Okapi HTML filter ignores OmegaT option "Remove leading/trailing tags"

Manuel Souto Pico
<br>
<a href="#">Click here to continue.</a>
- <g1>Strongly agree</g1>
- <g1>Click here to continue.</g1>
- Strongly agree
- Click here to continue.

jim
This would be a feature request. The HTML filter has never done
this type of cleanup. However, we do have steps like
CodeSImplifier that would do this (not part of the actual filter).
I'm not familiar with the OmegaT integration but it should be
possible to add something like this and use the OmegaT option you
describe.
Jim
--
You received this message because you are subscribed to the Google Groups "okapi-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to okapi-users...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-users/CABm46baLQivcy-16mfGK4A%3DrWZQZ%3D_urd4HRojYxyC%3D%2B%3DipRFQ%40mail.gmail.com.
Manuel Souto Pico

Mihai Nita
<a href="#">Click here to continue.</a>
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-users/CABm46bYLVy3%2BE9OPw2W4daX-Zk3q5K4gvJTE99g0ZzXb3OWZbg%40mail.gmail.com.
jim
The filters job is to produce the most complete output - so that other subsequent steps have full access to all information. This is why most filters *do not* do cleanup. OpenXml and IDML are exceptions in that the codes they produce can be justified as needless noise. Or any any case a compromise is made in order that the segments can be translated.
The best solution is to use post-processing like the PostSegmentationSimplifierStep. It will do what you want but gives you much finer control over the kinds of things Mihai is warning about (very important!)
I don't know the OmegaT integration code but see no reason this couldn't be added as an option (barring resources and time).
Jim
jim
I see. The problem is Mihai and I are not familiar with OmegT or
its integration. If this was working file a bug ticket with the
info below. This is something that has to be done post-filter as
the HTML filter itself does not have this option.
One thing we might want to consider is spinning off the OmegaT integration code into an independent project. It would have its own issues, code base etc.. I think it would make things *much* easier for you guys. We could give everyone access. Doesn't even need to live in the Okapifraamework repository. We could create a new one.
What do you guys think?
Hi Jim,
jim <jhargr...@gmail.com> escreveu no dia segunda, 7/03/2022 à(s) 15:20:
The filters job is to produce the most complete output - so that other subsequent steps have full access to all information. This is why most filters *do not* do cleanup. OpenXml and IDML are exceptions in that the codes they produce can be justified as needless noise. Or any any case a compromise is made in order that the segments can be translated.
