Clustering words based on syntactic/grammatical behavior

Siva Reddy
The task is to cluster words which behave syntactically similar. Syntactic behavior of a word is described by its dependency relations (links) with other words. Currently we using link parser to get the dependency relations of the words.
For Eg:
+------MVp------+
+---Os---+ +-----Jp----+
+--Ss-+ +-Ds-+ | +--Dmc-+
| | | | | | |
she gave.v a party.n for.p the orphans.n
Here the syntactic behavior of gave is explained using the relation (also called disjunct) "Ss- Os+ MVp+" where Ss- means the the link which represents "subject singular on the left side of the word", Os+ means "Object singular on the right side of the word" and MVp+ means "the adjunct on the RHS".
We have with us millions of such entries of (word w, its_disjunct D, p(D/w), p(D, w) ) which were obtained from running link parser on wikipedia articles where
p(D/w) represents the probabilty of the disjunct "D" given the word 'w' occured
p(D, w) represents the probability of disjunct and word occuring together.
and we also have all kinds of scores that are possible like -log probabilities, entropies etc.
There exists an hierarchy between the links. For the time being we are not concentrating on this.
For eg:
O+ > Os+ > Osx+ > Osxx+ > Osxxx+
Also some links are not that important (optional) for a word.
For eg:
+----------------MVp---------------+
+------MVp------+ |
+---Os---+ +-----Jp----+ +-----Js----+
+--Ss-+ +-Ds-+ | +--Dmc-+ | +---Ds---+
| | | | | | | | | |
she gave.v a party.n for.p the orphans.n in the auditorium.n
Here the disjunct of the word gave is "Ss- Os+ MVp+ MVp+". The second MVp+ is not that important.
After clustering, we aim to group the words that behave syntactically.
For eg:
(gave, threw, celebrate) etc in one cluster which behave syntactically similar.
Once we accomplish this task, link parser dictionaries (grammar rules of words) can be refined and can be extended to cover new words. This will increase the coverage and accuracy of the parser.
I will post some of the techniques that can be used and more details in the coming mails. Any suggestions/techniques/methods are welcomed.
Regards,
Siva
Siva Reddy
---------------------------------------------------------------------
I'd like to have you start planning
for the clustering problem. I'm appending the raw data
format, (he SQL table format for the current data) below.
The goal is to use dataming/clustering techniques to
pull out classes of words that have similar sets of
disjunct frequencies.
Thus, for example: the two words:
demagoguery[?].n mutualism[?].n
both had almost identical disjunct usage:
(Jp- D*u- . 4.43262299145841)
(Jp- D*u- Mp+ . 1.67048905466711)
(Jp- . 0.770556642122605)
(the float pt numbers are the -log probability)
Therefore, these two words should probably
belong to the same "grammatical class": they
seem to be used in the same way, grammatically.
The goal is to go through the datasets, and find
these "grammatical classes". This is essentially
a clustering problem.
The tricky part of clustering is that the dataset
contains tens-of-thousands of "disjuncts" (in
the above example, the "Jp- D*u- Mp+" is one
disjunct; the above example uses three disjuncts)
For the above example, the other 9997 disjuncts
have a value of infinity (since -log 0 = infinity, and
the probability of observing the other disjuncts was
zero).
So the clustering problem is to find clusters in a
ten-thousand-dimensional space, where each
disjunct is an axis/dimension, and 9990 of the
coordinate values are infinite.
Alternately, perhaps there are alternate ways
of clustering ... ? But finding such "grammatically
similar" clusters is the goal.
---------------------------------------------------------------------------
I will post more updates in a couple of hours.
Regards,
Siva

Abhilash Inumella
I guess it's worth looking at the frequency of the number of disjuncts per word and also the number of words per disjunct.
You might want to read this http://www.stanford.edu/~jurafsky/cl01.pdf (See section 6.1 ). It has further references too.
Regards.
Abhilash I.
Abhilash I
IIIT-Hyderabad
Siva Reddy
The tricky part of clustering is that the dataset
contains tens-of-thousands of "disjuncts" (in
the above example, the "Jp- D*u- Mp+" is one
disjunct; the above example uses three disjuncts)
For the above example, the other 9997 disjuncts
have a value of infinity (since -log 0 = infinity, and
the probability of observing the other disjuncts was
zero).
So the clustering problem is to find clusters in a
ten-thousand-dimensional space, where each
disjunct is an axis/dimension, and 9990 of the
coordinate values are infinite.
I am trying to compare here two different views of clustering
1. Having disjunct as an axis
One way is direct case using the constraints as implemented in /opencog/nlp/wsd-post/cluster.scm. The tuples (word1, dj, count, log_cond_prob) and (word2, dj, count, log_cond_prob) are clustered into the same group
1) only if count > 1.0 and
2) only if log_cond_prob < 5
In this case each word represents a point along the axis. The thing to note is two different words which have different disjuncts lie on different axis and can never be clustered into a common group since each axis is othogonal to each other.
For eg:
(gave, "Ss- Os+ MVp+") and (gave, "Ss- Os+ MVp+ MVp+") cannot be in a common cluster whereas I think it is valid to have both of them in the same cluster.
Also (gave, "Ss- Os+ MVp+") and (gave, "Ss- Op+ MVp+") cannot be in a common cluster.
What I am trying to say is that even if there is a slight change in the disjunct the tuples cannot be clustered into a common group.
Also how do we know that log_cond_prob condition is a good constraint. Many times a word can have many senses and may have many disjuncts possible. In such a case, we cannot discard those words and log_cond_prob will not be a good constraint to decide in such cases.
The other way of viewing is that each word represents a point with disjuncts as its co-ordinates. But this will be completely wrong since a word may represent many senses and clustering words of different senses with another word does not make sense.
2. Link as an axis
Each tuple is represented by a vector with its links as its co-ordinates. Tuple represents a point and the clustered group represents the region of points in the space behaving syntactically similar.
So each point is a vector which looks like this
(Ss-, Ss+, Sp+, Sp-, Os-, Os+, Op-, Op+, MVp+, MVp-, Ox+, Ox-, ..... blah, blah)
or each link can be further divided like this
(S, s, p, -, + , O, s, p, -, +, MV, s, p, -, +, .... .... ..... )
The feature scores can be the log conditional probabilities or any other which we need to discuss. Once each tuple is represented in this way we can use SVM to classify them or many standard classifiers to cluster them into classes.
The advantages of this method are that we need not mention which feature is important. It automatically identifies important features based on the number of classes to be clustered.
We can also use methods used in previous works like [1] which resembles our problem. The difference is that they have (child_word, parent_word, link_name) tuples. This need to be modeled similar to our problem. Please read [1] and give me your comments.
Other methods include [2] based on distributional similarity. We can also use Levin classes or Verbnet classes etc without worrying about clustering. Many techniques are described in [3].
But all the above works are based on the assumption that words behaving syntactically similar are semantically similar. But in our case this may not be true. We are trying to cluster words based on seeing only its disjuncts and nothing more than that. (like using the child_word, parent_word inforamtions). What do you think ?. What does link clusters represent ?
I will proceed with Link as an axis if you don't have any problem.
References are attached:
[1] Dekang Lin, Automatic Retrieval and Clustering of Similar Words, 1998
[2] Pereira et al, DISTRIBUTIONAL CLUSTERING OF E N G L I S H WORDS
[3] Pierre Senellart and Vincent D. Blondel, Automatic Discovery of Similar Words
Regards,
Siva

Murilo Saraiva de Queiroz
Murilo Saraiva de Queiroz, MSc.
Senior Software Engineer
http://www.vettalabs.com
http://www.tecnologiainteligente.com.br
http://www.acalantoemcasa.com.br

Linas Vepstas
> Hi Linas,
>
>>
>> The tricky part of clustering is that the dataset
>> contains tens-of-thousands of "disjuncts" (in
>> the above example, the "Jp- D*u- Mp+" is one
>> disjunct; the above example uses three disjuncts)
>>
>> For the above example, the other 9997 disjuncts
>> have a value of infinity (since -log 0 = infinity, and
>> the probability of observing the other disjuncts was
>> zero).
>>
>> So the clustering problem is to find clusters in a
>> ten-thousand-dimensional space, where each
>> disjunct is an axis/dimension, and 9990 of the
>> coordinate values are infinite.
>
> I am trying to compare here two different views of clustering
>
> 1. Having disjunct as an axis
>
>
> One way is direct case using the constraints as implemented in
> /opencog/nlp/wsd-post/cluster.scm.
well, the above is a very crude clustering algo, and is not
ideal in a large number of ways. It did, however,
demonstrate to me that the concept is sound.
> In this case each word represents a point along the axis. The thing to note
> is two different words which have different disjuncts lie on different axis
> and can never be clustered into a common group since each axis is othogonal
> to each other.
Yes. I thought that this was an important feature!
> For eg:
>
> (gave, "Ss- Os+ MVp+") and (gave, "Ss- Os+ MVp+ MVp+") cannot be in a common
> cluster whereas I think it is valid to have both of them in the same
> cluster.
Why?
1) a-priori, there is no reason to beleive that these should
be in the same cluster, I don't see why you would want to
lump them together.
2) a posteriori, *after* looking at actual results, one could
descide that, for the case of repeated MV+ links, that
these could be collapsed together into a "one or more
MV+ link" class.
The point is that one must be careful with a-priori assumptions, as I
think there are counterexamples,
involving transitive verbs, direct and indirect objects,
and the like.
> Also (gave, "Ss- Os+ MVp+") and (gave, "Ss- Op+ MVp+") cannot be in a common
> cluster.
Same comments as above. You can say "I sang songs"
but not "I sang her". But "I sang her songs" is OK. I don't
want to start making a-prior assumptions about what's
grammatical, and what's not: I want to discover this in the
data.
Once a pattern is discovered, the parse rules themselves
can be modified to either strengthen it, or to weaken it.
I not only want to learn clusters, I want to learn how to modify
the grammar rules themselves i.e. to modify what sorts
of linkages a word can take.
> Also how do we know that log_cond_prob condition is a good constraint. Many
> times a word can have many senses and may have many disjuncts possible. In
> such a case, we cannot discard those words and log_cond_prob will not be a
> good constraint to decide in such cases.
I don't understand what you are trying to say here.
