Possible state cleaning issue with MarkDownFilter...

jim
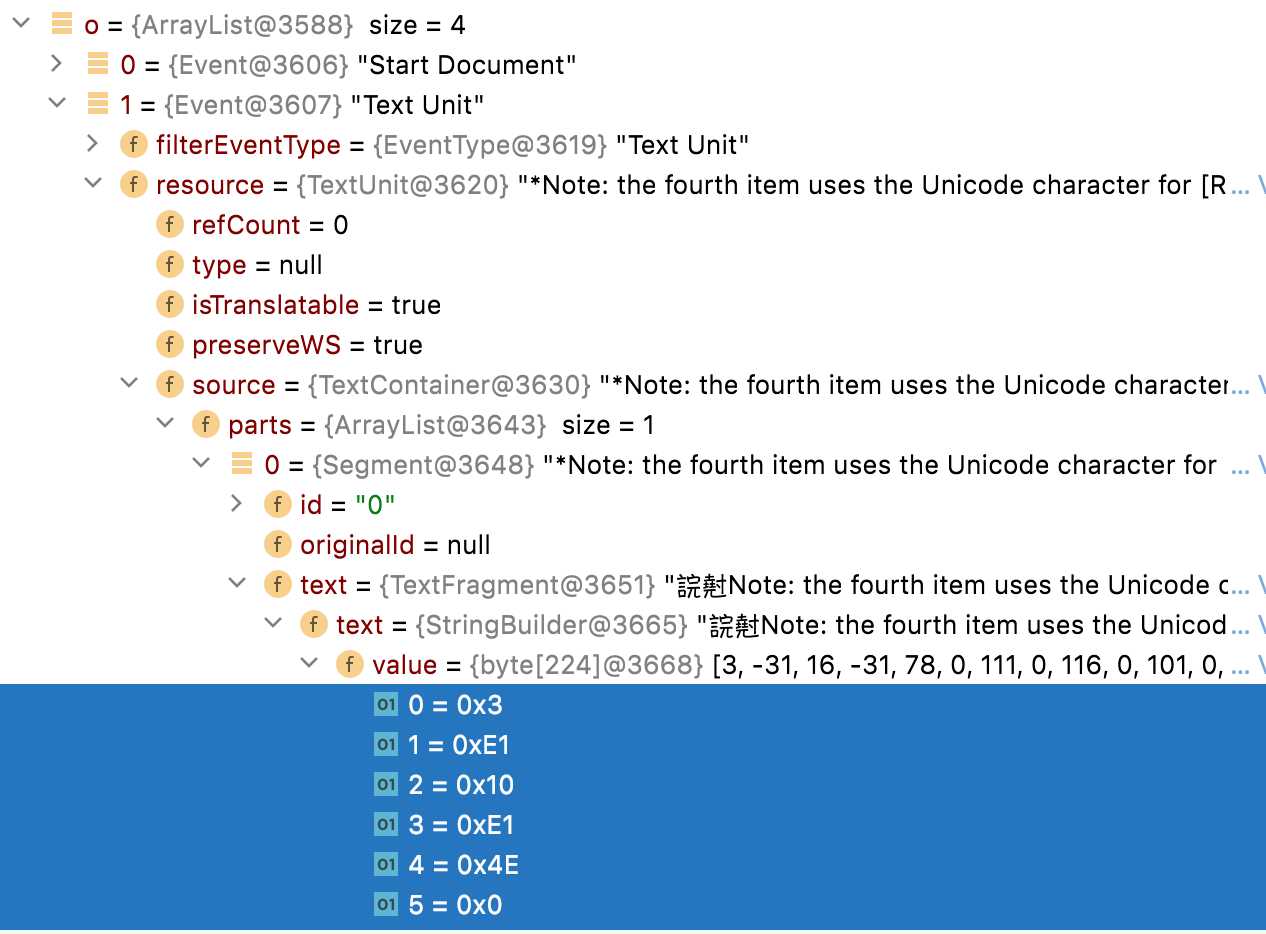
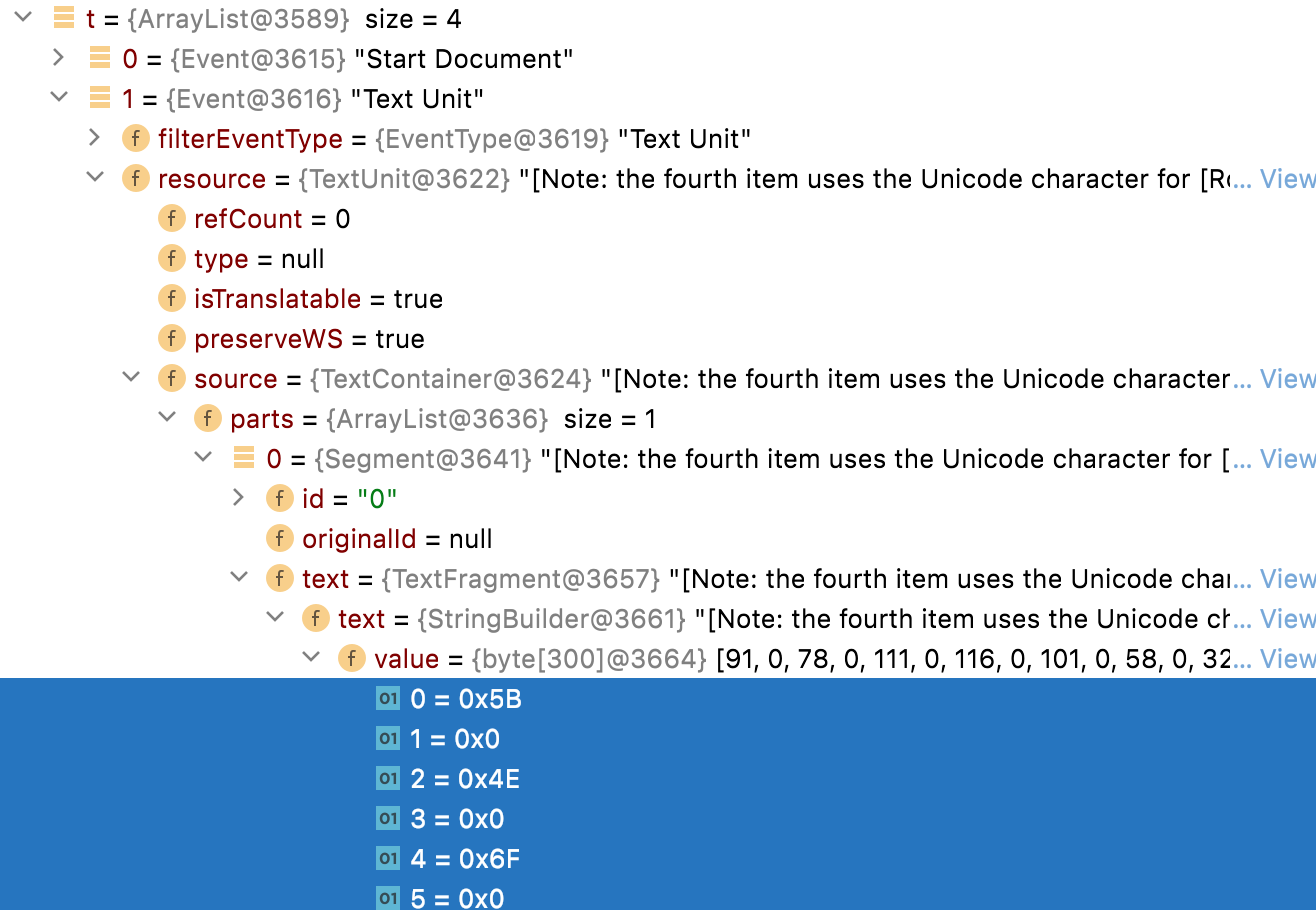
*Note: the fourth item uses the Unicode character for [Roman numeral four][2].*
First filter of the content above produces correct open/close tags for "*" as expected.
Close the filter but do not re-create it and filtering the same content makes the "*" open/close isolated tags.
I suspect that not all the reset logic is being applied to MarkDownFilter.close()
Jim

krsk...@gmail.com
public void testCloseMightNotResettingStatusProperly() throws Exception {
String snippet = "*Note: the fourth item uses the Unicode character for [Roman numeral four][2].*";
try (MarkdownFilter filter = new MarkdownFilter()) {
ArrayList<Event> events = FilterTestDriver.getEvents(filter, snippet, null);
ArrayList<Event> events2 = FilterTestDriver.getEvents(filter, snippet, null);
boolean areEventListsSame = FilterTestDriver.compareEvents(events, events2);
assertTrue(areEventListsSame);
}
}

Chase Tingley
--
You received this message because you are subscribed to the Google Groups "okapi-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to okapi-devel...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/6cbaccbb-1041-4cb6-8c64-0388ac950a83n%40googlegroups.com.
krsk...@gmail.com
jim
I found this with the integration tests which reproduce a realistic pipeline - the code matcher found the differences and complained. That's the easiest way to test it. Just drop a new file in with the example string and create a new test case for that specific file.
Jim
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/f47ec6a4-4af1-4db7-b8e5-40757d0aaea0n%40googlegroups.com.
jim
I'm slammed with other tasks sorry couldn't give a better unit test.
Jim
krsk...@gmail.com
Yes, the second pass keeps the "*" tags OPEN/CLOSE but the char marker in TextFragment is changed to isolated.
