Making OpenCog more developer friendly
177 views
Skip to first unread message

Keyvan Mir Mohammad Sadeghi
Jul 2, 2014, 7:25:38 PM7/2/14
to opencog, Benjamin Goertzel, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Hi,
--
I'm opening this thread for general brainstorming on a subject that's going to matter probably the most for the near future of OpenCog: becoming more developer friendly.
Having been around the project for about three years now, it's my understanding that OpenCog does have a "Wow Factor" for hobbyists visiting the project's website/github with different backgrounds, but then it falls short of offering immediate opportunities for them to participate. This is of course my subjective opinion, but if there are others who have thought the same at some point, views/suggestions are very much appreciated.
A random observation: probably the worst code I've ever written for OpenCog is the BayesNet code. It's incomplete, inconsistent, lacks any documentation/unit-test, absolute rubbish one might say. Surprisingly, recently there has been interest on this master piece of mine:
Maxwell Bertolero: By the way, this would be super helpful to anyone who does Bayes Net with Python, as no triangulation code exists out there.
I later found that he was wrong and good python BayesNet code does exist, but the takeaway from the conversation with Maxwell, for me, was that there are probably many other usages for OpenCog's code for people who don't do any AI/AGI whatsoever and it does not seem very smart not to make the most of this opportunity.
Noting that the eBay's BayesNet code was initiated in Apr 2013 (my code precedes this date), it wouldn't surprise me to see my shitty BayesNet code become more popular and even have it's own community by now, IFF it was initiated as a separate repo.
The OC code could be viewed as two categories:
- Logic: the code that implements a concept
- Glue: code that connects the logic to the rest of OC
As a starter, I suggest that we separate the above entities: glue code goes in the main OC repo and each Logic gets a repo of it's own. I do realise that this won't be possible to do with some spaghetti code that we might have, but it certainly is with the new components. As an example, my fuzzy/probabilistic Allen Interval Algebra code is currently a logic without glue; it can work as standalone and isn't yet integrated with the rest of OC. I argue that there exists an Interval Algebra community that might be interested in this code, and if I don't move it to a separate repo before integrating it with the rest of opencog, it might end up becoming another spaghetti bowl at our hands that no one but few understands it in a few years time. Fortunately, it's not hard to move sub-folders to their own repo in github:
I remember having a similar discussion with Ben a long time ago, his main objection about having a part of code in a separate repo was: "but what if they later want to make it work with other parts of OpenCog?". I did not have an answer back then, but now I do: "they can write the glue code!". A great tool towards this end could be docker, I hope that David Hart chimes in and correct me if I'm wrong, but I remember asking him if it would be possible to have a project's components in different repos and assemble them on installation by docker, and the answer was yes.
Conclusion, there are many who might not have the slightest clue/interest about AI/AGI, but are experts in other fields. Reorganising the project in such way that appeals to this group might be of great value and something to consider.
Cheers,
K
Keyvan Mir Mohammad Sadeghi
MSc AI
"One has to pay dearly for immortality; one has to die several times while one is still alive." -- Friedrich Nietzsche
MSc AI
"One has to pay dearly for immortality; one has to die several times while one is still alive." -- Friedrich Nietzsche

Ben Goertzel
Jul 2, 2014, 7:53:42 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Hi Keyvan,
We have taken that strategy with pieces of code that have meaningful operation apart from the Atomspace, e.g. RelEx and MOSES.
However, for much of our current work, we are focusing on making various AI functions interoperate rely *more* heavily on the Atomspace rather than less.... And if something depends heavily on the Atomspace, then providing it separately doesn't make sense....
For example, we are planning to reimplement many OpenCog functions (PLN, the planner, eventually RelEx) in a way that uses the Pattern Matcher (on the Atomspace) for the basic rule application step...
In short, as a general principle I think it makes more sense to push OpenCog in the direction of being "a special, integrated programming language and environment based on the Atomspace" than in the direction of being "a heterogenous AI toolkit"
However, when something is coded to operate separately from the Atomspace, but in coordination with OpenCog, I agree it makes sense to also make it available in a separately packaged form.... I guess your interval algebra code fits this description. However, I'd note that without good documentation the interval algebra code will not be useful to anyone; lack of documentation is a much more serious problem than being packaged with OpenCog or not IMO .... how's progress on that documentation? 8-D ...
-- ben
--
Ben Goertzel, PhD
http://goertzel.org
"In an insane world, the sane man must appear to be insane". -- Capt. James T. Kirk
"Emancipate yourself from mental slavery / None but ourselves can free our minds" -- Robert Nesta Marley
Ben Goertzel, PhD
http://goertzel.org
"In an insane world, the sane man must appear to be insane". -- Capt. James T. Kirk
"Emancipate yourself from mental slavery / None but ourselves can free our minds" -- Robert Nesta Marley
Ben Goertzel
Jul 2, 2014, 8:07:05 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
hah, cool, I just saw Sebastian made a start on the documentation for the interval algebra code.
Thanks, Sebastian !! ;)
Keyvan Mir Mohammad Sadeghi
Jul 2, 2014, 8:08:08 PM7/2/14
to opencog, Benjamin Goertzel, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Hi Ben,
We have taken that strategy with pieces of code that have meaningful operation apart from the Atomspace, e.g. RelEx and MOSES.
Cool. But I don't see a MOSES webpage, a separate repo and a MOSES community apart from my beloved friends in OC despite the fact that MOSES potentially has a great appeal to the ML community.
However, for much of our current work, we are focusing on making various AI functions interoperate rely *more* heavily on the Atomspace rather than less.... And if something depends heavily on the Atomspace, then providing it separately doesn't make sense....
In what way does moving the parts that work "heavily" with AtomSpace to a separate "place" makes them work "less" with AtomSpace? If the AtomSpace itself had it's own repo, it would have been something like HyperGraphDb by now. Guess you miss-understood me, I didn't propose "decomposition", rather, "organisation".
In short, as a general principle I think it makes more sense to push OpenCog in the direction of being "a special, integrated programming language and environment based on the Atomspace" than in the direction of being "a heterogenous AI toolkit"
That was not the idea, but now that you said it, it actually sounds cool! May I ask why you'd appose having components of OC becoming tools of their own and hence widen their application domain?
However, when something is coded to operate separately from the Atomspace, but in coordination with OpenCog, I agree it makes sense to also make it available in a separately packaged form.... I guess your interval algebra code fits this description.
Good. So you are partially against the idea but not totally? ;p
However, I'd note that without good documentation the interval algebra code will not be useful to anyone; lack of documentation is a much more serious problem than being packaged with OpenCog or not IMO .... how's progress on that documentation? 8-D ...
I'm working step-by-step with Sebastian. You'll hear more from me soon ;)
Ben Goertzel
Jul 2, 2014, 8:17:07 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Hmm... you say
> As a starter, I suggest that we separate the above entities: glue code goes in the main OC repo and each Logic gets a repo of it's own. I do realise that this won't be possible to do with some spaghetti code that we might have, but it certainly is with the new components.
According to Wikedia,
"
Spaghetti code is a pejorative term for source code that has a complex
and tangled control structure
"
...
However, it is not "spaghetti code" (i.e. bad, tangled up coding
style) that makes it inappropriate to separate out something like
ECAN, or the new PLN (that is currently in progress, and will rely on
the Atomspace and Pattern Matcher heavily) from the rest of OpenCog.
Rather, it's simply utilization of the Atomspace and Pattern
Matcher.... This utilization means that to build and install these
tools, one has to build and install a lot of OpenCog...
> As a starter, I suggest that we separate the above entities: glue code goes in the main OC repo and each Logic gets a repo of it's own. I do realise that this won't be possible to do with some spaghetti code that we might have, but it certainly is with the new components.
