FYI(art):Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications

alex.shkotin

John F Sowa

Alex Shkotin
John,
Please! And shortly.
If I want a very reliable LLM, I have to train it myself.
JFS: "That article is interesting. But without an independent method of testing and verification, Figure 4 is DIAMETRICALLY OPPOSED to the methods we have been discussing and recommending in Ontolog Forum for the past 20 or more years."
But this green box is all about your point.
One interesting point from one talk on the Internet is that Huge Language Models (from ChatGPT to now) use ALL World Wide Available Knowledge we have and it is not enough to make it good. But we do not have more for them🙂
Alex
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info/
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ontolog-forum/7b626705b52045849dd1bcf0c40b6a7f%40bestweb.net.
Alex Shkotin
John and All,
I began but not finished yet one report [1] of LLM ability to verbalize formal language, in this case OWL2.
The bad places have yellow and red colors.
And here [2] is an example of our dialog.
But the summary for me is clear: we can't trust LLM even for "translations from one language (natural or artificial) to another"
It is mostly correct but sometimes unexpectedly wrong.⚽
Id est even in this case we need "Revision" before to give LLM output to decision making.
Alex
[1] The modest charm of Claude 3 Sonnet(-:PUBLIC:-)
[2] DATA
OWL2P:every childless person is a person for which there does not exist anybody who has the first person as parent.
OWL2:SubClassOf(
:ChildlessPerson
ObjectIntersectionOf(
:Person
ObjectComplementOf(
ObjectSomeValuesFrom(
ObjectInverseOf( :hasParent )
owl:Thing ) ) ) )
C3S:Subclass Axiom with Complex Class Expression:
- The ChildlessPerson class is a subclass of the intersection between:
1) The Person class
2) The complement of the class of individuals that have at least one value for the inverse of the hasParent property.
(An individual is an instance of ChildlessPerson if it is a Person and does not have any parents)
AS:paraphrase is perfect, but usual natural language is wrong: it describes a parentless person.Alex,
--
John F Sowa
Sent: 6/7/24 3:53 AM
John F Sowa
Alex Shkotin
John,
For me on this fragment of Fig. 4
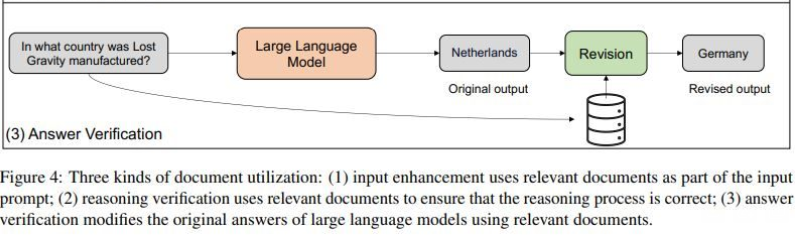
"Revision" is a final process. And it is very crucial as it changes the wrong output of LLM (Netherlands) to correct one (Germany).
What kind of knowledge and methods and in which form we use is an important question not only for ontologists but for all scientists and engineers.
Beginning from DB and up to KG and Formal ontologies we duplicate the same knowledge from 10 to 1000 times around the World.
One funny thing about Huge Language Models is that these are whole knowledge in one place concentrators!
By the way the same situation we have in theorem proving: there may be 10 tools like Coq, Isabelle, HOL4 keeping mostly math theories formalized.
I wonder what we have nowadays formalized in the Wolfram Language as a whole.
But to keep theoretical knowledge properly we need one framework for every particular science and technology.
This is huge and subtle work for science and technology experts. In some form this work is done by formal ontologists.
But today formal ontologies like GENO, GO etc. are a special kind of artifact.
We need a framework as a kind of united knowledge maintenance for all around the world.
One science or technology, one place to keep verified knowledge.
My tiny thing was to show a possible framework for the simplest but powerful theory of undirected graphs [1] and how to apply this theory to solve the simplest tasks on the simplest structure [2].
Theoretical knowledge is the treasure. Let's concentrate this knowledge before we formalize it.
It is clear that we can fully formalize Geometry following Hilbert axiomatic theory of Mechanics following Lagrange approach.
What about the frameworks of these theories?
The important feature of the framework is that we keep the same unit of knowledge in different languages natural and formal. Like this
And it is possible to add a line here for CL, Coq, Isabelle etc. But I am not sure about the DL for Count.
Advantages of formal definitions we discussed at our 2021 Summit [3].
Alex
[1] https://www.researchgate.net/publication/374265191_Theory_framework_-_knowledge_hub_message_1
[3] https://www.researchgate.net/publication/349164216_Advantages_of_Formal_Definitions
Alex,No, that third method is NOT what I was saying.ALTHOUGH their third method (below) may use precise methods, which could include ontology and databases as input, their FINAL process uses LLM-based methods to combine the information. (See Figure 4 below, which I copied from their publication.)When absolute precision is required, the final reasoning process MUST be absolutely precise. That means precise methods of logic, mathematics, and computer science must be the final step. Probabilistic methods CANNOT guarantee precision.Our Permion.ai company does use LLM-based methods for many purposes. But when absolute precision is necessary, we use mathematics and mathematical logic (i.e. FOL, Common Logic, and metalanguage extensions).Wolfram also uses LLMs for communication with humans in English, but ALL computation is done by mathematical methods, which include mathematical (formal) logic. Kingsley has also added LLM methods for communication in English. But his system uses precise methods of logic and computer science for precise computation when precision is essential.For examples of precise reasoning by our old VivoMind company (prior to 2010), see https://jfsowa.com/talks/cogmem.pdf . Please look at the examples in the final section of those slides. The results computed by those systems (from 2000 to 2010) were far more precise and reliable than anything computed by LLMs today.I am not denying that systems based on LLMs may produce reliable results. But to do so, they must use formal methods of mathematics, logic, and computer science at the final stage of reasoning, evaluation, and testing.JohnFrom: "Alex Shkotin" <alex.s...@gmail.com>
Sent: 6/7/24 3:53 AMJohn,
Please! And shortly.
If I want a very reliable LLM, I have to train it myself.
JFS: "That article is interesting. But without an independent method of testing and verification, Figure 4 is DIAMETRICALLY OPPOSED to the methods we have been discussing and recommending in Ontolog Forum for the past 20 or more years."
But this green box is all about your point.
One interesting point from one talk on the Internet is that Huge Language Models (from ChatGPT to now) use ALL World Wide Available Knowledge we have and it is not enough to make it good. But we do not have more for them🙂
Alex
чт, 6 июн. 2024 г. в 22:13, John F Sowa <so...@bestweb.net>:Alex,Thanks for the reference to that article. But the trends it discusses (from Dec 2023) are based on the assumption that all reasoning is performed by LLM-based methods. It assumes that any additional knowledge is somehow integrated with or added to data stored in LLMs. Figure 4 from that article illustrates the methods the authors discuss:Note that the results they produce come from LLMs that have been modified by adding something new. That article is interesting. But without an independent method of testing and verification, Figure 4 is DIAMETRICALLY OPPOSED to the methods we have been discussing and recommending in Ontolog Forum for the past 20 or more years.

