MOZI web UI

Linas Vepstas
--

Lansana Camara
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA355C6jVfExiFaqYusBxj4oGwD2Bpd%2B9DY7qP3jyLb7orQ%40mail.gmail.com.
Linas Vepstas
Linas,I’m not Xabush, but in regards to your question about a web UI…What are your requirements?
Building a (globally distributed?) and easily maintainable frontend that communicates with servers via HTTP or some similar protocol is very easy for me; this is my expertise. I can start from scratch and have a web UI up and running on a global CDN in one days time, using open source tech that is understood by the majority of the frontend community (eg React) which means that it would be easily maintainable and extensible.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERrO-KhO%3Ddp0UXOhfT4hUQn8O95%3DfzKGw26kpRzXpz-cxA%40mail.gmail.com.
Lansana Camara
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34e%3D-8E0d%2ByeGkwUMaj6jBWOO_Uoi26CDOUubbkeXknxQ%40mail.gmail.com.
Linas Vepstas
- Mikyas Damtew
- Kaleab Yitbarek
- Tsadkan Yitbarek
- Stephen Sherman
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERoovF6SsLsKD3WPpAa9OwtLc%2BK82Ao6CXzMJkBW2krWnA%40mail.gmail.com.

Reslav Hollos
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34hU%3DOdJBV6pFeCepjDrbsZquNGOZkwpCbwyOOMJcpV_g%40mail.gmail.com.
Linas Vepstas
I'm also interested in AtomSpace UI and have had very pleasant dev experience with React (as well as TypeScript which I would recommend).
Reslav Hollos
About NPM, it can sometimes be tricky but I think it's manageable, it shares some problems/solutions from many different package managers, like mismatch of node version between dev environments, incorrect handling of package-lock.json (a file that hardcodes all dependencies of dependencies versions) or some library incompatibilities with another library which solution is usually in github issues comments. I use NPM in all JS projects.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34hy9RZBg897pPX-hwhkcf_%2BbHmE%2B4QRSsE60p%3DnjKb9Q%40mail.gmail.com.

Michael Duncan
1. expanding query functionality to make it type agnostic, so any combination of elements (genes, proteins, RNAs, et) with arbitrarily specific interactions between them can be used to query the bio-atomspace
Linas Vepstas
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CANHDs8%3DrtH%3DUwMb5zwetbX9UPk3XiFnTnw2hy--aNmDqXkr3%3DA%40mail.gmail.com.
Lansana Camara
Dashboards -- well, when I say dashboard, what I think of are things like the BIOS boot-up screen -- menus and lists and configurable parameters and you can navigate it with keyboard or mouse. My wifi router has a dashboard -- it's a web page, you can configure wifi settings in it. My (android) cell phone has one: it's the "settings" panel: you can change this or that setting, turn things on and off.
So I'm thinking the same thing but for generic data science with opencog. Take this file, copy it to that directory, start this script, look at diagnostic output, wait until the dataset is done, and when it's done, paint a green dot, and if it crashed, paint a red dot. That kind of stuff. Show me a graph of megabytes used so far, cause I have a datacap of 1 million atoms per month. JK.😂
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34UVtF9vnOua5YOEVQuwZo_Z3PJkNZGVVYaC3H4yNUycg%40mail.gmail.com.
Linas Vepstas
Linas,Dashboards -- well, when I say dashboard, what I think of are things like the BIOS boot-up screen -- menus and lists and configurable parameters and you can navigate it with keyboard or mouse. My wifi router has a dashboard -- it's a web page, you can configure wifi settings in it. My (android) cell phone has one: it's the "settings" panel: you can change this or that setting, turn things on and off.So I'm thinking the same thing but for generic data science with opencog. Take this file, copy it to that directory, start this script, look at diagnostic output, wait until the dataset is done, and when it's done, paint a green dot, and if it crashed, paint a red dot. That kind of stuff. Show me a graph of megabytes used so far, cause I have a datacap of 1 million atoms per month. JK.😂What you're asking for here is basically what they pay me the big bucks in Silicon Valley to build on a 9-5 schedule 😂
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERrZ5tpm5HD-nQxs09ykEUERzQ0hAcytrahzU_vE-UBhdg%40mail.gmail.com.
Lansana Camara
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37ba8zJnEodzavpSo3hF6b6nAt0Q2rmAvvZC93i%2BCLa_Q%40mail.gmail.com.

Adrian Borucki
On Tue, Jun 29, 2021 at 11:49 PM Lansana Camara <lxc...@gmail.com> wrote:Linas,Dashboards -- well, when I say dashboard, what I think of are things like the BIOS boot-up screen -- menus and lists and configurable parameters and you can navigate it with keyboard or mouse. My wifi router has a dashboard -- it's a web page, you can configure wifi settings in it. My (android) cell phone has one: it's the "settings" panel: you can change this or that setting, turn things on and off.So I'm thinking the same thing but for generic data science with opencog. Take this file, copy it to that directory, start this script, look at diagnostic output, wait until the dataset is done, and when it's done, paint a green dot, and if it crashed, paint a red dot. That kind of stuff. Show me a graph of megabytes used so far, cause I have a datacap of 1 million atoms per month. JK.😂What you're asking for here is basically what they pay me the big bucks in Silicon Valley to build on a 9-5 schedule 😂Sigh. It shouldn't be like that. I won't create a GUI mockup, for two reasons: first, this is something that artists and designers do, when trying to take an existing system to the next level. Right now, we don't have anything basic. Second, these kinds of things best evolve through regular use: you use it for a while, and if it stinks you stop using it, or you alter it so it works right. It's very hard to predict what that might be in advance. Also, processing steps evolve, flows change. The flow from last month might no longer apply this month. The process changes; the GUI needs to be malleable.Now, back in the day of desktop apps, there was this thing called a "gui designer". It allowed you to drag-n-drop menus, text-boxes, buttons, plots, charts, change their color, font size, stuff like that. You could hook them up to code that "did stuff": there was an editor, and you'd fill in the blank: on button-press, do this. On double-click, do that. If you never used one, you should try it. They're awesome! The one for Gnome/GTK is glade -- https://glade.gnome.org/Is there something like this for React and/or Angular?I am confusing you and I am confusing myself, because I am talking about three different things.1) An atomspace visualizer. This would be for complete beginners, and would be a web-javascript thing, so that we could stick it on a website, and allow people to dink with it, without having to install anything at all. Bonus: it runs on tablets.
2) A dashboard. I'm starting to think that maybe using Glade and GTK to build a desktop app is not a bad idea. The only thing wrong with that is it wouldn't run on cell phones and tablets.3) A science exploration ... system/journal. Perhaps Jupyter is the best choice for this. The most deeply flawed problem with Jupyter is revision control. If you change one line of code in Jupyter, and do a diff, you get thousands of lines of code changed. That sucks: that makes using git completely useless. I'm told that there are some maybe-solutions for this, but I haven't really looked/tried.
Linas Vepstas
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERpJ1kXpzEZSj8ENMWQdutnu-N4Wa0oTBMpc%2B4x1Ph56Bg%40mail.gmail.com.

Douglas Miles
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34cicZZpuDSPSFLg5d%2B8ToXFyqD-2ODQ-9wOxkHyvOFfg%40mail.gmail.com.

