Yes, this is a great comparison and is exactly what I mean"?
Yes but that's an entirely different question, namely whether we
want to to have redundant copies of Parts and Packages in the job
file or not.
This question is much more fundamental: whether we want to drop
Package support in OpenPnP.
> You would simply select a compatible part from the
database and it would copy the data in. You could even have a
"reference" part in the database if you like, say R0402-Master.
Seriously? I have to hand-curate "master
parts" and on each import hand-assign them because OpenPnP
has become too "simpleton" to care about ECAD-asserted
Part->Package associations?
And what about this question?
>> And if one day I want to add a second compatible
nozzle tip to my R0402s, or reassign them to an optimized vision
setup, do I need to go in there and manually change
a hundred parts?
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jxSc%3D-YjefBwfJxk9oL7Si%3DqVGmeDWH%3DNmJ8xR3690ssQ%40mail.gmail.com.
John Plocher
What do you really mean?
I'm sure you know all this, but for the purpose of the discussion and for other readers, I'd like to elaborate. Eagle has even three levels:
Parts (with value)->Devices->Packages
Eagle has a Library called ref_packages.lbr, with hundreds of common footprintsA new part is created in a library by associating a Symbol with a set of Packages. While both are intended to be copied from elsewhere if possible (i.e., all resistors should share the same R Symbol, and all wide small outline 24-pin ICs should share the same SO24W package), figuring out how to copy/use an existing item was sufficiently difficult that all the tutorials simply showed how to create a new Symbol or Package from scratch - which is what most people did.A new Project is created by adding parts from libraries and giving them values (schematic) and then placing specific packages on a PCB (board editor).In Eagle, this gives us
- reference libraries exist that contain an (incomplete) set of industry defined packages and symbols
- distribution libraries are created to hold parts (part = symbol + set of packages, with pin bindings)
- personal libraries are often used, which are populated with parts that have been validated by a particular designer
- parts from a library are added to schematics and given values (in eagle, this also copies all the part definition info from a library into the project file)
- A chosen package associated with each part is placed on PCBs
- PCBs are processed to give BOM and centroid information to OpenPnP
- parts in libraries can be edited/updated, and
- the parts in libraries used by a project remain unchanged even if the original library is updated, until the project developer explicitly asks to update the library from the project file.
John Plocher
8. the parts in libraries used by a project remain unchanged
Jason von Nieda
> Did you read my response to your message from earlier, where I started with "Yes, this is a great comparison and is exactly what I mean"?
Yes but that's an entirely different question, namely whether we want to to have redundant copies of Parts and Packages in the job file or not.
This question is much more fundamental: whether we want to drop Package support in OpenPnP.

VersTop NYC
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CA%2BQw0jzTnt2g2PBm_QsDFFzi8HbAKJNnZKZq5MyYKHzGC1_Hxg%40mail.gmail.com.
VersTop NYC
Hi everybodyI take geo0rpo's question as the trigger to finally discuss this.This is my take of things, if you think that's a bad idea, please speak up:> shouldn't the part bottom vision pipelines be at the "packages" tab
Absolutely, and that's very high on my list.
I'll even go one step further: The pipeline should not be in the package either, but multiple "Bottom Visions" should be defined in the Vision tree:
Each Bottom Vision setup would define the settings and pipeline together, optimized for each other (no change from today).
My assumption is, that if done well, you only ever need a handful of different pipeline/alignment setups. One of the setups would be marked as the "Default". Obviously you would define "Default" for the most widely used setup (probably the one for small passives).
In the Package you would then select one of the Bottom Visions setups from a combo-box, if (and only if) anything other than the "Default" is needed.
In the Part the same, but with the default given by the Package.
So we get a dynamically inherited assignment: Default -> Package -> Part.
The migration of existing machine.xml would be the most difficult part to implement this. The migration algorithm must group all equal (Pipeline + "Pre-Rotate") settings, create Bottom Vision setups from them, find the "Default" as the most commonly used one, on both the Machine and Package level, and assign the non-defaults where they don't match.
Fiducials the same way.
What do you think?
_Mark
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/c690532c-8c06-4295-9303-5e97adcce4edn%40googlegroups.com.