> The other way of viewing is that each word represents a point with disjuncts
> as its co-ordinates. But this will be completely wrong since a word may
> represent many senses and clustering words of different senses with another
> word does not make sense.
I don't get it. You say "the other way" but this is exactly
what cluster.scm implemented. So I we're somehow
talking past each other; I don't understand whtt this
"other way" is, nr why nits wrong. (What's wrong with
clustering different senses?) Again, I son't want to
assume that anything is "wrong" -- if clustering lumps
things together, then so be it -- and the scientific question
becomes "why did these things get lumped together?"
> 2. Link as an axis
>
> Each tuple is represented by a vector with its links as its co-ordinates.
> Tuple represents a point and the clustered group represents the region of
> points in the space behaving syntactically similar.
>
> So each point is a vector which looks like this
>
> (Ss-, Ss+, Sp+, Sp-, Os-, Os+, Op-, Op+, MVp+, MVp-, Ox+, Ox-, ..... blah,
> blah)
I don't quite get it: given a disjunct, say, for example,
(Ss- & Os+), then the actual vector has the value
(1,0,0,0,0,1,0,0,0,0,0,0,0,0,... blah)
right? so the coordinate is 1 if the link is present, and 0
if the link is absent, right? Or are you somehow
assigning coordinates in some other way?
> or each link can be further divided like this
>
> (S, s, p, -, + , O, s, p, -, +, MV, s, p, -, +, .... .... ..... )
This too needs an example, as i don't understand what
you are trying to do.
> The feature scores can be the log conditional probabilities or any other
> which we need to discuss.
I don't know what you mean by "feature score".
> We can also use methods used in previous works like [1]
I'll read that shortly.
> The difference is that they have (child_word, parent_word,
> link_name) tuples.
I beleive I have a table of those as well. No matter, even if
not, it can be generated readily enough.
> But all the above works are based on the assumption that words behaving
> syntactically similar are semantically similar. But in our case this may not
> be true.
well, I know explicitly that its not true. The collection of
transitive verbs is large, and behave in syntacticaly similar fashion,
yet are semantically diverse. I am hoping that
clustering will reveal a more fine-grained structure to the
class of all transitive verbs. Just how "semantic" this
structure will be, I don't know.
> We are trying to cluster words based on seeing only its disjuncts
> and nothing more than that. (like using the child_word, parent_word
> inforamtions). What do you think ?.
I have a wide variety of statistical information. I can
generate even more types of statistics fairly easily,
although it takes a lot of cpu time (weeks, typically)
> What does link clusters represent ?
I don't know; the goal is to find out.
--linas
Siva Reddy
2009/6/16 Siva Reddy <gvs....@gmail.com>:
> Hi Linas,
>
>>
> 1. Having disjunct as an axis
>
>
> One way is direct case using the constraints as implemented in
> /opencog/nlp/wsd-post/cluster.scm.
well, the above is a very crude clustering algo, and is not
ideal in a large number of ways. It did, however,
demonstrate to me that the concept is sound.
> In this case each word represents a point along the axis.
To say it more clearly each tuple (word, disjunct, log_cond_prob) represents a point along the axis with log_cond_prob as its distance from the origin. A word may have multiple points lying on different axes since a word can have multiple disjuncts (Each disjunct is an axis).
The thing to note
> is two different words which have different disjuncts lie on different axis
> and can never be clustered into a common group since each axis is othogonal
> to each other.
Again, two tuples lying on different axes cannot be clustered into one group. Here we are trying to group tuples into clusters ( and not the words exactly).
Yes. I thought that this was an important feature!
But grouping tuples with different disjuncts into same cluster is also a strong feature. But this have to be done very carefully. If this is done, we can learn unseen disjuncts for some words.
Why?
> For eg:
>
> (gave, "Ss- Os+ MVp+") and (gave, "Ss- Os+ MVp+ MVp+") cannot be in a common
> cluster whereas I think it is valid to have both of them in the same
> cluster.
1) a-priori, there is no reason to beleive that these should
be in the same cluster, I don't see why you would want to
lump them together.
2) a posteriori, *after* looking at actual results, one could
descide that, for the case of repeated MV+ links, that
these could be collapsed together into a "one or more
MV+ link" class.
The point is that one must be careful with a-priori assumptions, as I
think there are counterexamples,
involving transitive verbs, direct and indirect objects,
and the like.
Ahh. This makes clustering more complex. So what you are trying to say is if a word 'w' does not appear with a disjunct 'Dj' in our collected statistics, then the word 'w' cannot have 'Dj' as its disjunct. Correct ? Even if it has we need not handle it right.
If the above statement is wrong, then we also need to add unseen disjuncts to words. Is this possible without clustering tuples with different disjuncts into same cluster so that set of disjuncts acceptable to all the words in the cluster can be described. (In this way, words can be assigned even unseen disjuncts)
Same comments as above. You can say "I sang songs"
> Also (gave, "Ss- Os+ MVp+") and (gave, "Ss- Op+ MVp+") cannot be in a common
> cluster.
but not "I sang her". But "I sang her songs" is OK. I don't
want to start making a-prior assumptions about what's
grammatical, and what's not: I want to discover this in the
data.
Then what is the use of a cluster. We are not learning anything new from our clusters. I guess cluster helps in only arriving at the value of threshold to decide if a disjunct is valid for a word or not.
We can directly take each word and check what all disjuncts are possible to it and based on each disjunct score we can check if the disjunct is valid for that word and also try to fit a rule (generalize) that can describe all its disjuncts.
Now a cluster can be defined as the group of words having same disjunct. Using these clusters, link grammar dictionaries can be modified.
Once a pattern is discovered, the parse rules themselves
can be modified to either strengthen it, or to weaken it.
I not only want to learn clusters, I want to learn how to modify
the grammar rules themselves i.e. to modify what sorts
of linkages a word can take.
I don't understand what you are trying to say here.
> Also how do we know that log_cond_prob condition is a good constraint. Many
> times a word can have many senses and may have many disjuncts possible. In
> such a case, we cannot discard those words and log_cond_prob will not be a
> good constraint to decide in such cases.
If a word has many disjuncts possible, then p(D/w) is distributed over many disjuncts such that summation_over_D p(D/w) = 1 making the scores of each disjunct low. Since our source of decision comes from the scores only, we may miss out these kind of words. This is why I find the scores (eg: log_cond_prob) are not good enough to take decisions. But for most words these scores will be helpful
> The other way of viewing is that each word represents a point with disjuncts
> as its co-ordinates. But this will be completely wrong since a word may
> represent many senses and clustering words of different senses with another
> word does not make sense.
I don't get it. You say "the other way" but this is exactly
what cluster.scm implemented.
Hmm. I confused you a bit. Lets leave this "other way" since I find it inappropriate to this topic.
Currently, I developed a method of clustering. Once I finish implementing it, I will explain it in detail. Or I will mail the details soon.
I don't quite get it: given a disjunct, say, for example,
> 2. Link as an axis
>
> Each tuple is represented by a vector with its links as its co-ordinates.
> Tuple represents a point and the clustered group represents the region of
> points in the space behaving syntactically similar.
>
> So each point is a vector which looks like this
>
> (Ss-, Ss+, Sp+, Sp-, Os-, Os+, Op-, Op+, MVp+, MVp-, Ox+, Ox-, ..... blah,
> blah)
(Ss- & Os+), then the actual vector has the value
(1,0,0,0,0,1,0,0,0,0,0,0,0,0,... blah)
right? so the coordinate is 1 if the link is present, and 0
if the link is absent, right?
No
Or are you somehow
assigning coordinates in some other way?
Yes. We have to use scores as co-ordinate values. But I found it difficult to come up with a score.
I will talk about the below method later. Its not needed right now.
This too needs an example, as i don't understand what
> or each link can be further divided like this
>
> (S, s, p, -, + , O, s, p, -, +, MV, s, p, -, +, .... .... ..... )
you are trying to do.
I'll read that shortly.
I beleive I have a table of those as well. No matter, even if
> The difference is that they have (child_word, parent_word,
> link_name) tuples.
not, it can be generated readily enough.
If we have these tables, we can directly use the method mentioned in [1] to cluster semantically similar words. These clusters can have lot of information to learn new unseen disjuncts for words.
--linas
[1] Dekang Lin, Automatic Retrieval and Clutering of Similar Words.
Thanks,
Siva
Siva Reddy
Do you have the type hierarchy of Link grammar links (relations) like
Rel
|__S*
| |_Ss*
| | |__Ssxxx
| |
| |_Sp*
|
|__O*
|_Os*
|
|_Op*
Also, do you have any distance functions defined between two links. Can you give me some pointers. Should I use wordnet kind of similarity measures ?
Thanks,
Siva
Linas Vepstas
>
>
> On Thu, Jun 18, 2009 at 4:28 AM, Linas Vepstas <linasv...@gmail.com>
> wrote:
>>
>> 2009/6/16 Siva Reddy <gvs....@gmail.com>:
>> > Hi Linas,
>> >
>> >>
>> > 1. Having disjunct as an axis
>> >
>> >
>> > One way is direct case using the constraints as implemented in
>> > /opencog/nlp/wsd-post/cluster.scm.
>>
>> well, the above is a very crude clustering algo, and is not
>> ideal in a large number of ways. It did, however,
>> demonstrate to me that the concept is sound.
>>
>> > In this case each word represents a point along the axis.
>
> To say it more clearly each tuple (word, disjunct, log_cond_prob) represents
> a point along the axis with log_cond_prob as its distance from the origin. A
> word may have multiple points lying on different axes since a word can have
> multiple disjuncts (Each disjunct is an axis).
Yes. I like to think of it as a very high-dimensional
vector space; the number of dimensions is equal
to the number of possible disjuncts, which is 5K or 10K
or so. Rather than just thinking in terms of a "point"
on an axis, think instead "vector space" -- the vector
has a projection down to each axis, the projection
is just some number e.g. the mutual info, or entropy or whatever.
> Again, two tuples lying on different axes cannot be clustered into one
> group.
? If you has points in a vector space, then a natural
similarity measure is the euclidean distance between
the points.
When in doubt, envision everything as being
two-dimensional.
> If this is done, we
> can learn unseen disjuncts for some words.
Yes, exactly!