"
Spaghetti code is a pejorative term for source code that has a complex
and tangled control structure
"
...
However, it is not "spaghetti code" (i.e. bad, tangled up coding
style) that makes it inappropriate to separate out something like
ECAN, or the new PLN (that is currently in progress, and will rely on
the Atomspace and Pattern Matcher heavily) from the rest of OpenCog.
Rather, it's simply utilization of the Atomspace and Pattern
Matcher.... This utilization means that to build and install these
tools, one has to build and install a lot of OpenCog...
Keyvan Mir Mohammad Sadeghi
Jul 2, 2014, 8:20:36 PM7/2/14
to opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Yup, I said:
some spaghetti code
Parts of the embodiment code used to fit the Wikipedia description, those are the ones I meant (or is that fixed by now?)
Ben Goertzel
Jul 2, 2014, 8:27:46 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
I'd say there are few worthwhile points here, though...
1)
If some OpenCog-related functionality can be run autonomously without
need of the Atomspace or other OpenCog tools, it should be made
possible for someone to install and build and run that functionality
independently. This has been done pretty well I think, e.g. with
MOSES and RelEx.
2)
Making it easy for someone who just wants to use one OpenCog
functionality to install, build and run that functionality (including
use of the Atomspace) without fussing with other aspects of OpenCog.
I think this will be achieved OK via the OpenCog Dockerfile that David
Hart is preparing. This takes place of Cogbuntu, and should make it
easy for anyone running Linux to get up and running with OpenCog and
any its functions, without much fuss...
3)
Marketing various aspects of OpenCog separately, e.g. marketing
RelEx/RelEx2Logic to computational linguists; marketing MOSES to
machine learning folks; marketing PLN to probabilistic reasoning
folks; etc.
I agree that the OC community has not done a good job of this.
However, it should be recognized that this is a lot of work. I have
put my own energy into marketing OpenCog as an AGI framework, as that
is what I care most about. I don't personally have time to market the
various components. Similarly, Linas and Nil (who have been doing
the most MOSES work) are quite busy too, and not that oriented toward
marketing.
Typically the marketing of AI tools for specialized niches in the
academic and software community seems to be done by academics, who
market the tool they've built to build their own academic status,
brand and reputation, as well as to help the community.
So maybe we should make more effort to recruit academics to grab hold
of particular aspects of OpenCog and market them to particular niches,
sure
4)
Packaging aspects of OpenCog in separate repositories. I don't have a
strong opinion on this, and would defer to David Hart, Linas and
others on this. I think that in itself, packaging code in a separate
repo accomplishes very little, though....
To make e.g. MOSES popular as a standalone ML tool would require
someone to publish papers demonstrating MOSES's prowess on standard
benchmark problems, then go around to academic conferences giving
talks on how great MOSES is, etc. This is what has been done for
SVMs, decision trees, etc. etc. It's not hard to do, and MOSES is
good enough, but it takes a lot of somebody's time, and nobody
involved w/ MOSES has had the time and motivation to do that at this
point...
Similar comments would apply to other components besides MOSES....
-- Ben
--
Ben Goertzel, PhD
CEO, Novamente LLC and Biomind LLC
CTO, Genescient Corp
Adjunct Research Professor, Xiamen University, China
Chairman, Humanity+
Advisor, Singularity University and Singularity Institute
b...@goertzel.org
"My humanity is a constant self-overcoming" -- Friedrich Nietzsche
1)
If some OpenCog-related functionality can be run autonomously without
need of the Atomspace or other OpenCog tools, it should be made
possible for someone to install and build and run that functionality
independently. This has been done pretty well I think, e.g. with
MOSES and RelEx.
2)
Making it easy for someone who just wants to use one OpenCog
functionality to install, build and run that functionality (including
use of the Atomspace) without fussing with other aspects of OpenCog.
I think this will be achieved OK via the OpenCog Dockerfile that David
Hart is preparing. This takes place of Cogbuntu, and should make it
easy for anyone running Linux to get up and running with OpenCog and
any its functions, without much fuss...
3)
Marketing various aspects of OpenCog separately, e.g. marketing
RelEx/RelEx2Logic to computational linguists; marketing MOSES to
machine learning folks; marketing PLN to probabilistic reasoning
folks; etc.
I agree that the OC community has not done a good job of this.
However, it should be recognized that this is a lot of work. I have
put my own energy into marketing OpenCog as an AGI framework, as that
is what I care most about. I don't personally have time to market the
various components. Similarly, Linas and Nil (who have been doing
the most MOSES work) are quite busy too, and not that oriented toward
marketing.
Typically the marketing of AI tools for specialized niches in the
academic and software community seems to be done by academics, who
market the tool they've built to build their own academic status,
brand and reputation, as well as to help the community.
So maybe we should make more effort to recruit academics to grab hold
of particular aspects of OpenCog and market them to particular niches,
sure
4)
Packaging aspects of OpenCog in separate repositories. I don't have a
strong opinion on this, and would defer to David Hart, Linas and
others on this. I think that in itself, packaging code in a separate
repo accomplishes very little, though....
To make e.g. MOSES popular as a standalone ML tool would require
someone to publish papers demonstrating MOSES's prowess on standard
benchmark problems, then go around to academic conferences giving
talks on how great MOSES is, etc. This is what has been done for
SVMs, decision trees, etc. etc. It's not hard to do, and MOSES is
good enough, but it takes a lot of somebody's time, and nobody
involved w/ MOSES has had the time and motivation to do that at this
point...
Similar comments would apply to other components besides MOSES....
-- Ben
Ben Goertzel, PhD
CEO, Novamente LLC and Biomind LLC
CTO, Genescient Corp
Adjunct Research Professor, Xiamen University, China
Chairman, Humanity+
Advisor, Singularity University and Singularity Institute
b...@goertzel.org
"My humanity is a constant self-overcoming" -- Friedrich Nietzsche
Keyvan Mir Mohammad Sadeghi
Jul 2, 2014, 8:29:10 PM7/2/14
to opencog, Benjamin Goertzel
Guess you miss-understood me, I didn't propose "decomposition", rather, "organisation".
Ah, and don't get me wrong, we do have organisation: CMake
I'm merely proposing replacing CMake with docker.
Ben Goertzel
Jul 2, 2014, 8:34:56 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog
Hi,
Yeah, Dave Hart is in the midst of transitioning OpenCog to using
Docker for everything...
Some of the Embodiment code is still a mess, but Lake and Nil have
been cleaning it up lately.... E.g. Lake has partially refactored the
action interface, Nil has been cleaning mess in the Router, etc. But
Embodiment is probably the OpenCog code that would be least
interesting outside an OpenCog context anyway; it's really pretty
specific to interfacing an openCog Atomspace based system with an
external body/world...
ben
Yeah, Dave Hart is in the midst of transitioning OpenCog to using
Docker for everything...
Some of the Embodiment code is still a mess, but Lake and Nil have
been cleaning it up lately.... E.g. Lake has partially refactored the
action interface, Nil has been cleaning mess in the Router, etc. But
Embodiment is probably the OpenCog code that would be least
interesting outside an OpenCog context anyway; it's really pretty
specific to interfacing an openCog Atomspace based system with an
external body/world...
ben
Keyvan Mir Mohammad Sadeghi
Jul 2, 2014, 8:36:55 PM7/2/14
to opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Nice comments, one more from me.
3)
Marketing various aspects of OpenCog separately, e.g. marketing
RelEx/RelEx2Logic to computational linguists; marketing MOSES to
machine learning folks; marketing PLN to probabilistic reasoning
folks; etc.
I agree that the OC community has not done a good job of this.
