Centered or non-centered parameterization?
174 views
Skip to first unread message

Matthijs Hollanders
Jul 18, 2021, 2:34:52 AM7/18/21
to nimble-users
Hello all,
I'm wondering if there's general guidance on how to formulate models in NIMBLE regarding centered vs. non-centered parameterization, or if this is context dependent. When I specify a random intercepts/slopes model like this:
y[i,m] ~ alpha[m] + beta1[m]*x
alpha[m] ~ dnorm(alpha.mu, sd = alpha.sigma)
alpha.mu ~ dnorm(0, sd = 10)
alpha.sigma ~ dunif(0, 10)
beta[m] ~ dnorm(beta.mu, sd = beta.sigma) # idem
beta.mu ~ dnorm(0, sd = 10)
beta.sigma ~ dunif(0, 10)
vs.
y[i,m] ~ (alpha0 + alpha[m]) + (beta0 + beta[m])*x
alpha0 ~ dnorm(0, sd = 10)
alpha[m] ~ dnorm(0, sd = alpha.sigma)
alpha.sigma ~ dunif(0, 10)
beta0 ~ dnorm(0, sd = 10)
beta[m] ~ dnorm(0, sd = beta.sigma)
beta.sigma ~ dunif(0, 10)
I notice I get different samplers, like losing the conjugate sampler on alpha.mu in the second parameterization. I've seen that a few people recommend the latter parameterization for STAN but I'm not sure if NIMBLE would be the same. What I like about the second parameterization is that one could put indicator variables for RJMCMC on the random component as a test to see if there's additional random variation to the mean intercept and/or slopes (alpha0 and beta0). But, if it's going to give me much less efficient sampling, it may be better to formulate the first parameterization.
Looking forward to your answer. I'm still loving NIMBLE!
Regards,
Matt

Daniel Turek
Jul 19, 2021, 7:07:30 AM7/19/21
to Matthijs Hollanders, nimble-users
Matt, thanks for the question.
Without seeing the full model, it's a little difficult to discuss answers. Notably, the lines:
y[i,m] ~ alpha[m] + beta1[m]*x
and
y[i,m] ~ (alpha0 + alpha[m]) + (beta0 + beta[m])*x
don't specify any distribution on the right-hand-side following the "~", so I think something is missing. If the distribution for y[i,m] was normal (dnorm), then you'd still retain conjugate samplers for alpha0 and beta0 in the second parameterization, but it sounds like that's not the case.
Beyond the issue of conjugate sampling, the different parameterizations could affect MCMC performance in a number of ways. In the second parameterization, MCMC updates to alpha0 and beta0 will always require calculation of the full likelihood for all y[i,m] terms, so this could be slower computationally. In contrast, using the first parameterization, MCMC updates to alpha.mu and beta.mu only require calculating the log-density of the alpha[m] and beta[m] terms, respectively, so these could be faster.
That said, using the second parameterization, updates to the mean terms alpha0 and beta0 would take place independently from the deviation terms alpha[m] and beta[m]. Decoupling the relationship between these will generally allow them to sample (update value during the course of the MCMC) more freely, resulting in faster MCMC mixing and increased posterior effective sample size. As you noted, however, this could be at the expense of conjugate sampling, so the fact remains there's no definitive answer to your question. But these are the sorts of issues I would consider. Time allowing, you might try both approaches, and inspect the performance of the MCMC from each.
I hope this helps, and fuels thinking about some of these considerations.
Cheers,
Daniel
--
You received this message because you are subscribed to the Google Groups "nimble-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to nimble-users...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/20c91fce-9223-43b4-b9c2-c88d204dbf68n%40googlegroups.com.