>> > (gave, "Ss- Os+ MVp+") and (gave, "Ss- Os+ MVp+ MVp+") cannot be in a
>> > common
>> > cluster whereas I think it is valid to have both of them in the same
>> > cluster.
>>
>> Why?
>> 1) a-priori, there is no reason to beleive that these should
>> be in the same cluster, I don't see why you would want to
>> lump them together.
>>
>> 2) a posteriori, *after* looking at actual results, one could
>> descide that, for the case of repeated MV+ links, that
>> these could be collapsed together into a "one or more
>> MV+ link" class.
>>
>> The point is that one must be careful with a-priori assumptions, as I
>> think there are counterexamples,
>> involving transitive verbs, direct and indirect objects,
>> and the like.
>>
>
> Ahh. This makes clustering more complex.
I don't think so: I was trying to assert something simpler:
when looking for patterns in data, it is faulty to assume
that some particular pattern must surely be there, and
then build that assumption into your methodology.
Don't assume. Let the data show you what is true.
> So what you are trying to say is if
> a word 'w' does not appear with a disjunct 'Dj' in our collected statistics,
> then the word 'w' cannot have 'Dj' as its disjunct.
No. If it does not appear, then maybe our sample set
was too small, or was skewed. It might appear (with
low probability) if the data set was larger.
>> > Also (gave, "Ss- Os+ MVp+") and (gave, "Ss- Op+ MVp+") cannot be in a
>> > common
>> > cluster.
>>
>> Same comments as above. You can say "I sang songs"
>> but not "I sang her". But "I sang her songs" is OK. I don't
>> want to start making a-prior assumptions about what's
>> grammatical, and what's not: I want to discover this in the
>> data.
>
> Then what is the use of a cluster. We are not learning anything new from our
> clusters.
? I didn't really understand what you meant by the above,
or what followed.
> If a word has many disjuncts possible, then p(D/w) is distributed over many
> disjuncts such that summation_over_D p(D/w) = 1 making the scores of each
> disjunct low.
Yes.
> Since our source of decision comes from the scores only, we
> may miss out these kind of words.
I don't know what you mean by "miss out". It is possible
that these might not be assigned to the same cluster,
when they should have been. So if we have a word
"asdf" which apears with many many disjuncts, and
another word "pqrs" which appears with many, but
different, disjuncts, then each may be assigned to its own,
unique cluster.
At some point, we print out the list of clusters, and look
at them. We''lk see "asdf" in one, and "pqrs" in another,
and we might say "gee, shouldn't these have been in
the same cluster? Why weren't they? Were our similarity
measures incorrect? Our cluster diameters too narrow?
our dataset too small? Or perhaps these words are
more different than they seem?" I don't know what the
answers to any of these questions are: and more, I don't
even want to assume or guess what the answers might
be: I'd rather run the experiment, look at the data, and
find out!
> Currently, I developed a method of clustering. Once I finish implementing
> it, I will explain it in detail.
Well, rather than implementing it, I'd like you to explain
what it is ... what is the space? How are coordinates assigned? what
is the similarity measure?
Give a simple example, with 2 or 3 or 4 data points, and
show how two are close by, and thus clustered, and how
the 3rd is not.
--linas
Linas Vepstas
> Hi Linas,
>
> Do you have the type hierarchy of Link grammar links (relations) like
>
> Rel
> |__S*
> | |_Ss*
> | | |__Ssxxx
> | |
> | |_Sp*
> |
> |__O*
> |_Os*
> |
> |_Op*
Well, you can certainly draw the tree you drew above,
but I don't understand what it means or what it's good
for.
> Also, do you have any distance functions defined between two links.
I don't understand what you mean. Given the word on the
left and the word on the right, I can tell you how often a link occurs.
Or do you mean "the length of a link" -- i.e. how many
words appear in between the two connected words?
If you are asking "how similar is Sp to Os" then I don't
know .. and I can't guess what that means or what its
good for.
Given a long list of disjuncts, I guess you could ask
questions like "what happens if I replace all occurances
of Sp+ by Os- ?" but I have some difficulty guessing why
this would be an interesting question.
I guess you could say that a "G" link is kind-of-like an
"GN" link, in a hand-waving kind of way. Perhaps,
due to a broken dictionary, we are incorrectly using
a G link when a GN should have been used. Then it
might make sense to ask "what happens if we lumped
these two together into one".
However, I'd rather see this question formulated as
a hypothesis against the data: if the hypothesis is true,
then there should be some pattern in the data. Then we
look at the data: Is the pattern there, or not?
(Certainly, the dictionary is "broken" in many many
ways, with all sorts of incorrect links being used.
How to find and correct these in a semi-automated
fashion is an open question.)
--linas
Siva Reddy
Lets take word1 and word2 belonging to the same cluster. What are the properties common to both of the words?. The answer will make many things clear.
Is it true that word1 have the exact same disjuncts as word2 ? My answer is no. What is your answer ?
Thanks,
Siva
Linas Vepstas
I agree.
But what is more important, some disjuncts may occur
far more frequently than others. So for example:
word1 occurs with A+ & B- with p=0.9
word1 occurs with C+ & D- with p=0.1
word2 occurs with A+ & B- with p=0.8
word2 occurs with C+ & D- with p=0.1
word2 occurs with A+ & D- with p=0.1
It is probably reasonable to assign
word 1 and 2 to the same cluster. Note that
word1 has an implicit coordinate at zero:
word1 occurs with A+ & D- with p=0.0
which is not all that far away from word2.
If we use Euclidean distance, these are
sqrt ((0.9-0.8)^2 + (0.1-0.1)^2 + (0.1)^2) = 0.1414
Compare now word3:
word3 occurs with A+ & B- with p=0.15
word3 occurs with C+ & D- with p=0.8
word3 occurs with A+ & D- with p=0.05
It is probably incorrect to find word3 in the
same cluster as words 1 & 2.
The distance is greater:
the Euclidean distance between word3 and
the center of the 1-2 cluster is
sqrt((0.85-0.15)^2 + (0.8-0.1)^2 + 0^2) = 0.99
Instead of using p, it is interesting to think about
using -ln p as the coordinate value. Instead of using
Euclidean distance, other distances (or divergences)
might be reasonable.
--linas
Siva Reddy
I explored some of the clustering tools and algorithms which can be used to cluster words based on disjuncts. Cluto[1], Weka[2], Lucene[3] and Nutch[4] are the some of the popular clustering tools freely available.
Cluto is a dedicated clustering tool for clustering low- and high-dimensional datasets and for analyzing the characteristics of the various clusters. It also has graphical interface. This has many clustering algorithms which I think suits us well.
Weka has both classification and clustering. But limited clustering algorithms are only implemented in it.
Lucene and Nutch are very famous in search industry. But their main purpose is not clustering. They are designed to help building search engines. Also their code base is very large.
So I am planning to use Cluto for clustering. I found it customizable.
Your previous mail cleared many of my doubts. I still have some. Is it possible for a word to go to multiple clusters. If so, how is it possible. Can you please give me an example ?.
Tasks to do:
----------------
I am using your idea of disjunct as an axis and point as a vector with disjuncts as co-ordinates. Task is to apply different clustering algorithms with different parameters for clustering.
Clustering Algorithms:
1. Direct (already implemented by you)
2. K-means clustering.
3. agglomerative (bottom up clustering)
4. repeated bisections (top down clustering)
5. EM Algorithm (I will do this only after completing above algorithms)
Different type of similarity measures available to measure the similarity between two clusters:
1. Eucledian distance
2. cosine similarity
3. Jacard co-efficient
4. Correlation co-efficient
Features that are avialable to define the co-ordinates of the vector.
1. log conditional probabilities
I am still afraid of clustering whenever I think of word senses. I feel it would be better to cluster word senses rather than the words. But as you said we will keep it for later.
I will mail you some of the results tomorrow or on Sunday. How are we going to evaluate the clusters formed. One naive way of evaluation would be using the already existing dict files in link parser. If two words are clustered into a same cluster and if they exist in the same dict file of link parser, we can take it as a +ve hit.
Also how are we going to use the clusters ? One of the use is that since we have same set of disjuncts for all the words in cluster it will be possible to learn unseen disjuncts for a word. But we need to be careful since we do not know if this assumption is correct.
References:
[1] http://glaros.dtc.umn.edu/gkhome/views/cluto
[2] http://www.cs.waikato.ac.nz/ml/weka/
[3] http://lucene.apache.org/
[4] http://lucene.apache.org/nutch/
I find these link very useful to get knowledge about clustering. http://statsoft.eu/uk/textbook/stcluan.html , http://databases.about.com/od/datamining/Data_Mining_and_Data_Warehousing.htm
Thanks,
Siva
Linas Vepstas
> Hi Linas,
>
> I explored some of the clustering tools and algorithms which can be used to
> cluster words based on disjuncts. Cluto[1], Weka[2], Lucene[3] and Nutch[4]
> are the some of the popular clustering tools freely available.
Cluto is not, it is proprietary. see e.g.
http://glaros.dtc.umn.edu/gkhome/node/332
I think that rules it out for general use.
Weka might be the way to go.
There is a long list of open-source clustering s/w at
http://mloss.org/software/tags/clustering/
I have not read through this list myself.
> Is it
> possible for a word to go to multiple clusters.
Not usually, but that depends on the clustering algorithm.
Most clustering algorithms try to assign any given item to
only one cluster.
> Clustering Algorithms:
> 1. Direct (already implemented by you)
Badly...
> 2. K-means clustering.
I am concerned that the K-means algo is very slow, and will be overwhelmed.
> 3. agglomerative (bottom up clustering)
> 4. repeated bisections (top down clustering)
> 5. EM Algorithm (I will do this only after completing above algorithms)
OK.
> I am still afraid of clustering whenever I think of word senses.
The initial attempt should be to cluster words by grammatical
properties, and not word-senses. The word-senses problem
is considerably harder.
> I feel it
> would be better to cluster word senses rather than the words.
Again, this is harder. For example, pick some common verb
that can be used in a transitive and intransitive way. For example:
give -- see http://www.thefreedictionary.com/give
Notice it has sections for v.tr and v.intr and the definitions in each
section are distinct.
Now, link-grammar does not by itself distinguish between these
senses: it just has one entry for "give", and provides parsing
rules that allow it to be used in a transitive or intransitive fashion.