However, it should be recognized that this is a lot of work. I have
put my own energy into marketing OpenCog as an AGI framework, as that
is what I care most about. I don't personally have time to market the
various components. Similarly, Linas and Nil (who have been doing
the most MOSES work) are quite busy too, and not that oriented toward
marketing.
Typically the marketing of AI tools for specialized niches in the
academic and software community seems to be done by academics, who
market the tool they've built to build their own academic status,
brand and reputation, as well as to help the community.
So maybe we should make more effort to recruit academics to grab hold
of particular aspects of OpenCog and market them to particular niches,
sure
Beware of the open-source magic. Many well-known-by-now projects were initiated as one's hobby. But gradually that 'one' became 'two' and so on. Being open-source is a huge advantage and separate specialised repos will help gaining more attention.
Ben Goertzel
Jul 2, 2014, 8:41:27 PM7/2/14
to opencog, Linas Vepstas, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
There's no magic in open sourcing stuff, really. The internet is full of a huge number of OSS projects that nobody uses or develops. Just putting code online doesn't help much. Don't underestimate the value of marketing and community building. This doesn't have to be large-scale -- it can take the form of one energetic, active developer ongoingly updating and pushing his code and posting demos of what it can do.... But it requires somebody's ongoing energy, creativity and initiative...
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To post to this group, send email to ope...@googlegroups.com.
Visit this group at http://groups.google.com/group/opencog.
For more options, visit https://groups.google.com/d/optout.
David Hart
Jul 2, 2014, 9:25:26 PM7/2/14
to ope...@googlegroups.com, Benjamin Goertzel
Oh, Docker is not a replacement for CMake, rather they are complimentary. A situation like Keyvan describes is likely accomplished best with git submodules which allow for repos within repos, and CMake compile-time integration. OpenCog's CMakefiles certainly need some attention, particularly the portions that generate 'make install' Makefile targets. Docker comes into the picture for things like continuous integration (our buildbot already uses Docker), distributed compiles (our distcc already uses Docker), distributing a collection of OpenCog parts as a packaged whole (Docker container dhart/opencog-cogserver is already built and available/distributed online), and sharing development environments (Docker container opencog/opencog-dev is already built and available/distributed online). From the point of view of the latter two items, Dockerizing an OpenCog codebase split into algos + glue repos is a non-issue once the git submodules and CMake work is done.

Linas Vepstas
Jul 2, 2014, 10:45:58 PM7/2/14
to Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, David Hart, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
I've spent 6 years marketing link-grammar and relex, as best I can, and its gone over with a thud.
As far as I can tell, relex has zero users outside of opencog, although maybe there were 2-3 serious attempts to use it outside of opencog.
Link-grammar has, over time, had maybe 5-6 proprietary users, who seem to use it for 2-3-4 years and then fade away. A game company, a law firm .. supposedly, Cyc used it at one time... I've had almost utterly insignificant contributions from the proprietary users, with one exception 4-5 years ago which could be called "minor".
The Windows users are the worst. As far as I can tell, Windows developers couldn't code their way out of a paper bag.
I ascribe this to the fact that the need for natural language parsing has very narrow appeal.
Compare this to a very successful open source project I've had experience with: GnuCash. Its a personal/small-business financial accounting software. Its's got hundreds of thousands, maybe millions of users. Out of that user base, there are maybe 5-10 developers who work on it, part-time, and large but very itinerant band of translators (50-100, or about 2-3 for each language its been translated into).
So the ratio for a "popular" project seems to be: 1 million users->10 developers. That's for a project that has almost no commercial use at all.
Projects that have commercial uses get a lot more attention & support.
The likelihoood of an open-source project succeeding has very much to do with the user base, the marketing, the platform, as well as the source itself. Clearly, the advent of smart phones has ripped apart the Linux desktop. The open-source replacements for facebook have utterly flopped. And so on.
-- linas
David Hart
Jul 3, 2014, 1:10:21 PM7/3/14
to Linas Vepstas, Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Linas, what does your incoherent tirade have to do with anything? Am I missing something here?
-dave
Linas Vepstas
Jul 3, 2014, 1:54:05 PM7/3/14
to David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Ramin Barati, Sebastian Ruder
Heh. I didn't realize its incoherent. I could go into a lot more detail, but I'm pretty sure you would not want to hear it.
I was simply trying to reply to Keyvan's original post. I'm just reminding him that this is not the field of dreams: if you build it, they probably will not come.
--linas

Ramin Barati
Jul 3, 2014, 6:44:06 PM7/3/14
to Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi,
Separation of concerns and minimizing the coupling between the different modules in a big project is a tried and true software engineering concept, there is no argue in that; what I don't understand is, why no one is eager to follow that practice in the CogPrime architecture?!
I get it, there is this legacy code and we don't have the time and resources to clean it up etc etc; but someone, had wrote this revolutionary piece of code called the "RESTfull API" that exposes enough of this legacy code through a standard protocol to write decoupled modules from now on (even if it's not enough, adding more functionality is a piece of cake, now that the hard part is done)! it's so easy, just don't #include 'atomspace.h' in the code anymore and make a remote call. There is also this AtomspacePublisher too, thanks to Cosmo, there are really no needs to be dependent on the Atomspace binary anymore.
The whole system is slow enough that some calls to the loopback wouldn't impact the performance, no one will even feel it. It will increase the development time by a day or two, again too small compared to the actual development time of a module. Also, that would be a one time job, as others can reuse the helpers class that called the APIs. It will add one more tiny dependency to the project; everyone should already download at least 200Mb of data only to get the code, what is the size of a RPC library compared to that?
Putting the modules in separate repos won't attract more devs? OK. The current modules are tangled up with the Atomspace too much? Fine; Why are we continuing writing more badly engineered code? We are all aware of the fact that Atomspce should become distributed somehow someday! Why not think distributed, now that we have the means to do so? It will reduce the code re-factoring load once we reach that point, even if we start following those two easy rules right now!
The current approach is not quite "spaghetti code" but it's no marvel of software engineering either, it fails to meet the needs of the developers and the users (from a software point of view) by a large margin.
Sorry about the rant.
Ramin
David Hart
Jul 3, 2014, 7:56:36 PM7/3/14
to Ramin Barati, Linas Vepstas, Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi All,
I'd really like for us to elaborate on Ramin's points and discuss them in greater detail.
Separation of concerns and minimizing the coupling between the different modules in a big project is a tried and true software engineering concept, there is no argue in that; what I don't understand is, why no one is eager to follow that practice in the CogPrime architecture?!
I think it would be useful to actually pick apart and discuss the module, node, and lobe level structure of C' that is already documented. For reference, that documentation exists in a few forms and locations at: the 50-ish page paper with an overview of the AGI design being
targeted by our current efforts: http://wiki.opencog.org/w/CogPrime_OverviewThe overview paper is a condensed version of the two-volume book "Engineering
General Intelligence, A Path to Advanced AGI via Embodied Learning and
Cognitive Synergy":
http://www.amazon.com/Engineering-General-Intelligence-Part-Cognitive/dp/9462390266
http://www.amazon.com/Engineering-General-Intelligence-Part-Architecture/dp/9462390290
An older preprint version of the EGI book is at http://goertzel.org/monkeyburger/bbm_main.pdf
It's my understanding that for some parts, e.g. between certain connected nodes and lobes (groups of nodes that share common quasi-brain-analogous functions), lose coupling is a primary design goal, while for other parts, e.g. between certain other different significantly connected modules and nodes, tight coupling (including large shared memory pools) is a practical necessity. It would help our discussions to be very specific about which parts are under discussion at any given point in time.
I get it, there is this legacy code and we don't have the time and resources to clean it up etc etc; but someone, had wrote this revolutionary piece of code called the "RESTfull API" that exposes enough of this legacy code through a standard protocol to write decoupled modules from now on (even if it's not enough, adding more functionality is a piece of cake, now that the hard part is done)! it's so easy, just don't #include 'atomspace.h' in the code anymore and make a remote call. There is also this AtomspacePublisher too, thanks to Cosmo, there are really no needs to be dependent on the Atomspace binary anymore.
