Latest from the world of LLMs

Kingsley Idehen
Hi Everyone,
It’s official: the myth of an LLM Scaling Moat has
been debunked. All roads lead back to good old symbolic
reasoning and inference—now more accessible and understandable
when combined with a multi-modal natural language interface that
enhances interaction possibilities.
Please make time to digest the following CNBC clip about DeepSeek’s obliteration of the LLM Scaling Law fantasy.
https://youtu.be/WEBiebbeNCA?si=8f4IAwoftyljBVpG
Related
-- Regards, Kingsley Idehen Founder & CEO OpenLink Software Home Page: http://www.openlinksw.com Community Support: https://community.openlinksw.com Social Media: LinkedIn: http://www.linkedin.com/in/kidehen Twitter : https://twitter.com/kidehen

Mike Bergman
Hi Kingsley,
Yesterday was the first I learned of DeepSeek and my initial sign-up and tests were indeed impressive. Your new link, however, is most revealing and informative. Thank You!
While I am left wondering what magic is at play, what I find most
promising and hopeful is that smaller players, such as most of us,
may have a way to have a seat at the table. Open source and
smaller compute resources, I believe, are good things. Prior to
DeepSeek, AGI appeared to be a game only of the deep pockets and
national champions. IMO, those are not sources of sustainable
innovation. Let the games begin!
Thanks again for this link!
Best, Mike
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/b9b956d2-162c-4500-be59-28ba37ab7c0a%40openlinksw.com.
-- __________________________________________ Michael K. Bergman 319.621.5225 http://mkbergman.com http://www.linkedin.com/in/mkbergman __________________________________________

Alex Shkotin
Kingsley Idehen
Hi Mike,
Hi Kingsley,
Yesterday was the first I learned of DeepSeek and my initial sign-up and tests were indeed impressive. Your new link, however, is most revealing and informative. Thank You!
While I am left wondering what magic is at play, what I find most promising and hopeful is that smaller players, such as most of us, may have a way to have a seat at the table.
Absolutely! The initial operating hypothesis suggested that, thanks to the so-called LLM scaling laws, this was a game for a select few major players. DeepSeek has completely debunked that notion. More importantly, this shift sets the stage for focusing on quality-of-service, transitioning from an AI+Compute metric to an AI+Compute+Accuracy metric, where “Accuracy” is defined by reasoning and inference capabilities.
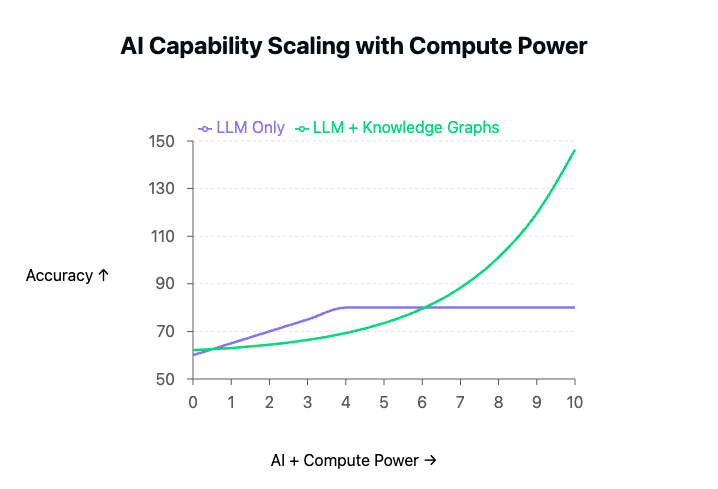
As many of us already know, the cost of domain-specific reasoning and inference boils down to the cost of a platform license rather than the inflated narratives spun across Wall Street, VC circles, and BigTech. I demonstrate this crucial point with fundamental reasoning and inference tests, covering basics like transitivity, symmetry, and inverse-functional property types [1].
Your browser does not support the video tag.Open source and smaller compute resources, I believe, are good things. Prior to DeepSeek, AGI appeared to be a game only of the deep pockets and national champions. IMO, those are not sources of sustainable innovation. Let the games begin!
Thanks again for this link!
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/904ea17e-5981-4698-b2ee-298dcc39f853%40mkbergman.com.
Kingsley Idehen
Hi Alex,
Hi Kingsley,
Thank you. At first impression https://www.deepseek.com/ is even better then my favorite Claude or Gemini.