Abdulrahman Semrie
Lansana Camara
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/d16f492c-26f2-4f21-807e-e02cfd8f7c6cn%40googlegroups.com.
Linas Vepstas
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAER3M5%3DqeZvQLop27%3DGU8iH1eJOX8Q%2BZ9piaB0zZMTgxPJRJkw%40mail.gmail.com.
Linas Vepstas
Hi Linas,(Sorry for not responding earlier. As Mike have explained, I'm on vacation and don't check my e-mail regularly. I should be able to answer more questions when I'm back next week)More or less, the three requirements that you mentioned above have either been partially implemented (1) or were planned to be implemented (2 & 3) in the previous Mozi platform iteration, albeit using the (now old?) Python API of the AtomSpace.
The code for both the backend and frontend is available on gitlab in a private Mozi repository. I should probably export it to github and make it public.
Going through the list of requirements:1) We had an interface to create an AtomSpace from a scheme file but back then we had issues keeping the imported data into separate AtomSpaces and accessing them independently.
If you remember. this is before you implemented the copy-on-write functionality.
However, with the AtomSpace gRPC server that I wrote few months back, this is possible and I have been using multiple atomspaces to run annotation tasks but haven't developed a generic UI around it.
2) I was actually planning to extend the gRPC server by integrating it with Grafana for monitoring purposes. Unfortunately, I didn't find the time to implement it. AFAIK, Grafana handles much of the UI stuff and only needs some API for it to be used as a dashboard/monitoring tool. I think this is easier than writing a new UI code.
3) For the visualization, in addition to the visualizer in https://github.com/opencog/external-tools/,
we developed our own custom Cytospace visualizer that visualized atoms representing biochemical entities using custom layouts.
This is the visualizer used in the annotation service you linked above.
The main issue we had with the Cytoscape visualizer was calculating the layout algorithms on the front-end when the size of the graph got bigger. I suppose anyone who wants to use a data explorer with the atomspace will eventually run into such a performance issue as the atomspace gets bigger.
To resolve this, I created a small library that runs the layout algorithm on the backend and send the coordinates of the nodes and edges to the front-end. This code is not generic but some part of it can be reused or it can be refactored to make it generic.
> Maybe a kind-of-like jupyter for the atomspace.This kind of functionality was also implemented on the old Mozi platform using cogserver but it needs updating.In conclusion, a skeleton of what you have listed above exists, but needs refactoring to make it generic/reusable and also merge it into one tool/product.
On Saturday, June 26, 2021 at 10:04:34 PM UTC+3 linas wrote:Hi Xabush,So I have a tough question for you: the MOZI webserver ...I'm trying to solve a meta-problem: I want to increase developer engagement in opencog/atomspace. For that, it would be nice to have a web UI. Three of them actually, or four.1) A web UI that allows users to create new atomspaces, and put (by hand) some atoms into it, and visualize simple graphs. So, people can point their browser at it, and mess around.2) A job control panel web UI. So, for the language learning project, I have a collection of bash scripts that start and stop the atomspace, and ingest text files, and take hours or days to run. I thought of MOZI because it has some similar requirements.3) A data explorer. Given an atomspace, with say, millions of atoms (from language learning, or from biochem), I want to explore what's inside of it: print all atoms in some cluster, ranked by frequency, or plot some histogram of mutual information vs frequency or whatever. Maybe a kind-of-like jupyter for the atomspace. Again, I think of the MOZI work in this direction. You were trying to get a simple web UI for biochemists to use. I want the same deal, but for linguists. Under the covers, it's all the same stuff: just atoms in the atomspace.How can this be accomplished? You've built some kind of custom solution for 2 & 3 for MOZI, but I don't understand how to backtrack out of that, and custom-tailor it so that it works for language learning instead of ChEBI or PubChem. Any ideas?I mean, you and Hedra have put a lot of effort into these things...I see things like this:and this:And I'd like to have it work for the kinds of graphs and systems in the language-learning codebase, instead of biochemistry. What would it take to have that work? Do I really have to start from scratch? Is there a way to recycle any of the work that you've done, and use it for other applications?I don't want to go off and state the obvious, but maybe I should go off and state the obvious: if this web UI stuff was generic, then other users could use it, which means that other users could show up and help fix bugs and add features. It would grow the project overall ... it would help anyone interested in the atomspace and in singularitynet and all that jazz ...BTW, back in the days of Hanson Robotics, we had the same problem ... I think we throw a lot of money at some Brazillian to create a WebUI for the Owyl behavior tree subsystem, but .. of course, that code failed with the AtomSpace, so it was like .. wasted money, wasted effort. .. we still don't have a generic AtomSpace WebUI ...-- Linas
--Patrick: Are they laughing at us?Sponge Bob: No, Patrick, they are laughing next to us.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/d16f492c-26f2-4f21-807e-e02cfd8f7c6cn%40googlegroups.com.
Linas Vepstas
Keep in mind that even Grafana's UI is built in JavaScript ;) building a modern frontend like what you're seeking using a language like C/C++ would be an anti-pattern. It's simply harder to do it that way.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERrWx4%2B59Kf163pAnmyaOD%2B5bbQ0pSJ89vFbE50CPrSLNw%40mail.gmail.com.
Lansana Camara
We hear you. You have a very strong opinion. But before you say, once again, how hard C and C++ is, and how easy javascript is, you should try Glade. https://glade.gnome.org/ And not just try it, but get good with it. Build an app with it.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35AAE89d4K6bxZeofcyDKbrsXkQCCcvBCGtRj-nv6OLhg%40mail.gmail.com.
Linas Vepstas
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERpw8PyF5%3DA9TN4c2FeNcbTqRPnokVA4S%3DOQEukh65qVCg%40mail.gmail.com.
Lansana Camara
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35xZpJ%3Db6a3ZObT2AD1GjLdUVsFa6Q0DSMHBaow4GUSCw%40mail.gmail.com.
Linas Vepstas
Linas,Dude I totally get it. Again, you have me confused for someone I’m not.
Let’s take a step back. Correct me if I’m wrong, but this whole thread is about you wanting to rebuild a UI that was left in a poor state and is difficult to maintain, right?
So, how do we make sure we don’t find ourselves in that place again?
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAPPXERony-grxxDKwf_c4TCqKwdUEcGc75FgADefSY1QQG-6HA%40mail.gmail.com.
Adrian Borucki
Hi Lansana,On Thu, Jul 1, 2021 at 11:58 PM Lansana Camara <lxc...@gmail.com> wrote:Keep in mind that even Grafana's UI is built in JavaScript ;) building a modern frontend like what you're seeking using a language like C/C++ would be an anti-pattern. It's simply harder to do it that way.We hear you. You have a very strong opinion. But before you say, once again, how hard C and C++ is, and how easy javascript is, you should try Glade. https://glade.gnome.org/ And not just try it, but get good with it. Build an app with it.
Now, if we had some kind of app builder for javascript, then, yes, you might have a point.
Adrian Borucki
On Saturday, 3 July 2021 at 03:48:53 UTC+2 linas wrote:Hi Lansana,On Thu, Jul 1, 2021 at 11:58 PM Lansana Camara <lxc...@gmail.com> wrote:Keep in mind that even Grafana's UI is built in JavaScript ;) building a modern frontend like what you're seeking using a language like C/C++ would be an anti-pattern. It's simply harder to do it that way.We hear you. You have a very strong opinion. But before you say, once again, how hard C and C++ is, and how easy javascript is, you should try Glade. https://glade.gnome.org/ And not just try it, but get good with it. Build an app with it.Ah, I remember toying with Glade… a decade ago. I don’t think GNOME developers use it anymore - GNOME Shell itself uses JavaScript nowadays for example.A better proposition for C++ would be QtCreator because it and Qt framework at least are supposed to be cross platform - there is a UI designer in QtCreator of course.All in all the problem with these is that they make you stuck with a specific tool (Glade / QtCreator) and framework (GTK+ / Qt) and none of those are particularly popular anymore (besides GTK+’s niche in Linux world).
Michael Duncan
Linas Vepstas
linus, here is a suggestion for a useful domain agnostic graphical interface to attract opensource devs to opencog and lower the learning curve for the opencog system.
start with a knowledge metagraph complex enough to be a useful for the "intro to opencog" tutorial, which would include the atoms in all the examples. some subset of SUMO small enough to fit into a low end laptop (4-8G ram?) is one possibility but i'm guessing because i haven't actually played with SUMO or any of the examples except for the ones in the unit tests...
ideally there would be a public server running the demo system so users could run the examples from their phone or a netbook, with step by step instructions for setting up a local instance for more ambitious users
a dashboard shows stats for the complete atomspace (type counts for atoms, data sources, etc), and a menu for pulling example sub-metagraphs from the atomspace server
paired visualizer windows based on atomspace explorer code
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/b750b969-6cb6-4303-b986-7e963e0d90bfn%40googlegroups.com.

Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35tErzxe%3D%2Bj2hObh36d__4Ghmi_u7b9cJ3LuK8PD%3DeXsQ%40mail.gmail.com.
Ivan V.
- How hard is it to implement a theorem prover in Atomese? (narrow, but noticeable user base; a strong potential for graph visualization)
- How hard is it to implement a math expression solver in Atomese? (wider user base; weaker potential for graph visualization)
- How hard is it to implement a program code synthesis system in Atomese? (well, this should be the future of programming; almost none potential for graph visualization)
Linas Vepstas
Hi all :)Just thinking out loud, these may be some suggestions...
- How hard is it to implement a theorem prover in Atomese? (narrow, but noticeable user base; a strong potential for graph visualization)
- How hard is it to implement a math expression solver in Atomese? (wider user base; weaker potential for graph visualization)

- How hard is it to implement a program code synthesis system in Atomese? (well, this should be the future of programming; almost none potential for graph visualization)
Do I miss something more ear-catching, and more applicable to graph visualization? Does this make any sense at all with fitting into the big OpenCog picture?
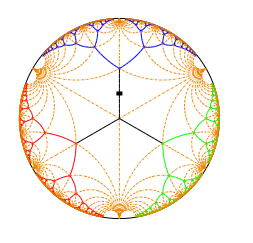
Lastly, does anyone have any interest in contributing to any of these use cases?And another "hey" from my littleness - according to Linas' visualisation idea, if someone decides to roll on the whole thing, and if server side scripting not a problem, I would be interested in sponsoring the OpenCog foundation with a fractal graph visualizer for tree structures repo that I'm developing for some time now. Of course, I am able to adjust the visualizer licence to OpenCog licencing standards, and I'm prepared for very flexible terms, so no worries from that side.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6WhiAPmHUH4m8s0Q_YS%2BOFARGvZZ7w7zVjOEKj4wyu97g%40mail.gmail.com.
Ivan V.



To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34LW2y0ef72%3D4c2OGCLS%2BV9%3DFSVPRUupiBZLALDwrGd7g%40mail.gmail.com.
Linas Vepstas




To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6U9v%2Bu2fJKe8Ykn3LpJoZed_NhDVZ_ixQsYuPA1izBfbA%40mail.gmail.com.