I think that's a different topic from the issue that I was raising. My feedback was not about tag noise clean-up in general, but about how the filter ignores a user-defined setting in OmegaT that allows the user to decide whether leading/trailing tags are displayed or not.
The purpose of inline tags is to replicate those codes in the translation while letting the translator insert them in the appropriate location in the translation. However, leading and trailing tags never have a different position in the target language, the two paired tags must simply embed the full sentence in both languages. I have never seen an exception to that and I can't think of a reason for changing their position. Therefore, they don't need to be exposed in the segment, since the translator will have to insert them in the same position (at the beginning and at the end of the segment). It doesn't prevent translation, it just makes it more cumbersome when that happens often.
I'm not sure if my original example was misleading (at least I think I have managed to mislead Mihai..). Let me try with another example. I had used an example in HTML in my original email, but I've just seen now that this problem also happens with other file types such as XLIFF.
I can produce an OmegaT project in Rainbow from the HTML file of my original email, where the XLIFF file has something like this:
<trans-unit id="tu4" restype="x-input"><source xml:lang="en-US"><g id="1" ctype="x-label" equiv-text="<label for="answer">">Strongly agree</g></source><target xml:lang="fr-FR"><g id="1" ctype="x-label" equiv-text="<label for="answer">">Strongly agree</g></target></trans-unit>
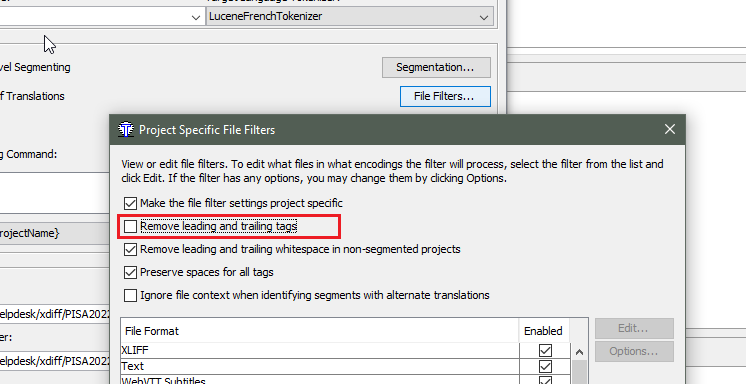
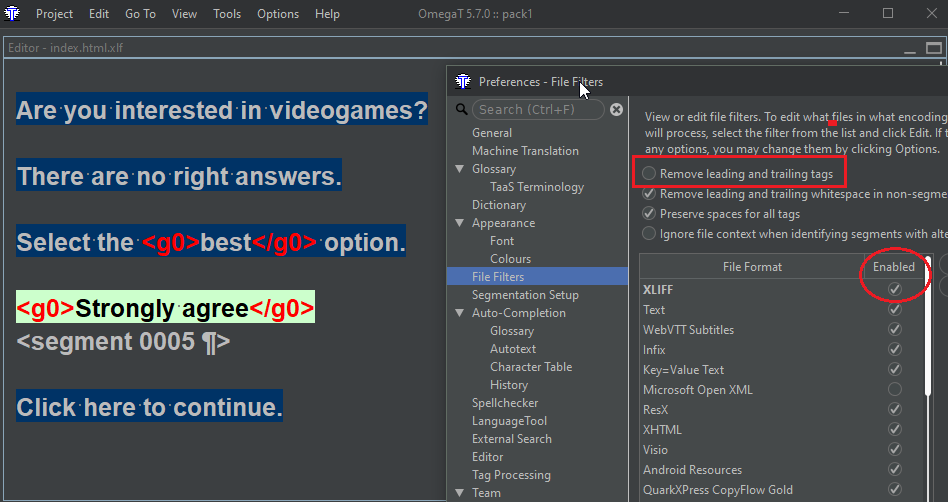
If I use the default OmegaT XLIFF filter and have the "Remove leading and trailing tags" option unchecked, I get:
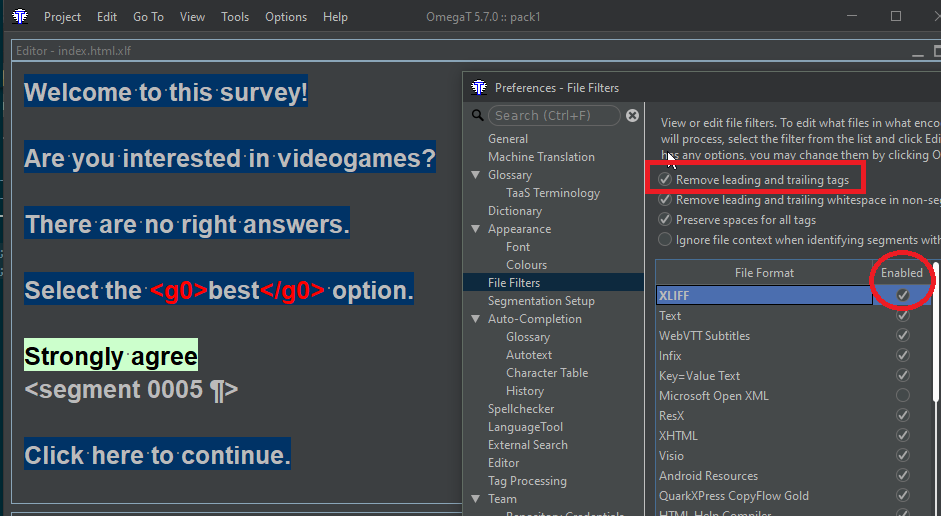
If I check the "Remove leading and trailing tags" option (with that same filter), I get:
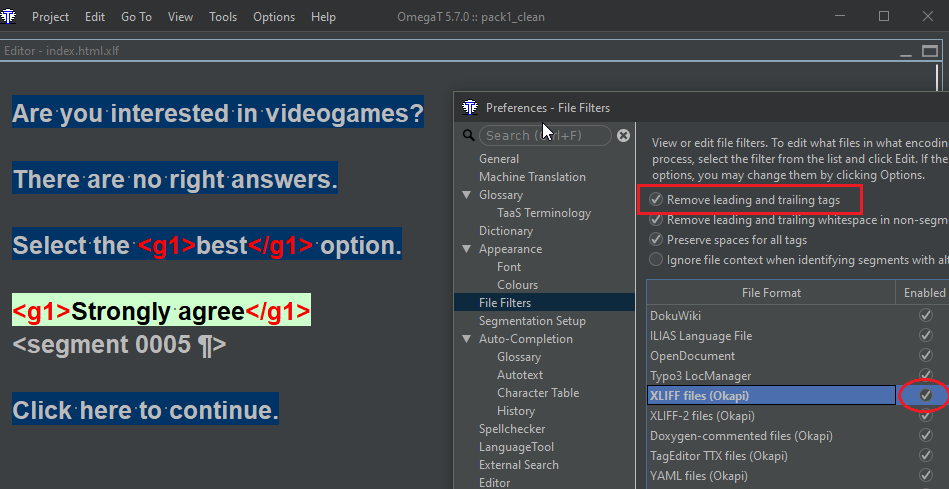
So far so good. However, if I try to use the same preference with the Okapi XLIFF filter, it makes no effect, I get the tags nonetheless:
In other words, the problem is independent from what the filter does or what I configure the filter to do (whether <br> is considered INLINE or TEXTUNIT or EXCLUDED, etc.). I think Mihai was talking about that.
The best solution is to use post-processing like the PostSegmentationSimplifierStep. It will do what you want but gives you much finer control over the kinds of things Mihai is warning about (very important!)
I have tried adding this step (precisely called "Post-segmentation Inline Codes Simplifier") to my pipeline, but I get the same result as above in the generated XLIFF...
I have added a segmentation step just in case, but with no rules...

