OpenLMIS deployment topology

Sebastian Brudziński
I was asked to share some insights and findings that the Malawi team has got about the AWS deployment topology in order to help improve the recommended deployment topology docs of OpenLMIS (http://docs.openlmis.org/en/latest/deployment/topology.html). Before getting to the numbers though, I should mention that the Malawi instance runs limited amount of OpenLMIS services (no stock management or cce), however we have three (small) services of our own. Please see the exact compose file at https://github.com/OpenLMIS-Malawi/mw-distro/blob/master/docker-compose.yml
Our exact topology is very similar to the current, official
recommendations. We do not use Route53 as MoH manages the
domains on their own. We use ELB (we switched from elastic IPs).
We also use Amazon SES for notifications. We use m4.large EC2
instance - we have performed small tests with bigger EC2
instance but our findings were that it does not seem to improve
processing time at all. The biggest gain in processing time
could be observed when boosting the database instance. We have
tested all t2 class instances and db.m4.large and went with
db.t2.medium for a start and just recently bumped it to
db.t2.large to see if we can improve report generating time
(some take very long to generate data for the whole country).
The t2 class databases offer temporary boosts in processing for
heavier queries or when there are many queries at the same time,
which probably is the reason why they gave the best results.
When the t2 database is unused, it generates "credit points",
that can later on be used for those bursts when full processing
power is required. This also seems like the best solution for
us, since our database will be heavily used only about 8-10
hours a day, while the rest of the day it will have minimal
traffic. A little more on t2 bursts:
-
https://aws.amazon.com/about-aws/whats-new/2014/08/04/new-low-cost-amazon-rds-option-t2/
-
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.DBInstanceClass.html#Concepts.DBInstanceClass.T2
It's worth mentioning that our database contains about 200,000
legacy requisitions and our biggest program contains 250 full
supply products (+ around 1k non-full supply). We have also
recently conducted a research on how specific EC2+RDS
combinations affect performance of specific endpoints. You can
see the outcome of the research in the table below. We have
tested 6 different AWS EC2+RDS combinations and tested most of
the requisition endpoints.
Number of all requisitions in the system: 191582
Number of products (full supply / available non-full supply) for
tested requisition: 266 / 818
Requisitions found in search: 60
Avg of 3 operations
| AWS Setup | m4.large + db.t2.small |
m4.large + db.t2.medium |
m4.large + db.t2.large |
m4.xlarge + db.t2.small |
m4.xlarge + db.t2.medium |
m4.2xlarge + db.m4.large |
|---|---|---|---|---|---|---|
| Requisition search | 9.92s | 9.37s | 8.18s | 10.04s | 9.37s | 10.2s |
| Requisition initiate | 37.31s | 10.55s | 11.21s | 16.02s | 11.09s | 10.81s |
| Requisition get | 26.6s | 14.17s | 13.96s | 15.34s | 14.20s | 12.80s |
| Requisition save | 27.85s | 16.55s | 14.96s | 19.91s | 17.32s | 14.2s |
| Requisition submit | 15.44s | 2.65s | 2.47s | 3.07s | 2.67s | 2.40s |
| Requisition authorize | 25.96s | 16.45s | 13.15s | 14.64s | 13.18s | 13.06s |
| Batch approve (retrieve 3 requisitions) | 51.42s | 24.34s | 18.96s | 50.62s | 19.82s | 37.83s |
| Batch approve (approve 3 requisitions | 1.3min | 1.0min | 1.0min | 1.3 min | 1.0min | 1.3 min |
| Cost (EU - Ireland, on demand) | 108$ per month | 136$ per month | 193$ per month | 188$ per month | 216$ per month | 464$ per month |
Please let us know if you have any specific questions about the deployment topology. I, or someone from the Malawi team will be happy to answer or share more info.
--
Sebastian
Brudziński
Software Developer / Team
Leader
sbrud...@soldevelo.com
SolDevelo Sp. z o.o. [LLC] / www.soldevelo.com
Al. Zwycięstwa 96/98, 81-451, Gdynia, Poland
Phone: +48 58 782 45 40 / Fax: +48 58 782 45 41