Ben Goertzel
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6U9v%2Bu2fJKe8Ykn3LpJoZed_NhDVZ_ixQsYuPA1izBfbA%40mail.gmail.com.
Ivan V.
Without trying to respond to all your points, I would like to note that the new language we are designing for the "OpenCog Hyperon" system (which will involve creating new systems to play the roles of a bunch of existing OpenCog code, details being worked out) -- which we have been calling "Atomese 2" but will soon have a less awkward name -- is indeed intended to be a human readable/write-able language corresponding to the internal operations of the Atomspace metagraph...
Regarding visualization though, I don't see how to connect the fractal images you show w. Atomspace visualization in a direct way. Do you have some thoughts there? Atomspace visualization is one of many OpenCog-related topics that turns out to be much harder than it seems at first...
--- --- --- --- --- --- --- --- ---
I J K L M N P Q R
----------------- ----------------- -----------------
A B C
-----------------------------------------------------------
X
About narrow-AI applications of symbolic or neural-symbolic AI, certainly they are worthy of attention, and indeed they might be an easier way to garner wide developer enthusiasm than AGI R&D. And yes both current OpenCog and Hyperon and Linas's future germ/sheaf-based system etc. should be usable for such narrow-AI applications.... If you want to build one many of us are here to offer what guidance we can...
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBeScDCuuM2LLXr%2BySsu%2Bh--V7iHgRV0hGUdmjki%2B8Kn9w%40mail.gmail.com.
Linas Vepstas
Thank you for asking, and my thoughts are pretty obvious. As I understand, URE and PLN are all about proofs, so my thoughts may go in that direction. Suppose we have a natural deduction proof composition:
--- --- --- --- --- --- --- --- ---
I J K L M N P Q R
----------------- ----------------- -----------------
A B C
-----------------------------------------------------------
XYou can already see the tree-like composition, but as it may span over a very wide and tall area, it may be required to represent it within an on-demand scaling system. This example roughly shows what I have imagined for proof representation. In the example you can play with ovals, dragging them around and in or out the central area, zooming proof parts of the current interest. Notice how it is possible to represent and navigate nearly infinite length proofs, assuming enough memory space.
Ivan V.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34HBqa02JkW9-EVR5OrpSkOWEMGjZBOCPM2vKKpJR2%2B0A%40mail.gmail.com.
Ben Goertzel
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6UgLR5xMP9WeE%2BWOkqBynGTr%2BNQTwsmUq9JrSuU1Sh1ZA%40mail.gmail.com.
Ivan V.
A reasonable step would be for Nil to send you some real PLN and URE inference histories and see what your visualizer does with them...
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBeOoqMRD20KFDYPGG1YfRqT0qW4wehOGtTKSqTb%3D6L2Jw%40mail.gmail.com.
Ivan V.
Ivan V.
this is very cool, ivan! two suggestions would be to indicate on the ovals with a tick mark where the off-screen nodes are to guide navigation, and a permanent slider/[+,-] buttons for global zoom control. (i know these are obvious)
this is very cool, ivan! two suggestions would be to indicate on the ovals with a tick mark where the off-screen nodes are to guide navigation, and a permanent slider/[+,-] buttons for global zoom control. (i know these are obvious)
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/88dc6d00-07a3-4421-9cc0-9e5e1a8d0052n%40googlegroups.com.
Ivan V.
Linas Vepstas
Knowing that new Atomspace versions may be coming, I'd like to leave the support option open.
I believe that the mentioned JSON input would work well enough with the incoming versions.
What it isn't
Newcomers often struggle with the AtomSpace, because they bring preconceived notions of what they think it should be, and its not that. So, a few things it is not.
-
Its not JSON. So JSON is a perfectly good way of representing structured data. JSON records data as
key:valuepairs, arranged hierarchically, with braces, or as lists, with square brackets. The AtomSpace is similar, except that there are no keys! The AtomSpace still organizes data hierarchically, and provides lists, but all entries are anonymous, nameless. Why? There are performance (CPU and RAM usage) and other design tradeoffs in not using explicit named keys in the data structure. You can still have named values; it is just that they are not required. There are several different ways of importing JSON data into the AtomSpace. If your mental model of "data" is JSON, then you will be confused by the AtomSpace. -
It's not SQL. It's also not noSQL. Databases from 50 years ago organized structured data into tables, where the
keyis the label of a column, and differentvaluessit in different rows. This is more efficient than JSON, if you have many rows: you don't have to store the same key over and over again, for each row. Of course, tabular data is impractical if you have zillions of tables, each with only one or two rows. That's one reason why JSON was invented. The AtomSpace was designed to store unstructured data. You can still store structured data in it; there are several different ways of importing tabular data into the AtomSpace. If your mental model of "data" is structured data, then you will be confused by the AtomSpace. -
It's not a vertex+edge store. (Almost?) all graph databases decompose graphs into lists of vertexes and edges. This is just fine, if you don't use complex algorithms. The problem with this storage format is locality: graph traversal becomes a game of repeatedly looking up a specific vertex and then, a specific edge, each located in a large table of vertexes and edges. This is non-local; it requires large indexes on those tables (requires a lot of RAM), and the lookups are CPU consuming. Graph traversal can be a bottleneck. The AtomSpace avoids much of this overhead by using (hyper-/meta-)graphs. This enables more effective and simpler traversal algorithms, which in turn allows more sophisticated search features to be implemented. If your mental model of graph data is lists of vertexes and edges, then you will be confused by the AtomSpace.
The actual AtomSpace resembles some aspects of all three, without being specifically any of them. It tries to be general: it wants to let you work with structured data or with unstructured data or with graphs, or any mixture of all three, however you please. It does not force any particular style.
You can store data as ontologies, or as lambda expressions, or as prolog-like logical statements, or as syntactic (BNF-style) productions or as constraints or as RDF/OWL style schemas ... you can mix declarative, procedural and functional styles ... we don't care. The AtomSpace is meant to allow general knowledge representation, in any format.
That said: it means that the AtomSpace is different and unusual. It might be a bit outside of the comfort zone for most programmers. It doesn't have API's that are instantly recognizable to users of these other systems. There is a challenging learning curve involved, here. We're sorry about that: if you have ideas for better API's that would allow the AtomSpace to look more conventional, and be less intimidating to most programmers, then contact us!
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6UWpdQOir0eZ2Xj%2B8rYW1s6DtCurK%2BvJ9qa2WoxL61MVg%40mail.gmail.com.
Michael Duncan
Ben Goertzel
>
alongside our other projects) do not yet have a detailed design for a
Hyperon Atomspace, though we do have a lot of ideas that are in an
intensive form of refinement.
Our hopeful timeline is
-- by end of August, to have a coherent, complete-ish description of
the type-system we want for "Atomese2" (the new programming language
that will be used to create and represent structures in the Hyperon
Atomspace). [this is down to Alexey Potapov and myself]
-- by around the same timeframe, to have a specific proposal for the
distributed-processing and backing-store aspects of Hyperon Atomspace,
leveraging existing key-vector stores and such ... (DAS, Distributed
AtomSpace)
-- by around Sep 15, to have some decisions on what tools we want to
use for implementing Atomese2 and DAS
(e.g. what programming language to implement Atomese2, what key-value
stores as the basis for DAS...)
Note that none of the above are specifically about the in-RAM
"Atomspace" in terms of the containers behind the Atomspace API ...
It would be possible to have a new Atomese2 language and DAS, working
together with the current Atomspace. On the other hand, if we're
implementing a new Atomese2 and DAS, it may end up being most
effective to implement a new local in-RAM Atomspace as well... this
will be considered in mid-September ...
Note that the SingularityNET team that is pushing this Hyperon design
initiative is also heavily using the existing OpenCog system, eg for
the Grace humanoid robot software system, for biomedical AI R&D, and
in the ROCCA project aimed at AI agents collectively playing
Minecraft. So the motive for redesigning/rebuilding is not a feeling
that the current Atomspace/OpenCog is bad, but rather that through
this work (and prior work) we are seeing that some things that are
fairly awkward in the current system could be made much
cleaner/easier/more-efficient in a variant system with some different
characteristics... (key examples are real-time learning interactions
btw external deep learning software and OpenCog; and large-scale
logical-inference meta-learning...)
The Hyperon wiki page contains links to a quite a lot of our
early-stage thinking on all this as it's been evolvlng over the last
year...
--
Linas Vepstas
linus, an outline of the potential new atomspace is here.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/1738876c-09a3-42b7-8884-0b4a8449c250n%40googlegroups.com.
Linas Vepstas
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBduKz%2BcPHTpmaJvMRJS3Y4y56u6RGrHRzaDVq62Ysy3cA%40mail.gmail.com.
Linas Vepstas
So the motive for redesigning/rebuilding is not a feeling
that the current Atomspace/OpenCog is bad, but rather that through
this work (and prior work) we are seeing that some things that are
fairly awkward in the current system
could be made much
cleaner/easier/more-efficient in a variant system with some different
characteristics...
(key examples are real-time learning interactions
btw external deep learning software and OpenCog;
and large-scale
logical-inference meta-learning...)
The Hyperon wiki page contains links to a quite a lot of our
early-stage thinking on all this as it's been evolvlng over the last
year...
--
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBduKz%2BcPHTpmaJvMRJS3Y4y56u6RGrHRzaDVq62Ysy3cA%40mail.gmail.com.
Ben Goertzel
The documents on that "Atomspace" page that Mike linked are not really
the key ones for the Hyperon design, and nor are the 2017 documents
about the DAS so important right now (Senna is in the midst of putting
together something new regarding DAS actually, informed by more recent
investigations...)
In the happy circumstance you decide to take the time to understand
the crux of what we're aiming for w/ Hyperon, Alexey's various
documents linked from
https://wiki.opencog.org/w/Hyperon:Atomese
are important; and then general formal/theoretical context is given by
my 4 papers in the first bullet list in
https://wiki.opencog.org/w/Hyperon
(which are significantly inspired by, and refer to, your work on
sheaves and germs in OpenCog .. you can see that instantly from the
diagrams in the "Folding and Unfolding on Metagraphs" paper).
I understand this is a lot of dense material to go through tho, and
you may not have time...
We are aiming to have concrete proposals for Atomese2 language
(probably with a different name) and {whatever form of Distributed
Atomspace or Atomspace-distributed-processing-framework we have
concluded is most sensible} by (hopefully) end of September.... Your
feedback on these proposals will be valued at that time, and possibly
instrumental...
We had hoped for wrapping up this early first-stage-of-design phase in
July rather than September but with various peoples' summer vacations
and a lot of work for Awakening Health it's taking a little longer.
Anyway these are far from trivial matters as u know...
ben
Linas Vepstas
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBea3_HRLMWsax%2BwSPh5pJ8ZtOsQES5j005KKjJnrKEwtA%40mail.gmail.com.