Likewise, the statistical tables that I have list the frequency of
how often this word was used in different syntactical constructions.
How should we "split apart" these frequency counts, so as to
assign them to distinct senses?
One might try to do this a-priori, e.g. tag them with wordnet sense
using some other, entirely different algorithm (e.g. one of the
usual WSD algorithms).
Alternately, one might try to look at how some synonymous words
were used - e.g. synonyms for "to make a present of, to deliver,
to hand over" these synonyms will account for *some* of the
observed syntatic usage of "give", but not all. What is left over
is presumably senses like "to collapse from force or pressure".
However, doing this kind of data-mining is likely to be quite
difficult, since I suspect the dataset is quite noisy, and it wiil
be hard to pick these apart. This is why its important to get
the simpler cases well-understood and working.
> How are we going
> to evaluate the clusters formed.
At this point, "seat of the pants".
> One naive way of evaluation would be using
> the already existing dict files in link parser.
Well, my intent was to turn this process on its head: I'm hoping
to find that the results of clustering will be *more* accurate than
the lg dicts, and I wanted to use those to make corrections
and fixes to LG.
> Also how are we going to use the clusters ? One of the use is that since we
> have same set of disjuncts for all the words in cluster it will be possible
> to learn unseen disjuncts for a word. But we need to be careful since we do
> not know if this assumption is correct.
Yes, we'd have to feel our way around and see what happens.
--linas
Siva Reddy
Cluto is not, it is proprietary. see e.g.
http://glaros.dtc.umn.edu/gkhome/node/332
I think that rules it out for general use.
Oops. I read the readme file and found that it is free to use for researched purposes. So I thouhght it has GPL license. Ok, we shall discard using this tool.
Weka might be the way to go.
I am currently using this. It has the following algorithms implemented.
1. K-means
2. EM
3. Farthest first
4. Cobweb
There is a long list of open-source clustering s/w at
http://mloss.org/software/tags/clustering/
I have not read through this list myself.
Thanks for the link. The link has many useful tools.
Not usually, but that depends on the clustering algorithm.
> Is it
> possible for a word to go to multiple clusters.
Most clustering algorithms try to assign any given item to
only one cluster.
Badly...
> Clustering Algorithms:
> 1. Direct (already implemented by you)
> 2. K-means clustering.
I am concerned that the K-means algo is very slow, and will be overwhelmed.
Input format:
----------------
Each word is represented by a vector with the word's disjuncts as the co-ordinates. The value of each coordinate is the log conditional prob of the corresponding disjunct.
The disadvantage of this method is that the vector dimensional space is very large. To get rid of this, we can first generalize the disjuncts and perform clustering. Then each cluster is selected and by specialization of the disjuncts, words are further divided into clusters. Finally we will end up in the leaves which are the clusters we need. I am trying out this currently.
The main problem with many of the existing clustering algorithms is the we should know the number of clusters apriori. Is there any way to know this ??
I found that if we know the number of clusters to be formed, K-means performance is better than other clustering algorithms. I ran some experiments with the data already present in Weka and found this.
If it is not possible to know "K" aprori, then Cobweb [1] suits best. It automatically clusters the data with no need of specyfying the number of clusters to be formed. But this takes lot of computation. Even on small data, it takes 10 times more time than other clustering algos.
> 3. agglomerative (bottom up clustering)
> 4. repeated bisections (top down clustering)
> 5. EM Algorithm (I will do this only after completing above algorithms)
[1] D.H Fisher. Knowledge Acquisition Via Incremental Conceptual Clustering
Regards,
Siva
Siva Reddy
I found this links useful to our project.
http://www.link.cs.cmu.edu/link/dict/
http://python.about.com/od/pythonanddatabases/ss/postgresqlread.htm
Regards,
Siva
Hi Linas,
From the dump you gave me, I got 379442 distinct disjuncts. All these cannot be valid disjuncts. Some of the disjuncts are very long. Since we represent word as a vector of disjuncts, we need to choose certain disjuncts among all these disjuncts.
I am using the following criteria for choosing a disjunct to be a dimension. I sorted disjuncts based on their word frequency i.e with how many distinct words did the disjunct occur. Shall I select top 10000 disjuncts in the sorted list to be the dimensions. Is this ok ? I am attaching the disjunct frequency file. First and second columns represent (disjunct, word_frequency) respectively.
I generated one more frequency list by generalizing distincts by removing additional attributes of each link. For eg: link Ss- is changed to S-. I am also attaching this file. The number of distinct disjuncts are 67982 which are far less compared to the previous list. I think it would be better if we select a disjunct based on its frequency. Please see the list and can you comment anything on this. Clustering using these disjuncts as vector co-ordinates help us in designing a heirachial clustering algorithm. Also the dimensional space would be small.
Next steps:
---------------
1. Generating word as vectors
2. Applying clustering (Is there any possibility on guessing the number of clusters to be formed.)
I am using python. I generated the attached files using it. Database connectivity in python is very easy. Also it has all the functions present in perl and I am very convinient in using python.
Thanks,
Siva
Linas Vepstas
> The main problem with many of the existing clustering algorithms is the we
> should know the number of clusters apriori. Is there any way to know this ??
>
> I found that if we know the number of clusters to be formed, K-means
> performance is better than other clustering algorithms.
I can provide an approximate answer:
link-grammar currently has about 71 "large" clusters
and another 1500 or so "small" clusters, where
"large" means 30 or 50 or more members, and
"small" is in the 1-50 range. I get these numbers
by counting the number of semi-colons in
data/en/4.0.dict, and for the "large" clusters, the
number of files in the "data/en/words" directory.
So, for initial runs, try K=1500 or K=2000 and see
what happens.
My long-term goal is to refine this into even more, smaller,
tighter clusters.
--linas
Siva Reddy
To decide on the disjuncts to use as dimensions, I collected the following statistics. These statistics are collected from the tuples (word, disjunct, count, log_cond_prob) which satisify count >= 3.0. This is an assumption similar to the one used in opencog/nlp/wsd-post/clusters.scm
Attached files are the collected statistics of disjuncts. Please have a view. Column 1 repesents the disjunct, Column 2 represents the number of distinct words which occured with this distinct, Column 3 represents the total count of this disjunct with all the words.
Three files are generated.
- Type0: Statistics are collected without modifying disjuncts
- Type1: Statistics are collected by removing additional attributes of the disjunct links. For eg: Sp- Os+ MVp+ is changed to S- O+ MV+
- Type2: Statistics are collected by generalizing the disjuncts. The basic idea is to merge many dimensions initially and then expand them at later levels of clustering. This helps us in reducing the dimenisions of the vector space
Type1 has 7134 disjuncts
Type2 has 4967 disjuncts
We see the reduction in dimension space as we generalize the disjunts.
Questions:
-------------
1. What criteria should I choose for a disjunct to be eligible to make it as an axis.
2. Which do you think is better to start with. Type1 or Type2 or Type3
Thanks,
Siva
Siva Reddy
I am attaching the program which is used to generate the statistics. I do not the programming style/guidelines/conventions of opencog. Please check if this is ok.
Immediate tasks to follow:
---------------------------------
1. Preparing data for clustering in Weka format.
2. Applying K-means and EM (based on your suggestion of number of clusters to be formed)
3. I think cobweb algorithm suits us well if we are not sure of the number of clusters to be formed. Do you have any suggestions on algorithms to be used ?. We can try our clustering algorithms based on our own similarity measures (currently Eucledian is used)
Thanks,
Siva
Linas Vepstas
2009/7/5 Siva Reddy <gvs....@gmail.com>:
> From the dump you gave me, I got 379442 distinct disjuncts. All these cannot
> be valid disjuncts.
? Well, they were all generated by the parser, and so they
are "valid" in that sense. The parse itself may have been
invalid, but that's a different issue.
> Some of the disjuncts are very long. Since we represent
> word as a vector of disjuncts, we need to choose certain disjuncts among all
> these disjuncts.
Why? What's wrong with using all of them?
> I am using the following criteria for choosing a disjunct to be a dimension.
> I sorted disjuncts based on their word frequency i.e with how many distinct
> words did the disjunct occur.
There's an alternate way of counting, which is different,
and maybe more correct, and that is to count how often
a disjunct occurred in real text, instead of how often it was
recorded in the file. i.e. instead of adding +1 for each line
in the file, add +N where N is the count value in the table.
N is the actual number of times that disjunct-word-pair was
seen in real text.
> Shall I select top 10000 disjuncts in the
> sorted list to be the dimensions. Is this ok ?
Sure, but realize that this cutoff is purely arbitrary.
I'm attaching a graph which shows that the frequency
of disjuncts is very nearly scale-free -- I plotted your
raw data against Zipf's law on a log-log graph. Its
well-known that scale-free data simply doesn't have
any natural cutoff. (Scale-free data obeying Zipf's law
is seen everywhere, from sand-piles and shoreline
coast lengths and critical exponents in physics,
to the sizes of cities, the number of hits on web sites,
and the number of citations an academic paper gets).
> I generated one more frequency list by generalizing distincts by removing
> additional attributes of each link. For eg: link Ss- is changed to S-.
I don't like this. Its loosing important data.
A better idea would be to collapse identical links,
but only if they occur next to each-other. So, for
example:
MX- Xd- G- MX+ MX+ MX+ Xca+
can be converted into
MX- Xd- G- @MX+ Xca+
so that @MX+ means "zero or more occurrences of MX+"
However, even here, care should be taken: the above
can only be safely done if the actual data contains
MX- Xd- G- MX+ MX+ MX+ Xca+
MX- Xd- G- MX+ MX+ Xca+
MX- Xd- G- MX+ Xca+
MX- Xd- G- Xca+
which justifies collapsing this into one.
Doing this would be nice, but is not strictly necessary
for the first round of data analysis.
> select a disjunct based on its frequency.
Yes, reducing the number of disjuncts considered will
make it easier to work with the data. As the scale-free
graph shows, its reasonable to put the cutoff just about anywhere,
although I expect better accuracy by using
more data.