I found this with the integration tests which reproduce a realistic pipeline - the code matcher found the differences and complained. That's the easiest way to test it. Just drop a new file in with the example string and create a new test case for that specific file.
jim
@Test
public void debug() throws FileNotFoundException, URISyntaxException {
final File file = root.in("/markdown/test.md").asFile();
runTest(false, file, null, null, new FileComparator.EventComparator());
--
You received this message because you are subscribed to the Google Groups "okapi-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to okapi-devel...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/3c039ec3-6db4-4006-a3f0-ca7e73fedc0fn%40googlegroups.com.
krsk...@gmail.com
RawDocument trd = new RawDocument(Util.toURI(tkitMerged), "UTF-8", source, target)) {
filter.setFilterConfigurationMapper(mapper);
final List<Event> o = IntegrationtestUtils.getEvents(filter, ord, params);
final List<Event> t = IntegrationtestUtils.getEvents(filter, trd, params);
assertTrue("Compare Lines: " + f, comparator.compare(t, o));
}
These error messages were displayed at the merge time:
$ ./tikal.sh -m test.md.xlf
...
Merging
...
Code mismatch in TextUnit tu1
Can't find matching Code(s) id='3' originalId='' data='<g id=3>', Closing data='2'
Can't find matching Code(s) id='3' originalId='3' data='</g>'
Can't find matching Code(s) id='1' originalId='' data='*'
Done in 1.635s
$ cat test.out.md
Note: the fourth item uses the Unicode character for [Roman numeral four][2.]
$ cat test.md
*Note: the fourth item uses the Unicode character for [Roman numeral four][2].*
jim
We have to be very careful when using simplified codes like x and g (is that default for Tikal?). All our integration tests use non-simplified codes. Technically it should work both ways, but I have noticed that simplified codes can be hard to match between source and target because they loose info like the original data.
Can you try tikal without simplified codes and see what difference that makes? I may need to make a special code compare case for simplified codes - but we don't mark them in any special way.
Jim
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/52cc0080-fb96-425b-92ab-a76cfe43eca4n%40googlegroups.com.
jim
almost forgot - please use the branch "fix_textunitmerger" (now PR https://bitbucket.org/okapiframework/okapi/pull-requests/590) this may fix the actual code match issue you saw with Tikal.
Jim
krsk...@gmail.com
Code mismatch in TextUnit tu1
Can't find matching Code(s) id='1' originalId='' data='</Xpt>'
Can't find matching Code(s) id='1' originalId='' data='*'
Code mismatch in TextUnit tu1
Can't find matching Code(s) id='1' originalId='' data='</Xpt>'
Can't find matching Code(s) id='4' originalId='' data=']'
$ cat test.out.md
*Note: the fourth item uses the Unicode character for [Roman numeral four][2.
$ cat test.md
*Note: the fourth item uses the Unicode character for [Roman numeral four][2].*
Jim Hargrave
jim
If you just run your simple initial unit test can you confirm that the "*" and "*" tags are converted to true OPEN/CLOSE and not ISOLATED? I think you mentioned they were ISOLATED, but this doesn't seem correct to me as they are in the same segment (unless they are separated somehow?). Any tags in the same TextFragment should never be marked as isolated.
Our new logic for code matching is more precise and relies on finding OPEN/CLOSE mates in both source and target. If there are ISOLATED tags we may not get the best match.
Also, here is the code in Tikal to change the xliff placeholder mode. Should we update this permanently? We loose info with simplified placeholders.
// Filter events to raw document final step (using the XLIFF writer)
FilterEventsWriterStep fewStep = new FilterEventsWriterStep();
XLIFFWriterParameters paramsXliff;
XLIFFWriter writer = new XLIFFWriter();
fewStep.setFilterWriter(writer);
paramsXliff = writer.getParameters();
paramsXliff.setPlaceholderMode(true); <---- Change to false to get full bpt/ept tags
paramsXliff.setCopySource(extOptCopy);
paramsXliff.setIncludeAltTrans(extOptAltTrans);
paramsXliff.setIncludeCodeAttrs(extOptCodeAttrs);
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/989da180-76f2-42bc-b7b3-962179cbf8a6n%40googlegroups.com.
krsk...@gmail.com
<source xml:lang="en"><it id="1" pos="open">*</it>Note: the fourth item uses the Unicode character for <bpt id="2">[</bpt>Roman numeral four<ept id="2">]</ept><bpt id="3">[</bpt><ept id="3">2</ept><it id="4" pos="close">]</it>.<it id="1" pos="close">*</it></source>
krsk...@gmail.com
Can't find matching Code(s) id='4' originalId='' data=']'
krsk...@gmail.com
jim
I think this might be fixed with a proper balanceCodes call in the filter. The open/close tags have the same id.
I will make some adjustments and add it to my branch if possible.
I also think we need to change the Tikal xliff default output - but I will check on that as well as in this case id's should have been enough to match.
thanks!!
Jim
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/0f3f619d-9829-4f65-a635-e741afe9e854n%40googlegroups.com.
jim
Since we get both the **source** and target content from the xliff file - then try to match the original file source (unsegmented) on merge - that's why we are getting mismatches.
I think what we need for the MarkDownFilter is a smart post-processor that can repair these illegal codes before they leave the filter.
Jim
krsk...@gmail.com
jim
Thanks Kuro!
To view this discussion on the web visit https://groups.google.com/d/msgid/okapi-devel/a7d2c030-29bd-4cf3-86be-8909d88eb20dn%40googlegroups.com.