Matthijs Hollanders
Jul 19, 2021, 7:03:11 PM7/19/21
to nimble-users
Hi Daniel,
Thanks for getting back so quickly. I realise my initial message was both vague and incorrect. I've since better wrapped my head around non-centered parameterization. I'll also expand on my model a bit. I'm working on a mark-recapture model with capture histories from three sites. I'm modeling the survival and capture probabilities as logistic functions of a number of predictors. So my survival function of individual i, at time (interval) t, and site m is:
logit(phi[i,t,m]) ~ phi.alpha[m] + phi.beta[1]*x[1] + phi.beta[2]*x[2]
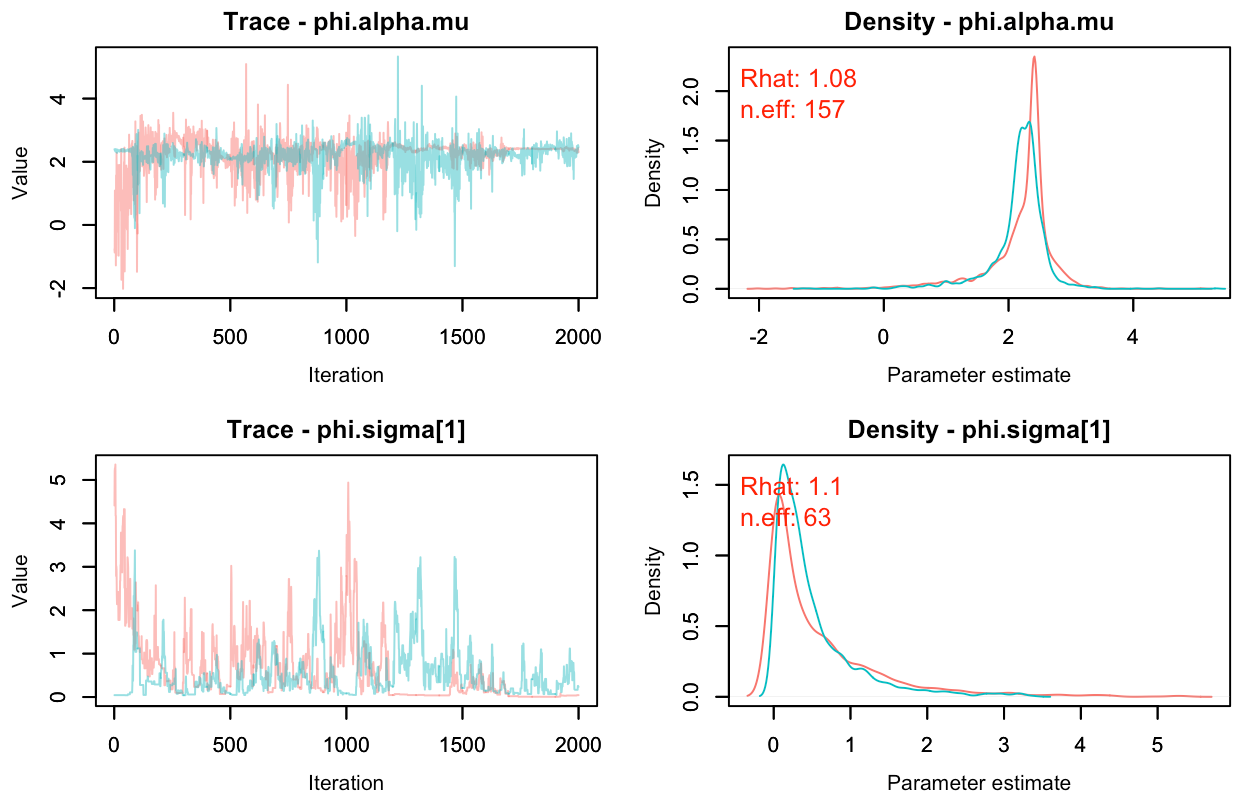
I'm allowing the intercept to vary by site (phi.alpha[m]), but not the predictors, but the methodology also applies to predictors. I'm modeling the intercepts as random draws of a normal distribution (I realise that with only three sites, this is questionable). If I parameterize it as follows
phi.alpha[m] ~ dnorm(phi.alpha.mu, phi.alpha.sigma)
phi.alpha.mu ~ dnorm(0, sd = 1.5)