--linas
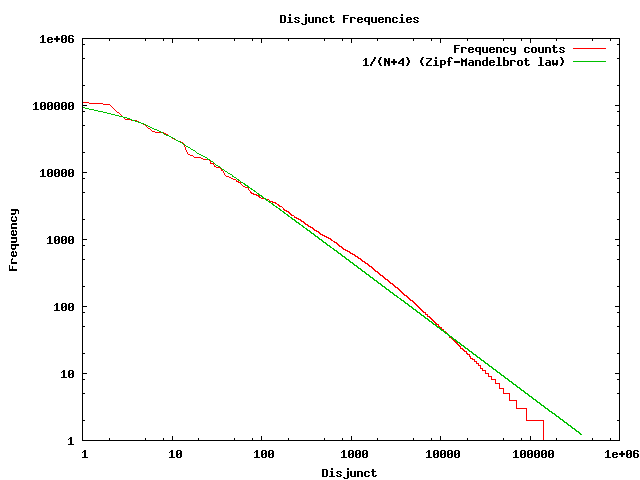{kind=link}
Linas Vepstas
2009/7/5 Siva Reddy <gvs....@gmail.com>:
>
> I sorted disjuncts based on their word frequency
The most frequent one was blank. What does that mean?
--linas
Siva Reddy
Blank disjunct is present in the database. So I collected it. I think it represents no relation with other words (since I find [] around the words). The word might have been left while parsing. Sample output from the database is shown below
word disjunct count log_cond_probability
and 465321.326745 0.0490705099187
, 137676.573512 2.81980213994
[.] 52408.7862595 1.74461475342e-06
or 46963.1671923 0.00734402135222
[,] 35310.4253245 0.0
but 23381.3670903 0.349716245838
[of] 22213.5195756 0.0
[:] 16108.7989889 0.0
[rparenID2] 15784.1946385 0.0
Regards,
Siva
Linas Vepstas
> Linas,
>
> Blank disjunct is present in the database. So I collected it. I think it
> represents no relation with other words (since I find [] around the words).
Yes, that's exactly it. Thanks.
You should leave these out during clustering, they'll
mess up the data.
--linas
p.s. I blogged the frequency counts at
http://opencog.wordpress.com/2009/07/06/frequency-of-grammatical-disjuncts/
Linas Vepstas
Actually, the above link is slightly out of date,
there have been some minor modifications and
revisions. The current copy is located at:
http://www.abisource.com/projects/link-grammar/dict/index.html
--linas
Linas Vepstas
2009/7/6 Siva Reddy <gvs....@gmail.com>:
> Attached files are the collected statistics of disjuncts. Please have a
> view. Column 1 repesents the disjunct, Column 2 represents the number of
> distinct words which occured with this distinct, Column 3 represents the
> total count of this disjunct with all the words.
The more I look at this, the more I dislike column 2.
Its clear that G+ and AN+ are vastly over-represented.
This is in part because the corpus is wikipedia, and
every new article introduces a new given name of
one sort or another, frequently a foreign word at that.
A large portion of wikipedia articles are biographies,
and this shows in the frequency of the G and AN links.
(that is, the databse has a large number of unique,
distinct names in it, and these names connect with G
and AN links. Because there are a lot of names, they
contribute to your counts. By contrast, words like "the"
"a" "of" "in" "there", etc. are strongly under-represented
in your counts -- but would show up in the column-3 counts.)
By contrast, compare the counts of MVp and MVa links;
these connect verbs to various things -- you can see how
much more popular they are when you consider the
floating-point frequency in column 3, which is what should
be used for ranking.
> Type0: Statistics are collected without modifying disjuncts
>
> Type1: Statistics are collected by removing additional attributes of the
> disjunct links. For eg: Sp- Os+ MVp+ is changed to S- O+ MV+
I really dislike this, this looses important information.
To trim down the size of the dataset, it would be better
to eliminate everything which contains a capital letter,
number or punctuation. A reasonable first start would
be accept words that consist entirely of ASCII lower-case,
or dot, or dash (dot and dash are used in word subscripts)
That should drastically reduce the number of words.
Another simplification is to ignore all disjuncts that
contain ID*** connectors. There are thousands of these,
they are used only for idiomatic phrases, and so by
definition will always sit in a cluster by themselves.
-- linas
Siva Reddy
? Well, they were all generated by the parser, and so they
> From the dump you gave me, I got 379442 distinct disjuncts. All these cannot
> be valid disjuncts.
are "valid" in that sense. The parse itself may have been
invalid,
That is why I used your constraint of count > 3.0 to eliminate disjuncts from very low parse scores. Even this may not be a correct constraint for eliminating such disjuncts. The best one would be I guess the ratio
count(disjunct_with_this_word)/actual_count(disjunct_with_this_word)
where actual_count is the number of times the disjunct occurred with this word (This is obtained by adding +1 everytime rather than adding parse score every time)
If it is less than a threshold, we can eliminate that entry but we don't have the actual counts in the current tables. Right now I am discarding this option.
but that's a different issue.
Why? What's wrong with using all of them?
> Some of the disjuncts are very long. Since we represent
> word as a vector of disjuncts, we need to choose certain disjuncts among all
> these disjuncts.
Hmm. You are correct. I understood this from the plot. Did you plot all the disjuncts and got the zipfs curve ?. In your plot I see some disturbances in the end points of the curve which tells us that there is some abnormality with bottom most. If we can find the good range of disjunts that follow zipfs curve I think these dijuncts can be choosen as the valid axes.
There's an alternate way of counting, which is different,
> I am using the following criteria for choosing a disjunct to be a dimension.
> I sorted disjuncts based on their word frequency i.e with how many distinct
> words did the disjunct occur.
and maybe more correct, and that is to count how often
a disjunct occurred in real text, instead of how often it was
recorded in the file. i.e. instead of adding +1 for each line
in the file, add +N where N is the count value in the table.
N is the actual number of times that disjunct-word-pair was
seen in real text.
Yes. I have seen your latest mail and will follow as you said.
> Shall I select top 10000 disjuncts in theSure, but realize that this cutoff is purely arbitrary.
> sorted list to be the dimensions. Is this ok ?
I'm attaching a graph which shows that the frequency
of disjuncts is very nearly scale-free -- I plotted your
raw data against Zipf's law on a log-log graph. Its
well-known that scale-free data simply doesn't have
any natural cutoff. (Scale-free data obeying Zipf's law
is seen everywhere, from sand-piles and shoreline
coast lengths and critical exponents in physics,
to the sizes of cities, the number of hits on web sites,
and the number of citations an academic paper gets).
Nice explanation. I never knew this law. Now Zipf's law is in my pocket. I think any corpus can be validated using this. Its interesting that this law holds for disjuncts too. In our case I think it is trying to say this. It is not wrong to discard some of the disjuncts and then cluster. Even those clusters represent something meaningful. One can further cluster these clusters already formed with the disjuncts that were discarded earlier.
I don't like this. Its loosing important data.
> I generated one more frequency list by generalizing distincts by removing
> additional attributes of each link. For eg: link Ss- is changed to S-.
What I thought is initially we cluster it using this generalized data. And at the next stage of clustering we shall introduce these fine grained distinctions to classify the clusters further. But since you say that this information is very important, I will throw away this option.
A better idea would be to collapse identical links,
but only if they occur next to each-other. So, for
example:
MX- Xd- G- MX+ MX+ MX+ Xca+
can be converted into
MX- Xd- G- @MX+ Xca+
so that @MX+ means "zero or more occurrences of MX+"
However, even here, care should be taken: the above
can only be safely done if the actual data contains
MX- Xd- G- MX+ MX+ MX+ Xca+
MX- Xd- G- MX+ MX+ Xca+
MX- Xd- G- MX+ Xca+
MX- Xd- G- Xca+
which justifies collapsing this into one.
Doing this would be nice, but is not strictly necessary
for the first round of data analysis.
Why can't we write it as @MX- @Xd- @G- @Xca+ . I think even this is valid.
My idea is to merge as many dimensions as possible in the first step and then perform initial clustering. And at the later stages, we further divide these initial clusters by expanding the merged dimensions.
Siva
Linas Vepstas
2009/7/6 Siva Reddy <gvs....@gmail.com>:
count(disjunct_with_this_word)/actual_count(disjunct_with_this_word)
>
> where actual_count is the number of times the disjunct occurred with this
> word (This is obtained by adding +1 everytime rather than adding parse score
> every time)
>
> If it is less than a threshold, we can eliminate that entry but we don't
> have the actual counts in the current tables.
The parse-ranker itself is not perfect: it may well be giving
a low score to correct parses, and a high score to
incorrect ones. Its dangerous to second-guess this stuff
too much.
>> A better idea would be to collapse identical links,
>> but only if they occur next to each-other. So, for
>> example:
>>
>> MX- Xd- G- MX+ MX+ MX+ Xca+
>>
>> can be converted into
>>
>> MX- Xd- G- @MX+ Xca+
>>
>> so that @MX+ means "zero or more occurrences of MX+"
>>
>> However, even here, care should be taken: the above
>> can only be safely done if the actual data contains
>>
>> MX- Xd- G- MX+ MX+ MX+ Xca+
>> MX- Xd- G- MX+ MX+ Xca+
>> MX- Xd- G- MX+ Xca+
>> MX- Xd- G- Xca+
>>
>> which justifies collapsing this into one.
>>
>> Doing this would be nice, but is not strictly necessary
>> for the first round of data analysis.
>
> Why can't we write it as @MX- @Xd- @G- @Xca+ . I think even this is valid.
No, because such a rule allows grammatically incorrect sentences: X
connects words to punctuation, so the
above would allow a sentence ,,,,,,,,, with lots of ;;;;;
bogus punctuation.
By contrast, @MX and @A occur frewquently in the dict.
--linas
Siva Reddy
By contrast, compare the counts of MVp and MVa links;
these connect verbs to various things -- you can see how
much more popular they are when you consider the
floating-point frequency in column 3, which is what should
be used for ranking.
Yes. I used this in the updated disjuncts list.
To trim down the size of the dataset, it would be better
to eliminate everything which contains a capital letter,
number or punctuation. A reasonable first start would
be accept words that consist entirely of ASCII lower-case,
or dot, or dash (dot and dash are used in word subscripts)
That should drastically reduce the number of words.
Another simplification is to ignore all disjuncts that
contain ID*** connectors. There are thousands of these,
they are used only for idiomatic phrases, and so by
definition will always sit in a cluster by themselves.
Implemented this. Yes links are reduced drastically.