Many, but not all, new components can be written to the RESTful API, and I agree that the impulse and tendency to write in C++ by default is strong and, in many cases unwarranted. I believe that both the RESTful API and the AtomspacePublisher have been successful experiments but that we need to address the performance concerns of components that are loosely coupled with these connecting bits of software by designing and writing new C++ implementations of both.
Two recent additions to the wiki touch on some parts of a RESTful API redesign that I believe we should discuss:
The whole system is slow enough that some calls to the loopback wouldn't impact the performance, no one will even feel it. It will increase the development time by a day or two, again too small compared to the actual development time of a module. Also, that would be a one time job, as others can reuse the helpers class that called the APIs. It will add one more tiny dependency to the project; everyone should already download at least 200Mb of data only to get the code, what is the size of a RPC library compared to that?
Can you elaborate please?
Putting the modules in separate repos won't attract more devs? OK. The current modules are tangled up with the Atomspace too much? Fine; Why are we continuing writing more badly engineered code? We are all aware of the fact that Atomspce should become distributed somehow someday! Why not think distributed, now that we have the means to do so? It will reduce the code re-factoring load once we reach that point, even if we start following those two easy rules right now!
Even when we achieve a distributed AtomSpace, some components will only run practically on supernodes with monster amounts of memory. For reference, the type of real-world commodity hardware that we should consider when imagining which tasks can be efficiently and practically distributed and which should live on supernodes are already well described, namely quad-socket Intel E7 v2 systems that can receive *6TB* RAM per 4U-high standard rack-mountable chassis (http://www.pcpro.co.uk/news/enterprise/387196/intel-xeon-e7-v2-servers-support-6tb-of-ram). The bulk of the cost of these systems is the RAM rather than the processors, system boards or chassis. If Intel expands the architecture to fancier 32-socket systems (a trend that has been going strong since the 1990s), these systems will accommodate *48TB* RAM each. Keep in mind that these systems are all single-image SMP-like NUMA systems where a single instance of the Linux kernel runs with a 1.5TB-48TB addressable memory space and the kernel cooperating with the hardware handle many of the details of managing multiple shared-memory processes across differently coupled processor cores and their caches. Many large-memory C' tasks can be run on such systems that would simply fail hard on a distributed system (Google-like or otherwise).
The current approach is not quite "spaghetti code" but it's no marvel of software engineering either, it fails to meet the needs of the developers and the users (from a software point of view) by a large margin.
I think it would really help for us to collaboratively produce a write-up targeted at average developers that enumerates the types of programming tasks suited to RESTful API, AtomspacePublisher, Pythonic, Schemey, and other rapid development components vs which are practically suited to only being attempted in C++ vs which can be prototyped with the rapid tools with the intention of porting to C++.
Sorry about the rant.
Not a rant! Your comments are spot-on IMHO.
Ben Goertzel
Jul 3, 2014, 9:43:20 PM7/3/14
to opencog, Ramin Barati, Linas Vepstas, Keyvan Mir Mohammad Sadeghi, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder, hk-addis
Hi guys,
These are good discussions to have, for sure...
A few points
1)
As Linas's comments on RelEx / link grammar indicate, having a separate repo and a mailing list and good documentation and solid, utterly modular code, and even a few publications, does not provide anywhere near a guarantee of garnering developer or user interest for a project...
2)
I believe that OpenCog developer needs and OpenCog *user* needs (where by a user I mean a non-AI-researcher software developer who wants to use OpenCog in some product or serivce they are building) are going to be utterly different. I made a very rough sketch of my thoughts about a direction for an OpenCog interface for users, a little while ago
Building something like this would be a significant project on its own, of course leveraging existing OpenCog tools, probably including the RESTful API and the Scheme shell (or a similarly-functional python analogue), etc.
3)
Some parts of OpenCog are messy and need massive refactoring. The Embodiment module contains a lot of mess, for example (though some of it is fine, e.g. Shujing's 3DSpaceMap and closely associated code).
On the other hand, some parts of OpenCog are quite nice -- take a look inside the PatternMatcher code that Linas wrote (as Misgana and I have been doing recently...)
4)
Also, a number of infrastructure improvements have been suggested here
Many of these would help address the issues raised by Keyvan and Ramin (e.g. items 6, 8 and 9). This list also includes some cleaning up of Embodiment.
However, listing needed improvements takes less time than making them. Anyone who wants to pitch in with these, that would be great!
5)
Modularizing code is a subtler matter in an OpenCog context than in the context of a typical software project.
As an analogy, the parts of a car are pretty modular; the parts of a human body much less so. There are lots of interdependencies between body organs because the organs have all evolved to work together. The same is true for the parts of the human brain.
Now, OpenCog is an engineered not evolved system so its parts don't have to be as interdependent of those as a human body or brain. On the other hand, it is a complex adaptive system (which a car is not, and neither are the current batch of self-driving cars), which probably is not compatible with the maximal level of clean modularity that can be achieved in a system where the parts can all operate fairly independently of each other, interacting only via simple and clean interfaces.
I realize this is a somewhat philosophical point, but I'll make it concrete below.
6)
Now I want to talk about some stuff being currently developed in OpenCog. I think it's important to ground discussions like these in terms of specific AI modules or capabilities; otherwise the discussion can too easily turn into fancy-sounding articulations of generally good design practices...
I will enumerate a few cases, different in nature...
A)
PLN. Our current plan is to replace the existing python PLN with a new PLN version that is much more tightly coupled with the Atomspace. This involves e.g.
-- rewriting the PLN inference rules as ImplicationLinks, living in the Atomspace
-- replacing the current custom PLN chainers with usage of a generic chainer that operates on the Atomspace, utilizing the PatternMatcher.
-- some PLN-customized callbacks for the PatternMatcher (so, custom C++ code)
On the face of it, this seems the opposite direction of what Ramin and Keyvan are advocating. Yet, I think it is the right direction for development of PLN as an AI system. Key advantages are:
-- it makes clear that the PLN inference rules are cognitive content, which can then be improved by PLN, studied by pattern mining, etc. (In the python version the rules were tangled up inside python code)
-- rather than proliferating another specialized chainer, it makes use of an elegant general purpose chainer (that Misgana is just starting to build)
So we are embodying two good principles here
-- whenever possible, make the rules of operation of an AI module into cognitive content that can be learned and adapted by the system
-- avoid making multiple modules in the code that do the same thing (in this case, many chainers)
But we are making a PLN that is interwoven w/ other OpenCog functions, in a careful and thought out way. This is not spaghetti code.
B)
RelEx2Logic
Currently it's broken into
-- a modular piece, which is a custom RelEx output generator (a separate Java class to be run w/in RelEx)
-- some Scheme code that postprocesses the output of said output generator
We intend to replace the former part with some ImplicationLinks to be executed via the general-purpose PatternMatcher based rule engine. Furthermore, it has become apparent that the most elegant/simple way to do RelEx2Logic will be to invoke PLN or a similar inference engine,
which does not really gel with the idea of having RelEx2Logic operate separately of other OpenCog modules.
C)
Pattern Miner
Shujing has coded a frequent subgraph miner for the Atomspace. By its nature, this must be closely tied to the particulars of Atomspace representation (though not to the specific Atom types currently used). This makes heavy use of the PatternMatcher, and uses a separate Atomspace as an interim data-store to store the raw patterns in the process of being mined. (This makes the patterns themselves into cognitive content, which is important for many reasons, including that we can then do "meta-pattern mining" on this second Atomspace to learn patterns regarding which kinds of patterns tend to be worth searching for, and these meta-patterns can then be used to guide future pattern mining...)