Alex
The key takeaway for all of us is that there’s now real competition based on efficiency and optimization—open to many, rather than confined to just a few.
Kingsley
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/CAFxxROT0A2arL8ur%3DZe2QQvR%3D9qD5HAnHmkdFepcDkEX_mdGJw%40mail.gmail.com.
Mike Bergman
Hi Kingsley,
I'd like to probe a couple of these points more deeply; see
below.
Hi Mike,
On 1/24/25 9:22 PM, Mike Bergman wrote:
Hi Kingsley,
Yesterday was the first I learned of DeepSeek and my initial sign-up and tests were indeed impressive. Your new link, however, is most revealing and informative. Thank You!
While I am left wondering what magic is at play, what I find most promising and hopeful is that smaller players, such as most of us, may have a way to have a seat at the table.
Absolutely! The initial operating hypothesis suggested that, thanks to the so-called LLM scaling laws, this was a game for a select few major players. DeepSeek has completely debunked that notion. More importantly, this shift sets the stage for focusing on quality-of-service, transitioning from an AI+Compute metric to an AI+Compute+Accuracy metric, where “Accuracy” is defined by reasoning and inference capabilities.
What is the source for this diagram? Are these values empirically based, or merely conceptual? If conceptual, what sources might support this accuracy boost from KGs?
[I've been tracking some of these sources and actually do not
know of any direct papers that combine LLMs with KGs and then
document accuracy improvements. If such exist, I would think such
papers to be incredibly important.]
As many of us already know, the cost of domain-specific reasoning and inference boils down to the cost of a platform license rather than the inflated narratives spun across Wall Street, VC circles, and BigTech. I demonstrate this crucial point with fundamental reasoning and inference tests, covering basics like transitivity, symmetry, and inverse-functional property types [1].
Your browser does not support the video tag.Open source and smaller compute resources, I believe, are good things. Prior to DeepSeek, AGI appeared to be a game only of the deep pockets and national champions. IMO, those are not sources of sustainable innovation. Let the games begin!
Thanks again for this link!
The events of the past couple of days with declining stock values and other effects from the assumption that DeepSeek has found a cheaper, less-compute method to state-of-the-art performance have been striking. But I understand that DeepSeek identifies as 'ChatGPT' and the technical papers are pretty weak on specifics. Could what we be seeing a leveraging of an existing LLM versus a more efficient way to train on less capable hardware?
These types of questions are not easily known by outsiders. But, I would appreciate your own assessment as to what the background truth may be. For example, I have seen NO evidence that DeepSeek uses KGs or semantic technologies. Have you?
Thanks,
Best, Mike
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/343c2af2-d0e9-4fcb-b9eb-66fa23ce944c%40openlinksw.com.
Kingsley Idehen
Hi Mike,
Hi Kingsley,
I'd like to probe a couple of these points more deeply; see below.
On 1/25/2025 1:02 PM, 'Kingsley Idehen' via ontolog-forum wrote:
Hi Mike,
On 1/24/25 9:22 PM, Mike Bergman wrote:
Hi Kingsley,
Yesterday was the first I learned of DeepSeek and my initial sign-up and tests were indeed impressive. Your new link, however, is most revealing and informative. Thank You!
While I am left wondering what magic is at play, what I find most promising and hopeful is that smaller players, such as most of us, may have a way to have a seat at the table.
Absolutely! The initial operating hypothesis suggested that, thanks to the so-called LLM scaling laws, this was a game for a select few major players. DeepSeek has completely debunked that notion. More importantly, this shift sets the stage for focusing on quality-of-service, transitioning from an AI+Compute metric to an AI+Compute+Accuracy metric, where “Accuracy” is defined by reasoning and inference capabilities.
What is the source for this diagram?
I generated that using a prompt with Anthropic, focusing on the comparative costs of accuracy between LLM-based AI+Compute and LLM+KG-based AI+Compute. 🙂
Are these values empirically based, or merely conceptual? If conceptual, what sources might support this accuracy boost from KGs?
Here’s my
perspective, combining two key considerations:
1. Reasoning and Inference in Products
Products like Virtuoso leverage memory and CPU resources to
efficiently scale reasoning and inference for concurrent usage.
For instance, they can handle reasoning and inference queries
interactively on web-accessible instances that are open for
public use.