phi.alpha.sigma ~ dunif(0, 10)
I get whacky traceplots (attached image 'Centered.png'). From what I've gathered from the Stan camp (see, for example, http://elevanth.org/blog/2017/09/07/metamorphosis-multilevel-model/), this happens when samplers get stuck somewhere in the parameter space. When I apply the non-centered parameterization as follows
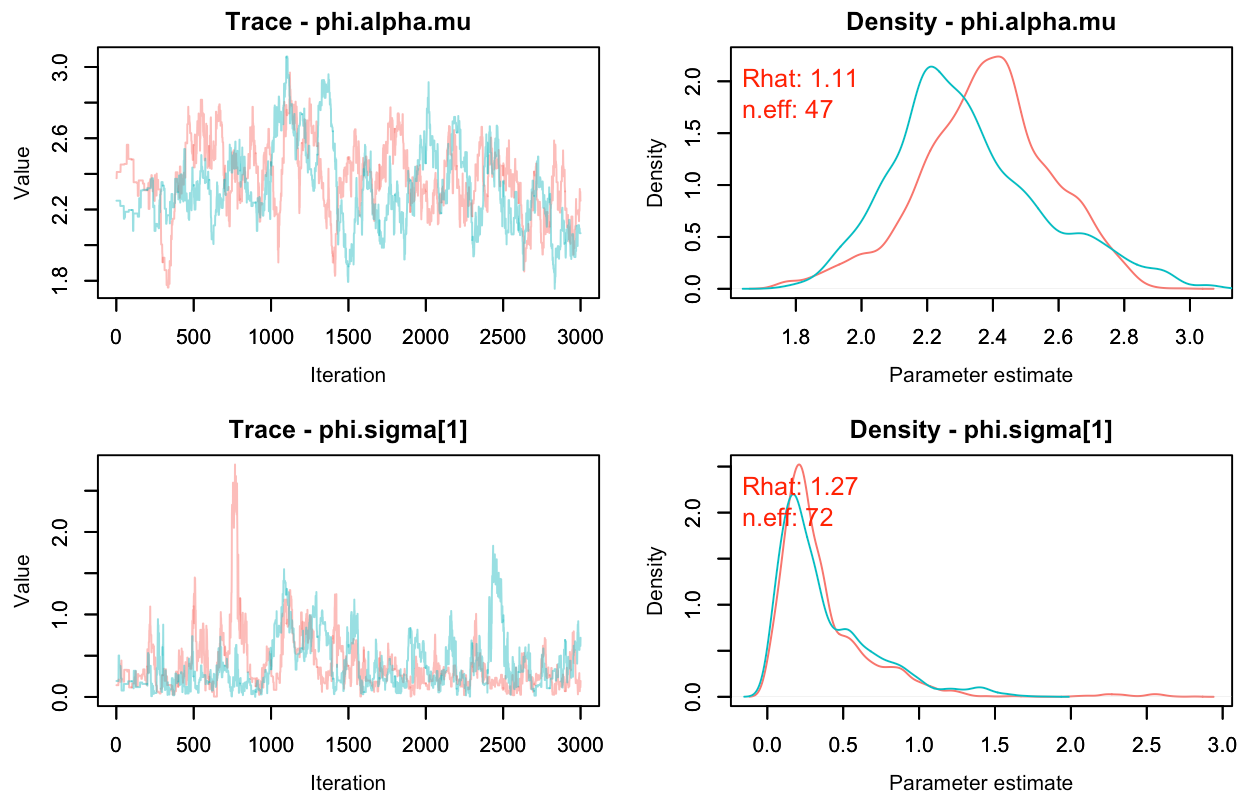
phi.alpha[m] <- phi.alpha.mu * phi.alpha.z[m]*phi.alpha.sigma)
phi.alpha.mu ~ dnorm(0, sd = 1.5)
phi.alpha.sigma ~ dunif(0, 10)
phi.alpha.z[m] ~ dnorm(0, 1)
The sampling much improves ('Noncentered.png'). Not that there's no convergence yet, but my model is quite complex and takes a fair few more iterations to reach convergence. I realise this is nothing new as there's lots of stuff online about the non-centered parameterization, but I'd never heard or read about it anywhere in the bugs/jags/nimble camp. I think it may be helpful. I didn't measure the speed of sampling but it doesn't matter so much to me given how much better the traceplots look.