The Pattern Miner is C++ code. It didn't have to be; Shujing could instead have extended the PatternMatcher Scheme API to encompass more of the functions of the PM's C++ API, or could have written a python API for the PM, etc. However, Shujing is a good C++ programmer, and the PM and Atomspace are in C++, so the choice of C++ seems fine enough to me here.
The Pattern Miner itself could of course be invoked via Scheme or Python or via the REST API or whatever, and its results could then be exported to non C++ code, etc. This will be done after the functionality has been more thoroughly tested and tuned.
The Pattern Miner can't really be a module separate from the Atomspace, Pattern Miner, etc. But it could have a specialized API allowing users who don't care about OpenCog to use it as a graph/hypergraph mining tool.
D)
DeSTIN
This has always been a separate module from the rest of OpenCog, as it originated separately. We are setting about reimplementing it, because the current C implementation is kind of a pain to work with, and not that flexible.
We considered implementing it very tightly coupled with the Atomspace, but the direction Tewodros (Teddy) and I are currently playing with is to reimplement it in python using the Theano GPU libraries developed by Yoshua Bengio's group at U. Montreal. This is convenient because
-- DeSTIN, unlike most of OpenCog, can make good use of GPUs for acceleration
-- As there is fairly good support for python in OpenCog, it will still be relatively straightforward to incorporate OpenCog functionality into DeSTIN dynamics if we do it this way
So in this case, we'd have a pretty separate module, and would continue to package and document it separately, as well as to use it together with OpenCog.
E)
ECAN
The purpose of ECAN is to spread STI and LTI among Atoms, and to build Atoms based on STI and LTI values. The goal here is to make these values accurately reflect the short and long term importance of Atoms, so as to effectively guide other cognitive processes.
As ECAN needs to loop through a lot of Atoms as quickly as possible, this seems a case where including delays between ECAN and the Atomspace is a bad idea. Also ECAN is specialized algorithmically for the Atomspace, and to use it for some other sort of AI system, woulc require lots of customization. Not straightforwardly made modular.
F)
Bio-MOSES
Eddie Monroe, Mike Duncan and I are looking at integration of MOSES w/ the Atomspace in gene expression data analysis problems.
For instance, within MOSES, if one has program trees representing patterns in genetic data, one may wish to mutate a program tree in a manner that makes use of OpenCog's assessment of similarity between two genes references in the program tree. This would require MOSES to make a call to PLN, or at least a lookup into the Atomspace, in the course of mutating a program tree.
This is a case where using a clean separation makes sense. E.g. the RESTful API in some variation could be used by MOSES to query the Atomspace or PLN and get an answer.
...
OK, there are more examples, but that's probably enough to get across the variety of scenarios.
To me, it is clear that a simplistic insistence on broad design principles like modularity doesn't really cut the mustard here. We're doing something really complicated here, and only a certain amount of that complicated can be banished via effective software design.
-- Ben
--
You received this message because you are subscribed to the Google Groups "opencog" group.
To unsubscribe from this group and stop receiving emails from it, send an email to opencog+u...@googlegroups.com.
To post to this group, send email to ope...@googlegroups.com.
Visit this group at http://groups.google.com/group/opencog.
For more options, visit https://groups.google.com/d/optout.
Linas Vepstas
Jul 3, 2014, 10:14:42 PM7/3/14
to Ramin Barati, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Benjamin Goertzel, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
I have little to add, except for the first sentence:
On 3 July 2014 17:44, Ramin Barati <rek...@gmail.com> wrote:
Separation of concerns and minimizing the coupling between the different modules
What modules? If the suggestion is to move certain blocks of code into other github repositories, I just don't see where the lines between such modules would be drawn. Everything except moses depends on the atomspace. No one (outside of opencog) would ever use the atomspace all by itself. So why split it off?
As to moses, I used to think that it should be split off, except that it already depends on cogutil, so such a split would be quite messy. For historical reasons, moses invented a different version of the atom, called the vertex, and so (currently) doesn't use the atomspace. There's a low priority plan to make it run on the atomspace. So again, where are these module boundaries?
--linas
Ben Goertzel
Jul 3, 2014, 10:21:43 PM7/3/14
to Linas Vepstas, Ramin Barati, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
On 3 July 2014 17:44, Ramin Barati <rek...@gmail.com> wrote:
Separation of concerns and minimizing the coupling between the different modules
What modules? If the suggestion is to move certain blocks of code into other github repositories, I just don't see where the lines between such modules would be drawn. Everything except moses depends on the atomspace. No one (outside of opencog) would ever use the atomspace all by itself. So why split it off?
Yes, that is my feeling as well.
DeSTIN does not depend on the Atomspace, but we have plans to use it together with the Atomspace. But it's already a separate codebase.
If there are other significant OpenCog-related tools that have use w/o the Atomspace, they can certainly be packaged separately too.... But then let's talk about the particular cases...
As to moses, I used to think that it should be split off, except that it already depends on cogutil, so such a split would be quite messy. For historical reasons, moses invented a different version of the atom, called the vertex, and so (currently) doesn't use the atomspace. There's a low priority plan to make it run on the atomspace.
Yes, Linas most recently suggested to make Atom extend MOSES's Vertex class, which seemed an interesting strategy
The Reduct library used in MOSES could/should be unified with the pattern matching and simplification done in the Atomspace, which would have long-term benefits like easing experimentation with uncertain reductions (program tree simplifications)
This is low priority as MOSES works OK for many purposes and there are other OpenCog tasks that are more urgent. But it indicates that in the medium term we don't necessarily want to think of these as separate, modular codebases. Although, even if MOSES is integrated w/ Atomspace on the back end somehow, it should still retain a separate interface for those who want to use it in a simple way as an ML tool...
-- Ben
Ramin Barati
Jul 4, 2014, 7:29:12 AM7/4/14
to Ben Goertzel, Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Now I want to talk about some stuff being currently developed in OpenCog. I think it's important to ground discussions like these in terms of specific AI modules or capabilities; otherwise the discussion can too easily turn into fancy-sounding articulations of generally good design practices...
Agreed.
A) PLN. Our current plan is to replace the existing python PLN with a new PLN version that is much more tightly coupled with the Atomspace.
After reading the specifications of the new PLN, It's still not clear to me why this PLN should be tightly coupled with the Atomspace. It's highly dependent on the functionality of Atomspace and PatternMatcher, but functionality can be exposed through different means, that doesn't mean they should be tightly coupled. Let me elaborate more on this with an example.
Imagine a scenario, where users go to a website, send a request and get a response. Here, the request is taken to an instance of PLN that communicate with an instance of Atomspace+PatternMatcher and the response follows the reverse order and gets delivered to the user. All three instances are on an Intel E7 v2 supernode and the PLN, PatternMatcher and Atomspace are taking 10, 40 and 50 percent of resources respectively, everything works just fine. After a while, the website gains popularity and the current hardware can't take the load anymore, naturally, there is a need to scale the application. After some analysis, we reach the conclusion that the PLN is the part that needs to scale up. But due to tight coupling with other modules, we can't just scale the PLN, we should scale the whole system. Atomspace+PatternMatcher can not run efficiently on a simple core i7, so we are forced to buy another E7 v2 supernode just to give the PLN an extra 10% of it's resources. A couple years later, we'll have an Intel E7 v2 farm just to scale up PLN to 300% of it's original needs and at the same time wasted a shit-load of money and resources.
As you can see, when considering coupling and decoupling of modules, the emphasis is more on expanding and scaling properties of each module not their functional dependency on each other. The way I see it, the new PLN talks with Atomspace+PatternMatcher, it doesn't operate them or mingle with their jobs. More importantly, it doesn't share the same scaling properties with The Atomspace+PatternMatcher. Of course performance is a factor here too, but not as important as it's costs IMO.