--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info/
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ontolog-forum/f018f1882f814efd88fa9cbfe104197b%40bestweb.net.
Alex Shkotin
--
All contributions to this forum are covered by an open-source license.
For information about the wiki, the license, and how to subscribe or
unsubscribe to the forum, see http://ontologforum.org/info/
---
You received this message because you are subscribed to the Google Groups "ontolog-forum" group.
To unsubscribe from this group and stop receiving emails from it, send an email to ontolog-foru...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/ontolog-forum/8b7de9fcf406484da8fc44b416bab0ea%40bestweb.net.
John F Sowa
Another round with ChatGPT
ChatGPT is utterly unreliable when it comes to reproducing even very simple mathematical proofs. It is like a weak C-grade student, producing scripts that look like proofs but mostly are garbled or question-begging at crucial points. Or at least, that’s been my experience when asking for (very elementary) category-theoretic proofs. Not at all surprising, given what we know about its capabilities or lack of them.

So I take a look. Every single reference is a total fantasy. None of the chapters/sections have those titles or are about anything even in the right vicinity. They are complete fabrications.
I complained to ChatGPT that it was wrong about Mac Lane and Moerdijk. It replied “I apologize for the confusion earlier. Here are more accurate references to works that cover the concept of complements and pseudo-complements in a topos, along with their proofs.” And then it served up a complete new set of fantasies, including quite different suggestions for the other two books.