worker node not booting to login prompt after RHCOS deployment. Observed this issue multiple time. Any resolution to this issue ?
41 views
Skip to first unread message

Sunny Anthony
Jul 6, 2021, 3:15:45 AM7/6/21
to okd-wg
Hi,
Anyone faced errors after deployment of RHCOS image and booting post-deployment. 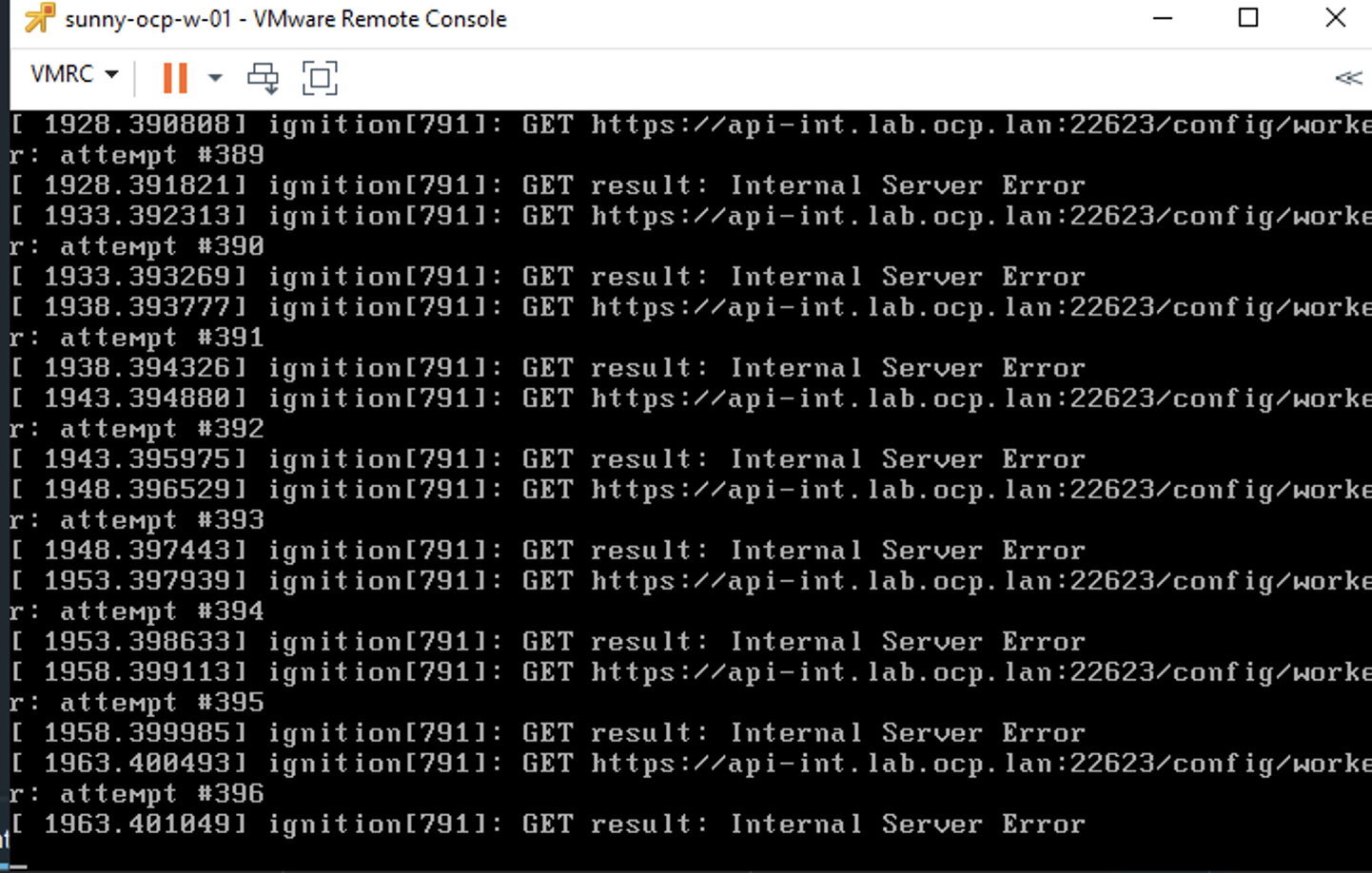

Eduardo Lúcio Amorim Costa
Jul 7, 2021, 5:10:49 PM7/7/21
to okd-wg
This is normal to happen for a maximum period of 30 minutes on worker nodes.
To follow the evolution of the bootstrap process in OKD_SERVICES use...
`
openshift-install wait-for bootstrap-complete --log-level=info --dir=/usr/local/okd/
`
... and to follow up with more details on OKD_BOOTSTRAP access via (no password required)...
`
ssh co...@10.3.0.4
`
...and run this command...
`
journalctl -b -f -u release-image.service -u bootkube.service
` .
IMPORTANT: The "bootstrap" process only ends when "all" the "nodes" - in fact only the "master nodes" need to be - have been created and output similar to the one below is observed for the `openshift-install wait-for bootstrap-complete --log-level=info --dir=/usr/local/okd/`...
"
[...]
INFO Waiting up to 20m0s for the Kubernetes API at https://api.mbr.okd.local:6443...
INFO API v1.20.0-1077+2817867655bb7b-dirty up
INFO Waiting up to 30m0s for bootstrapping to complete...
INFO It is now safe to remove the bootstrap resources
INFO Time elapsed: 1350s
"
... and output similar to the one below is observed for the command `openshift-install wait-for bootstrap-complete --log-level=info --dir=/usr/local/okd/`...
"
[...]
Jun 22 21:07:51 okd4-bootstrap bootkube.sh[14320]: I0622 21:07:51.810982 1 waitforceo.go:67] waiting on condition EtcdRunningInCluster in etcd CR /cluster to be True.
Jun 22 21:07:53 okd4-bootstrap bootkube.sh[14320]: I0622 21:07:53.164188 1 waitforceo.go:64] Cluster etcd operator bootstrapped successfully
Jun 22 21:07:53 okd4-bootstrap bootkube.sh[14320]: I0622 21:07:53.164541 1 waitforceo.go:58] cluster-etcd-operator bootstrap etcd
Jun 22 21:07:53 okd4-bootstrap bootkube.sh[8771]: bootkube.service complete
Jun 22 21:07:53 okd4-bootstrap systemd[1]: bootkube.service: Deactivated successfully.
Jun 22 21:07:53 okd4-bootstrap systemd[1]: bootkube.service: Consumed 16.979s CPU time.
" .
NOTE: The "node workers" are created from the "master nodes".
Another suggestion of a general nature is that you note that your servers have enough hardware resources as shown in this table (as this is often a "hidden" source of a lot of problems):
```
NAME ROLE CPU RAM
OKD_BOOTSTRAP bootstrap 4[V] 8~16
OKD_MASTER_1 master 4[V] 8~16
OKD_MASTER_2 master 4[V] 8~16
OKD_MASTER_3 master 4[V] 8~16
OKD_WORKER_1 worker 4[V] 12~16
OKD_WORKER_2 worker 4[V] 12~16
OKD_SERVICES DNS/LB/web/NFS 4[V] 4
_ [V] Nested virtualization enabled (if your nodes run on a Hypervisor).
```
Hope I was helpful! Success! =D
Sunny Anthony
Jul 9, 2021, 8:22:29 AM7/9/21
to okd-wg
Thanks for more insight to the investigation .

Mario Gamboa
Jul 10, 2021, 12:24:30 AM7/10/21
to okd-wg
If you are installing OKD you need fedora core OS for the installation if you are trying OKD on RHCOS just to let you know when the bootstrap reboot now with the new fedora image if the case of okd you need to login to the bootstrap machine remove the directory of cni and reboot the machine rm -rf /opt/cni after you make that the bootstrap starting ok when the master and workers reboot into fedora core you need to make the same to allow them join if not you going to get errors of connection because the cni hasn't been started.
Sunny Anthony
Jul 13, 2021, 3:45:04 AM7/13/21
to okd-wg
Hi Mario,
I'm trying RHCOS on OpenShift 4.7.18. Will workaround mentioned work for RHCOS on OpenShift as well ?
Regards,
Sunny

Jaime Magiera
Jul 14, 2021, 9:57:57 AM7/14/21
to Sunny Anthony, okd-wg
Hi Sunny,
This Google Group is for people using OKD, an Open Source community-supported version of Kubernetes, which is a parallel of Red Hat OCP. If you are trying to install OCP, there are various official Red Hat support avenues.
Jaime Magiera
DevOps Engineer Senior
ICPSR
DevOps Engineer Senior
ICPSR
"If you want to build a ship, don't drum up people together to collect wood and don't assign them tasks and work, but rather teach them to long for the endless immensity of the sea."
-- Antoine de Saint-Exupery
-- Antoine de Saint-Exupery
--
You received this message because you are subscribed to the Google Groups "okd-wg" group.
To unsubscribe from this group and stop receiving emails from it, send an email to okd-wg+un...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/okd-wg/75a28f91-8d38-4bb9-8c12-da6337229d77n%40googlegroups.com.
Mario Gamboa
Jul 17, 2021, 12:20:36 AM7/17/21
to okd-wg
Ah ok , how did you try to install openshift as IPI or UPI method what i mention before was with the UPI (user provisioning infrastructure) method and using pxeboot to do that. let me know what kind of method and i can help doesn't matter is openshift this think of no help because is a product from a company but the source is and opensource doesn't make any sense for me , i can undestard even if you try the ocp you are on you own same as okd sometimes you get help sometimes you need to figure it out but never mind let me know your process for the installation of ocp even did you already setup dns and have you haproxy as loadbalancer before start the installation and of course dhcp for the ip
Mario Gamboa
Jul 17, 2021, 12:29:32 AM7/17/21
to okd-wg
sorry i miss the picture , the issue you have is because is try to looking in the app-int.ocp dns name did you create the 2 zones 1 that is called api-int.lab.ocp.local and the other one api.lab.ocp.local in your dns and did you have point to othe same ip of you load balancer
example of my haproxy in this case i use 1 machine with haproxy and 2 ip's in the same machine for example 10.0.0.1 point to api.lab.ocp.lan api-int.lab.ocp.lan and 10.0.0.2 ingress apps.lab.ocp.lan
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
daemon
# stats socket for hatop
stats socket /var/run/haproxy.sock mode 0600 level admin
defaults
mode http
log global
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# Enable stats on :9000/haproxy_stats (no auth required)
listen stats
bind 0.0.0.0:9000
mode http
stats enable
stats uri /haproxy_stats
#---------------------------------------------------------------------
### API SERVER here resolve 10.0.0.1 point to api.lab.ocp.lan api-int.lab.ocp.lan
#---------------------------------------------------------------------
frontend api-server-6443
mode tcp
bind *:6443
default_backend api-server-6443
frontend api-server-22623
mode tcp
bind *:22623
default_backend api-server-22623
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
daemon
# stats socket for hatop
stats socket /var/run/haproxy.sock mode 0600 level admin
defaults
mode http
log global
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# Enable stats on :9000/haproxy_stats (no auth required)
listen stats
bind 0.0.0.0:9000
mode http
stats enable
stats uri /haproxy_stats
#---------------------------------------------------------------------
### API SERVER here resolve 10.0.0.1 point to api.lab.ocp.lan api-int.lab.ocp.lan
#---------------------------------------------------------------------
frontend api-server-6443
mode tcp
bind *:6443
default_backend api-server-6443
frontend api-server-22623
mode tcp
bind *:22623
default_backend api-server-22623
#---------------------------------------------------------------------
### API SERVER BACKENDS
#---------------------------------------------------------------------
backend api-server-6443
mode tcp
balance roundrobin
server master0 10.139.203.102:6443 check
server master1 10.139.203.103:6443 check
server master2 10.139.203.104:6443 check
#server bootstrap 10.139.203.101:6443 check <--bootstrap only need comment out when you provision for first time the cluster
backend api-server-22623
mode tcp
balance roundrobin
server master0 10.139.203.102:22623 check
server master1 10.139.203.103:22623 check
server master2 10.139.203.104:22623 check
#server bootstrap 10.139.203.101:22623 check <--bootstrap only need comment out when you provision for first time the cluster
#---------------------------------------------------------------------
### INGRESS TRAFFIC here is resolve 10.0.0.2 point to apps.lab.ocp.lan
#---------------------------------------------------------------------
frontend ocp_ingress_80
mode tcp
bind *:80
default_backend ocp_ingress_80
frontend ocp_ingress_443
mode tcp
bind *:443
default_backend ocp_ingress_443
#---------------------------------------------------------------------
### INGRESS TRAFFIC BACKENDS
#---------------------------------------------------------------------
backend ocp_ingress_80
mode tcp
balance roundrobin
server worker0 10.139.203.105:80 check
server worker1 10.139.203.106:80 check
server worker2 10.139.203.107:80 check
backend ocp_ingress_443
mode tcp
balance roundrobin
server worker0 10.139.203.105:443 check
server worker1 10.139.203.106:443 check
server worker2 10.139.203.107:443 check
Reply all
Reply to author
Forward
0 new messages