Nil Geisweiller
On 7/12/21 21:30, Ben Goertzel wrote:
A reasonable step would be for Nil to send you some real PLN and URE inference histories and see what your visualizer does with them...
Is that still needed?
Nil
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CACYTDBeOoqMRD20KFDYPGG1YfRqT0qW4wehOGtTKSqTb%3D6L2Jw%40mail.gmail.com.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/1571e542-776a-2aad-c15f-02aaf8ad1ca3%40gmail.com.
Nil Geisweiller
I see. Well, it's probably not so much that we've lost interest and
more like we're too busy with other stuff, and so less important stuff
get forgotten. Don't hesitate to re-ping when necessary.
Nil
On 9/21/21 12:28, Ivan V. wrote:
> Hi Nil,
>
> I don't know, everybody suddenly lost interest (IIRC Linas was the only
> one interested), and I'm not in position to lead the visualization
> project on my own. Lastly, this thread mysteriously vanished from my
> google groups and my mail account a while ago. Now that it is back
> again, the visualization topic seems a bit strayed from this thread
> about Atomspace, so if anybody is interested in mentoring me toward a
> useful (still a open question) bit of visualization fragment of OpenCog,
> we can continue this conversation in the original thread (this thread is
> branched from the original "MOZI web UI" thread).
>
> Thank you,
> Ivan V.
>
> uto, 21. ruj 2021. u 09:48 'Nil Geisweiller' via opencog
> On 7/12/21 21:30, Ben Goertzel wrote:
>
>> A reasonable step would be for Nil to send you some real PLN and
>> URE inference histories and see what your visualizer does with them...
>
>
> Is that still needed?
>
>
> Nil
>
>
>>
>> On Mon, Jul 12, 2021, 10:59 AM Ivan V. <ivan....@gmail.com
>> <mailto:ivan....@gmail.com>> wrote:
>>
>> I made a small infinity test
>> zooming ovals in, zooming ovals out, ... Surely it's not
>> exactly perfect, but I could live with it.
>>
>> pon, 12. srp 2021. u 17:48 Linas Vepstas
>>
>> Hi Ivan,
>>
>> On Mon, Jul 12, 2021 at 6:00 AM Ivan V.
>> <ivan....@gmail.com <mailto:ivan....@gmail.com>> wrote:
>>
>>
>> Thank you for asking, and my thoughts are pretty
>> obvious. As I understand, URE and PLN are all about
>> proofs, so my thoughts may go in that direction.
>> Suppose we have a natural deduction proof composition:
>> I J K L M N P Q R
>> ----------------- ----------------- -----------------
>> A B C
>> -----------------------------------------------------------
>> You can already see the tree-like composition, but as
>> it may span over a very wide and tall area, it may be
>> required to represent it within an on-demand scaling
>> https://groups.google.com/d/msgid/opencog/CAHrUA34HBqa02JkW9-EVR5OrpSkOWEMGjZBOCPM2vKKpJR2%2B0A%40mail.gmail.com
>> --
>> You received this message because you are subscribed to the
>> Google Groups "opencog" group.
>> To unsubscribe from this group and stop receiving emails from
>> it, send an email to opencog+u...@googlegroups.com
>> <https://groups.google.com/d/msgid/opencog/CAB5%3Dj6UgLR5xMP9WeE%2BWOkqBynGTr%2BNQTwsmUq9JrSuU1Sh1ZA%40mail.gmail.com?utm_medium=email&utm_source=footer>.
>> --
>> You received this message because you are subscribed to the Google
>> Groups "opencog" group.
>> To unsubscribe from this group and stop receiving emails from it,
>> send an email to opencog+u...@googlegroups.com
>> <https://groups.google.com/d/msgid/opencog/CACYTDBeOoqMRD20KFDYPGG1YfRqT0qW4wehOGtTKSqTb%3D6L2Jw%40mail.gmail.com?utm_medium=email&utm_source=footer>.
> --
> You received this message because you are subscribed to the Google
> Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails from it,
> send an email to opencog+u...@googlegroups.com
> <https://groups.google.com/d/msgid/opencog/1571e542-776a-2aad-c15f-02aaf8ad1ca3%40gmail.com?utm_medium=email&utm_source=footer>.
> --
> You received this message because you are subscribed to the Google
> Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to opencog+u...@googlegroups.com
> <https://groups.google.com/d/msgid/opencog/CAB5%3Dj6VVz4h1zkKFg_R1w0kmw6yDfdyrXeyY3L48AT41Dt4teA%40mail.gmail.com?utm_medium=email&utm_source=footer>.
Nil Geisweiller
anyone in need just let me know.
Nil
On 9/21/21 13:00, Ivan V. wrote:
> Ok then.
>
> <http://ocog.atspace.cc/infinite/>, and I've got some free time. Let me
>
> All best,
> Ivan
>
> sub, 10. srp 2021. u 18:53 Ivan V. <ivan....@gmail.com
> Hi all :)
>
> Just thinking out loud, these may be some suggestions...
>
> visualization)
> none potential for graph visualization)
>
> Do I miss something more ear-catching, and more applicable to graph
> visualization? Does this make any sense at all with fitting into the
> big OpenCog picture? Lastly, does anyone have any interest in
> contributing to any of these use cases?
>
> And another "hey" from my littleness - according to Linas'
> visualisation idea, if someone decides to roll on the whole thing,
> and if server side scripting not a problem, I would be interested in
> sponsoring the OpenCog foundation with a fractal graph visualizer
> for tree structures repo that I'm developing for some time now. Of
> course, I am able to adjust the visualizer licence to OpenCog
> licencing standards, and I'm prepared for very flexible terms, so no
> worries from that side.
>
> Be well,
> Ivan
>
>
> sub, 10. srp 2021. u 07:27 Ivan V. <ivan....@gmail.com
> May I ask did you solve the problem from bullet No. 1? Who will
> use it and for which purpose?
>
> uto, 6. srp 2021. u 00:54 Linas Vepstas <linasv...@gmail.com
> https://reactstudio.com
> <https://reactstudio.com> or https://builderx.io
> <https://builderx.io>.
> is possible and I have been using
> multiple atomspaces to run
> annotation tasks but haven't
> developed a generic UI around it.
>
> 2) I was actually planning to extend
> the gRPC server by integrating it
> Unfortunately, I didn't find the
> time to implement it. AFAIK, Grafana
> handles much of the UI stuff and
> only needs some API for it to be
> used as a dashboard/monitoring tool.
> I think this is easier than writing
> a new UI code.
>
> 3) For the visualization, in
> addition to the visualizer in
> https://github.com/opencog/external-tools/
> Cytospace visualizer that visualized
> atoms representing biochemical
> entities using custom layouts. This
> is the visualizer used in the
> annotation service you linked above.
> The main issue we had with the
> Cytoscape visualizer was calculating
> the layout algorithms on the
> front-end when the size of the graph
> got bigger. I suppose anyone who
> wants to use a data explorer with
> the atomspace will eventually run
> into such a performance issue as the
> atomspace gets bigger. To resolve
> this, I created a small library
> --
> You received this message because you
> are subscribed to the Google Groups
> "opencog" group.
> To unsubscribe from this group and stop
> receiving emails from it, send an email
> to opencog+u...@googlegroups.com.
>
> To view this discussion on the web visit
> <https://groups.google.com/d/msgid/opencog/CAPPXERrWx4%2B59Kf163pAnmyaOD%2B5bbQ0pSJ89vFbE50CPrSLNw%40mail.gmail.com?utm_medium=email&utm_source=footer>.
>
>
> --
> Patrick: Are they laughing at us?
> Sponge Bob: No, Patrick, they are laughing
> next to us.
>
>
> --
> You received this message because you are subscribed to
> the Google Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails
> from it, send an email to
> opencog+u...@googlegroups.com
> <https://groups.google.com/d/msgid/opencog/b750b969-6cb6-4303-b986-7e963e0d90bfn%40googlegroups.com?utm_medium=email&utm_source=footer>.
>
>
> --
> Patrick: Are they laughing at us?
> Sponge Bob: No, Patrick, they are laughing next to us.
>
>
> --
> You received this message because you are subscribed to the
> Google Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails
> from it, send an email to
> opencog+u...@googlegroups.com
> <https://groups.google.com/d/msgid/opencog/CAHrUA35tErzxe%3D%2Bj2hObh36d__4Ghmi_u7b9cJ3LuK8PD%3DeXsQ%40mail.gmail.com?utm_medium=email&utm_source=footer>.
> --
> You received this message because you are subscribed to the Google
> Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to opencog+u...@googlegroups.com
> <https://groups.google.com/d/msgid/opencog/CAB5%3Dj6Uyjdc4DLmGwrV%2Bn77Yybv4RR1-9yHUifRAhrbisDnejw%40mail.gmail.com?utm_medium=email&utm_source=footer>.
Linas Vepstas
Chicken-fried steak? Do we need to make you an honorary Texan?
> and this, and I've got some free time. Let me know if I can be useful regarding the OpenCog visualization attempt.
Neither are "deep", (hierarchical deep) both are "broad" (have many
connections)
By contrast, Nil's inference trees are more likely to be deep.
-- linas
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37CeXb842bPi2QP6W9f%2B41PWLZQvi9gKJqmD3-vOUeBoQ%40mail.gmail.com.
Linas Vepstas
>
> > Chicken-fried steak? Do we need to make you an honorary Texan?
>
> Linas, I can't work in such an atmosphere. If that’s the best you can offer, we need to split up. In that case, thank you all for your time but this is too much for me.
Your demo had the words "chicken steak" in it. I've travelled around
the world, and the only place that I know of that has "chicken steak"
on restaurant menus is Texas. They have it in Germany too, but it's
called "Weiner schnitzel" there. (There are a lot of Germans in
Texas.) But you wrote "chicken steak" and not " Weiner schnitzel" ...
https://en.wikipedia.org/wiki/Chicken_fried_steak
https://en.wikipedia.org/wiki/Schnitzel
-- linas
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA36jr9g2pWav5sSCJsBi-aXC1PNi19SeKyGOMoRiBk0vwQ%40mail.gmail.com.
Linas Vepstas
>
> As for the visualization tool, I'll have more time in a few weeks when I settle some of my obligations.
into doing something.
> Then, a kind of OpenCog debugger (or IDE) is what I have on my mind.
entertainment. If it turns out to be useful for others, that would be
wonderful, but, as this long conversation has shown, there's no
general vision of what anyone wants. Different people want different
things; what's useful for one is useless for another.
> It would be something like an atomspace editor communicating to cogserver, showing inference trees related to edited fragments. Nothing too fancy, no dozens of options, just a simple atomspace expressions writing aid, as minimalistic as it can get, with an editor on the left and related inference trees on the right side.
backward chainer, and have almost nothing to do with the atomspace.
(other than that they are kept in the atomspace ... for a while ..
until they are deleted. Nil can supply those if that is what you
really want.)
(2) Don't worry about the cogserver. Don't use the cogserver. Just
work with the atomspace directly. Why? (a) you don't need the
cogserver to get things done. (b) if you absolutely must have a
network connection to some remote AtomSpace, use the CogStorageNode
-- it will automatically open a network connection to a remote
AtomSpace, and it will automatically trade atoms with it, bringing
them over to your local AtomSpace. You just have to specify which
atoms. If you are not sure which atoms, you can easily run a query on
the remote AtomSpace.
Documentation:
https://wiki.opencog.org/w/CogStorageNode
Demos:
https://github.com/opencog/atomspace-cog/tree/master/examples
-- linas
Ivan V.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34zZ%2BqFdgycq8PQjp1BvikD0b1Y8HSRSebMMxCfeF5p8Q%40mail.gmail.com.
Linas Vepstas
>
> Just a quick question while we're at it, if I may: what is the best way to communicate between web browser and atomspace?
that was weird, slow, mis-designed, old and incomplete...
Let me take you on a trip.
What is really needed are some javascript bindings that talk to the
cogserver. It is very easy, trivial, even, to talk to the cogserver,
and get a reply. The hard part is to convert the results into whatever