Niclas Hedhman
The pads/pins of each device associated package must be logically wired up to the symbol pins, so I can switch the package any time, without touching the schematic. I find this very useful, and KiCAD missing this feature, is one of the reasons I'm not in a hurry to jump (but I'm also still on pre-subscription Eagle 7.7 :-).

Jarosław Karwik
ma...@makr.zone
Hi Niclas
OT...
In Eagle you can place a device in the schematic, wire it up etc.
Then later, you decide you want the smaller version of the device,
you just right click the part on the schematic or board and select
another package.
You change it from this...

... to this:
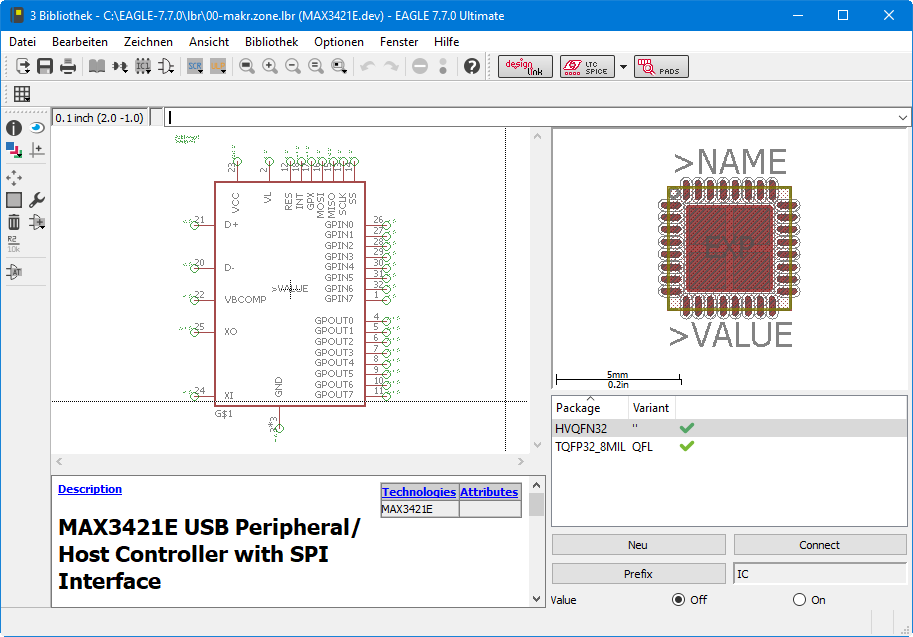
All the signals are still connected, the schematic is untouched. The extra thermal pad is properly connected to GND (if you look closely in the symbol, you see one extra connection to the GND pin).
I have many devices like that, because my project kept evolving
to be smaller and smaller... ;-)
Last time I checked, KiCAD couldn't do that (yet).
_Mark
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/CADmm%2BKf0i7LNb5XRFa6g6CHk77c2MCUcoTZuXbOCYQ0TZtj0AQ%40mail.gmail.com.