I imagine that the PLN is more like a mobile app, I mean, there would be multiple instances of PLN running on everyday devices that communicate with a distributed and scalable Atomspace+PatternMatcher instance.
My understanding of the system right now is that, the Atomspace and PatternMatcher is better to be tightly coupled with each other, as a bigger Atomspace always needs a faster PatternMatcher, but PLN is only a user of their functionality, better to be served by them and thus, loosely coupled.
B) ... C) ... D) ... E) ... F) ...
I'm not familiar with inner workings of these modules or fully understand their place in the system, so I won't make some blind statements here. But anyone with enough knowledge of these modules should answer this question: 'Does this module scale up with the same pace as its dependencies?". Of course it takes more than that, but it would be a good start.
Ramin
Ben Goertzel
Jul 4, 2014, 12:55:25 PM7/4/14
to Ramin Barati, Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Regarding PLN, your discussion remains too general, I think. Let's consider what goes into PLN, i.e.
1) The inference rules and formulas
2) The chainer
3) The control heuristics for guiding the chainer efficiently
In the new implementation, we will have
1) Inference rules and formulas as cognitive content in the Atomspace
2) The chainer is the unified forward/backward chainer that Misgana will write to work with the Pattern Matcher (so it will work for PLN but also any other application of rules represented as ImplicationLinks)
3) The control heuristics are implemented via callbacks to the Pattern Matcher (e.g. the callback Misgana just wrote lets the PM get guided by STI values, which may be generically useful beyond PLN)
...
Notable here is that everything is done via generic Atomspacey methods, so that the amount of code needed for just PLN is minimal.
...
In your vision of PLN as a separate module communicating with the Atomspace/PM, how are 1, 2 and 3 taken care of?
In the current python PLN, what we have is
1) Inference rules and formulas in python code, not cognitive content (so not modifiable/inspectable by AI methods)
2) A custom chainer, which goes to a lot of work to replicate in python the basic variable-unification functionality that the PM does against the Atomspace
3) The control heuristics are not there, but would be implemented in custom python code, in a way presumably usable only with the custom PLN chainer
...
The current python PLN has more modularity and could "easily" be wrapped up as a mobile app or whatever, communicating with a remote Atomspace..... But it involves duplicating functionality that exists in the PM, and expresses the rules in code rather than as cognitive content, and doesn't use generic cognitive control code either.
The proposed, in-progress new PLN is interwoven with the Atomspace, thus not able to operate as a mobile app or other separate module; but it uses much less code, and relies much more on generic cognitive mechanisms; and is designed to be automatically improvable via reflective meta-analysis...
To me this is a very clear case where the particular nature of OpenCog as a complex AI system where different AI methods need to interoperate closely (a "body / brain" type situation) pushes in a different direction from having simplistically separated modules (a "car" type situation)
-- Ben
Ramin Barati
Jul 5, 2014, 3:42:11 PM7/5/14
to Ben Goertzel, Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi Ben,
I think there has been a misunderstanding here, I've never apposed the new PLN design and I'm not defending the old PLN, maybe we're not using the same vocabulary. By tightly coupled modules I'm talking about a design choice.
For the sake of simplicity, let's suppose there are two classes involved here, PLN and Atomspace, with the following definitions:
class Atomspace{
public:
Node AddAtom(string data){
/*
the logic
*/
}
};
class PLN{
public:
void Chain(Atomspace& as){
as.AddNode("data");
}
};
Here, the PLN class is tightly coupled with the Atomspace class, whereas if for example the proxy pattern where used, the two classes where loosely coupled. Now, if we implement the proxy using remote procedure calls, we would have a scalable system, as we can move the objects anywhere in the network and still get the same functionality we got before.
Of course when we aren't using a shared memory channel, there would be some performance impacts. If memory serves, the bandwidth of a shared memory channel would be around 800 MB/s, whereas using RPCs and the TCP loopback it would decrease to around 200 MB/s. These numbers are highly dependent on the properties of the data being exchanged, but there would be an impact no matter what.
Back to the matter at hand, My underestanding of the current approach is that Atomspace and PatternMatcher should exchange data using a shared memory channel, because of the need for speed and the crucial role of PatternMatcher in querying the Atomspace; as a matter of fact, scaling of Atomspace will bring an immediate need for re-scaling of PatternMatcher.
PLN on the other hand, would benefit from a loosely coupled design here, as it's work load is not comparable with the the workload of Atomspace+PatternMatcher, and those two modules should scale independently of the PLN.
Ramin
Linas Vepstas
Jul 5, 2014, 8:33:56 PM7/5/14
to Ramin Barati, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Ramin,
What you are doing here is known in the industry as "premature optimization". You are making random guesses as to where the bottlenecks may or may not be, and then deciding how to split up the problem into parts, while lacking any evidence whatsoever where the *actual* bottlenecks are.
Converting an algorithm that runs on a local machine into one that runs well in a distributed environment requires deep insight into the algorithm, as well as numerous actual measurements and experiments. Just guessing that the bandwidth requirements between PLN and the atomspace is low does not mean that the actual bandwidth requirement will actually be low. You have to measure and find out.
If it is, then you can *easily* add a proxy, post-facto. It is much, much, much easier to insert interface shims, than it is to make the actual performance measurements to decide where they should go.
I've done this many times in my life now; most recently, by adding MPI support to MOSES. I added the MPI support in about a few days or at most a week. Making the performance measurements to understand how to split the problem took months.
Is to the pattern matcher -- I suppose I'm happy that it will be used more; I'm nervous that it will be revealed as a performance bottleneck. Maybe. Or maybe not; we'll see.
-- Linas
Ramin Barati
Jul 6, 2014, 6:26:11 AM7/6/14
to Linas Vepstas, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi Linas,
What you are doing here is known in the industry as "premature optimization".
In which industry following good OOP practices in writing new and fresh code is called "premature optimization" or even "optimization"?
You are making random guesses as to where the bottlenecks may or may not be
What is/are this/these bottleneck/s you're talking about? If it's the development bottleneck called "bad software engineering", you are following this discussion, if not, then I don't know what it is that you are talking about. For example, the usage of singleton pattern in scheme/python evaluators was "bad software engineering".
, and then deciding how to split up the problem into parts, while lacking any evidence whatsoever where the *actual* bottlenecks are.
Again, this PLN is getting written right now! I'm not taking guesses here, I'm proposing that we should introduce some bottlenecks in the code in favor of good software development practice. If the old PLN code was following a good OO approach, we weren't talking about a NEW PLN code, we were talking about an evolving PLN code.
Converting an algorithm that runs on a local machine into one that runs well in a distributed environment requires deep insight into the algorithm, as well as numerous actual measurements and experiments. Just guessing that the bandwidth requirements between PLN and the atomspace is low does not mean that the actual bandwidth requirement will actually be low. You have to measure and find out.
FYI, I was the one who were supposed to write the now old PLN, I've even worked on it for a week or two, but life got in the way. Even back then, we were all aware of the fact that PLN would need to dynamically load it's rules someday, there were talks of using pattern matcher too. But we decided that it was not the time to write a rule engine or use the pattern matcher and the emphasis was on having a "working PLN soon". Nevertheless, when I was designing the original old PLN, I put some classes here and there just to make the transition from statically loaded rules to dynamically loaded rules as easy as inheriting from a class. I had abstracted the chainers, so that anyone could write any chainer for the PLN without the need to actually changing any of the available code. It was designed expandable, not that I was sure of it's needs in the future, I designed it expandable because it's "good development practice".
Now, here you are, a year after, trying to write yet another PLN. A PLN that we wouldn't have need, if other developers have shared my enthusiasm for "good software engineering", but instead, they moved my small, incomplete but carefully designed code to another folder and let it rot.