> A better idea would be to collapse identical links,
> but only if they occur next to each-other. So, for
> example:
>
> MX- Xd- G- MX+ MX+ MX+ Xca+
>
> can be converted into
>
> MX- Xd- G- @MX+ Xca+
>
> so that @MX+ means "zero or more occurrences of MX+"
>
> However, even here, care should be taken: the above
> can only be safely done if the actual data contains
>
> MX- Xd- G- MX+ MX+ MX+ Xca+
> MX- Xd- G- MX+ MX+ Xca+
> MX- Xd- G- MX+ Xca+
> MX- Xd- G- Xca+
>
> which justifies collapsing this into one.
>
> Doing this would be nice, but is not strictly necessary
> for the first round of data analysis.
For Eg:
S-
S- O+
S- O+ O+
- If we generalize the above disjuncts to S- @O+, then S- is also covered by this disjunct. Intransitive verbs have S- as their disjunct and Transitive verbs have S- @O+ as thier disjunct. I think combing Transitive and Intrasitive verbs may not be a good idea. Several such cases arise if we use @ for 0 or more.
- Also, I found implementing it is time taking which can be done after initial round of our analysis of our clusters.
One more mail to follow.
Thanks,
Siva
Linas Vepstas
>> so that @MX+ means "zero or more occurrences of MX+"
>
> I rather took it as one or more instances.
Yes, right.
> S-
> S- O+
> S- O+ O+
>
> If we generalize the above disjuncts to S- @O+, then S- is also covered by
> this disjunct. Intransitive verbs have S- as their disjunct and Transitive
> verbs have S- @O+ as thier disjunct. I think combing Transitive and
> Intrasitive verbs may not be a good idea. Several such cases arise if we use
> @ for 0 or more.
Yes, it should be for "one or more". Also, we should
probably use it only if three or more links were actually
observed. This is because I don't believe that there are
real-life @O+ linkages. (there can't ever be three objects)
> I am attaching the updated disjuncts files. In the generalized disjuncts
> file, @A represents { A, A A , A A A, ... N times A} where maximum value of
> N is atleast 2. Is this ok or shall I change it to three.
It should probably be 3, per above.
--linas
Siva Reddy
> The main problem with many of the existing clustering algorithms is the weI can provide an approximate answer:
> should know the number of clusters apriori. Is there any way to know this ??
>
> I found that if we know the number of clusters to be formed, K-means
> performance is better than other clustering algorithms.
link-grammar currently has about 71 "large" clusters
and another 1500 or so "small" clusters, where
"large" means 30 or 50 or more members, and
"small" is in the 1-50 range. I get these numbers
by counting the number of semi-colons in
data/en/4.0.dict, and for the "large" clusters, the
number of files in the "data/en/words" directory.
I think this might work. Great idea.
So, for initial runs, try K=1500 or K=2000 and see
what happens.
Yes. I will start with this.
My long-term goal is to refine this into even more, smaller,
tighter clusters.
--
Siva
Linas Vepstas
> I am attaching the updated disjuncts files.
Much better, thank you!
Now the top entries make sense:
Ds+ 19 950275.635843
Xp- 1 838569.90527
A+ 6040 616522.664867
AN+ 7904 566658.997313
MVp- Js+ 63 563082.649325
MVp- Jp+ 63 446487.310222
Ds+ connects the determiner "the" to nouns: and of course,
"the" is the most frequent word in the English language.
Xp- connects the period at the end of the sentence to the
start of the sentence, so of course its frequently observed.
A+ connects adjectives to nouns, AN+ connects
noun modifiers.
MV connects verbs to modifying phrases, and J
connects prepositions to objects, so that MV- J+ is
the disjunct that most prepositions will get.
The rank-ordering of these disjuncts is much less
of a surprise.
Attached is a graph. As can be seen its got a much
sharper falloff, and its even less of a straight line ...
Its less Zipfian, less scale-free. I can't explain these
details.
--linas
{kind=link}
Siva Reddy
2009/7/7 Siva Reddy <gvs....@gmail.com>:
The rank-ordering of these disjuncts is much less
of a surprise.
Attached is a graph. As can be seen its got a much
sharper falloff, and its even less of a straight line ...
Its less Zipfian, less scale-free. I can't explain these
details.
This may be because of our decision to cut words other than [a-z.-]* . The rank positions in the new file may not be their actual positions. But I don't know. Just a guess.
--
Siva
Linas Vepstas
Hmm. I doubt it; but just in case .. can you send me data
that does include all words, but skips the idiom (ID*) links?
--linas
Siva Reddy
It should probably be 3, per above.
> I am attaching the updated disjuncts files. In the generalized disjuncts
> file, @A represents { A, A A , A A A, ... N times A} where maximum value of
> N is atleast 2. Is this ok or shall I change it to three.
Ok. Attached is the updated list.
Now coming to feature selection part, I am going to use the log cond probability of disjuncts as features (dimensions).
For the generalized disjuncts we generated, log_cond_prob_scores need to be computed. To compute them, shall I use only the counts of our refined disjunct lists or shall I include the ones which are excluded too (other than [a-z.-]* )
Coming to the number of disjuncts(features) that need to be chosen, when we observe the disjunct frequency files, we observe that more than 3/4 of the disjuncts in the list have very low scores. I think these disjuncts are very word specific. Including them or excluding them will not affect large sets of words. For the time being I will use 4000, 6000, 8000 and 10000 disjuncts as different feature sets and perfom clustering. And then we can analyze the effect of number of disjuncts chosen on the clustering.
Shall I use part of speech category as a dimension too. Many clustering tools allow strings to be features (apart from numerical values). For stop words, I will have a new tag. For unknown words, I will use unknown tag (This tag is generally provided by the clustering tool itself.). I find many words with no tags. I don't know how this is going to effect if pos tag is taken to be a dimension.
--
Siva
Siva Reddy
> This may be because of our decision to cut words other than [a-z.-]* . TheHmm. I doubt it; but just in case .. can you send me data
> rank positions in the new file may not be their actual positions. But I
> don't know. Just a guess.
that does include all words, but skips the idiom (ID*) links?
Attached are the files which includes everything.
disjunct_frequencies_all.txt is generated from only the words whose count >= 3.0
and the remaining file includes everything.
I compressed the latter file because of its size.
It will be good if you can plot both of these.
--
Siva
Linas Vepstas
> Now coming to feature selection part, I am going to use the log cond
> probability of disjuncts as features (dimensions).
Just keep in mind that log_cond_prob = infinity
for any disjuncts that are missing. i.e when p=0 then
-log p = infty and so if you use this as the coordinate,
you have to set the value of missing diusjuncts to either
infy or some large number (e.g. 1000) and NOT to zero!
It might be better to use the entropy S, which is defined
as
S = -p log p
where log_cond_prob = -log p
This is because entropy plays a special role in information
theory; it maximizes the uncertainty of unknown relations.
I should probably take the time to make a stronger
arguments as to why entropy would be best for clustering.
> For the generalized disjuncts we generated, log_cond_prob_scores need to be
> computed. To compute them, shall I use only the counts of our refined
> disjunct lists
Yes. Add the probabilities together.
Since l.c.p. = -log p, first undo the log, then add,
then redo the log.
>or shall I include the ones which are excluded too (other
> than [a-z.-]* )
Not needed, we can leave the total denormalized
without any harm.
> Coming to the number of disjuncts(features) that need to be chosen, when we
> observe the disjunct frequency files, we observe that more than 3/4 of the
> disjuncts in the list have very low scores. I think these disjuncts are very
> word specific.
Well, yes, that's the point!
> Including them or excluding them will not affect large sets
> of words.
The large sets are arguably the most boring sets.
But I guess we'll find out.
> For the time being I will use 4000, 6000, 8000 and 10000 disjuncts
> as different feature sets and perfom clustering. And then we can analyze the
> effect of number of disjuncts chosen on the clustering.
OK.
> Shall I use part of speech category as a dimension too.
No.
The correct way of thinking of a disjunct is as a kind
of highly-detailed part-of-speech. Thus,
MVp- Js+ and MVp- Jp+ both identify a word as a
preposition, .. and more: they distinguish prepositions
that take singular vs. plural objects.
In short, disjuncts already encode part-of-speech
information.
> Many clustering
> tools allow strings to be features (apart from numerical values).
Err ? yes, the disjuncts are the features. Not sure what
you mean here. Each feature is assigned a numerical
value, and that numerical value is the location of the
item on the axis defined by that feature ...
My gut instinct is that we should probably use the
entropy as the coordinate, I'll try to think of a more
rational argument.
> For stop
> words, I will have a new tag.
?? Why are stop words important to think about ??
> For unknown words, I will use unknown tag
?? what's an unknown word?
--linas
Linas Vepstas
> Attached are the files which includes everything.
>
> disjunct_frequencies_all.txt is generated from only the words whose count >=
> 3.0
> and the remaining file includes everything.
>
> I compressed the latter file because of its size.
>
> It will be good if you can plot both of these.
Much better. The first file made no difference at all, that I could
make out. The second flattens out the line very nicely! I like it!
Now, If I could just understand the shape ...
--linas
Siva Reddy
> Now coming to feature selection part, I am going to use the log condJust keep in mind that log_cond_prob = infinity
> probability of disjuncts as features (dimensions).
for any disjuncts that are missing. i.e when p=0 then
-log p = infty and so if you use this as the coordinate,
you have to set the value of missing diusjuncts to either
infy or some large number (e.g. 1000) and NOT to zero!
Oops.. I overlooked this. Thanks for the information.
It might be better to use the entropy S, which is defined
as
S = -p log p
where log_cond_prob = -log p
This is because entropy plays a special role in information
theory; it maximizes the uncertainty of unknown relations.
I should probably take the time to make a stronger
arguments as to why entropy would be best for clustering.
Why not we use the probabilities directly.??
Generally entropy should be calculated by taking the summation of -p log p over all the disjuncts for a given word. Can you please explain what does your above entropy refer to. What does it represent ?
Yes. Add the probabilities together.
> For the generalized disjuncts we generated, log_cond_prob_scores need to be
> computed. To compute them, shall I use only the counts of our refined
> disjunct lists
Since l.c.p. = -log p, first undo the log, then add,
then redo the log.
Or the other way is to calculate cond prob p from the counts. By undoing and then redoing logs we may miss many floating points which is not that desirable.