I don't know the OmegaT integration code but see no reason this couldn't be added as an option (barring resources and time).
If it can do the same thing as the "Remove leading and trailing tags" option in OmegaT, and can be added to all Okapi filters in the plugin for OmegaT, that would be fine with me. However, I think it would be much clearer if the "Remove leading and trailing tags" option in OmegaT could work also with Okapi filters.
I don't know whether the problem is in the Okapi filter not being aware of that setting or in OmegaT not sending that info to the filter...
I hope this helps.
Cheers, Manuel
jim
Thinking about this more it makes sense to actually move the
okapi plugin to OmegaT. That way you guys can address any
configuration issues in the plugin, while we continue to address
problems on the Okapi side.
Mihai Nita
You received this message because you are subscribed to the Google Groups "okapi-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to okapi-devel...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/73c64118-43b3-030c-2ade-64e618680a77%40gmail.com.
Mihai Nita
Manuel Souto Pico
jim
The plugin code does not contain any true filters - only wrappers
for the Okapi filters. The plugin acts as a light intermediate
between OmegaT and Okapi. It's the code you want to change if
there is a configuration problem for example.
https://bitbucket.org/okapiframework/omegat-plugin/src/dev/
We could just give you guys full access to this repository. Make any changes you need. Several of your tickets could be addressed above vs the "real" Okapi filters here:
https://bitbucket.org/okapiframework/okapi/src/dev/
Agreed, lets wait for Aaron Madlon-Kay to reply.
Jim

Aaron Madlon-Kay
Hi Jim,
<image.png>
If I check the "Remove leading and trailing tags" option (with that same filter), I get:
<image.png>
So far so good. However, if I try to use the same preference with the Okapi XLIFF filter, it makes no effect, I get the tags nonetheless:
<image.png>
In other words, the problem is independent from what the filter does or what I configure the filter to do (whether <br> is considered INLINE or TEXTUNIT or EXCLUDED, etc.). I think Mihai was talking about that.
The best solution is to use post-processing like the PostSegmentationSimplifierStep. It will do what you want but gives you much finer control over the kinds of things Mihai is warning about (very important!)
I have tried adding this step (precisely called "Post-segmentation Inline Codes Simplifier") to my pipeline, but I get the same result as above in the generated XLIFF...
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-users/1cdc3818-43a6-e4b8-82f9-3c18114060a5%40gmail.com.

yves.s...@gmail.com
Hi all,
I tend to agree with Aaron.
The problem is mostly resource: never enough time to do half of what’s needed.
-yves ☹
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-users/A77516D7-DF70-4813-97B9-F34D240B212F%40madlon-kay.com.
Jim Hargrave
On Mar 15, 2022, at 9:34 PM, yves.s...@gmail.com wrote:
Manuel Souto Pico
jim
The removal of leading/trailing tags would have to be done in the omegat interface code (the repository I pointed to). This isn't a direct option for the okapi HTML filter. You would have to post-process the text units coming out of okapi before they go to OmegaT.
But I have never worked in that code - this is my best guess. But
this doesn't address how to get the trimmed tags back into
Okapi. Anyway hopefully this can get you started. Keep in
mind those are *not* Okapi filters only wrappers of okapi filters
for OmegaT.
I think this is where you intercept the content:
AbstractOkapiFilter.processFile()
Jim