Now, here I am, a year after, observing yet another design choice that would turn the "new PLN" into the "old PLN" in a year or so. Guys, WE ARE ALL AWARE OF THE FACT THAT THE ATOMSPACE WOULD BECOME DISTRIBUTED SOMEHOW SOMEDAY AND OTHER MODULES LIKE PLN ARE NOT SHARING THE SAME FATE NECESSARILY! and when that comes, there would be no "shared memory channel" to compare it's efficiency with other channels of data transfer! You don't need to conduct trials or measure performances, or anything for that matter, to see that. Stop making the same mistakes again and again. Do NOT tightly couple any piece of code with Atomspace binary, unless you are perfectly sure that the module should scale along side the Atomspace, otherwise the dilemma of the "old X" and the "new X" will continue.
If it is, then you can *easily* add a proxy, post-facto. It is much, much, much easier to insert interface shims, than it is to make the actual performance measurements to decide where they should go.
Wrong Linas, the only *easy* thing about adding a middle tier to an implemented architecture is *thinking* about what it would take to add a middle tier to an implemented architecture.
I've done this many times in my life now; most recently, by adding MPI support to MOSES. I added the MPI support in about a few days or at most a week. Making the performance measurements to understand how to split the problem took months.
For god's sake Linas, I'm not talking about optimizations here!
Is to the pattern matcher -- I suppose I'm happy that it will be used more; I'm nervous that it will be revealed as a performance bottleneck. Maybe. Or maybe not; we'll see.
The need for an Atomspace querying tool was always there, it's funny how no one wants to use someone else's tools in OpenCog! Software developers were supposed to be some lazy bums that maximize "not writing new code", but here everyone wants to make their own code, curious! :)
Pattern matcher was always there, we knew it's potential, at least I knew, and I'm happy that it's getting more action now. the RESTful API and the AtomspacePublisher are similar pieces of code that really should get more attention. They may not be optimized to the fullest and they may become bottlenecks, but using them ensures good software design, so don't just brush them off.
Ramin
Ben Goertzel
Jul 6, 2014, 8:30:52 AM7/6/14
to Ramin Barati, Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Ramin,
For the sake of simplicity, let's suppose there are two classes involved here, PLN and Atomspace, with the following definitions:class Atomspace{public:Node AddAtom(string data){/*the logic*/}};class PLN{public:void Chain(Atomspace& as){as.AddNode("data");}};Here, the PLN class is tightly coupled with the Atomspace class, whereas if for example the proxy pattern where used, the two classes where loosely coupled. Now, if we implement the proxy using remote procedure calls, we would have a scalable system, as we can move the objects anywhere in the network and still get the same functionality we got before.
But if the PLN rules are themselves stored in the Atomspace, and PLN uses a generic Atomspace-oriented chainer that is implemented using the PatternMatcher with customized callbacks (coded in C++ and working directly on the Atomspace), then what does this potentially remote class PLN do?
I guess there are two options here
1)
The PLN class does nothing but remotely invoke the chainer
2)
The chainer is implemented in a way that it can be run remotely from the Atomspace. The PLN class then contains an instance of the chainer.
...
But the problem with Choice 2 is, the Chainer will need to consult the Atomspace (e.g. HebbianLinks) at each step, in order to help it decide which inference rule to choose next....
So if the chainer needs to consult the Atomspace for guidance at each step, and the rules are being executed by the PM within the Atomspace, then what would be the point of implementing the chainer so that each of its steps could be run remotely from the Atomspace?
...
Again, you are not outlining an alternate PLN design here, you're just giving some example classes with evocative names like "PLN" and "Atomspace" that don't actually engage with the details of what PLN does....
Yes, it would be possible to build a PLN system that was only loosely coupled with the Atomspace. I don't think this is a good idea, for reasons I've already outlined. Your counterargument is basically that "modularity and loose coupling are generally good" -- which is a fine proclamation, but doesn't really tell you what to do in a particular case like this one...
-- Ben
Linas Vepstas
Jul 6, 2014, 9:30:19 AM7/6/14
to Ramin Barati, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
I don't know what to say. I'm not saying "follow bad coding practices". Follow good ones. However, coders must constantly make choices, and, on average, many of them will be bad. Its unavoidable. You have to recognize the bad ones and don't let them spread.
However, if you treat coding as a religion, where certain must be done a certain way, where certain choices cannot be questioned, then you will get bad code. You are talking with religious conviction in these emails; that worries me.
Anyway, a few years ago, the AtomSpace used the proxy pattern and it was a performance disaster. I removed it, which was a lot of hard, painful work, because it should never have been added in the first place. Atomspace addnode/link operations got 3x faster, getting and setting truth values got 30x faster, getting outgoing sets got 30x faster. You can read about it in opencog/benchmark/diary.txt
--linas
Ramin Barati
Jul 6, 2014, 12:03:18 PM7/6/14
to Linas Vepstas, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi Ben,
Again, you are not outlining an alternate PLN design here, you're just giving some example classes with evocative names like "PLN" and "Atomspace" that don't actually engage with the details of what PLN does....
OK, so can you please explain to me what steps are taken, with details, from the moment that PLN starts an inference step? I have some assumption, but I wanna continue this discussion based on actual code and facts.
Ramin
Ramin Barati
Jul 6, 2014, 12:51:21 PM7/6/14
to Linas Vepstas, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi Linas,
I don't know what to say. I'm not saying "follow bad coding practices". Follow good ones. However, coders must constantly make choices, and, on average, many of them will be bad. Its unavoidable. You have to recognize the bad ones and don't let them spread.
Obvious enough.
However, if you treat coding as a religion, where certain must be done a certain way, where certain choices cannot be questioned, then you will get bad code. You are talking with religious conviction in these emails; that worries me.
Tnx for pointing that out.
Anyway, a few years ago, the AtomSpace used the proxy pattern and it was a performance disaster. I removed it, which was a lot of hard, painful work, because it should never have been added in the first place. Atomspace addnode/link operations got 3x faster, getting and setting truth values got 30x faster, getting outgoing sets got 30x faster. You can read about it in opencog/benchmark/diary.txt
I can't even imagine what use has the Atomspace for the proxy pattern.
Ramin
Linas Vepstas
Jul 6, 2014, 6:21:36 PM7/6/14
to Ramin Barati, Ben Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
On 6 July 2014 11:51, Ramin Barati <rek...@gmail.com> wrote:
Anyway, a few years ago, the AtomSpace used the proxy pattern and it was a performance disaster. I removed it, which was a lot of hard, painful work, because it should never have been added in the first place. Atomspace addnode/link operations got 3x faster, getting and setting truth values got 30x faster, getting outgoing sets got 30x faster. You can read about it in opencog/benchmark/diary.txtI can't even imagine what use has the Atomspace for the proxy pattern.
Ostensibly thread-safety, and distributed processing. Thread-safety, because everything was an "atom space request" that went through a single serialized choke point. Distributed processing, because you could now insert a zeromq into that choke point, and run it on the network. The zmq stuff was even prototyped, When measured, it did a few hundred atoms per second, so work stopped.
To me, it was an example of someone getting an idea, but failing to think it through before starting to code. And once the code was written, it became almost impossible to admit that it was a failure. Because that involves egos and emotions and feelings.
--linas
Ben Goertzel
Jul 7, 2014, 12:31:47 AM7/7/14
to Ramin Barati, Linas Vepstas, David Hart, Keyvan Mir Mohammad Sadeghi, opencog, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
On Mon, Jul 7, 2014 at 12:03 AM, Ramin Barati <rek...@gmail.com> wrote:
Hi Ben,
Again, you are not outlining an alternate PLN design here, you're just giving some example classes with evocative names like "PLN" and "Atomspace" that don't actually engage with the details of what PLN does....