Not needed, we can leave the total denormalized
>or shall I include the ones which are excluded too (other
> than [a-z.-]* )
without any harm.
Ok.
The large sets are arguably the most boring sets.
> Including them or excluding them will not affect large sets
> of words.
But I guess we'll find out.
> Shall I use part of speech category as a dimension too.
No.
Ok.
The correct way of thinking of a disjunct is as a kind
of highly-detailed part-of-speech. Thus,
MVp- Js+ and MVp- Jp+ both identify a word as a
preposition, .. and more: they distinguish prepositions
that take singular vs. plural objects.
In short, disjuncts already encode part-of-speech
information.
Its clear now. I agree they enocode pos. I tested with some prepositions to convince myself.
Err ? yes, the disjuncts are the features. Not sure what
> Many clustering
> tools allow strings to be features (apart from numerical values).
you mean here. Each feature is assigned a numerical
value, and that numerical value is the location of the
item on the axis defined by that feature ...
I meant this. Generally features(here disjuncts) take numerical values. If we introduce pos tag as a new feature, its value will be a string. Even on such data, current clustering tools work. Since we are planning not to use pos tag, this question is of no use.
My gut instinct is that we should probably use the
entropy as the coordinate, I'll try to think of a more
rational argument.
?? Why are stop words important to think about ??
> For stop
> words, I will have a new tag.
?? what's an unknown word?
> For unknown words, I will use unknown tag
Many words in the database does not have any pos category attached to them. I called these words as unkwown words.
Thanks,
Siva
Linas Vepstas
2009/7/7 Linas Vepstas <linasv...@gmail.com>:
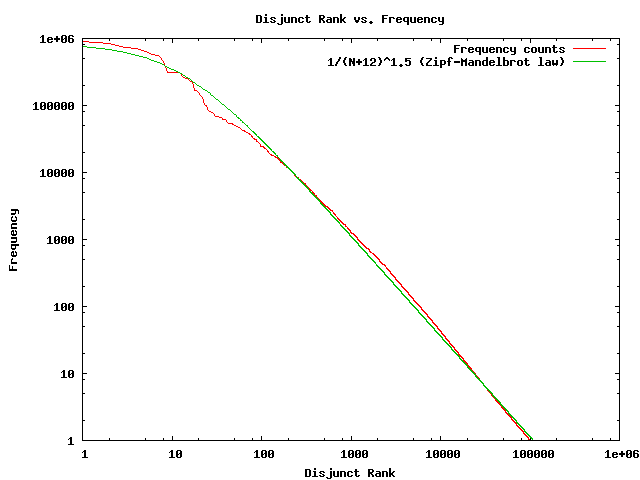{kind=link}
Siva Reddy
I am attaching some statistics of our data that needs to be clustered. I collected the frequency of words having one, two, three .. N disjuncts.
Total number of words (vectors to be clustered) are around
- 40,000 in generalized disjuncts data (i.e with regular expression '@')
- 32000 in normal data i.e without any disjunct generalizations
Thanks,
Siva
Linas Vepstas
> I am attaching some statistics of our data that needs to be clustered. I
> collected the frequency of words having one, two, three .. N disjuncts.
Ah, well, this does present an alternate way of shrinking the dataset
to a size that is managable by existing tools.
For the case of words having only one disjunct, clustering is almost
trivial. Could you create a list of the words and the clusters they're
in?
To get fancy, you would also consider those word with multiple
disjuncts, but for which the probability of one of the disjuncts
exceeding, say, 95%.
> What I am trying to say from the observed statistics is that from our
> feature dimensionality of 10000,
I think it is a mistake to limit the number of feature dimensions.
> only a small fraction of dimensions are
> used for each word.
Yes. As your data shows, most words occur with just
a handful of disjuncts.
Because of this, a simple clusterin algo does suggest itself,
which would just classify words via simple lookup.
--linas
Siva Reddy
I am attaching the words list which have only one disjunct and also the words with one of their disjunct > 0.95. I did not mention the disjunct details in the attachments. I will mail you with clear details tomorrow.
Regards,
Siva
Linas Vepstas
>
> Or perhaps very sparse matrix techniques would work well. A 10K by 10K =
Its actually more like 50K or 100K words.
> 10K*4 =40K for 4 features per
> word
well, maybe a max of ten features per word. But yes, sparse
in this way, which indeed should make it far more tractable.
> Maybe it would help to review what is being
> classified and what it is being applied to. I missed that part of this
> conversation. What is being classified into what classes?
The goal is to improve the link-grammar dictionary in several ways:
-- (automatically) assign words to narrower, "tighter" categories
-- (automatically) loosen parse rules to allow parsing of a broader
range of text
-- (automatically) learn new words
-- progressively iterate on the above three steps.
Clustering addresses the first and the third points, although right now,
it will be "manual" not "automatic". I'll have to do some hacking to
enable the second point.
Linas.
Siva Reddy
Current work status:
Simcluster is hierarchical based clustering. It has three different distance measures which are used in clustering.
Simcluster is able to handle our data if the number of words given for clustering is in the range of 10000. So what I did is removed the words with exacltly one disjunct. These words can be put into clusters to be formed from the remaining words at later stages. Also it is found that majority of the words fall in two or three clusters. If we remove these words too from the word list, then the clustering using simcluster is feasible. Currently I clustered 10000 Random words. The tree view of the resulting clusters is currently being generated by simcluster.
My current next goal is to refine the word list so that clustering is possible using the above procedure. Once clusters are formed, some of the words in each custer are choosen along with the left out words in the previous step and agian clustering is done to determine the clusters to which left out words went.
Papers read by me:
-------------------------
Linas, the paper which you told me to read "Fast Exact Inference with a Factored Model for NLP" was not much useful for us. The paper discusses about the factored models , one category model (phrase) and the other lexical model which are constrained together to get the best parse. Earlier methods did the whole thing at one go. This paper proposes modular structure in contrast to earlier approaches.
I have read some more papers reffered by you on the wiki page
Grammatical Trigrams: A Probabilistic Model of Link Grammar
Unsupervised Learning of Dependency Structure for Language Modeling
But these papers are not much useful to our project. Currently I am reading Yuret 1998 paper.
"Adding a Medical Lexicon to an English Parser" will be useful for us once we form the clusters to add the new grammar rules to the link dictionaries.
Clusters will be ready in two/three days. Our next step is to determine the corresponding disjuncts to the clusters formed.
Regards,
Siva
Linas Vepstas
> Hi Linas,
>
> Current work status:
>
> Simcluster is hierarchical based clustering. It has three different distance
> measures which are used in clustering.
>
> Simcluster is able to handle our data if the number of words given for
> clustering is in the range of 10000. So what I did is removed the words with
> exacltly one disjunct.
Yes, good.
> These words can be put into clusters to be formed
> from the remaining words at later stages. Also it is found that majority of
> the words fall in two or three clusters.
I'd be interested in knowing what these are. Can you send a copy?
They don't have to be fully populated, I'd just like to see what they
look like.
The number and size of these clusters depends on the
cluster radius ...
> My current next goal is to refine the word list so that clustering is
> possible using the above procedure. Once clusters are formed, some of the
> words in each custer are choosen along with the left out words in the
> previous step and agian clustering is done to determine the clusters to
> which left out words went.
Why is this necessary? Just to keep computational times lower?
> Papers read by me:
You should be focusing on getting results at this point, time
is running out.
> Clusters will be ready in two/three days.
I'd like to review partial results, if any, sooner than that.
> Our next step is to determine the
> corresponding disjuncts to the clusters formed.
? I assume that the output of the clustering program includes
some average or centroid position of the cluster, right?
--linas
Siva Reddy
> Simcluster is able to handle our data if the number of words given forYes, good.
> clustering is in the range of 10000. So what I did is removed the words with
> exacltly one disjunct.
Words having only one disjunct are under the heading "Number of Main Disjuncts --> 1" in the attached file.
I discarded any disjunct whose probability given the word is less than 0.05. So even if a word have many disjuncts, only the disjuncts whose prob > 0.05 are considered. This is basically done to remove disjuncts with very less prob for a word.
I'd be interested in knowing what these are. Can you send a copy?
> These words can be put into clusters to be formed
> from the remaining words at later stages. Also it is found that majority of
> the words fall in two or three clusters.
They don't have to be fully populated, I'd just like to see what they
look like.
Attached file contain these words. I collected the words which are having only two and three disjuncts. These words are displayed under "Number of Main Disjuncts --> 2" and "Number of Main Disjuncts --> 3" .
I am assuming that if the number of words having same set of disjuncts are more than certain threshold (say 20), they form a cluster. Is this correct ? (These words may be further clustered into one or more groups)
Not all words in the attached file form clusters (I have included them for more clarity).
The number and size of these clusters depends on the
cluster radius ...
Why is this necessary? Just to keep computational times lower?
> My current next goal is to refine the word list so that clustering is
> possible using the above procedure. Once clusters are formed, some of the
> words in each custer are choosen along with the left out words in the
> previous step and agian clustering is done to determine the clusters to
> which left out words went.
Yes. Also to decrease the size of memory used by clustering. Clustering in steps helps us to perform clustering when the memory is not sufficient to cluster all the words at one go.
Many clustering algorithms are memory intensive. With this approach we will be able to apply them on our data.
> Papers read by me:
You should be focusing on getting results at this point, time
is running out.
I'd like to review partial results, if any, sooner than that.
> Clusters will be ready in two/three days.
? I assume that the output of the clustering program includes
> Our next step is to determine the
> corresponding disjuncts to the clusters formed.
some average or centroid position of the cluster, right?
Yes. We have some numerical values depending on the clustering method used. With simcluster we get average.
Linas Vepstas
2009/7/24 Siva Reddy <gvs....@gmail.com>:
>> > Simcluster is able to handle our data if the number of words given for
>> > clustering is in the range of 10000. So what I did is removed the words
>> > with
>> > exacltly one disjunct.
>>
>> Yes, good.
>
> Words having only one disjunct are under the heading "Number of Main
> Disjuncts --> 1" in the attached file.