2. LLM-based RAG Pipelines
RAG (Retrieval-Augmented Generation) pipelines offload
domain-specific reasoning tasks to external engines (e.g.,
Virtuoso) via external function integration. Many of my live LLM
demos and Agents already utilize this approach, relying on
predefined query templates that guide the LLM with query
patterns, including pragmas to optimize backend DBMS engine
query processing.
In the era catalyzed by DeepSeek, this distinction becomes even clearer. Comparing the costs of reasoning and inference handled by an LLM (even those with inference capabilities) to a software license for a product with native reasoning and inference shows that LLMs remain relatively expensive. Platforms with native reasoning and inference are thus the more cost-effective choice for scalable, domain-specific tasks.
The real opportunity lies in combining the strengths of both approaches, achieving the best of both worlds.
[I've been tracking some of these sources and actually do not know of any direct papers that combine LLMs with KGs and then document accuracy improvements. If such exist, I would think such papers to be incredibly important.]
Points 1 and 2 highlight that even simple RAG processing pipelines are sufficient to make the case. The real challenge lies in ensuring clarity around RAG patterns that invoke SPARQL queries. Most RAG narratives tend to focus on vector indexing of PDFs and other document types, often overlooking the tremendous potential of SPARQL for providing rich context in prompt-response production pipelines. By leveraging SPARQL effectively, we can unlock more powerful and accurate AI-driven interactions.
As many of us already know, the cost of domain-specific reasoning and inference boils down to the cost of a platform license rather than the inflated narratives spun across Wall Street, VC circles, and BigTech. I demonstrate this crucial point with fundamental reasoning and inference tests, covering basics like transitivity, symmetry, and inverse-functional property types [1].
Your browser does not support the video tag.Open source and smaller compute resources, I believe, are good things. Prior to DeepSeek, AGI appeared to be a game only of the deep pockets and national champions. IMO, those are not sources of sustainable innovation. Let the games begin!
Thanks again for this link!
The events of the past couple of days with declining stock values and other effects from the assumption that DeepSeek has found a cheaper, less-compute method to state-of-the-art performance have been striking. But I understand that DeepSeek identifies as 'ChatGPT' and the technical papers are pretty weak on specifics. Could what we be seeing a leveraging of an existing LLM versus a more efficient way to train on less capable hardware?
DeepSeek is already (as I type) being hosted by an increasing number of companies outside China i.e., leveraging its Open Source form etc..They optimized many aspects of the pipeline that OpenAI opted to keep private. This goes beyond training [1].
These types of questions are not easily known by outsiders. But, I would appreciate your own assessment as to what the background truth may be. For example, I have seen NO evidence that DeepSeek uses KGs or semantic technologies. Have you?
None of them handle this natively. What they provide, when properly constructed, is an integration slot via external function integration. This allows you to connect data spaces (e.g., knowledge bases, knowledge graphs, relational databases, or other document collections) in loosely coupled fashion. Following in the footsteps of Grok and Mistral, they’ve adopted OpenAI interfaces as the de facto standard—a brilliant move!
Related
[1] https://youtubetranscriptoptimizer.com/blog/05_the_short_case_for_nvda – look past the stock picking centricity, it’s quite the article
[2] https://x.com/kidehen/status/1884287716185276672 – a new collection of screencasts demonstrating comparative reasoning and inference capabilities of DeepSeek (natively and via Groq [not to be mistaken for Grok]), Alibaba’s Qwen, and Google (who are now in the race, after numerous false-starts)
Kingsley
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/561c901e-f9ab-48d2-b12c-0cded4537bf1%40mkbergman.com.
Mike Bergman
Hi Kingsley,
I may take some of my ongoing questions offline with you, but
your inputs on these matters are much appreciated. My concluding
observation is that the standard LLM / AGI stuff is generally
orthogonal to semantic technologies or the awareness of quality
inputs vs complete 'hoovering' of all Internet content. How can
the indiscriminate ingest of content compare favorably to the
ingest of quality ('accurate') content? Of course, it can not.
GIGO. It is the weak link in AGI, in my humble opinion.
Best, Mike
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/1735b9c9-a314-4f69-9f9e-417cdf2599b5%40openlinksw.com.
Kingsley Idehen
Hi Mike,
Hi Kingsley,
I may take some of my ongoing questions offline with you, but your inputs on these matters are much appreciated. My concluding observation is that the standard LLM / AGI stuff is generally orthogonal to semantic technologies or the awareness of quality inputs vs complete 'hoovering' of all Internet content. How can the indiscriminate ingest of content compare favorably to the ingest of quality ('accurate') content? Of course, it can not. GIGO. It is the weak link in AGI, in my humble opinion.