Regards,
Matt

Perry de Valpine
Jul 19, 2021, 8:27:36 PM7/19/21
to Matthijs Hollanders, nimble-users
I'm not delving fully into this at the moment but just want to point out this paper, Yu & Meng 2012, on the topic: https://doi.org/10.1198/jcgs.2011.203main The results in this paper suggest the best-mixing approach is problem-specific. As a result, they suggest interweaving the two approaches. At times among nimblers we have discussed trying to write samplers that can do this automatically based on the model structure. It would be somewhat involved, but it could be a great project if anyone is looking for an idea to contribute to the package...
-Perry
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/4d673964-012b-4878-b67a-3026bda7e203n%40googlegroups.com.
Daniel Turek
Jul 20, 2021, 11:31:28 AM7/20/21
to Matthijs Hollanders, nimble-users, Perry de Valpine
Matt, one thing which might be causing some problems, when you model the site intercept as a random effect, with the line:
I think you'd want "sd = " to specify that phi.alpha.sigma is the normal *standard deviation*. That might make the posterior results more sensical, and consistent with other MCMC runs:
phi.alpha[m] ~ dnorm(phi.alpha.mu, sd = phi.alpha.sigma)
Hope this helps,
Daniel
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/CABeTmqh4X%3DrGrCYngjvf%3Di8fwcTit8xfCj_2cNuBHjXEPfD4Jg%40mail.gmail.com.

{kind=link}
{kind=link}
Chris Paciorek
Jul 20, 2021, 1:02:04 PM7/20/21
to Daniel Turek, Matthijs Hollanders, nimble-users, Perry de Valpine
My understanding is that the non-centered generally works better for HMC, hence the recommendation to use it when using Stan. If not using HMC, as Perry points out, it's probably problem specific, but often in my experience centered will work better.
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/CAKbe0hq1crqaAh3kONfeTGGS2BP-i%3DF7Hu0nHBgrPveVVWo-SA%40mail.gmail.com.
Matthijs Hollanders
Jul 20, 2021, 6:38:46 PM7/20/21
to nimble-users
Perry, thanks for that paper. Very interesting. Definitely over my head and I'm not qualified to write such samplers, otherwise I'd raise my hand.
Daniel, you're right, I once again wrote it incorrectly in this thread. In my code, the sigmas are specified as being SD's.
Chris, do you have any references for that? My understanding was that HMC allows one to quantify the divergent transitions which makes diagnosing the problem possible, but that non-centered parameterizations should also have benefits for samplers other than HMC. Did you take a look at my traceplots? It's only a few thousand (unthinned, no burnin) iterations from a complex model, but it seems to me that the non-centered parameterization works considerably better. The disturbing thing to me is that the Rhat value doesn't really capture that the chains aren't behaving properly.
Chris Paciorek
Jul 21, 2021, 12:55:42 PM7/21/21
to Matthijs Hollanders, nimble-users
I don't have a reference for use of non-centered for HMC apart from discussions on the Stan forum and probably in their documentation.
As for whether non-centered might be better in non-HMC situations, as Perry commented, it can vary depending on the context.
-chris
To view this discussion on the web visit https://groups.google.com/d/msgid/nimble-users/04dca01f-a613-4313-be86-41fa8dbabc88n%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages