some doubts using the platform

Luís Martins
Hi,
I have been exploring this tool to analyse my proteomics data and would like to ask a few questions to understand how some calculations are performed and how some data is presented to better interpret my data.
1 - In a contrast where both the control and main groups have more than one condition, how are the conditions in the same group computed? Is there a statistical calculation that accounts the weight of the conditions of that group or is it simply an average of all the samples in that group independently of their condition?
2 - Regarding the WGCNA and the modules feature, after computing to include 8000 genes I obtain 18 different modules but only 12 are shown in the Module-Trait relationship chart. I would like to ask what is the selection criteria for the modules that are shown?
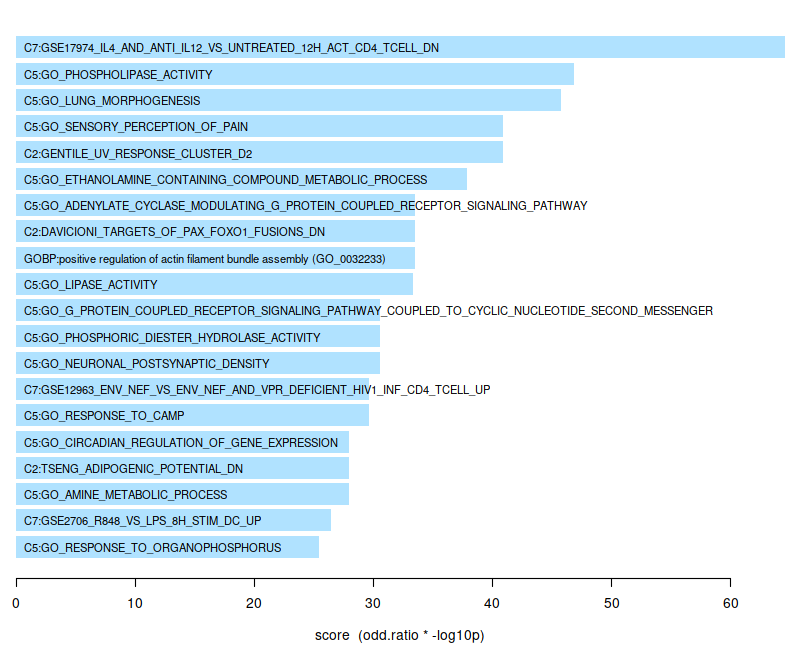
3 - Also in the WGCNA - Modules - Enrichment plot, only for module 1 I see some of the top most enriched genesets bar in pink, for all other modules all geneset bars are shown in blue. I would like to ask what is the meaning of this difference in colour?
Thank you in advance for your help.
Kind regards,
Luis Martins

{kind=link}
{kind=link}
{kind=link}
{kind=link}