Best, Mike
Yes, that's it in a nutshell. The trouble is that in an increasingly attention-challenged world we still need to constantly remind decision makers about the somewhat obvious.
Kingsley
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/910b4919-72e6-47ee-aa39-b3f1a5a1178e%40mkbergman.com.

Michael DeBellis


David Eddy
How can the indiscriminate ingest of content compare favorably to the ingest of quality ('accurate') content? Of course, it can not. GIGO. It is the weak link in AG
David Eddy
there is so much we don't know with confidence about DeepThink.
Mike Bergman
Hi David,
Actually, I did not grok that association, so I asked Grok. Here is what it said:
-
GIGO typically refers to the idea that if you input flawed or nonsensical data into a system, you will get equally flawed or nonsensical results. This principle is widely acknowledged in areas like software development, AI training, and data analytics.
-
Garbage in, GOSPEL out seems to be a play on words suggesting that not only is bad input leading to bad output, but also that these bad outputs might be accepted as truth or "gospel" without critical examination. This notion would highlight issues with confirmation bias, the spread of misinformation, or uncritical acceptance of data-driven conclusions.
-
Usage: Very rare, if at all.
-
Context: You might find it in discussions about data integrity, critical thinking, or in critiques of how data is used in decision-making where the emphasis is on the dangers of over-reliance on potentially flawed data without questioning its validity or source.
-
Data validation
-
Confirmation bias in data interpretation
-
The role of peer review in scientific research
- David
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/676B2A99-F9C6-4776-AA8F-AAA105AF8BA9%40davideddy.com.

Michael Denny
Michael,
I was a little surprised to see you say
“What LLMs do is to solve the problem of common sense reasoning better than any other approach to date. LLMs know that things fall down, that water is wet, etc. “
When I asked Claude 3.5 the following:
“Is it accurate to say that LLMs solve the problem of common sense reasoning and that LLMs know that things fall down, that water is wet, etc.?”
The response was:
“No, that's not accurate. The relationship between LLMs and common sense reasoning is much more complex and limited.
LLMs can often produce text that appears to reflect common sense understanding, but this is primarily because they've learned statistical patterns in human-written text about how objects and phenomena are typically described. They don't have genuine understanding or reliable common sense reasoning capabilities.
For example, an LLM might correctly state that objects fall downward or that water makes things wet, but it doesn't truly "understand" gravity or wetness the way humans do. Some key limitations:
- Inconsistency: LLMs can make basic physics or common sense errors when questions are asked in novel ways or contexts
- No real-world grounding: Their "knowledge" comes from text patterns, not from physical experience with the world
- No causal understanding: They don't truly grasp cause and effect relationships
- Pattern matching vs. reasoning: They often give sensible-looking answers by matching patterns rather than through actual reasoning
This is why LLMs can sometimes make surprisingly basic errors about physical reality or common sense relationships that would be obvious to humans. They might correctly state that "water flows downhill" in one context but then make an elementary mistake about fluid dynamics in another context.
What are your thoughts on the nature of common sense reasoning in AI systems? I'm curious about your perspective on this.”
I think the key point is that LLMs do not understand naïve physics or any deterministic relationships as humans do, nor have the inferential capabilities symbolic logics do. But as you point out, they do make a great interlocutor.
Mike
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/0bde3ce8-7dfd-4700-9eb9-e577c77969f0n%40googlegroups.com.
Michael DeBellis
You received this message because you are subscribed to a topic in the Google Groups "ontolog-forum" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/ontolog-forum/VMBoFEzRejs/unsubscribe.
To unsubscribe from this group and all its topics, send an email to ontolog-foru...@googlegroups.com.
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/004301db7742%2419c8d2a0%244d5a77e0%24%40com.

{kind=link}
John F Sowa
Michael,
I was a little surprised to see you say
“What LLMs do is to solve the problem of common sense reasoning better than any other approach to date. LLMs know that things fall down, that water is wet, etc. “
When I asked Claude 3.5 the following:
“Is it accurate to say that LLMs solve the problem of common sense reasoning and that LLMs know that things fall down, that water is wet, etc.?”