Josh Zamor
For the deployment topology recommendation I think an updated and concise recommendation learning from this would be to list the RDS as:
- For local development, QA and simple demos: use Ref-Distro's included PostgreSQL or a db.t2.micro
- For CD, non-trivial demos/UATs and production: db.t2.medium
- And then increase to >= db.t2.large as needed, especially depending on reporting and data size (first two KPIs being largest number of full supply product + non-full supply products, and max # of requisitions in a program).
Would you agree with that and/or change anything with that?
I also believe that Malawi experienced a limited period where even the db.t2.large ran out of available DB connections (on the RDS side)? Beyond the somewhat simplistic recommendation above we could start looking at moving (some) services to their own dedicated RDS instances. To make that recommendation it'd be useful to know which services are spiking connections the most. Have you seen this spike in DB connections again and/or know which Service's are using more than their fair share of connections?
Josh
Sebastian Brudziński
Yes, this looks like a good recommendation. In general, when working with the t2 class databases, the most important thing is monitoring the CPU credit balance. When RDS runs out of them, it operates at like 30%~ of its full potential. AWS console easily allows you to see your credit balance and how it evolved during certain time frame. The better the RDS class, the more credits you have and the faster they grow up when the database is unused. When we run out of the credits, it has been reported that users could barely use the system. Once upgrading to db.t2.large we seem to have enough credits to get by a busy day (10h~) without running out of credits. Of course, the t2 class database would NEVER be a good choice for systems that operate and are used 24h/day. They would never have a chance to regain the credits and always operate at low performance (maybe that's worth mentioning in the recommendation as well?)
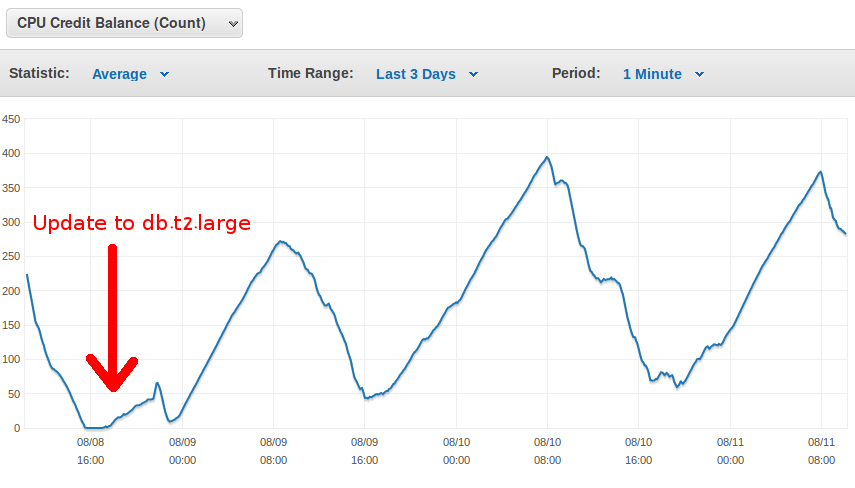
As for running out of available connections, this actually happened when we were still on db.t2.medium database, but the problem seemed to be a limit on the application level, not on the RDS side. RDS still had a number of connections available and the logs reported that the connection cannot be obtained from the connection pool. It seems like there's a default limit on 100 connections (probably per service?) and for some weird reason we have reached that limit. Anyways, this has happened once for a short period of time only so we didn't investigate this more, but if it becomes a problem we will be diving into it more.
Kind regards,
Sebastian.
--
You received this message because you are subscribed to the Google Groups "OpenLMIS Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openlmis-dev...@googlegroups.com.
To post to this group, send email to openlm...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openlmis-dev/0ac51689-fda2-441a-a6cf-a7b756c57f6e%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Sebastian
Brudziński
Software Developer / Team Leader
sbrud...@soldevelo.com

Paweł Gesek
To unsubscribe from this group and stop receiving emails from it, send an email to openlmis-dev+unsubscribe@googlegroups.com.
To post to this group, send email to openlm...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openlmis-dev/0ac51689-fda2-441a-a6cf-a7b756c57f6e%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
Sebastian Brudziński
Software Developer / Team Leader
sbrud...@soldevelo.com
SolDevelo Sp. z o.o. [LLC] / www.soldevelo.com
Al. Zwycięstwa 96/98, 81-451, Gdynia, Poland
Phone: +48 58 782 45 40 / Fax: +48 58 782 45 41
--
You received this message because you are subscribed to the Google Groups "OpenLMIS Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openlmis-dev+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openlmis-dev/c5327112-9471-4869-61a4-17e3f1d6111c%40soldevelo.com.
Josh Zamor
On Aug 11, 2017, at 2:02 AM, Paweł Gesek <pge...@soldevelo.com> wrote:
PawełRegards,I think Boot uses the Tomcat jdbc connection pool by default - https://people.apache.org/~fhanik/jdbc-pool/jdbc-pool.html.The default value for active connections is 100.
On Fri, Aug 11, 2017 at 10:52 AM, Sebastian Brudziński <sbrud...@soldevelo.com> wrote:
Yes, this looks like a good recommendation. In general, when working with the t2 class databases, the most important thing is monitoring the CPU credit balance. When RDS runs out of them, it operates at like 30%~ of its full potential. AWS console easily allows you to see your credit balance and how it evolved during certain time frame. The better the RDS class, the more credits you have and the faster they grow up when the database is unused. When we run out of the credits, it has been reported that users could barely use the system. Once upgrading to db.t2.large we seem to have enough credits to get by a busy day (10h~) without running out of credits. Of course, the t2 class database would NEVER be a good choice for systems that operate and are used 24h/day. They would never have a chance to regain the credits and always operate at low performance (maybe that's worth mentioning in the recommendation as well?)
<Screenshot from 2017-08-11 10:40:38.png>
To unsubscribe from this group and stop receiving emails from it, send an email to openlmis-dev...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/openlmis-dev/CADt-Nu1fiCV-pFMttbqMxpQ%2B_s3VdoVhw4sknog%3DPLErdpSAnw%40mail.gmail.com.

Jake Watson
Sebastian Brudziński
The docs look great and they would definitely help choosing the
correct database instance if we were just starting the
implementation.
Thanks for setting up the notifications. I agree that monitoring
available credits is critical. We didn't have any notifications
set up until this point - I've created a ticket to explore what
metrics and alerts would be useful for us and to create them. Once
we have a better understanding on which of them are useful for us,
we can circle back and share our thoughts so they can be included
in the monitoring & alerting recommendations.
Best regards,
Sebastian.