javascript you want -- we do not have any existing layer for that.
Creating this layer would be an excellent project.
Thus, for example:
-- use javascript to open a socket to 17001
-- send command over that socket; for example,
`(cog-value (Concept "foo") (Predicate "some key"))`
-- read the result, for example
`(FloatValue 1.000000 2.000000 3.00000)`
-- close the socket, or re-use it.
Great! But how do you convert `(FloatValue 1.000000 2.000000
3.00000)` into what you want? (What do you want?)
Now, before you get on that airplane, and start writing code to use
javascript to talk to the cogserver, consider this:
If you wrote that code, you would have to cache the results locally,
in javascript. That is, you would have to create a local, in-browser
copy of (Concept "foo") and (Predicate "some key") and remember that
(FloatValue 1 2 3) is attached to it. In other words, you would be
re-inventing the atomspace, locally, running inside the browser. Good
god, why? We already have an atomspace, why reinvent a
browser-specific one? (Because this is what things like the
atomspace-explorer were doing.)
The correct solution is this: create javascript bindings for the
atomspace. That's it, end of story. Want to talk to some remote
AtomSpace? Just use the CogStorageNode! That's it, you're done.
I'll stop writing the email here .. because there is nothing more to
say! People who use web browsers need javascript. If we had javascript
binding to the atomspace, you would have it in your browser.
If you want to create these bindings, I'l create a github repo under
the opencog project, give you full write permission, and you can do
whatever in there. I'm sure many people could use them.
--linas
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35-K8V6T3V%2BM7nLSze0NdPhcuk9txBNAoMAd1XJ%3DGekEw%40mail.gmail.com.
Linas Vepstas
On Thu, Sep 23, 2021 at 10:51 AM Ivan V. <ivan....@gmail.com> wrote:
>
> Thank you, I'll take some time to think about it if you don't mind.
thought about it a bit, and realized that I could hack up a basic
solution in a day. So I did. If you grabe the very latest atomspace
and cogserver code, then you get a simple network API to the
atomspace, here. The README explains all:
https://github.com/opencog/atomspace/blob/master/opencog/persist/json/README.md
The JSON is delivered as a string, over the network. You still have to
do something with it. If/when you want to create javascript, node.js,
emscripten, or whatever kind of interfaces to it, let me know. I just
now create a new, empty git repo at
https://github.com/opencog/atomspace-js
Anyone who is interested should just ask, I'll provide write access to
that repo.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA36dV20DGvtE2hTP94q48-f5BrtBjRi3h%2Bv5U6hYhr3MsQ%40mail.gmail.com.
Ivan V.
Linas Vepstas
Well that was fun!
There are two REPL loops (four, actually) the guile/scheme repl loop;
the guile/scheme repl loop provided by the cogserver, which is almost
the same except it runs over telnet. Then there's the python repl,
and the cogserver provides a telnet python repl, too. The telnet
python REPL is almost the same as regular python, but not quite, it
hand;es whitespace differently. Python is to blame for that:
whitespace rules for repls are different from whitespace rules on
files. Whatever. At any rate, these are all inter-operable: atoms
created in one show up in the other.
An interesting visualization is this one:
(List (Word "this") (Word "that"))
(List (Word "this") (Word "thing"))
(List (Word "this") (Word "cat"))
(List (Word "that") (Word "cat"))
...
So, if you start at (Word "this") and move up, you'll find a thousand
List's. Pick one (say, "cat") move down and then back up, you'll find
a thousand Lists that "cat" is in. Bouncing around in this network
can be entertaining, provided the pairs are meaningful.
The point here is that the s-expression (Word "that") is globally
unique: it is one and the same, everywhere.
--linas
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35rxQTu%2BNG7-k0h791LruXCLksyUCju-YgzGTC4eaQMOw%40mail.gmail.com.
Linas Vepstas
>
> Hi linas,
>
> Nice to see someone having fun with this thingy :)
Maybe it's covid.
> Thousands of nodes might seem a bit of overkill for this system, especially considering the fact that this system is a brute s-expression listing machine, without caring what nodes stand for the same one. I believe the system wouldn't choke on that, but navigating them would be a Hell of a task.
> However, there is one trick that might render all this usable: what if there was a query system (already a part of AtomSpace) to narrow down only the nodes we are looking for.
> For example, a command `display some-query` could intercept an output and pipe such an output to the visualisation module, showing only atoms of our interest, not the entire Atomspace.
directly. The actual syntax would be
(display (cog-execute! (MeetLink ... the actual query)))
and since display doesn't print a newline, use formated print instead:
(format #t "And the answer to the query is ~A\n" (cog-execute!
(MeetLink ... the actual query)))
> I was also thinking of advancing REPL to editing sessions for Atomspace scripts.
I guess you mean a new web-page repl?
> Such session would first check if Atomspace is empty (eg. no one is currently using it).
existing database, or dump a bunch of atoms in.
> Then the telnet would populate Atomspace from the editing session, with intercepting `display` commands, concatenating them ino one s-expression and piping it out to the visualizer. Lastly, after ending the script, telnet would wipe out the entire Atomspace to prepare it for the next visualization cycle.
However, there is one weird trick ...
In your local atomspace, you can do this:
(cog-open (CogStorageNode "cog://example.com:17001"))
(fetch-atom (Concept "foo")) ; this will get all the (truth) values ...
(store-atom (Concept "bar")) ; this will store all the values
(fetch-incoming-set (Concept "foo")) ; get every Link that foo is inside of ...
so if example.com is running a cogserver on port 17001, then you can
have access to it. and copy atoms between it and your local atomspace.
Just don't trash it's contents, the owner might not be happy.
--linas
Ivan V.
- read - print - loop (RPL without Eval in the middle)
- remembering history of passed input
- reporting errors on invalid s-expressions
- visualizing valid s-expressions
What remains is the juicy part - connecting eval and print to OpenCog server REPL. Hopefully soon.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37UtMHuv-UvU3vUqnCqSuFf0Kvx3%2Be0RHPctdwrJ26aLw%40mail.gmail.com.
Ivan V.
Linas Vepstas
>
> Hi Linas and others,
>
> Sorry for the delay, I've been busy with my other projects. Now I tried to install OpenCog, made through several make steps until my machine started to hang. Tried several times, it always hangs on the same build step. I guess this is a penalty for having only 4GB on my machine, right?
when new, so low end from the get-go.). I can even browse the web
while it's building.
Open a bug report. describe the problem.
> And then I tried another option: I installed OpenCog from here: `https://github.com/opencog/docker`. I tried to follow `README.md` instructions, ran `./docker-build.sh -a` (the script successfully completed), but then I got stuck starting cogserver because the `cogserver/build/` folder is empty.
--linas
Ivan V.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34a2O624WCfk821t3wqUEYeg0WM%2B571AOKxGG2cCUB_xA%40mail.gmail.com.
Linas Vepstas
>
> Ok, this was fun...
>
> I restarted the computer in the meanwhile, deleted the whole OpenCog, and recloned and rebuilt everything without any problems. This time I put all the additional assets I needed like cogserver under `opencog` directory, if that means anything.
building, saying `sudo make install` puts everything under the
`/usr/local` directory.
My guess is that you had old and incompatible clones: you would have
to say `git pull` in all repos, to get a self-consistent version.
> Cogserver is now up and running on port 17001, successfully communicating to rlwrap telnet. The initial test went fine.
>
> Next, the plan is to telnet it from php, and pipe it to html visualizer, if that's ok.
Warning, there are two incompatible versions of netcat you can
install. They are *almost* compatible, but not quite; one needs an
extra flag that the other doesn't, else it hangs up too soon.
I have the bsd version installed the package is `netcat-openbsd`
Use it like so: `nc localhost 17001 (+ 2 2)` or `nc localhost 17001
(cog-prt-atomspace)` and so on.
> Wish me luck :)
Good luck! and Merry Christmas, too!
-- linas
>
> - ivan -
>
> pon, 20. pro 2021. u 20:00 Linas Vepstas <linasv...@gmail.com> napisao je:
>>
>> On Sun, Dec 19, 2021 at 2:11 PM Ivan V. <ivan....@gmail.com> wrote:
>> >
>> > Hi Linas and others,
>> >
>> > Sorry for the delay, I've been busy with my other projects. Now I tried to install OpenCog, made through several make steps until my machine started to hang. Tried several times, it always hangs on the same build step. I guess this is a penalty for having only 4GB on my machine, right?
>>
>> It builds just fine on my six-year-old 1GB laptop (which cost $200
>> when new, so low end from the get-go.). I can even browse the web
>> while it's building.
>>
>> Open a bug report. describe the problem.
>>
>> > And then I tried another option: I installed OpenCog from here: `https://github.com/opencog/docker`. I tried to follow `README.md` instructions, ran `./docker-build.sh -a` (the script successfully completed), but then I got stuck starting cogserver because the `cogserver/build/` folder is empty.
>>
>> The docker containers are possibly stale.
>>
>> --linas
>>
>> --
>> You received this message because you are subscribed to the Google Groups "opencog" group.
>> To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
>> To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34a2O624WCfk821t3wqUEYeg0WM%2B571AOKxGG2cCUB_xA%40mail.gmail.com.
>
> --
> You received this message because you are subscribed to the Google Groups "opencog" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
Linas Vepstas
Try this:
echo "(+ 2 2)" |nc -N localhost 17001
The -N flag closes the socket after getting the reply, otherwise it
hangs waiting for more input.
So you'd replace the echo by php print and pipe to command.
-- Linas
Linas Vepstas
echo -e "scm quiet\n(+ 2 2)\n" |nc -N localhost 17001
The "quiet" mode suppresses the printing of the guile prompts.
Unfortunately, the first prompt is always sent :-(
-- linas
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35jXYy0AgLtum%3DvynpN%3DjvTH0r%2Bv5NPnBWncMVAxaKjtw%40mail.gmail.com.
Linas Vepstas
Some quick remarks about networking.
-- Using telnet to access the cogserver is wild technology overkill.
Telnet was designed to provide a teletype terminal over the network,
including lots of complex teletype escape sequences. The cogserver
needs exactly zero of that.
-- the cogserver network interface is extremely low-level. So
low-level, you can't get any lower. It's rock-stupid simple and basic.
You open a socket. A very basic, simple, plain ordinary socket. Then
you read and write characters to it. That's all. That's it. It's not
any harder than opening a file, and reading/writing to that. Uses the
same read/write API that files use. If you know sockets well (and it
seems very few people do) it's about 5-10 lines of code. Or less.
There's absolutely no need for complexity.
I don't know php well enough, but the pseudocode really should be
```
sock = open (locahost, 17001)
write (sock, "(+ 2 2)")
read(sock, buffer)
close(sock)
```
Really little or nothing more than that..
FWIW, that's my coding philosophy: remove as much complexity as
possible ("but no more"). Kind of everything is guided by that.
Linas