OK, so can you please explain to me what steps are taken, with details, from the moment that PLN starts an inference step? I have some assumption, but I wanna continue this discussion based on actual code and facts.Ramin
Apologies, but I really don't have time to write that out for you just now...
Jade's python PLN basically does the right stuff; although it doesn't use STI or other clever heuristics to select which inference rule to use at each step, nor to search the Atomspace for potential Atom-sets fulfilling the requirement of an inference rule...
ben
Linas Vepstas
Jul 7, 2014, 10:21:55 PM7/7/14
to Hendy Irawan, opencog, Ramin Barati, Benjamin Goertzel, David Hart, Keyvan Mir Mohammad Sadeghi, Joel Pitt, Cosmo Harrigan, Jade O'Neill, Sebastian Ruder
Hi Hendy,
One short answer is that the way you describe things is not how it actually works. So, in your bullet 4, you write "findAtomsWhichAre(Person).foreach( ..."
But we would never do that, we don't want to do that ... What we are trying to do is to perform logical induction, using probabilities and "activation spreading". We don't program in the sense that you are thinking of.
You have to understand to the atoms in the atomspace are kind-of-like a programming language, and so we represent all our data and do all of our processing, by using atoms. In particular, we are not doing "coding" such as in your bullet #1, so it doesn't matter how intuitive it is, because that's not how it works. Nor are we #2 threading (that's automatic) nor are we #3 messaging (that's automatic as well) .. all the way down to #10 on your list ... your features 1-10 are already built into opencog, they are in a deep base layer, intentionally hidden from the users and programmers.
Now, some system maintainers have to maintain these deep hidden guts, but frankly I don't see how to map what you are selling to what we actually could use.
--linas
I think designing most parts of the software around data grid and compute grid constructs would allow:
- intuitive coding. i.e. no special constructs or API, just closures and local data, and closures are still cheap even when lots of iterations and no thread switching. e.g.
Range(0..100000).foreach { calculateHeavily(it); }.collect( sum )
a nice side effect of this is, a new member or hire can join a project and ideally, not having to learn the intricacies of messaging & multithreading plumbing, there's already too much logic to learn anyway without adding those glue.
- practical multithreading. I'm tempted to say painless multithreading :) multithreading becomes configuration, not a baked in logic that's "afraid" to be changed (in the sense that, while make a singlethreaded code to multithreaded takes time, I think it takes even more time to make it work right + no race conditions + avoid negative scaling.. then when all else fails you return it back to the original code, while other developments are done concurrently)
- messaging. even the simple code above implies messaging, i.e. logically it is sending "int i" into the closure. at runtime it can be singlethread, multithread, or multinode. if calculateHeavily is in nanoseconds then it's pointless to use multithread. but if calculateHeavily takes more than 1 second multinode is probably good.
- data affinity. the data passed to the closure doesn't have to be "data"/"content", it can be a key, which the closure can then load locally and process and aggregate.
findAtomsWhichAre(Person).foreach( (personId) -> { person = get(personId); calculateHeavily(person); }.collect( stats )
I haven't seen the ZeroMQ implementation of AtomSpace, but I'm suspecting it is (was?) a chatty protocol, and would've been different if data affinity was considered. I only ever used AMQP, but I think both ZeroMQ and AMQP are great to implement messaging protocol instead of scaling, unless explicitly designed as such like how Apache Storm uses ZeroMQ.
- caching... consistently & deterministically. one way to reduce chattiness is to cache data you already have, that can be reused on next invocations (which hopefully many, otherwise too many cache misses will be worse). the problem is cache becomes stale. the solution is to use the data grid model, meaning the cache is consistent at all times. While this means there is a bit more coupling between cache and database, the programming model stays the same (as point #1) and no need for stale cache checks.
- caching... transactionally. manually implementing atomicity is hard in using messaging/RPC/remote proxy, or even basic multithreading. a data grid framework allows transactional caching, so
ids.foreach { a = get(id) -> process(a) -> put(id, a) }
would not step on some other operation.- performance testing for several configurations. if there are performance unit tests for a project, these can be in multiple configs: 1 thread; n threads; 2 nodes × n threads.
this ideally achieves instant gratification. if a performance unit test has negative scaling, you can notice it earlier. and if it does approach linear scaling, congrats & have a beer :D- bulk read & write. related to #5, if there are lots of scattered writes to database, a cache would improve this using write-through, while maintaining transactional behavior. instead of 100 writes of 1 document each, the cache can bulk-write 1 database request of 100 documents. you may let the framework do it or may code bulk write manually in certain cases, there's the choice.
- bulk messaging. related to #3 and #4. a straightforward messaging protocol may divide 100 operations into send 50 messages to node1 and 50 messages to node2, which may be significant overhead. a compute grid can divide 100 operations into 2 messages: 1 message of 50 operations to node1 and 1 message of 50 operations to node2.
- avoid premature optimization, while allowing both parallelization and optimization. related to point #7, since you know you can change config at any time, if you notice negative scaling you can simply set the config for that particular cache or compute to single-thread or single-node. Implementing #2 + #3 manually sometimes actually hinders optimization.
While my reasons above pertain to performance, I'm not suggesting considering performance while coding, but I do suggest considering a programming model which allow you to implement performance tweaks unobtrusively and even experimentally while retaining sanity. (that last part seems to be important at times :)
For example, using GridGain one uses closures or Java8 lambdas or annotated methods to perform compute, so things aren't that much different. To access data one uses get/put/remove/queries abstraction and you usually abstract these anyway, but now you have the option to make these read-through and write-through caches instead of direct to database. Data may be served from a remote/local database, a remote grid node, or local memory, this is abstracted. The choice is there, but it doesn't have to clutter code, and can be either implemented separately a in different class (Strategy pattern) or configured declaratively.
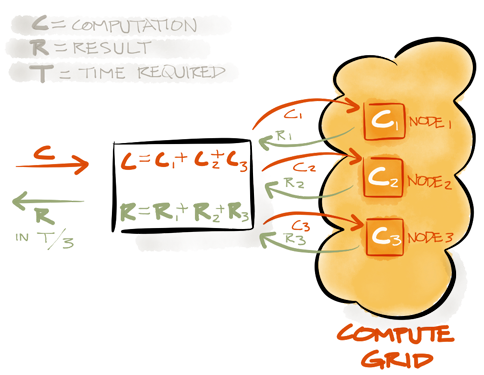
For Java it's easy to use GridGain, I believe modern languages like Python or Scheme also have a way to achieve similar programming model. Although if for C++ then I can't probably say much.Personally I'd love for a project to evolve (instead of rewrite), i.e. refactoring different parts over versions while retaining general logic and other parts. This way not only retains code (and source history), but more importantly team knowledge sharing. In a rewrite it's hard not to repeat the same mistake, not to mention the second-system effect.In my experience with Bippo eCommerce, our last complete rewrite was 2011 when we switched from PHP to Java. From that to the present we did several major architectural changes, as well as frameworks: JSF to quasi-JavaScript to Wicket, Java EE to OSGi to Spring, Java6 to Java7 to Java8, LDAP to MongoDB, MySQL to MongoDB to MongoDB + PostgreSQL, and so on... sure we had our share of mistakes but the valuable part is we never rewrite the entire codebase at once, we deprecated and removed parts of codebase as we go along. And the team retains collective knowledge of the process, i.e. dependency between one library and another, and when we change one architecture the other one breaks. I find that very beneficial.Hopefully this can be of consideration for Dr. Linas Vepstas, and also be of use regarding Ramin Barati's concern with the (apparent?) rewrite of PLN every year or two.Hendy
Reply all
Reply to author
Forward
0 new messages