{kind=link}
Niclas Hedhman
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/98b1651e-e89d-6888-b2a0-39971fd58004%40makr.zone.
ma...@makr.zone
Test: Does GG create a new topic, if I change the subject line on the email?
___
Hi Niclas,
Continuation of https://groups.google.com/g/openpnp/c/7DeSdX4cFUE/m/5nCodBX3AQAJ
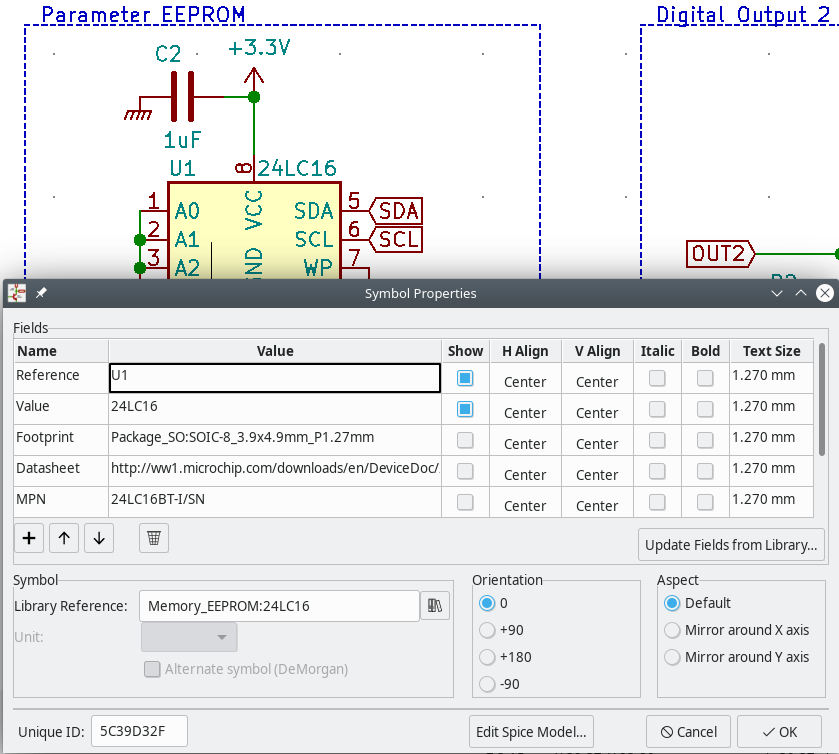
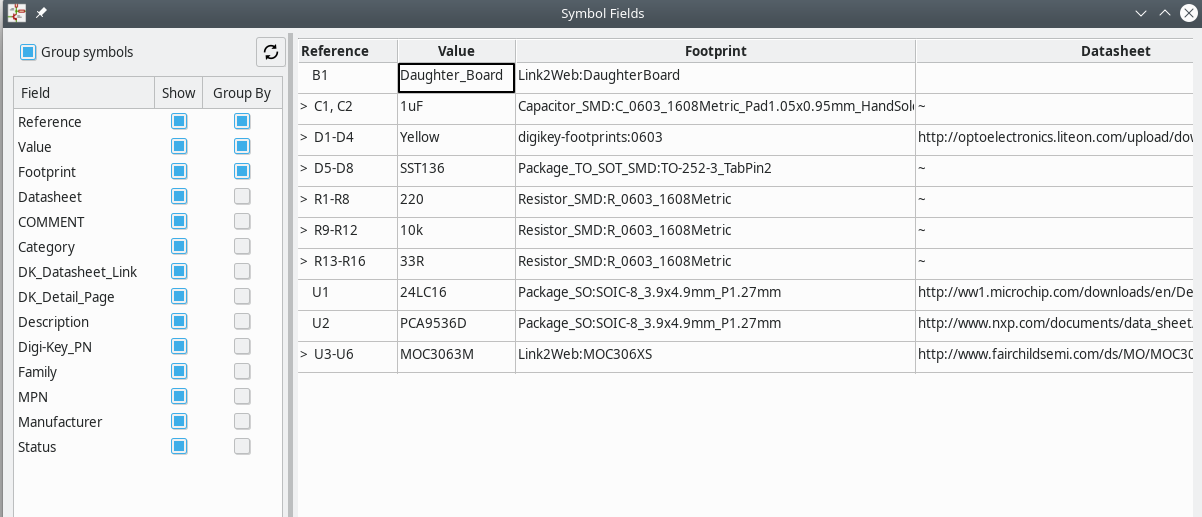
When I go to the library and open the device, I see only one
Footprint selection.

And I see no way to wire the symbol to the footprint in a
footprint specific way.
The way I understand, it only works half-automatically if the symbol pin names/numbers match the package contact names. And that won't allow for varied wiring, e.g. when you have that extra thermal pad or when power devices have multiple pins/pads on the same signal to allow for higher currents on smaller packages.
_Mark
johanne...@formann.de
ma...@makr.zone
Johannes, could you please re-post this in the new thread?
_Mark
--
You received this message because you are subscribed to the Google Groups "OpenPnP" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openpnp+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openpnp/0deb1181-a4e9-4897-b1c9-e0f87ee75035n%40googlegroups.com.