Jacques Basaldúa
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37G6CUQrdHQpwMS%3DkmM3StUZNCrUrmsVohr-sd51ZSsgA%40mail.gmail.com.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CA%2B_pmb6BgsVcp%2B9HuYY%3Dmm-%2BwNjmf7aX7aBLK1ZJ1R%3DxwZpe-Q%40mail.gmail.com.
Linas Vepstas
>
> Thank you, Jacques, for your thoughtful response.
>
> I've been experimenting with php for a few hours now. It's exactly as Linas said, like reading and writing files, completely php native, no addons. I'll probably go like an ajaxing php script that opens a connection, sends a command, reads a response, and closes the connection. Things look promising for now, it is just that little something I'd like to avoid: mandatory sleeping php for 125 milliseconds (on my machine) to give a time for getting the response after sending a command. But I'm out of ideas on how to avoid it.
-- conventionally, socket-reads are blocking: the call does not return
until there is something to be read,
-- blocking kills interactivity, so usually people do socket i/o is
done in it's own thread.
-- if you don't like threads, then there are async i/o libraries that
try to avoid this,
-- and it rapidly goes downhill from there, because you have to deal
with things that hang, never return, crash, return only partial
messages, and its a general horror show.
-- I've used one async library in my life, the boost c++ async
library, and it is 100% awful.
This is why network programming is challenging.
--linas
p.s. you don't have to close the cogserver socket after one message,
you can keep it open.
Ivan V.