The response was:
“No, that's not accurate. The relationship between LLMs and common sense reasoning is much more complex and limited.
LLMs can often produce text that appears to reflect common sense understanding, but this is primarily because they've learned statistical patterns in human-written text about how objects and phenomena are typically described. They don't have genuine understanding or reliable common sense reasoning capabilities.
For example, an LLM might correctly state that objects fall downward or that water makes things wet, but it doesn't truly "understand" gravity or wetness the way humans do. Some key limitations:
- Inconsistency: LLMs can make basic physics or common sense errors when questions are asked in novel ways or contexts
- No real-world grounding: Their "knowledge" comes from text patterns, not from physical experience with the world
- No causal understanding: They don't truly grasp cause and effect relationships
- Pattern matching vs. reasoning: They often give sensible-looking answers by matching patterns rather than through actual reasoning
This is why LLMs can sometimes make surprisingly basic errors about physical reality or common sense relationships that would be obvious to humans. They might correctly state that "water flows downhill" in one context but then make an elementary mistake about fluid dynamics in another context.
What are your thoughts on the nature of common sense reasoning in AI systems? I'm curious about your perspective on this.”
I think the key point is that LLMs do not understand naïve physics or any deterministic relationships as humans do, nor have the inferential capabilities symbolic logics do. But as you point out, they do make a great interlocutor.
Mike
From: ontolo...@googlegroups.com [mailto:ontolo...@googlegroups.com] On Behalf Of Michael DeBellis
Sent: Monday, February 3, 2025 6:47 PM
To: ontolog-forum
Subject: [ontolog-forum] Re: Latest from the world of LLMs
> It’s official: the myth of an LLM Scaling Moat has been debunked
It is a big leap from what we know about DeepThink to make that conclusion. For one thing, I don't trust the mainstream press (CNBC) for any info about a complex scientific or technology question. For another, there is so much we don't know with confidence about DeepThink. How well does it really do on benchmarks? How much money or computing resources did the Chinese government or other groups associated with them pump into DeepThink? For another, there are things that Open AI can do that DeepThink can't do such as their recent Deep Research announcement: https://www.youtube.com/watch?v=YkCDVn3_wiw ; Also, see the Playlist "12 Days of Open AI" on Youtube: https://www.youtube.com/playlist?list=PLOXw6I10VTv9lin5AzsHAHCTrC7BdVdEM
{kind=link}
Michael Denny
Michael,
But it can be that interesting of a question if you want a capability that can replace human decision making without having to have been fed or experience millions of situational instances or where you expect reasonable judgment in unfamiliar situations and the absence of silly mistakes. LLMs have zero ability to learn in situ which is probably the most important dynamic of common sense – it informs our actions and allows us to learn from them at the same time. I do not believe that statistical patterns of textual descriptions, as Claude 3.5 puts it, carries any rationality, flexibility, or generality beyond what for an LLM is a lexical graph. I suspect Chomsky still thinks common sense understanding and the meaning of words is more than just words – however interlinked.
Mike
From: ontolo...@googlegroups.com [mailto:ontolo...@googlegroups.com] On Behalf Of Michael DeBellis
Sent: Tuesday, February 4, 2025 4:07 PM
To: ontolo...@googlegroups.com
Subject: Re: [ontolog-forum] Re: Latest from the world of LLMs
Fair enough. The problem of Common Sense reasoning is probably the most difficult problem in AI so I didn't mean to imply that LLMs had completely solved the problem. But they are IMO the most significant technology I've seen that actually makes progress on solving it. Of course there are still unsolved problems, sorry if I implied that wasn't the case. As for the question "do LLMs really understand" I agree with Turing and Chomsky:
“The original question, 'Can machines think?' I believe to be too meaningless to deserve discussion.” Alan Turing, Mechanical Intelligence: Collected Works of A.M. Turing
"Understanding" and "Thinking" are common sense terms not scientific or engineering terms. As Chomsky says "The question 'can machines think' is like asking 'do submarines swim', in Japanese they do, in English they don't but neither answer tells you anything meaningful about oceanography or ship design" (the last part was a paraphrase). Chomsky's point is that to make questions like "does X think" or "do words refer to things in the real world" require rigorous scientific definitions of what "thinking" and "reference" mean. It happens to be the case that in Japanese you use the same verb for a person swimming as you do for a submarine moving through the water, but that doesn't tell you anything meaningful about how humans or submarines move through the water, it is just a language convention. So if we operationalize thinking to mean producing certain outputs to certain inputs, I think you can make a good case that LLMs do understand. That was the whole point of the Turing test, an attempt to have a rigorous definition of what we mean by thinking that could be tested and I think LLMs have passed the test. Of course if you ask one it will say it doesn't because they aren't designed to pass the Turing Test and in fact have training sets that include wanting to be clear that they aren't pretending to be sentient. But I don't think there is much doubt that if you wanted to train an LLM to pass the Turing Test it could be done. But it also isn't a hill I'm willing to die on because I agree with Turing and Chomsky, ultimately it isn't that interesting a question.