I'm confused. The file starts with:
Number of Main Disjuncts --> 1
Main Disjuncts --> '@A+'
Actual Number of disjuncts --> 1
a.m.
abducted.v
abject.a
abnormal.a
abolitionists.n
but a.m. has 25 different disjuncts associated with it, and
abducted.v has 80, etc. for example:
inflected_word | disjunct | log_cond_probability
----------------+----------------------------------+----------------------
abducted.v | Pv- | 1.82876319641111
abducted.v | Pv- MVp+ | 2.57902834757274
abducted.v | A+ | 3.36777993354544
abducted.v | Pv- MVp+ MVp+ | 3.82672257304021
abducted.v | E- A+ | 4.95246679079432
abducted.v | Ss- Os+ | 5.40579043433208
abducted.v | Pv- MVx+ | 5.47621429250552
abducted.v | Pv- MVp+ MVi+ | 5.54739398423103
abducted.v | Pv- MVs+ | 5.81114387203035
abducted.v | Pv- E- | 5.95107333357787
abducted.v | Ss- E- O+ | 5.99225171310795
etc.
so I'm unclear as to what your list is illustrating.
--linas
Siva Reddy
I have created my branch of code. Currently the code is not documented properly. Once documentation is complete I will ask you for a review. You can have a look at https://code.launchpad.net/relex-statistical
Also words which are not included in clustering at initial steps can be accessed here. These words have either one or two disjuncts only. http://bazaar.launchpad.net/%7Esivareddy/relex-statistical/testbranch/revision/780/src/clustering_gsoc/statistics/words_with_one_or_two_disjuncts.txt
I finished clustering. The current output format is in weka .arff format and is generated by Weka. I need to convert the output into understandable word clusters and will mail you the final clusters formed. Current output can be downloaded at http://web.iiit.ac.in/~gvsreddy/clustering_gsoc/ . I used weka and Simcluster for clustering. Simcluster is still running since 2 days. I don't know when it stops. Once it stops, I will mail you the final clusters formed using simcluster.
Thanks,
Siva
2009/7/28 Siva Reddy <gvs....@gmail.com>:
You should create your own branch.
> I am planning to commit my programs in opencog bzr repo. Is this ok ?
It makes more sense to associate that branch either with RelEx
or better yet, LexAt, which is where the other statistical work is.
https://launchpad.net/relex-statistical
Just create a new branch there.
--linas
Siva Reddy
Words are clustered using Simcluster. Attached are the results of clustering in newick format (http://evolution.genetics.washington.edu/phylip/newicktree.html). Simcluster implements hierarchical clustering algorithm. To analyze the output of simcluster, TreeDraw is used to draw the tree structure of the hierarchical clusters. In our case, Treedraw is not able to generate an image (reason might be due to large number of nodes in the tree which makes the size of image very large).
To see the final formed clusters in human readable form, do you have any suggestions for the output format (how should it look like). I am planning to form a seperate file for each cluster. Each cluster (file) will have its parent information (cluster id) and its words.
Current status is that we have clusters of words behaving syntactically similar. These clusters are formed by Weka (K means k=1500) and Simcluster (hierarchical clustering). Next step is to assign disjuncts to these clusters. Do you have any suggestions how to do these. One way is to look what all disjuncts are common to words belonging to the same cluster. In K-means clustering, we have mean of each disjunct for each cluster. This information can be used to propose a formal procedure for choosing disjuncts of the clusters.
Regards,
Siva
Siva Reddy
Attached are the clusters formed with the words having more than 2 disjuncts. Words having one and two disjuncts can be downloaded at http://bazaar.launchpad.net/%7Esivareddy/relex-statistical/testbranch/annotate/head%3A/src/clustering_gsoc/statistics/words_with_one_or_two_disjuncts.txt . These can also be treated as separate clusters.
I have converted both the outputs of Weka and Simcluster to readable formats. Both the outputs are added in relex-statistical/src/clustering_gsoc/statistics
Clusters of Weka are displayed in the descending order of the cardinality of each cluster.
Since Simcluster Clusters are hierarchical in nature, they are displayed with directory structure. Words at each node are also displayed in a file at each directory (node).
I updated my branch at https://code.launchpad.net/~sivareddy/relex-statistical/testbranch . These codes are not yet for review.
To Do: Identify Disjuncts of each cluster. I am on this right now. Do you have any suggestions/feedback ?
Thanks,
Siva
Linas Vepstas
> Hi,
>
> Words are clustered using Simcluster. Attached are the results of clustering
> in newick format
aka a "dendrogram" .. A casual look seems to indicate its
a binary tree .. is that so?
> is not able to generate an
> image (reason might be due to large number of nodes in the tree which makes
> the size of image very large).
Yes, this is a recurring problem; none of the open-source visualization
tools seem to be able to handle large datasets (even when they claim
that they can.) We've had the same experience with when using
various different packages to visualize opencog graphs.
> To see the final formed clusters in human readable form, do you have any
> suggestions for the output format (how should it look like).
Not right now. I'm thinking of creating some simple tools to crawl
over what you've sent me ...
> I am planning
> to form a seperate file for each cluster.
it would be nicer to have everything in one file -- dealing qith 1500
files can be painful.
> Current status is that we have clusters of words behaving syntactically
> similar.
Well, My goal here was to be able to automatically refine the
link-grammar dicts from this data. This remains an important,
unrealized goal ...
> These clusters are formed by Weka (K means k=1500) and Simcluster
> (hierarchical clustering). Next step is to assign disjuncts to these
> clusters. Do you have any suggestions how to do these.
?? Well, presumably weka already "knows" this, its just not printing
it out. By writing some extra code, we could take the newick tree,
and compute centers for the graph nodes.
What is the meaning of the numerical value attached to the data.
The newick page says "distance", implying that this can be used for
graphical layout, but is this indeed the case?
--linas
Linas Vepstas
> To Do: Identify Disjuncts of each cluster.
Yes, this would be interesting.
I wrote some scripts to post-process the files you sent me, and
I notice that the clusters are grouping together words from different
link-grammar classes, while also splitting apart existing classes
I'm curious to know why.
--linas
Siva Reddy
> Words are clustered using Simcluster. Attached are the results of clusteringaka a "dendrogram" ..
> in newick format
A casual look seems to indicate its
a binary tree .. is that so?
Yes. I verified it manually. I could not find in the documentation.
Yes, this is a recurring problem; none of the open-source visualization
> is not able to generate an
> image (reason might be due to large number of nodes in the tree which makes
> the size of image very large).
tools seem to be able to handle large datasets (even when they claim
that they can.) We've had the same experience with when using
various different packages to visualize opencog graphs.
Seems hot discussion is going on this right now. Manually going through the data is painful. An image will help a lot.
Not right now. I'm thinking of creating some simple tools to crawl
> To see the final formed clusters in human readable form, do you have any
> suggestions for the output format (how should it look like).
over what you've sent me ...
it would be nicer to have everything in one file -- dealing qith 1500
> I am planning
> to form a seperate file for each cluster.
files can be painful.
Yes. Initially I created a file for each cluster. Later merged all those files.
Well, My goal here was to be able to automatically refine the
> Current status is that we have clusters of words behaving syntactically
> similar.
link-grammar dicts from this data.
Since we formed the clusters using the link parser (i.e. using link grammar dictionaries), I think the clusters formed may be refinements of the current word classes of link grammar dicts. Currently in the clusters I did not include unknown words (marked by [?]). If we include these words too, we can increase the coverage of link parser tremendously. This way we are refining as well as increasing the coverage of link grammar dictionaries.
There may be side effects by adding new words, disjunct rules to link dictionaries since the current handling of unknown words by link parser may be better than by adding these words in the dictionaries. Do you have any corpus to test which is a gold standard link parsed output (either by manual parsing or by some other method).
This remains an important,
unrealized goal ...
?? Well, presumably weka already "knows" this, its just not printing
> These clusters are formed by Weka (K means k=1500) and Simcluster
> (hierarchical clustering). Next step is to assign disjuncts to these
> clusters. Do you have any suggestions how to do these.
it out. By writing some extra code, we could take the newick tree,
and compute centers for the graph nodes.
For each cluster, I collected its centroid w.r.t each disjunct ((sum of all the scores of the words in the cluster with that disjunct)/(Total number of words) ) . You can download the cluster centroids at http://web.iiit.ac.in/~gvsreddy/clustering_gsoc/weka_data.details.txt (81 MB)
Once I have cluster centroids, how do I say that a cluster can have a particular disjunct by looking at the centroid value. Can we formalize this ?
What is the meaning of the numerical value attached to the data.
The newick page says "distance", implying that this can be used for
graphical layout, but is this indeed the case?
I could not find proper explanation to this. What it might indicate is the strength by which it belongs to a given node. It does indicate distance too.
Regards,
Siva
Siva Reddy
> To Do: Identify Disjuncts of each cluster.Yes, this would be interesting.
I wrote some scripts to post-process the files you sent me,
What does these scripts do. Do they check the current link grammar word groups to the clusters formed.
and
I notice that the clusters are grouping together words from different
link-grammar classes,
If this grouping is correct, it means the clusters can used for extending the link grammar dictionaries.
while also splitting apart existing classes
Nice. This means clusters also represent refinements of existing link grammar word classes.
I'm curious to know why.
We can know this once we assign disjuncts to clusters and compare with LG word classes.
--
Siva
Linas Vepstas
>
>> > To Do: Identify Disjuncts of each cluster.
>>
>> Yes, this would be interesting.
>>
>> I wrote some scripts to post-process the files you sent me,
>
> What does these scripts do. Do they check the current link grammar word
> groups to the clusters formed.
They're very simple, ad-hoc. For example, I notice that your
cluster469 has 24 words, mostly from words.n.2.s but also
has doubts.n, warnings.n which have their own distinct
collection of disjuncts, and also excuses.n which is from
a different grouping.
This suggests the basic mechanism for broadening parse coverage
as explained in the other email.
--linas
Siva Reddy
cluster469 has 24 words, mostly from words.n.2.s but also
has doubts.n, warnings.n which have their own distinct
collection of disjuncts, and also excuses.n which is from
a different grouping.
I tried to map the clusters formed to the current link grammar classes. I extracted all the word classes from the link dictionaries. Lnk grammar word classes are attached.
Each cluster is mapped to a link grammar class. Mappings are also attached. Scores are also assigned to clusters based on the number of overlap of cluster words to link grammar groups.
This suggests the basic mechanism for broadening parse coverage
as explained in the other email.
Regards,
Siva