All of this is really a visual html/php app that communicates to OpenCog. On the left pane, there is a scheme command prompt where commands are sent to CogServer. Upon each command send, the command output is brought back to the prompt interface, and the right pane visualizer is updated to reflect the current AtomSpace contents. I believe it could be fun communicating to OpenCog this way.
Unfortunately, the app has to be installed on a local machine in order for php telnet to communicate to a local CogServer instance which is not visible to the public web. This means having php and web server on a local machine in order to run the app.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34AdmAmWMxNL4dXD4ReNgcrybOiF8JXQgv2Aa7r_On09Q%40mail.gmail.com.
Linas Vepstas
And finally, I'd like to hear if the app fulfills criteria for inclusion in the official OpenCog distribution.
If it does, I'm interested in sending a pull request at a place you'd find appropriate.
it could be fun communicating to OpenCog this way.
Ivan V.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37kKaJXSio4jv-YycGp4tP%2Bdk-5DCCv6eS1F21VoJ4KZg%40mail.gmail.com.
Ivan V.
Ivan V.

Linas Vepstas
Sorry for the late response, I guess I was taking a vacation from myself.
... More reblow
On Thu, Dec 23, 2021 at 11:33 PM Ivan V. <ivan....@gmail.com> wrote:
>
> I also decided to change the app name to "CogServerLab", if that's ok. The name is unique, and Google Search likes it.
https://github.com/opencog/cogprotolab/
per your later emails. I could not figure out what your github ID is,
so I could not give you access. What's your github ID?
> I can't express my gratitude, it is the best Christmas present ever. Thank you very much.
> Also, what license does OpenCog prefer?
> > It would be fun to load up the atomspace with one of the big datasets, e.g. at https://linas.org/datasets/ and prowl around in that and see what happens.
>
> It depends on the amount of RAM. The biggest issue is bitmap caching, so if each oval takes 500 x 500 pixels in average, 4B per pixel, then it is about 1MB per oval, meaning 1GB of free ram should be able to hold about 1000 ovals. In practice, the shallowest oval bitmap is the biggest one, grading down with structure depth. Maybe I could work on this, to remove caching, then it would be more scalable because only visible ovals would take the bitmap memory, but the rendering would be slower and blocking. I'll try to provide both versions (cached and non-cached) switch in a separate configuration file. Other than bitmaps, an s-expression array and its tree structure array are required to reside in RAM all the time.
a millisecond per bubble.
> But I'm not sure that mega-sized-datasets are practical examples of using CogServerLab.
toy problems and demos, datasets consisting of 1 to 100 million atoms
would be "typical". They fit easily into RAM, they don't need the
fancy footwork that Ben talks about.
> I imagine some other uses where newbies can play with a few hundreds of atoms while learning how AtomSpace behaves on what Scheme commands in a realtime. It would be also great to see someone making an OpenCog introduction or feature video using CogServerLab. Certainly, I agree CogServerLab wouldn't be the most useful application in the world, but I guess it could be fun to play with.
entry level stuff.
> Otherwise, what is happening with OpenCog Wiki pages? It would be nice to have an objective reference to CogServerLab from there.
Accounts have to be added by hand, as otherwise spammers take over.
--linas
Linas Vepstas
Hi,Progressing further in a hope that someone finds this useful:CogProtoLab isn't tied only to visualizing hidden (cog-prt-atomspace) command output anymore. Now there is an input field where we can put any query to an AtomSpace part intended to be visualized.

Ivan V.
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37X0pXKFvnJUkv%2BHSviVD2ThJ_h1bcd_un7%2B9nKb6SR8A%40mail.gmail.com.
Linas Vepstas
Hi Linas,A simple feature update on your idea: a configurable menu of queries is implemented - I still don't know of what form are the standard queries to include them in the menu, but it should be just a matter of adding strings in a separate quasi-JSON init file.
+ (append-map (lambda (SEC) (LLOBJ 'get-cross-sections SEC))
+ rsect-list))
+ (format #t "before all cross= ~A\n" (prt-element XSE)))
+ allx)
For now I included only (cog-prt-atomspace) and a rudimentary inheritance-variable-concept matching, but I hope to get some help in this direction. And of course, all other ideas, suggestions, advices, feature requests, or any other criticism or help is more than welcome.My github ID is: contrast-zoneI look forward to a fruitful collaboration :)Be well,- ivan ---sri, 5. sij 2022. u 00:58 Linas Vepstas <linasv...@gmail.com> napisao je:--On Tue, Jan 4, 2022 at 2:21 PM Ivan V. <ivan....@gmail.com> wrote:Hi,Progressing further in a hope that someone finds this useful:CogProtoLab isn't tied only to visualizing hidden (cog-prt-atomspace) command output anymore. Now there is an input field where we can put any query to an AtomSpace part intended to be visualized.That would actually be awesome! A menu or drop-down list of standard queries would be great ... writing queries by hand is tedious and error-prone, and they're verbose, so having a menu would be great. A configurable menu would be even better.--linas
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA37X0pXKFvnJUkv%2BHSviVD2ThJ_h1bcd_un7%2B9nKb6SR8A%40mail.gmail.com.
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.

To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6VN_j_%3D7UxW_4U40%2BXGy6L1zn62U%3Dzq7UEx28Fa5_kTNQ%40mail.gmail.com.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA34APJmf-FeOM2dnNDOzcndYhjxaXzTxXazTHy%3DtF-%2B3wg%40mail.gmail.com.
Linas Vepstas
Linas,Thank you for the invite, I uploaded the initial commit.
Queries you use are pretty specific to tasks one wants to accomplish.
(cog-report-counts) seems interesting, maybe I'll give some thought to that. But something else bugs me more (beside raising the loadable atoms count limit). If some commands run for a long time, CogProtoLab sleeps in the meanwhile, waiting for the final result. Moreover, long running processes may occasionally print out some status or some info, before finally ending, as is in your case. CogProtoLab doesn't print anything while it sleeps, as it only reads the entire finished output in a Javascript AJAX call prone to connection timeout. Maybe some php thread simulation, partial AJAX reads, or something similar would solve it, I'll have to think about it and inform myself more properly about solving this problem.
But as I see CogProtoLab right now, it is more like a beginner's toy than a full blown scientific dashboard. Maybe someday it may grow beyond being just an introductory toy, but it would still be a kind of a toy, this time for serious people who are playful kids in their hearts. It would certainly be interesting to see what kinds of queries are possible in structuring their clever results in parent-child manner, but the road seems not too easy.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6XeZwSmgZXLiE9RrKT4jLFehUy62dPdPMpJ23PtHyMbWA%40mail.gmail.com.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA35nDvOGCmPwLpoRD27Q8abv-KHtvsDa85Knb1LrJ8_Cvg%40mail.gmail.com.
Linas Vepstas
I'm stuck at the RuleBasedEngine implementation part (it was a Hell of a problem to me just to conceptualize it), but things are developing in the right direction, maybe slowly, but steadily.
but then I have to return to my main project because I need something more than air to survive.
And just to be noted, the more I learn about AtomSpace, the more I like it.
There are some things I'd do differently,
but AtomSpace is already here and working well right now, at this moment. Good job.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6W73LrT7JL6KR6q7Q48YLEZdDcT64tfGiv48OwmvmPxYw%40mail.gmail.com.
Ivan V.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAHrUA36A_cVzAtYaxVFh0%2BokoJMDuNZ3W8nprLC2u0jaJD110A%40mail.gmail.com.
Linas Vepstas
> Perhaps I could convince you to look at the URE, and figure out how to layer your idea of a "rule" on top of it?Well, it has begun to be more of a personal matter between me and God. I've been working and experimenting on this cause for more than twenty years now, and although I reinvented the hot water with most of my work, I feel I'll just explode if I don't do it my own way now. Now I'm aware of URE and Prolog, those are good tools, and it would be faster for me to use them, but I also have this little bit different perspective of mine to try to justify my efforts. I simply can't come out of all this trouble with my empty hands. I hope you'll understand it.
Ivan V.

- UX regarding to sending commands / updating visuals is redefined
- left-top pane is redesigned to include some utilities we considered helpful
- cmd-delay time is removed. Php telnet script now waits for
guile>prompt to be read, then returns the output. Interfacing command prompt works faster now. - some bugs have been eradicated
Linas Vepstas
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/opencog/CAB5%3Dj6UCYKNykYfOvGqTaENQACU8Hi9Z61wbejK%2BYzEnyWosPg%40mail.gmail.com.