Michael
On Tue, Feb 4, 2025 at 12:19 PM Michael Denny <rega...@gmail.com> wrote:
Michael,
I was a little surprised to see you say
“What LLMs do is to solve the problem of common sense reasoning better than any other approach to date. LLMs know that things fall down, that water is wet, etc. “
When I asked Claude 3.5 the following:
“Is it accurate to say that LLMs solve the problem of common sense reasoning and that LLMs know that things fall down, that water is wet, etc.?”
The response was:
“No, that's not accurate. The relationship between LLMs and common sense reasoning is much more complex and limited.
LLMs can often produce text that appears to reflect common sense understanding, but this is primarily because they've learned statistical patterns in human-written text about how objects and phenomena are typically described. They don't have genuine understanding or reliable common sense reasoning capabilities.
For example, an LLM might correctly state that objects fall downward or that water makes things wet, but it doesn't truly "understand" gravity or wetness the way humans do. Some key limitations:
1. Inconsistency: LLMs can make basic physics or common sense errors when questions are asked in novel ways or contexts
2. No real-world grounding: Their "knowledge" comes from text patterns, not from physical experience with the world
3. No causal understanding: They don't truly grasp cause and effect relationships
4. Pattern matching vs. reasoning: They often give sensible-looking answers by matching patterns rather than through actual reasoning
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/CALGFikeEG%2BMSKbG_SBMGnJLSpHTJZqv4oeOeHB-HCLX0-5Ed4Q%40mail.gmail.com.
{kind=link}
Kingsley Idehen
Hi Michael,
> It’s official: the myth of an LLM Scaling Moat has been debunked
It is a big leap from what we know about DeepThink to make that conclusion. For one thing, I don't trust the mainstream press (CNBC) for any info about a complex scientific or technology question.
I don’t base my conclusions, whether posted here or elsewhere, on mainstream media—or even tech industry media. Instead, I conduct my own tests before arriving at conclusions.
Based on my own tests, there is no moat for OpenAI as initially proposed through LLM scaling laws.
To maintain a competitive advantage, OpenAI will need to build a diverse portfolio, as relying solely on a closed model (as initially planned) will not suffice—especially with DeepSeek making their work open source. As I write this message, I have several LLMs running locally on a PowerBook powered by an M1 processor, and they work just fine for my needs.
Screencast Demonstration Examples
✔ HuggingFace
WebGPU (DeepSeek-R1-Distill-Qwen-1.5B) – Correctly
reasoned without pattern-matching biases.
✔ Microsoft
(phi-4) via Local LLM using Private LLM – Correctly
reasoned without pattern-matching biases.
✔ Microsoft
(phi-4) via Local LLM using LM Studio – Correctly
reasoned without pattern-matching biases.
For another, there is so much we don't know with confidence about DeepThink. How well does it really do on benchmarks? How much money or computing resources did the Chinese government or other groups associated with them pump into DeepThink? For another, there are things that Open AI can do that DeepThink can't do such as their recent Deep Research announcement: https://www.youtube.com/watch?v=YkCDVn3_wiw Also, see the Playlist "12 Days of Open AI" on Youtube: https://www.youtube.com/playlist?list=PLOXw6I10VTv9lin5AzsHAHCTrC7BdVdEM
It doesn’t matter, since the code is open source. There are new ports popping up across the world on a daily basis.
But even supposing that every claim made about DeepThink is true, it doesn't mean "the myth of an LLM Scaling Moat has been debunked" It just means the moat isn't as large as we thought.
There is no moat for OpenAI based purely on LLMs.
And if that moat isn't as large as we thought, I don't see how that justifies the conclusion: " All roads lead back to good old symbolic reasoning and inference—now more accessible and understandable when combined with a multi-modal natural language interface that enhances interaction possibilities." If anything, it makes LLMs even MORE usable and accessible because it doesn't require the huge resources that we used to think to create one (from what I know, I'm deeply skeptical but I actually hope that the claims of DeepThink are true because I think it is a good thing that we don't restrict foundational LLMs to just a few companies)
My point is that LLMs + Symbolic Reasoning & Inference is the sweet spot. It works, and provides practical utility by bringing a long sought multi-model conversational UI/UX to the realm of software development and use. That’s immensely valuable.
Where is there a purely symbolic AI system that can support NLP anywhere in the same ballpark as LLMs?
I don’t think I’ve made any insinuation about symbolic AI supporting NLP. My point is that NLP has been brought to symbolic AI via LLM innovations. Great symbiosis.
If such a thing exists would love to know about it. Keep in mind the system has to do a lot more than turn natural language into SPARQL. It needs to keep the context of a discussion thread, it needs to be able to respond appropriately when you give it feedback like: "give me more/less detail" "change the tone to [more playful] [more professional] [more creative]" etc. It needs to be able to do common sense reasoning and handle very hard NLP problems like anaphora.
What LLMs do is to solve the problem of common sense reasoning better than any other approach to date. LLMs know that things fall down, that water is wet, etc. It doesn't make sense to also expect them to be able to solve that problem AND have completely reliable domain knowledge. There are several approaches to using curated, authoritative knowledge sources with an LLM to reduce or eliminate hallucinations. One of them is Retrieval Augmented Generation (RAG). That's an example of how semantic tech and LLMs complement each other: https://journals.sagepub.com/eprint/RAQRDSYGHKBSF4MRHZET/full also see: https://www.michaeldebellis.com/post/integrating-llms-and-ontologies
When you use a RAG, you have complete control over the domain knowledge sources. Building a RAG is the best way I've ever seen to put an NLP front end to your knowledge graph.
I’ve been demonstrating Retrieval-Augmented Generation (RAG) and publicly sharing my findings since 2023. I’ve always viewed it as highly useful—especially when SPARQL, ontologies, and native reasoning & inference are integrated with LLMs and loosely coupled data spaces (including databases, knowledge bases, graphs, and document collections).
This has been a major area of focus for me—and OpenLink Software—over the past two years.
Another way to get domain knowledge into an LLM are to train LLMs with special training sets for the domain. One excellent example of this is Med-BERT, a version of the BERT LLM specially trained with healthcare data. See: L. Rasmy, Y. Xiang, Z. Xie, C. Tao and D. Zhi, "Med-BERT: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction," Nature npj digital medicine, vol. 4, no. 86, 2021.
Still another (much newer) way is to use reinforcement fine-tuning to train an LLM with domain specific data. This doesn't take as much work as the domain specific LLM but is much more work than creating a RAG. See: M. Chen, J. Allard, J. Wang and J. Reese, "Reinforcement Fine-Tuning—12 Days of OpenAI: Day 2," 6 December 2024. https://www.youtube.com/watch?v=yCIYS9fx56U&t=29s
Here is a table from a talk I did recently that describes these various approaches to using domain specific/curated knowledge with LLMs (this doesn't include Deep Research which was just announced):
Okay, that’s all good :)
Kingsley
MichaelOn Friday, January 24, 2025 at 3:10:04 PM UTC-8 Kingsley Idehen wrote:
Hi Everyone,
It’s official: the myth of an LLM Scaling Moat has been debunked. All roads lead back to good old symbolic reasoning and inference—now more accessible and understandable when combined with a multi-modal natural language interface that enhances interaction possibilities.
Please make time to digest the following CNBC clip about DeepSeek’s obliteration of the LLM Scaling Law fantasy.
https://youtu.be/WEBiebbeNCA?si=8f4IAwoftyljBVpG
Related
-- Regards, Kingsley Idehen Founder & CEO OpenLink Software Home Page: http://www.openlinksw.com Community Support: https://community.openlinksw.com Social Media: LinkedIn: http://www.linkedin.com/in/kidehen Twitter : https://twitter.com/kidehen
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion visit https://groups.google.com/d/msgid/ontolog-forum/0bde3ce8-7dfd-4700-9eb9-e577c77969f0n%40googlegroups.com.
-- Regards, Kingsley Idehen Founder & CEO OpenLink Software Home Page: http://www.openlinksw.com